
Все виды информации по способу двоичного кодирования
Вся информация, которую обрабатывает компьютер должна быть представлена двоичным кодом с помощью двух цифр 0 и 1. Эти два символа принято называть двоичными цифрами или битами. С помощью двух цифр 0 и 1 можно закодировать любое сообщение. Это явилось причиной того, что в компьютере обязательно должно быть организованно два важных процесса: кодирование и декодирование.
Кодирование – преобразование входной информации в форму, воспринимаемую компьютером, т.е. двоичный код.
Декодирование – преобразование данных из двоичного кода в форму, понятную человеку.
Система счисления — способ записи чисел с помощью набора специальных знаков, называемых цифрами.
| Система счисления | Основание | Алфавит цифр |
| Десятичная | 10 | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 |
| Двоичная | 2 | 0, 1 |
| Восьмеричная | 8 | 0, 1, 2, 3, 4, 5, 6, 7 |
| Шестнадцатеричная | 16 | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F |
Десятичная система счисления — позиционная система счисления по основанию 10. Предполагается, что основание 10 связано с количеством пальцев рук у человека. Наиболее распространённая система счисления в мире. Для записи чисел используются символы 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, называемые арабскими цифрами.
Двоичная система счисления — позиционная система счисления с основанием 2. Используются цифры 0 и 1. Двоичная система используется в цифровых устройствах, поскольку является наиболее простой.
Двоичная система счисления обладает такими же свойствами, что и десятичная, только для представления чисел используются не 10 цифр, а всего две. Соответственно и разряд числа называют не десятичным, а двоичным.
Перевод из десятичной системы счисления в систему счисления с основанием p осуществляется последовательным делением десятичного числа и его десятичных частных на p, а затем выписыванием последнего частного и остатков в обратном порядке.
Переведем десятичное число 20 в двоичную систем счисления (основание системы счисления p=2).
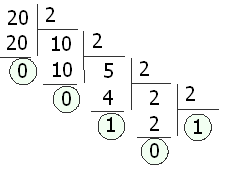 В итоге получили 2010 = 101002.
В итоге получили 2010 = 101002.
Двоичное кодирование текстовой информации
Начиная с 60-х годов, компьютеры все больше стали использовать для обработки текстовой информации и в настоящее время большая часть ПК в мире занято обработкой именно текстовой информации.
Традиционно для кодирования одного символа используется количество информации = 1 байту (1 байт = 8 битов).
Для кодирования одного символа требуется один байт информации.
Учитывая, что каждый бит принимает значение 1 или 0, получаем, что с помощью 1 байта можно закодировать 256 различных символов. (28 = 256)
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный двоичный код от 00000000 до 11111111 (или десятичный код от 0 до 255).
Важно, что присвоение символу конкретного кода – это вопрос соглашения, которое фиксируется кодовой таблицей.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера (коды), называется таблицей кодировки.
Создавать и хранить графические объекты в компьютере можно двумя способами – как растровое или как векторное изображение. Для каждого типа изображений используется свой способ кодирования.
Кодирование растровых изображений
Растровое изображение представляет собой совокупность точек (пикселей) разных цветов. Пиксель — минимальный участок изображения, цвет которого можно задать независимым образом.
В процессе кодирования изображения производится его пространственная дискретизация. Пространственную дискретизацию изображения можно сравнить с построением изображения из мозаики (большого количества маленьких разноцветных стекол). Изображение разбивается на отдельные маленькие фрагменты (точки), причем каждому фрагменту присваивается значение его цвета, то есть код цвета (красный, зеленый, синий и так далее).
Для черно-белого изображения информационный объем одной точки равен одному биту (либо черная, либо белая – либо 1, либо 0).
Для четырех цветного – 2 бита.
Для 8 цветов необходимо – 3 бита.
Для 16 цветов – 4 бита.
Для 256 цветов – 8 бит (1 байт).
Качество изображения зависит от количества точек (чем меньше размер точки и, соответственно, больше их количество, тем лучше качество) и количества используемых цветов (чем больше цветов, тем качественнее кодируется изображение). Растровые изображения очень чувствительны к масштабированию (увеличению или уменьшению). При уменьшении растрового изображения несколько соседних точек преобразуются в одну, поэтому теряется различимость мелких деталей изображения. При увеличении изображения увеличивается размер каждой точки и появляется ступенчатый эффект, который можно увидеть невооруженным глазом.
Кодирование векторных изображений
Векторное изображение представляет собой совокупность графических примитивов (точка, отрезок, эллипс…). Каждый примитив описывается математическими формулами. Кодирование зависит от прикладной среды.
Достоинством векторной графики является то, что файлы, хранящие векторные графические изображения, имеют сравнительно небольшой объем.
Важно также, что векторные графические изображения могут быть увеличены или уменьшены без потери качества.
Источник
Информатика. 7 класс
Конспект урока
Кодирование информации. Двоичный код
Перечень вопросов, рассматриваемых в теме:
- Понятие код.
- Понятие кодирования информации.
- Двоичный код.
Дискретизация информации – процесс преобразования информации из непрерывной формы представления в дискретную. Чтобы представить информацию в дискретной форме, её следует выразить с помощью символов какого-нибудь естественного или формального языка.
Алфавит языка – конечный набор отличных друг от друга символов, используемых для представления информации. Мощность алфавита – это количество входящих в него символов.
Алфавит, содержащий два символа, называется двоичным алфавитом. Представление информации с помощью двоичного алфавита называют двоичным кодированием. Двоичное кодирование универсально, так как с его помощью может быть представлена любая информация.
1. Босова Л. Л. Информатика: 7 класс. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2017. – 226 с.
- Босова Л. Л. Информатика: 7–9 классы. Методическое пособие. // Босова Л. Л., Босова А. Ю., Анатольев А. В., Аквилянов Н.А. – М.: БИНОМ, 2019. – 512 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 1. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 2. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Гейн А. Г. Информатика: 7 класс. // Гейн А. Г., Юнерман Н. А., Гейн А.А. – М.: Просвещение, 2012. – 198 с.
Теоретический материал для самостоятельного изучения
Для решения своих задач человеку часто приходится преобразовывать имеющуюся информацию из одной формы представления в другую. Например, при чтении вслух происходит преобразование информации из дискретной (текстовой) формы в непрерывную (звук). Во время диктанта на уроке русского языка, наоборот, происходит преобразование информации из непрерывной формы (голос учителя) в дискретную (записи учеников).
Информация, представленная в дискретной форме, значительно проще для передачи, хранения или автоматической обработки. Поэтому в компьютерной технике большое внимание уделяется методам преобразования информации из непрерывной формы в дискретную.
Дискретизация информации – процесс преобразования информации из непрерывной формы представления в дискретную.
Рассмотрим суть процесса дискретизации информации на примере.
На метеорологических станциях имеются самопишущие приборы для непрерывной записи атмосферного давления. Результатом их работы являются барограммы – кривые, показывающие, как изменялось давление в течение длительных промежутков времени. Одна из таких кривых, вычерченная прибором в течение семи часов проведения наблюдений, показана на рисунке 1.
На основании полученной информации можно построить таблицу, содержащую показания прибора в начале измерений и на конец каждого часа наблюдений.

Полученная таблица даёт не совсем полную картину того, как изменялось давление за время наблюдений: например, не указано самое большое значение давления, имевшее место в течение четвёртого часа наблюдений. Но если занести в таблицу значения давления, наблюдаемые каждые полчаса или 15 минут, то новая таблица будет давать более полное представление о том, как изменялось давление.
Таким образом, информацию, представленную в непрерывной форме (барограмму, кривую), мы с некоторой потерей точности преобразовали в дискретную форму (таблицу).
В дальнейшем вы познакомитесь со способами дискретного представления звуковой и графической информации.
В общем случае, чтобы представить информацию в дискретной форме, её следует выразить с помощью символов какого-нибудь естественного или формального языка. Таких языков тысячи. Каждый язык имеет свой алфавит.
Алфавит – конечный набор отличных друг от друга символов (знаков), используемых для представления информации. Мощность алфавита – это количество входящих в него символов (знаков).
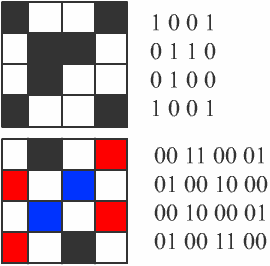
Алфавит, содержащий два символа, называется двоичным алфавитом (рис. 3). Представление информации с помощью двоичного алфавита называют двоичным кодированием. Закодировав таким способом информацию, мы получим её двоичный код.
Рассмотрим в качестве символов двоичного алфавита цифры 0 и 1. Покажем, что любой алфавит можно заменить двоичным алфавитом. Прежде всего, присвоим каждому символу рассматриваемого алфавита порядковый номер. Номер представим с помощью двоичного алфавита. Полученный двоичный код будем считать кодом исходного символа.

Если мощность исходного алфавита больше двух, то для кодирования символа этого алфавита потребуется не один, а несколько двоичных символов. Другими словами, порядковому номеру каждого символа исходного алфавита будет поставлена в соответствие цепочка (последовательность) из нескольких двоичных символов. Правило получения двоичных кодов для символов алфавита мощностью больше двух можно представить схемой на рисунке.

Двоичные символы (0,1) здесь берутся в заданном алфавитном порядке и размещаются слева направо. Двоичные коды (цепочки символов) читаются сверху вниз. Все цепочки (кодовые комбинации) из двух двоичных символов позволяют представить четыре различных символа произвольного алфавита:

Цепочки из трёх двоичных символов получаются дополнением двухразрядных двоичных кодов справа символом 0 или 1. В итоге кодовых комбинаций из трёх двоичных символов получается 8 – вдвое больше, чем из двух двоичных символов:

Соответственно, четырёхразрядный двоичный код позволяет получить 16 кодовых комбинаций, пятиразрядный – 32, шестиразрядный – 64 и т. д.
Длину двоичной цепочки – количество символов в двоичном коде – называют разрядностью двоичного кода.

Обратите внимание, что:
32 = 2 ∙ 2 ∙ 2 ∙ 2 ∙ 2 и т. д.
Здесь количество кодовых комбинаций представляет собой произведение некоторого количества одинаковых множителей, равного разрядности двоичного кода.
Если количество кодовых комбинаций обозначить буквой N, а разрядность двоичного кода – буквой i, то выявленная закономерность в общем виде будет записана так:

В математике такие произведения записывают в виде:
Запись 2 i читают так: «2 в i-й степени».
Задача. Вождь племени Мульти поручил своему министру разработать двоичный код и перевести в него всю важную информацию. Двоичный код какой разрядности потребуется, если алфавит, используемый племенем Мульти, содержит 16 символов? Выпишите все кодовые комбинации.
Решение. Так как алфавит племени Мульти состоит из 16 символов, то и кодовых комбинаций им нужно 16. В этом случае длина (разрядность) двоичного кода определяется из соотношения: 16 = 2 i . Отсюда i = 4.
Чтобы выписать все кодовые комбинации из четырёх 0 и 1, воспользуемся схемой на рис. 1.13: 0000, 0001, 0010, 0011, 0100, 0101, 0110, 0111, 1000, 1001, 1010, 1011, 1100, 1101, 1110, 1111.
Универсальность двоичного кодирования
В начале нашей беседы вы узнали, что информация, представленная в непрерывной форме, может быть выражена с помощью символов некоторого естественного или формального языка. В свою очередь, символы произвольного алфавита могут быть преобразованы в двоичный код. Таким образом, с помощью двоичного кода может быть представлена любая информация на естественных и формальных языках, а также изображения и звуки (рис. 6). Это и означает универсальность двоичного кодирования.

Двоичные коды широко используются в компьютерной технике, требуя только двух состояний электронной схемы – «включено» (это соответствует цифре 1) и «выключено» (это соответствует цифре 0).
Простота технической реализации – главное достоинство двоичного кодирования. Недостаток двоичного кодирования – большая длина получаемого кода.
Равномерные и неравномерные коды
Различают равномерные и неравномерные коды. Равномерные коды в кодовых комбинациях содержат одинаковое число символов, неравномерные – разное.
Выше мы рассмотрели равномерные двоичные коды.
Примером неравномерного кода может служить азбука Морзе, в которой для каждой буквы и цифры определена последовательность коротких и длинных сигналов. Так, букве Е соответствует короткий сигнал («точка»), а букве Ш – четыре длинных сигнала (четыре «тире»). Неравномерное кодирование позволяет повысить скорость передачи сообщений за счёт того, что наиболее часто встречающиеся в передаваемой информации символы имеют самые короткие кодовые комбинации.
Разбор решения заданий тренировочного модуля
№1.Тип задания: ввод с клавиатуры пропущенных элементов в тексте
Переведите десятичное число 273 в двоичную систему счисления.
Воспользуемся алгоритмом перевода целых чисел из системы с основанием p в систему с основанием q:
1. Основание новой системы счисления выразить цифрами исходной системы счисления и все последующие действия производить в исходной системе счисления.
2. Последовательно выполнять деление данного числа и получаемых целых частных на основание новой системы счисления до тех пор, пока не получим частное, меньшее делителя.
3. Полученные остатки, являющиеся цифрами числа в новой системе счисления, привести в соответствие с алфавитом новой системы счисления.
4. Составить число в новой системе счисления, записывая его, начиная с последнего остатка.

Ответ: 27310= 100010001.
№2. Тип задания: единичный / множественный выбор.
Четыре буквы латинского алфавита закодированы кодами различной длины:
Источник



