
Способы формирования и типы выборок




![]()
![]()
Качество результатов выборочного наблюдения зависит от репрезентативностивыборки, т. е. от того, насколько она представительна в генеральной совокупности. Для обеспечения репрезентативности выборки надо соблюдать принцип случайности отбора статистических величин, который реализуется разными способами.
В статистике применяются различные способы формирования выборочных совокупностей, что обусловливается задачами исследования и зависит от специфики объекта изучения.
Основным условием проведения выборочного исследования является предупреждение возникновения систематических ошибок, возникающих вследствие нарушения принципа равных возможностей попадания в выборку каждой единицы генеральной совокупности. Предупреждение систематических ошибок достигается в результате применения научно обоснованных способов формирования выборочной совокупности.
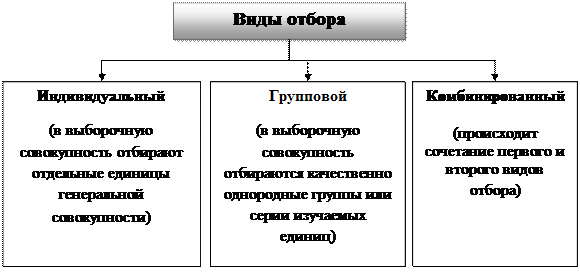
Существуют следующие способы (виды) отбора единиц из генеральной совокупности:
1) индивидуальный отбор – в выборку отбираются отдельные единицы;
2) групповой отбор – в выборку попадают качественно однородные группы или серии изучаемых единиц (бригады, микрорайоны);
3) комбинированный отбор – это сочетание индивидуального и группового отбора.
Отбор также может быть нерайонированным, который предполагает отбор единиц в выборочную совокупность из генеральной совокупности, не разбитой на группы по каким-либо признакам, и районированным, когда генеральная совокупность делится на группы по признакам (например, отбор предприятий по отраслям). Способы отбора определяются правилами формирования выборочной совокупности.
В зависимости от способа отбора выделяют следующие виды выборок:
1). Собственно-случайная (простая случайная) выборка состоит в том, что выборочная совокупность образуется в результате случайного (непреднамеренного) нерайонированного отбора отдельных единиц из генеральной совокупности. Единица отбора совпадает с единицей наблюдения. При этом количество отобранных в выборочную совокупность единиц обычно определяется исходя из принятой доли выборки.
Доля выборки есть отношение числа единиц выборочной совокупности n к численности единиц генеральной совокупности N, т. е. 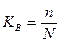 .
.
Так, при 5%-ной выборке из партии товара в 2 000 ед. численность выборки n составляет 100 ед. (5*2000:100), а при 20%-ной выборке она составит 400 ед. (20*2000:100) и т. д.
Примеры случайной выборки: лотерея, жеребьёвка или тираж. При этом обеспечивается абсолютно равная возможность попадания в выборку любой единицы. Этот способ можно осуществить также с помощью математических таблиц случайных чисел.
Собственно случайный отбор по методу проведения может быть повторным и бесповторным. При повторном отборе каждая единица, отобранная в случайном порядке из генеральной совокупности, после проведения наблюдения возвращается в эту совокупность, и может быть вновь подвергнута исследованию, т. е. имеет шанс попасть в новую выборку. При повторном отборе вероятность попадания каждой отдельной единицы генеральной совокупности в выборку остаётся постоянной. На практике такой способ отбора встречается редко.
Гораздо более распространен собственно случайный бесповторный отбор, при котором исследованные единицы в генеральную совокупность не возвращаются и не могут быть исследованы повторно. При бесповторном отборе вероятность попадания отдельных единиц в каждую последующую выборку меняется, для всех единиц, остающихся в генеральной совокупности после отбора, она возрастает.
Бесповторный отбор даёт более точные результаты, поэтому применяется чаще. Но есть ситуации, когда его применить нельзя (изучение пассажиропотоков, потребительского спроса и т. п.), и тогда ведётся повторный отбор.

2). Механическая выборка состоит в том, что отбор единиц в выборочную совокупность производится из генеральной совокупности, разбитой на равные интервалы (группы) по определённому критерию (по алфавиту, через временные промежутки, по пространственному способу и т. д.). Затем из каждой группы выбирается по одной единице наблюдения. При этом размер интервала (шаг отбора) в генеральной совокупности равен обратной величине доли выборки, т. е. определяется путём деления числа единиц генеральной совокупности на число единиц выборочной совокупности: 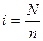 .
.

В выборочную совокупность входят единицы генеральной совокупности, расположенные в списке через данный интервал. Причём, если ряд не ранжирован, то первая единица выбирается наугад, а последующие – через равные интервалы. Так, при 2%-й выборке отбирается каждая 50-я единица (1:0,02), при 5%-й выборке – каждая 20-я единица (1:0,05) и т. д. Если статистические величины ранжированы, то выбираются единицы, находящиеся в серединах интервалов.
Таким образом, в соответствии с принятой долей отбора, генеральная совокупность как бы механически разбивается на равновеликие группы. Из каждой группы в выборку отбирается лишь одна единица.
Важной особенностью механической выборки является то, что формирование выборочной совокупности можно осуществить, не прибегая к составлению списков. На практике часто используют тот порядок, который позволяет брать единицы так, как они фактически располагаются в генеральной совокупности. Принцип случайного отбора в механической выборке обеспечивается тем, что единицы в генеральной совокупности располагаются в таком порядке, который не оказывает влияние на изучаемый признак или фактор. Например, последовательность выхода готовых изделий с конвейера или поточной линии, порядок размещения единиц партии товара при хранении, транспортировке, реализации и т. д.
3). Типическая (стратифицированная) выборкапредполагает, что генеральная совокупность вначале разделяется на однородные типические группы по реально существующим признакам. Затем из каждой типической группы собственно-случайной или механической выборкой производится индивидуальный отбор единиц в выборочную совокупность.
Общий объём выборки n разбивается пропорционально между списками:
1-й вариант – пропорционально удельному весу типических групп:
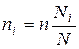 ,
,
где: n – объём выборки;
N – объём генеральной совокупности;
ni – число наблюдений из i-той типической группы;
Ni – объем i-той типической группы в генеральной совокупности.
2-й вариант – равномерный (из каждой группы поровну):
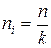 ,
,
где k – число групп.
3-й вариант – оптимальный (для групп с большей вариацией признака объём наблюдений увеличивается):
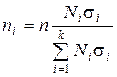 .
.
Типическая выборка обычно применяется при изучении сложных статистических совокупностей. Например, при выборочном обследовании производительности труда работников торговли, состоящих из отдельных групп по квалификации.
Типический отбор облегчает формирование выборочных совокупностей и обеспечивает более равномерное распределение единиц в генеральной совокупности.
Важной особенностью типической выборки является то, что она даёт более точные результаты по сравнению с другими способами отбора единиц в выборочную совокупность.
Разновидностью типической выборки является систематический отбор, т. е. механический отбор из совокупности, ранжированной по какому-либо признаку, связанному с изучаемым признаком. Например, отбор рабочих по семейному бюджету, связанному с их средней заработной платой.
4). Серийная (гнездовая) выборкахарактеризуется тем, что генеральная совокупность первоначально разбивается не на отдельные единицы совокупности, а на определённые равновеликие или неравновеликие серии, или гнёзда (единицы внутри серий связаны по определённому признаку), из которых путём случайного отбора отбираются серии, и затем внутри отобранных серий проводится сплошное наблюдение.
Например, при 10% обследовании качества продукции можно проверять каждую 10-ю единицу (механический отбор), при серийном – через 9 часов каждый 10-й час обследуется вся выпущенная продукция в течение целого часа.
Серийный отбор применяется редко, так как даёт высокую ошибку выборки.
5).Моментная выборка означает, что на определённые моменты времени фиксируется наличие отдельных элементов изучаемого процесса.
При моментном наблюдении обычно характеризуется альтернативный признак (работа или простой). При этом в качестве численности выборочной совокупности, принимается число записей моментного обследования. Например, изучение использования работниками рабочего времени и времени работы оборудования.
Моментное наблюдение может охватывать все единицы совокупности, стать сплошным.
6). Комбинированная выборка представляет собой сочетание нескольких способов выборки. При этом генеральная совокупность сначала разбивается на группы. Затем производят отбор групп, а внутри последних осуществляется отбор отдельных единиц.
Выборки также подразделяются на одноступенчатые и многоступенчатые.
При одноступенчатой выборке каждая отобранная единица сразу же подвергается изучению по заданному признаку. Так обстоит дело при собственно-случайной и серийной выборке.
При многоступенчатой выборке производят подбор из генеральной совокупности отдельных групп, из них – подгрупп, а из последних выбираются отдельные единицы. Так производится типическая выборка с механическим способом отбора единиц в выборочную совокупность.
Типичный отбор состоит в многоступенчатой выборке из сочетания нескольких стадий отбора, причём на каждой стадии имеется своя единица отбора (отрасль предприятия, численность работников и средняя заработная плата).
В случае многофазной выборки из исходной выборки составляются определённые подвыборки для последующих исследований по более обширной программе. Главное отличие многофазной выборки от многоступенчатой заключается в том, что на всех его этапах используются одни и те же единицы отбора, а каждая последующая фаза опирается на совокупность единиц наблюдения предыдущей фазы. При ступенчатом отборе единицы отбора меняются на каждой ступени.
По степени охвата единиц генеральной совокупности выборки разделяются на большие и малые.
Малая выборка – такое выборочное наблюдение, численность единиц которого находится в интервале от 4-5 до 30, в противоположном случае выборка считается большой. Хотя общий принцип выборочного наблюдения – чем больше выборочная совокупность, тем точнее показатели, – иногда используют малую выборку. Малая выборка применяется при исследовании качества продукции с последующим уничтожением проверяемой единицы.
Источник
Методы формирования выборки
При формировании выборки используются вероятностные (случайные) и невероятностные (детерминированные) методы.
Вероятностная выборка – любой метод формирования выборки, предполагающий, что вероятность попадания в выборку каждого элемента совокупности известна и больше нуля. Формирование вероятностной выборки можно использовать только в том случае, если имеется основа выборки и единицы исследования удается пронумеровать.
Детерминированная выборка получается, когда отбор в выборку производится на основе каких-либо дополнительно принятых условий, ограничивающих круг вероятных респондентов. Эту выборку применяют, когда невозможно получить список всех единиц генеральной совокупности и определить вероятность попадания в выборку каждого элемента.
Случайные (вероятностные) методы
Вероятностные методы включают в свой состав простой случайный отбор, систематический, кластерный и стратифицированный отбор (рис.15).

Рис. 15. Вероятностные методы формования выборок
Простой случайный отборпредполагает, что вероятность быть избранным в выборку известна и является одинаковой для всех единиц совокупности. Вероятность быть включенным в выборку определяется отношением объема выборки к размеру совокупности. Простой случайный отбор может осуществляться с помощью следующих методов: формирование выборки вслепую, с помощью таблицы случайных чисел, с использованием генератора случайных чисел.
При использовании метода формирования выборки вслепую единицы совокупности в соответствии с их фамилиями, названиями или другими признаками вносятся в карточки, которые в перемешанном виде помещаются в какую-то непрозрачную емкость (ящик, коробку). Из данной емкости кто-то случайным образом вытягивает число карточек, определяемое объемом выборки.
В таблицах случайных чисел содержатся числа, порядок включения которых в таблицу осуществлен случайным образом. Единицам совокупности присваивают порядковые номера. В таблице случайных чисел выбирают любую начальную точку и, двигаясь в произвольном направлении и произвольно меняя направление движения, выбирают необходимое количество номеров из числа присвоенных, равное заранее установленному объему выборки.
На практике метод используется нечасто, так как необходимо предварительно определить каждую единицу совокупности, пронумеровать ее, что при больших размерах совокупности сделать сложно, а порой невозможно.
Метод систематического отбора является упрощенным вариантом случайного отбора и представляет собой процедуру отбора каждого k-го элемента из списка элементов исходной совокупности. Номер первого элемента выборки часто определяется случайным образом.
В основу выборки здесь положены не вероятностные процедуры, а алфавитные списки, картотеки, схемы, которые, как предполагается, не зависят от изучаемого признака и обеспечивают равновероятность попадания в выборку всех единиц генеральной совокупности. Используется показатель «интервал скачка», рассчитанный как отношение размера совокупности к объему выборки. Например, если используется телефонный справочник и интервал скачка был определен равным 250, то это означает, что каждый 250-й телефонный номер включается в выборку. Для определения начальных страниц и колонки справочника используются случайные числа. Данный метод является более экономичным и быстрым по сравнению с методом простого случайного отбора.
Особенно широко метод систематического отбора используется, когда для различных видов совокупностей имеются различные справочники, списки и т.п. материалы.
Кластерный отбор (другое название – территориальная, районированная выборка): часто приходится разделять обследуемую совокупность на более или менее однородные части (кластеры) и затем осуществлять отбор единиц внутри этих частей. Такое разделение совокупности на части называется районированием. Территории или зоны выступают в роли первичных выборочных единиц. Генеральная совокупность делится (обычно с использованием карты) на ряд непересекающихся, исчерпывающих ее подмножеств (кластеров) или территорий, после чего формируется случайная выборка этих территорий.
Проблема заключается в обеспечении однородности выделяемых кластеров на основе существенных для исследователя критериев. Для решения такой задачи необходимо располагать данными о структуре генеральной совокупности и, в частности, о распределении признака районирования. Выделенные кластеры должны существенно отличаться друг от друга, но им должна быть присуща внутренняя однородность.
Стратифицированный отбор:генеральная совокупность разбивается на несколько групп (страт), отличающихся друг от друга по каким-либо признакам (доходу, возрасту, полу, национальности, отношению к чему-либо и пр.). Далее респонденты отбираются из каждой страты.
Если размер выборки для определенной страты пропорционален размеру страты в генеральной совокупности, то выборка называется пропорционально стратифицированной.
Если количество респондентов из каждой страты отбирается в соответствии с некоторыми установленными пропорциями, то выборка называется стратифицированной с оптимальным распределением. Например, основные покупатели товара – это молодежь от 18 до 25 лет, то оптимальным распределением будет такое, при котором из этой группы отберется 50% респондентов, а из других групп по 10%.
В некоторых источниках встречается название – расслоенная выборка.
Детерминированные (невероятностные) выборки
Детерминированные (невероятностные, неслучайные) методы отбора включают в свой состав: отбор на основе принципа удобства, отбор на основе суждений экспертов, формирование выборки в процессе обследования (метод «снежного кома») (рис.16).

Рис. 16. Невероятностные методы формования выборок
Удобная выборка – формирование выборки осуществляется самым удобным с позиций исследователя образом. Например, с позиций минимальных затрат времени и усилий, с позиции доступности респондентов. Выбор места исследования и состава выборки производится субъективным образом, например, опрос покупателей осуществляется в магазине, ближайшем к месту жительства исследователя. Очевидно, что многие представители совокупности не принимают участия в опросе.
Исследователь здесь имеет дело с максимально доступными для него единицами наблюдения и исходит по преимуществу только из критерия принадлежности респондента к проектируемой генеральной совокупности. Чаще всего в данном случае допускаются неконтролируемые систематические ошибки. Особенно это относится куличным опросам, когда фиксируется мнение тех, кто имеет возможность и желание поговорить с интервьюером. Существенную роль в данном случае играет взаимное расположение при встрече. Оценить репрезентативность выборки при таком отборе практически невозможно. Данный метод является дешевым и простым.
Выборка на основе суждения экспертов (типовая выборка):используют мнения квалифицированных специалистов относительно состава выборки (см. табл. 6).
Формирование выборки в процессе опроса («Снежный ком») основано на расширении числа опрашиваемых на основе предложений респондентов, которые уже приняли участие в обследовании. Первоначально исследователь формирует выборку намного меньшую, чем требуется в проводимом исследовании, затем она по мере проведения обследования расширяется. Данный метод применяется там, где основы выборки являются очень ограниченными, например, при проведении маркетинговых исследований продукции производственно-технического назначения.
Квотный отбор основан на целенаправленном формировании структуры выборочной совокупности. Интервьюер получает задание опросить некоторое количество лиц определенного возраста, пола, образования и профессии. Удельный вес квоты в выборочной совокупности должен соответствовать ее удельному весу в генеральной совокупности. Распределение этих признаков в генеральной совокупности известно и нетрудно обеспечить ее идентичность структуре выборки.
Но при соблюдении квот остается много возможностей для систематических ошибок. В частности, интервьюер, разыскивая респондента определенного пола, статуса и возраста в заданном районе, предпочтет беседовать с более привлекательными и коммуникабельными людьми. Дж. Гэллап отмечал, что в квотных выборках обнаруживается слишком много людей, окончивших колледж, с доходами выше среднего, республиканцев по политическим ориентациям.[30] Поэтому вероятностный отбор обладает немалым преимуществом перед квотным: выборка меньше зависит от инициативы интервьюера.
На практике имеет место параллельное использование нескольких методов формирования выборки.
7.3. Определение объема выборки
Объем выборки – это количество элементов генеральной совокупности, которые нужно изучить.
При определении объема выборки нужно прежде решить задачу требуемого исследователю уровня точности результата (Δ), гарантируемого с некоторой заранее заданной доверительной вероятностью (Р).
Допустимая ошибка Δ (случайная ошибка)– отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности. Эта величина определяет значение ошибки, хуже которой результат не должен быть.
Случайная ошибка – это вероятность того, что выборочная средняя не выйдет за пределы заданного интервала. Свойство случайных ошибок уменьшаться при возрастании объема выборочной совокупности делает бессмысленными обследования огромных массивов, которые предпринимаются чаще всего с целью произвести впечатление на профессионально неподготовленного заказчика (приложение 4).
Величина ошибки результатов опроса, задается исследователем. Максимально допустимая величина ошибки составляет 10 %. Чем меньше ошибка выборки, тем больше объем выборки и дороже исследование. Ошибка в 5 % считается оптимальной с точки зрения «цена – качество» исследования.
Доверительная вероятность – вероятность того, что результат проведенного измерения будет попадать в те границы, которые исследователь задает.
Формула, по которой можно, задавшись величинами допустимой ошибки и доверительной вероятности, вычислить требуемый объем выборки для оценки доли:

где N – объем генеральной совокупности;
p – доля исследуемого признака в генеральной совокупности;
t – коэффициент соответствия доверительной вероятности Р;
Δр – допустимая ошибка.
Значение t определяется по таблице нормированного нормального распределения, фрагмент которой имеет вид:
Р: … 0,80 0,85 0,90 0,95 0,96 0,97 0,98 0,99 0,995 0,997
t : … 1,29 1,44 1,65 1,96 2,06 2,17 3,33 2,58 2,81 3,0
Неудобство этой формулы состоит в том, что она требует предварительной информации о доле признака в генеральной совокупности, то есть как раз то, что исследователю тоже требуется определить в процессе исследования. Однако при p = 0,5 произведение p·q максимально и, значит, n тоже максимально. Подставив в формулу p = 0,5, получим выражение, которым можно пользоваться при любых долях признака в генеральной совокупности, а объем выборки при этом будет получаться с некоторым запасом (при t=2 и Р=0,954).
Размер выборки при t=2 , Р=0,954 и допустимой ошибке 5% представлен в табл.4.
Из таблицы видно, что, начиная с некоторого значения генеральной совокупности, ее увеличение не ведет к увеличению объема выборки, поэтому при генеральной совокупности больше 5000 величиной N можно пренебречь.
Таким образом, при отсутствии точной информации о размере генеральной совокупности вполне можно довольствоваться выборкой 400 респондентов при N > 5000.
Существуют три стратегии расчета объема выборки.
1. Стратегия предварительного расчета (до проведения исследования). Это лишь первоначальный ориентир, так как, не принимается во внимание из-за неопределенности разброс мнений; а поэтому исходят из соотношения 50:50% (половина ответов «да», половина «нет»). Зависимость объема выборки от разброса (распределения) ответов представлена в таблице 5. Распределение ответов является важным фактором для исследования. Чаще всего до проведения исследования не знают соотношения ответов, а оно оказывает существенное влияние, как на точность получаемых ответов, так и на прямые затраты.
Зависимость объема выборки от распределения ответов
| Распределение ответов, % | 50 : 50 | 40 : 60 | 30 : 70 | 20 : 80 | 10 : 90 |
| Объем выборки |
Если разброс мнений в проведенном исследовании будет иным, чем 50 : 50 %, то точность полученных результатов исследования будет иметь ошибку меньше 5%. Оценить ее можно по следующей формуле:
 ,
,
где p, q – определенны по полученным в ходе реального исследования данным; n – объём выборки реально проведенного исследования.
2. Стратегия последовательного расчета выборки. Используется, когда каждое интервью очень дорогостоящее или слишком длительное. Тогда объем выборки не рассчитывается заранее, а ставится в зависимость от результатов, полученных в ходе исследования. Например, сначала опрашивается 100 человек, на основе полученных данных о разбросе оценки вычисляют требуемый объем. Если оказывается, что этого количества опрошенных достаточно, то исследование прекращается. В противном случае добирают необходимое количество респондентов.
3. Стратегия комбинированного расчета. Рассчитывая выборку по предварительной стратегии, получаем верхние пределы допустимых объемов выборки, то есть ту величину выборки, при достижении которой прекращается опрос по последовательной стратегии.
Величину объема выборки можно определить на основе типичных объемов выборок, используемых в аналогичных исследованиях (табл.6)
Таблица 6 дает представление об объемах выборок, используемых в различных маркетинговых исследованиях. Эти величины установлены опытным путем и могут использоваться в качестве ориентировочных данных[31].
Типичные объемы выборок,
используемые в различных исследованиях
| Предмет изучения | Минимальный объем | Типовой объем |
| Изучение рынков Тестирование товара Реклама (в расчете на одно объявление, эффективность которого исследуется) | 1000-2500 300-500 200-300 | |
| Окончание табл.6 | ||
| естирование названий Тестирование упаковки Аудит на пробном рынке Фокус-группы | 100/название 100/упаковка 10 магазинов 6 групп | 250/название 250/упаковка 10-20 магазинов 10-15 групп |
На практике существует удобный способ определения объемов выборки с помощью таблицы больших чисел (табл.7). Задавшись величинами допустимой ошибки и доверительной вероятности, определяют требуемый объем выборки на пересечении строки (доверительная вероятность) и колонки (ошибка выборки).
Таблица больших чисел
для определения объема выборки
| Доверительная вероятность | Объем выборки при допустимой ошибке | ||||||||
| 0,10 | 0,09 | 0,08 | 0,07 | 0,06 | 0,05 | 0,04 | 0,03 | 0,02 | 0,01 |
| 0,750 | |||||||||
| 0,800 | |||||||||
| 0,850 | |||||||||
| 0,900 | |||||||||
| 0,910 | |||||||||
| 0,920 | |||||||||
| 0,930 | |||||||||
| 0,940 | |||||||||
| 0,950 | |||||||||
| 0,960 | |||||||||
| 0,965 | |||||||||
| 0,970 | |||||||||
| 0,975 | |||||||||
| 0,980 | |||||||||
| 0,985 | |||||||||
| 0,990 | |||||||||
| 0,991 | |||||||||
| 0,992 | |||||||||
| 0,993 | |||||||||
| 0,994 | |||||||||
| 0,995 | |||||||||
| 0,996 | |||||||||
| 0,997 | |||||||||
| 0,998 | |||||||||
| 0,999 |
1. Почему в маркетинговых исследования чаще используются выборочные, а не сплошные исследования?
2. Какова процедура составления плана выборки?
3. Каким образом определяют изучаемую совокупность?
4. Чем изучаемая совокупность отличается от генеральной?
5. Что такое единица выборки? Чем она отличается от элемента генеральной совокупности?
6. В чем отличие вероятностных методов формирования выборки от детерминированных?
7. Каковы отличительные черты простой случайной выборки?
8. Опишите процедуру систематической случайной выборки.
9. Охарактеризуйте стратифицированную выборку. Каковы критерии отбора переменных для стратификации?
10. Чем отличается пропорционально стратифицированная выборка от оптимальной?
11. Опишите процедуру кластерной выборки. Чем отличается кластерная выборка от стратифицированной?
12. Какие факторы необходимо учитывать при выборе между вероятностными и детерминированными методами выборки.
13. Что понимают под репрезентативностью?
14. Чем характеризуется репрезентативность?
15. Какие показатели необходимо задать априорно, чтобы определить объем выборки по статистическим формулам?
16. Что такое доверительная вероятность и доверительный интервал?
17. По какой формуле определяется объем выборки, если заранее известны генеральная совокупность и распределение оценок?
18. В чем на практике неудобство этой формулы? Как можно выйти из положения?
19. Какие стратегии расчета объема выборки можно использовать?
20. Какие удобные методы определения объема выборки существуют на практике?
21. Как скажется на величине объема выборки увеличение уровня достоверности с 95% до 99%.
22. В чем суть апостериорного контроля надежности выборочных данных?
23. Каким может быть максимальное отклонение показателей выборочной совокупности от соответствующих значений государственной статистики при апостериорном контроле? В каких пределах при этом варьирует ошибка выборки по изучаемому параметру?
ГЛАВА 8. СБОР ДАННЫХ
8.1. Организация полевых работ
Полевые работы заключаются в том, что персонал работает на местах, управляет процессом анкетирования, заполняет формы для записи наблюдений, объединяет полученные данные для дальнейшей обработки. К полевому персоналу относятся интервьюеры, заполняющие анкеты на дому у респондентов, в торговых залах магазинов, проводящие опрос по телефону; работники занятые рассылкой анкет из офиса, наблюдатели и другие работники, в функции которых входит сбор данных или наблюдение за этим процессом.
Как правило, маркетологи не в состоянии самостоятельно выполнить весь объем работ по сбору информации, поэтому возникает вопрос об увеличении штата полевого персонала. Решить его, можно сформировав коллектив с привлечением временных работников, либо заключив контракт со специальным агентством, занимающимся полевыми операциями.
Процесс полевых работ представлен на рисунке 17.

Рис. 17. Процесс полевых работ
Отбор персонала для полевых работ
На качество полученных ответов могут повлиять внешность, опыт, мнение и отношение интервьюера. Поэтому исследователю нужно решить, какими специфическими качествами должны обладать люди, работающие с респондентами, и разработать конкретные должностные инструкции.
Обычно считается, что вероятность успешного опроса выше, если респондент приемлет интервьюера в социальном плане, чем больше они имеют общих характеристик, тем выше качество полученной информации. Так же отмечается, что охотнее отвечают интервьюерам старшего возраста, чем молодым.
При отборе к полевому персоналу предъявляют следующие квалификационные требования:
1) крепкое здоровье. Работа по сбору информации на местах нередко тяжела и изнурительна, поэтому работники должны обладать физической подготовкой, выносливостью;
2) общительность. Интервьюеры должны уметь находить взаимопонимание с респондентом, уметь общаться с незнакомыми людьми, уметь говорить и слушать;
3) приятная внешность. Если работник имеет нестандартную или непривлекательную внешность, собранные им данные могут несколько искажаться;
4) образование должно быть не ниже среднего;
5) опыт. Опытные работники обычно точнее выполняют инструкции, быстрее налаживают контакты с опрашиваемыми и успешнее ведут опрос.
Расчет необходимого количества полевых работников проводится по формуле:
 ,
,
где u – оптимальное число интервьюеров;
n – объем выборки;
а – норма опроса респондентов в день (при личном опросе она составляет 5-7 чел.);
t – количество дней, отводимое на сбор информации.
Необходимое количество кодировщиков для обработки открытых вопросов анкет определяется по формуле:
 ,
,
где k – оптимальное число кодировщиков;
n – объем выборки;
о – число открытых вопросов в анкете ;
а – норма обработки вопросов в день (в среднем один кодировщик за день обрабатывает около 500 вопросов);
t – количество дней, отводимое на кодирование информации.
Подготовка полевого персонала
Достоверность собранных данных во многом зависит от точности и правильности действий каждого сотрудника. Низкий уровень подготовки и инструктирования может сказаться на отношении персонала к выполняемым полевым процедурам и породить небрежное исполнение поручаемой работы.
Наиболее распространенными формами обучения персонала являются инструктаж и проведение тренинга в виде ролевой игры друг с другом, когда роль респондента исполняется кем-то из сотрудников.
В ходе подготовки интервьюеры учатся налаживать первоначальный контакт с респондентом, задавать вопросы, стимулировать ответы, правильно их записывать и завершать интервью.
Налаживание первоначального контакта. Неудачный первоначальный контакт приводит к потере потенциального респондента. Интервьюер должен научиться так начинать разговор, чтобы сразу убедить человека, что его участие в опросе действительно имеет большое значение.
Пример: Здравствуйте, я представляю шоколадную фабрику «Новосибирская». Мы проводим опрос о предпочтениях людей по отношению к шоколаду. Вы входите в группу, специально отобранную для участия в нашем исследовании в результате научного анализа. Ваше мнение очень важно для нас и мы хотели бы задать вам несколько вопросов.
Интервьюер не просит специального разрешения респондента на то, что бы задать ему вопросы. Вопросов типа «Не мог бы я занять несколько минут вашего драгоценного времени?», «Не хотели бы ответить на несколько вопросов?» следует избегать. Интервьюеры должны иметь точные инструкции о том, как действовать в случае возражений и отказов.
Следует подробно описать респондентe суть проводимого опроса. Чем больше информации получает человек, тем менее подозрительно он относится к опросу. Не следует вводить респондента в заблуждение относительно продолжительности интервью.
Если респондент говорит о неудобном времени для опроса, можно договориться с ним о переносе интервью на другое время.
Очень важно принять решение о том, в какое время дня обзванивать респондентов. После 21 часа звонить неприлично.
Как задавать вопросы. Изменение содержания или последовательности вопросов во время интервью сильно влияет на результаты опроса. Персонал обязан задавать вопросы в таком порядке, как они расположены в анкете, даже если кажется, что анкета несовершенна.
Разрабатывая инструкцию для интервьюеров, необходимо воспользоваться следующими рекомендациями: тщательно изучить содержание анкеты; задавать вопросы точно в том порядке, в котором они включены в анкету; использовать только формулировки анкеты; зачитывать вопросы медленно, чтобы было понятно каждое слово; повторить вопрос, если респондент его не понял; задать все вопросы; следовать разработанному образцу пропусков (переходу от одного вопроса к другому); сохранять нейтралитет, не проявлять своего согласия либо несогласия с мнением респондента; избегать посторонних разговоров с респондентом.
Как стимулировать ответы. Стимулирование применяется для того, чтобы побудить респондента расширить или пояснить ответ, сосредоточиться на вопросе.
Для стимулирования ответов широко применяются следующие методы:
— повторение ответа респондента. Интервьюер дословно воспроизводит ответ, записывая его. Это может побудить респондента к комментариям;
— использование паузы. Выжидательная пауза или взгляд могут быть намеком на то, что интервьюер хочет получить более полный ответ;
— подбадривание респондента. Если респондент колеблется, уместно сказать, например, «Не существует правильных или неправильных ответов, мы просто хотим выяснить ваше мнение». Если респондент нуждается в пояснении слова или вопроса, нельзя предлагать ему своих интерпретаций. Нужно добиться, чтобы интерпретацию дал сам респондент, сказав, например, следующее: «Все зависит от того, что это означает для вас»;
— получение пояснений. Получить более полный ответ можно, используя нейтральные вопросы типа: не могли бы рассказать подробнее; существуют какие-либо иные причины; еще что-нибудь; что вы имеете в виду; что под этим подразумеваете; как вы к этому относитесь, другие варианты.
Как правильно записывать ответы. При работе со структурированными вопросами отмечается вариант, отображающий ответ респондента, если вопрос не структурирован – ответ записывается дословно, не обобщается и не перефразируется. В запись включается все, что имеет отношение к цели опроса. Записав полученный ответ, интервьюер должен повторить его. Кроме этого, фиксируются все стимулирующие действия и комментарии. В ходе инструктажа необходимо также отметить, что записи ответов ведутся четко и аккуратно; ответы не фальсифицируются.
Как завершать интервью. После опроса у респондента должно остаться положительное впечатление об интервью. Важно поблагодарить его и выразить свою признательность за сотрудничество.
Контроль над работой полевого персонала
Чтобы убедиться, что в ходе опроса соблюдаются все полученные инструкции, необходим контроль за работой полевого персонала. Контроль проводится по трем направлениям:
1) контроль качества ведения интервью и редактирования;
2) выборочный контроль;
3) предотвращение мошенничества.
Контроль качества ведения интервью. Контролер проверяет, находится ли интервьюер в положенном месте в положенное время. Он должен убедиться, что интервьюер соблюдает все необходимые методы работы. Если выявляются проблемы, необходим дополнительный инструктаж или тренинг. Чтобы лучше понимать проблемы интервьюеров, контролер должен время от времени сам участвовать в опросах. Ежедневно собирая анкеты, контролеры редактируют их: проверяют на все ли вопросы даны ответы; нет ли неясных, противоречащих друг другу ответов; разборчивы ли записи. Ежедневный сбор заполненных анкет позволяет контролировать график выполнения работ.
Выборочный контроль. Проверяется соблюдают ли интервьюеры выборочный план. Зачастую полевые работники допускают такие погрешности:
— избегают те элементы выборки, работать с которыми им тяжело или неприятно;
— если нужного респондента не оказывается дома, заменяют его следующей доступной единицей выборки, а не стараются связаться с ним еще раз;
— «растягивают» требования относительно пропорциональных выборок: чтобы выполнить требования квот, 58-летнего респондента включают в категорию 46 – 55-летних людей.
С целью контроля проводятся повторные интервью.
Контроль для предотвращения мошенничества. Мошенничество заключается в фальсификации ответов на некоторые или все вопросы анкеты. Самая бессовестная форма мошенничества – интервьюер сам отвечает на все вопросы, вообще не пообщавшись с респондентом. Вероятность такого обмана сводится к минимуму хорошей подготовкой персонала и строгим контролем.
Проверка результатов полевых работ
Чтобы проверить подлинность полученных в ходе опроса данных, контролеры обзванивают от 10 до 25 % респондентов и выясняют, действительно ли их опрашивали интервьюеры, какой была продолжительность опроса, как вел себя интервьюер, просят предоставить основные демографические данные. Полученную демографическую информацию сравнивают с данными, предоставленными в анкете.
Проверяется метод опроса, например, действительно ли проводился личный опрос, а не телефонный.
Кроме этого, проверяется, не являются ли респонденты близкими знакомыми интервьюера.
Оценка качества работы полевого персонала
Чтобы сформировать производительный штат полевых сотрудников, обеспечивающий высокое качество работы, необходимо постоянно оценивать их работу. Оценочными критериями являются:
1) эффективность использования рабочего времени (например, фактическое время опроса);
2) доля ответивших от общего количества опрашиваемых (большое количество отказов респондентов свидетельствует о неумении правильно построить вступительную речь);
3) качество опроса (контролер либо следит за интервью, либо анализирует магнитофонную запись. Качество оценивают по точности, с которой задаются вопросы, способности стимулировать ответы, не подталкивая респондента к тому или иному ответу и другим характеристикам);
4) качество полученных данных (разборчивость записи, ответы на неструктурированные вопросы понятны и полны для кодировки, пункт «нет ответа» встречается редко).
Ошибки сбора данных
Ошибки исследования могут быть двух типов: систематическими (смещение выборки) и случайными. Случайные ошибки легко оценить, их можно уменьшить с помощью увеличения выборки (см.раздел 7.3). Для общего результата значительно опаснее систематические ошибки, так как по выборке их невозможно выявить и оценить. Исследователь может даже не догадываться об их существовании. Мало этого, при увеличении объема выборки они могут возрастать, их величина и направление могут оказаться совершенно непредсказуемыми.
Чтобы исключить или уменьшить систематические ошибки, необходимо знать причины их возникновения. Систематические ошибки не связаны с выборкой, а могут быть вызваны концептуальными ошибками, допущенными при формировании выборки, неполучением данных от части выборки, ошибками сбора данных, а также статистическими, арифметическими, табуляционными ошибками.
Систематические ошибки делятся на два типа: ошибки неполучения данных и ошибки наблюдения (рис. 18).

Рис. 18. Виды систематических ошибок
Ошибки ненаблюдения возникают, если неполучены данные от части обследуемой совокупности потому, что: 1) эта часть не была представлена в выборке или 2) респонденты, включенные в выборку, не предоставили данные.
Ошибка неохвата: определенные части или целые блоки генеральной совокупности не были включены в основу выборки. Ошибка неохвата относится только к ошибочно выпавшим из рассмотрения частям генеральной совокупности, но никак ни к частям, исключенным намеренно.
Ошибка неохвата может возникнуть при использовании в качестве основы выборки телефонных списков (телефоны есть не у всех), некачественных рассылочных списков для почтовых опросов; при проведении опросов в торговых центрах (люди с самыми низкими и с самыми высокими доходами обычно представлены недостаточно); при проведении интервью на дому у респондентов (интервьюеры обходят стороной ветхие строения, чаще общаются с более общительными членами семьи, фальсифицируют демографические данные).
В противовес ошибке неохвата иногда может возникнуть ошибка перебора: например семья имеет несколько номеров телефонов, три машины и т.п., поэтому возникает большая вероятность включения их в выборку. Эта ошибка представляет меньшую опасность, чем ошибка неохвата.
Уменьшить ошибку неохвата можно улучшением основы выборки и усилением контроля над полевыми работниками.
Ошибка неполучения данных порождается отсутствием информации о некоторых элементах, которые должны были войти в выборку. Две главные причины неполучения данных – это отсутствие и отказ.
Источник



