
- 7 архитектур нейронных сетей для решения задач NLP
- Функция активации
- 1. Многослойный перцептрон
- 2. Сверточная нейронная сеть
- 3. Рекурсивная нейронная сеть
- 4. Рекуррентная нейронная сеть
- 5. LSTM
- 6. Sequence-to-sequence модель
- 7. Неглубокие (shallow) нейронные сети
- Нейронные сети в картинках: от одного нейрона до глубоких архитектур
- Иллюстративный материал
- Фреймворк
- Самая простая нейросеть
- Усложняем пример
- Дайте больше точности!
- Усложняем дальше
- Дайте больше нелинейности!
- Инициализация весов — это важно!
- Как это работает?
- За границей области обучения
- Идём в глубину
- Количество нейронов на внутренних слоях
7 архитектур нейронных сетей для решения задач NLP

Искусственная нейронная сеть (ИНС) — вычислительная нелинейная модель, в основе которой лежит нейронная структура мозга, способная обучаться выполнению задач классификации, предсказания, принятия решений, визуализации и некоторых других только благодаря рассмотрению примеров.
Любая архитектура ИНС состоит из искусственных нейронов — элементов обработки, имеющих структуру 3 связанных друг с другом слоев: входным, состоящим из одного или более слоев скрытым и выходным.
Входной слой состоит из входных нейронов, которые передают информацию в скрытый слов. Скрытый слой в свою очередь передает информацию в выходной. Каждый нейрон имеет входы с весами — синапсами, функцию активации, определяющую выходную информацию при заданной входной, и один выход. Синапсы — регулируемые параметры, конвертирующие нейронную сеть в параметризованную систему.
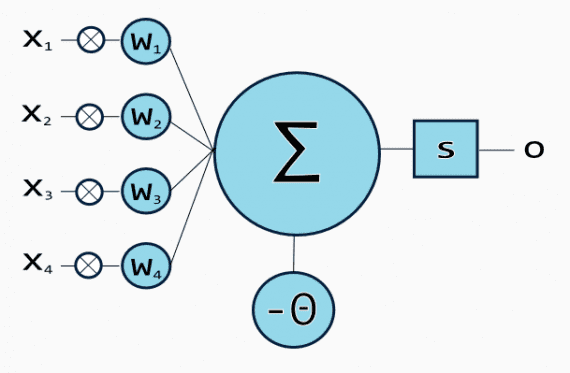 Искусственная нейронная сеть с 4 входами
Искусственная нейронная сеть с 4 входами
Функция активации
Взвешенная сумма со входов — активационный сигнал — проходит через функцию активации для вывода данных из нейрона. Есть несколько видов функции активации: линейная, ступенчатая, сигмоидная, тангенциальная, выпрямительная (Rectified linear unit, ReLu).
Линейная функция
Ступенчатая функция
Сигмоида
Функция гиперболического тангенса
Функция линейного выпрямителя
Обучение (или тренировка) — процесс оптимизации весов, в котором минимизируется ошибка предсказания, и сеть достигает требуемого уровня точности. Наиболее используемый метод для определения вклада в ошибку каждого нейрона — обратное распространение ошибки, с помощью которого вычисляют градиент. Это одна из модификаций метода градиентного спуска.
С помощью дополнительных скрытых слоев возможно сделать систему более гибкой и мощной. ИНС с многими скрытыми слоями называются глубокими нейронными сетями (deep neural network, DNN); они создают сложные нелинейные связи.
Рассмотрим популярные архитектуры нейронных сетей, которые хорошо показали себя в задачах NLP и рекомендуются к использованию.
1. Многослойный перцептрон
Многослойный перцептрон состоит из 3 или более слоев. Он использует нелинейную функцию активации , часто тангенциальную или логистическую, которая позволяет классифицировать линейно неразделимые данные. Каждый узел в слое соединен с каждый узлом в последующем слое, что делает сеть полностью связанной. Такая архитектура находит применение в задачах распознавания речи и машинном переводе.
2. Сверточная нейронная сеть
Сверточная нейронная сеть (Convolutional neural network, CNN) содержит один или более объединенных или соединенных сверточных слоев. CNN использует вариацию многослойного перцептрона, рассмотренного выше. Сверточные слои используют операцию свертки для входных данных и передают результат в следующий слой. Эта операция позволяет сети быть глубже с меньшим количеством параметров.
Сверточные сети показывают выдающиеся результаты в приложениях к картинкам и речи. В статье Convolutional Neural Networks for Sentence Classification автор описывает процесс и результаты задач классификации текста с помощью CNN. В работе представлена модель на основе word2vec, которая проводит эксперименты, тестируется на нескольких бенчмарках и демонстрирует блестящие результаты.
В работе Text Understanding from Scratch авторы показывают, что сверточная сеть достигает выдающихся результатов даже без знания слов, фраз предложений и любых других синтаксических или семантических структур присущих человеческому языку. Семантический разбор, поиск парафраз, распознавание речи — тоже приложения CNN.
3. Рекурсивная нейронная сеть
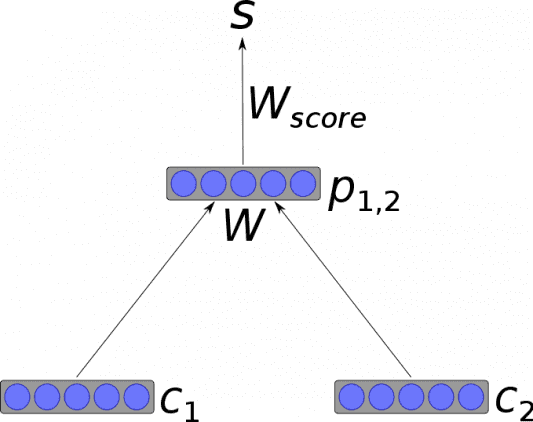
Рекурсивная нейронная сеть — тип глубокой нейронной сети, сформированный при применении одних и тех же наборов весов рекурсивно над структурой, чтобы сделать скалярное или структурированное предсказание над входной структурой переменного размера через активацию структуры в топологическом порядке. В простейшей архитектуре нелинейность, такая как тангенциальная функция активации, и матрица весов, разделяемая всей сетью, используются для объединения узлов в родительские объекты.
4. Рекуррентная нейронная сеть
Рекуррентная нейронная сеть, в отличие от прямой нейронной сети, является вариантом рекурсивной ИНС, в которой связи между нейронами — направленные циклы. Последнее означает, что выходная информация зависит не только от текущего входа, но также от состояний нейрона на предыдущем шаге. Такая память позволяет пользователям решать задачи NLP: распознание рукописного текста или речи. В статье Natural Language Generation, Paraphrasing and Summarization of User Reviews with Recurrent Neural Networks авторы показывают модель рекуррентной сети, которая генерирует новые предложения и краткое содержание текстового документа.
Siwei Lai, Liheng Xu, Kang Liu, и Jun Zhao в своей работе Recurrent Convolutional Neural Networks for Text Classification создали рекуррентную сверточную нейросеть для классификации текста без рукотворных признаков. Модель сравнивается с существующими методами классификации текста — Bag of Words, Bigrams + LR, SVM, LDA, Tree Kernels, рекурсивными и сверточными сетями. Описанная модель превосходит по качеству традиционные методы для всех используемых датасетов.
5. LSTM
Сеть долгой краткосрочной памяти (Long Short-Term Memory, LSTM) — разновидность архитектуры рекуррентной нейросети, созданная для более точного моделирования временных последовательностей и их долгосрочных зависимостей, чем традиционная рекуррентная сеть. LSTM-сеть не использует функцию активации в рекуррентных компонентах, сохраненные значения не модифицируются, а градиент не стремится исчезнуть во время тренировки. Часто LSTM применяется в блоках по несколько элементов. Эти блоки состоят из 3 или 4 затворов (например, входного, выходного и гейта забывания), которые контролируют построение информационного потока по логистической функции.
В Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling авторы показывают архитектуру глубокой LSTM рекуррентной сети, которая достигает хороших результатов для крупномасштабного акустического моделирования.
В работе Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Recurrent Neural Network представлена модель для автоматической морфологической разметки. Модель показывает точность 97.4 % в задаче разметки. Apple, Amazon, Google, Microsoft и другие компании внедрили в продукты LSTM-сети как фундаментальный элемент.
6. Sequence-to-sequence модель
Часто Sequence-to-sequence модели состоят из двух рекуррентных сетей: кодировщика, который обрабатывает входные данные, и декодера, который осуществляет вывод.
Sequence-to-Sequence модели часто используются в вопросно-ответных системах, чат-ботах и машинном переводе. Такие многослойные ячейки успешно использовались в sequence-to-sequence моделях для перевода в статье Sequence to Sequence Learning with Neural Networks study.
В Paraphrase Detection Using Recursive Autoencoder представлена новая рекурсивная архитектура автокодировщика, в которой представления — вектора в n-мерном семантическом пространстве, где фразы с похожими значением близки друг к другу.
7. Неглубокие (shallow) нейронные сети
Неглубокие модели, как и глубокие нейронные сети, тоже популярные и полезные инструменты. Например, word2vec — группа неглубоких двухслойных моделей, которая используется для создания векторных представлений слов (word embeddings). Представленная в Efficient Estimation of Word Representations in Vector Space, word2vec принимает на входе большой корпус текста и создает векторное пространство. Каждому слову в этом корпусе приписывается соответствующий вектор в этом пространстве. Отличительное свойство — слова из общих текстов в корпусе расположены близко друг к другу в векторном пространстве.
В статье описаны архитектуры нейронных сетей: глубокий многослойный перцептрон, сверточная, рекурсивная, рекуррентная сети, нейросети долгой краткосрочной памяти, sequence-to-sequence модели и неглубокие (shallow) сети, word2vec для векторных представлений слов. Кроме того, было показано, как функционируют эти сети, и как различные модели справляются с задачами обработки естественного языка. Также отмечено, что сверточные нейронные сети в основном используются для задач классификации текста, в то время как рекуррентные сети хорошо работают с воспроизведением естественного языка или машинным переводом. В следующих части серии будут описаны существующие инструменты и библиотеки для реализации описанных типов нейросетей.
Источник
Нейронные сети в картинках: от одного нейрона до глубоких архитектур
Многие материалы по нейронным сетям сразу начинаются с демонстрации довольно сложных архитектур. При этом самые базовые вещи, касающиеся функций активаций, инициализации весов, выбора количества слоёв в сети и т.д. если и рассматриваются, то вскользь. Получается начинающему практику нейронных сетей приходится брать типовые конфигурации и работать с ними фактически вслепую.
В статье мы пойдём по другому пути. Начнём с самой простой конфигурации — одного нейрона с одним входом и одним выходом, без активации. Далее будем маленькими итерациями усложнять конфигурацию сети и попробуем выжать из каждой из них разумный максимум. Это позволит подёргать сети за ниточки и наработать практическую интуицию в построении архитектур нейросетей, которая на практике оказывается очень ценным активом.
Иллюстративный материал
Популярные приложения нейросетей, такие как классификация или регрессия, представляют собой надстройку над самой сетью, включающей два дополнительных этапа — подготовку входных данных (выделение признаков, преобразование данных в вектор) и интерпретацию результатов. Для наших целей эти дополнительные стадии оказываются лишними, т.к. мы смотрим не на работу сети в чистом виде, а на некую конструкцию, где нейросеть является лишь составной частью.
Давайте вспомним, что нейросеть является ничем иным, как подходом к приближению многомерной функции Rn -> Rn. Принимая во внимания ограничения человеческого восприятия, будем в нашей статье приближать функцию на плоскости. Несколько нестандартное применение нейросетей, но оно отлично подходит для цели иллюстрации их работы.
Фреймворк
Для демонстрации конфигураций и результатов предлагаю взять популярный фреймворк Keras, написанный на Python. Хотя вы можете использовать любой другой инструмент для работы с нейросетями — чаще всего различия будут только в наименованиях.
Самая простая нейросеть
Самой простой из возможных конфигураций нейросетей является один нейрон с одним входом и одним выходом без активации (или можно сказать с линейной активацией f(x) = x):

N.B. Как видите, на вход сети подаются два значения — x и единица. Последняя необходима для того, чтобы ввести смещение b. Во всех популярных фреймворках входная единица уже неявно присутствует и не задаётся пользователем отдельно. Поэтому здесь и далее будем считать, что на вход подаётся одно значение.
Несмотря на свою простоту эта архитектура уже позволяет делать линейную регрессию, т.е. приближать функцию прямой линией (часто с минимизацией среднеквадратического отклонения). Пример очень важный, поэтому предлагаю разобрать его максимально подробно.
Как видите, наша простейшая сеть справилась с задачей приближения линейной функции линейной же функцией на ура. Попробуем теперь усложнить задачу, взяв более сложную функцию:
Опять же, результат вполне достойный. Давайте посмотрим на веса нашей модели после обучения:
Первое число — это вес w, второе — смещение b. Чтобы убедиться в этом, давайте нарисуем прямую f(x) = w * x + b:
Усложняем пример
Хорошо, с приближением прямой всё ясно. Но это и классическая линейная регрессия неплохо делала. Как же захватить нейросетью нелинейность аппроксимируемой функции?
Давайте попробуем накидать побольше нейронов, скажем пять штук. Т.к. на выходе ожидается одно значение, придётся добавить ещё один слой к сети, который просто будет суммировать все выходные значения с каждого из пяти нейронов:
И… ничего не вышло. Всё та же прямая, хотя матрица весов немного разрослась. Всё дело в том, что архитектура нашей сети сводится к линейной комбинации линейных функций:
f(x) = w1′ * (w1 * x + b1) +… + w5′ (w5 * x + b5) + b
Т.е. опять же является линейной функцией. Чтобы сделать поведение нашей сети более интересным, добавим нейронам внутреннего слоя функцию активации ReLU (выпрямитель, f(x) = max(0, x)), которая позволяет сети ломать прямую на сегменты:
Максимальное количество сегментов совпадает с количеством нейронов на внутреннем слое. Добавив больше нейронов можно получить более точное приближение:
Дайте больше точности!
Уже лучше, но огрехи видны на глаз — на изгибах, где исходная функция наименее похожа на прямую линию, приближение отстаёт.
В качестве стратегии оптимизации мы взяли довольно популярный метод — SGD (стохастический градиентный спуск). На практике часто используется его улучшенная версия с инерцией (SGDm, m — momentum). Это позволяет более плавно поворачивать на резких изгибах и приближение становится лучше на глаз:
Усложняем дальше
Синус — довольно удачная функция для оптимизации. Главным образом потому, что у него нет широких плато — т.е. областей, где функция изменяется очень медленно. К тому же сама функция изменяется довольно равномерно. Чтобы проверить нашу конфигурацию на прочность, возьмём функцию посложнее:
Увы и ах, здесь мы уже упираемся в потолок нашей архитектуры.
Дайте больше нелинейности!
Давайте попробуем заменить служивший нам в предыдущих примерах верой и правдой ReLU (выпрямитель) на более нелинейный гиперболический тангенс:
Инициализация весов — это важно!
Приближение стало лучше на сгибах, но часть функции наша сеть не увидела. Давайте попробуем поиграться с ещё одним параметром — начальным распределением весов. Используем популярное на практике значение ‘glorot_normal’ (по имени исследователя Xavier Glorot, в некоторых фреймворках называется XAVIER):
Уже лучше. Но использование ‘he_normal’ (по имени исследователя Kaiming He) даёт ещё более приятный результат:
Как это работает?
Давайте сделаем небольшую паузу и разберёмся, каким образом работает наша текущая конфигурация. Сеть представляет из себя линейную комбинацию гиперболических тангенсов:
f(x) = w1′ * tanh(w1 * x + b1) +… + w5′ * tanh(w5 * x + b5) + b
На иллюстрации хорошо видно, что каждый гиперболический тангенс захватил небольшую зону ответственности и работает над приближением функции в своём небольшом диапазоне. За пределами своей области тангенс сваливается в ноль или единицу и просто даёт смещение по оси ординат.
За границей области обучения
Давайте посмотрим, что происходит за границей области обучения сети, в нашем случае это [-3, 3]:
Как и было понятно из предыдущих примеров, за границами области обучения все гиперболические тангенсы превращаются в константы (строго говоря близкие к нулю или единице значения). Нейронная сеть не способна видеть за пределами области обучения: в зависимости от выбранных активаторов она будет очень грубо оценивать значение оптимизируемой функции. Об этом стоит помнить при конструировании признаков и входных данный для нейросети.
Идём в глубину
До сих пор наша конфигурация не являлась примером глубокой нейронной сети, т.к. в ней был всего один внутренний слой. Добавим ещё один:
Можете сами убедиться, что сеть лучше отработала проблемные участки в центре и около нижней границы по оси абсцисс:
N.B. Слепое добавление слоёв не даёт автоматического улучшения, что называется из коробки. Для большинства практических применений двух внутренних слоёв вполне достаточно, при этом вам не придётся разбираться со спецэффектами слишком глубоких сетей, как например проблема исчезающего градиента. Если вы всё-таки решили идти в глубину, будьте готовы много экспериментировать с обучением сети.
Количество нейронов на внутренних слоях
Просто поставим небольшой эксперимент:
Начиная с определённого момента добавление нейронов на внутренние слои не даёт выигрыша в оптимизации. Неплохое практическое правило — брать среднее между количеством входов и выходов сети.
Источник



