
- Алгоритмы сортировки на Python
- Искусство наведения порядка
- Сортировка методом пузырька
- Сортировка выбором
- Сортировка вставками
- Марк Лутц «Изучаем Python»
- Сортировка Шелла
- Пирамидальная сортировка («сортировка кучей»)
- Сортировка слиянием
- Быстрая сортировка
- Сортировка подсчетом
- Всё о сортировке в Python: исчерпывающий гайд
- Авторизуйтесь
- Всё о сортировке в Python: исчерпывающий гайд
- Основы сортировки
- Функции-ключи
- Функции модуля operator
- Сортировка по возрастанию и сортировка по убыванию в Python
- Стабильность сортировки и сложные сортировки в Python
- Декорируем-сортируем-раздекорируем
- Использование параметра cmp
- Поддержание порядка сортировки
- Прочее
Алгоритмы сортировки на Python
В этой статье мы вкратце расскажем, какие есть основные алгоритмы сортировки и каковы их главные характеристики. Также по каждому алгоритму покажем реализацию на Python.
Искусство наведения порядка
Сортировка означает размещение элементов в определенном порядке. Этот конкретный порядок определяется свойством сравнения элементов. В случае целых чисел мы говорим, что сначала идет меньшее число, а потом — большее.
Расположение элементов в определенном порядке улучшает поиск элемента. Следовательно, сортировка широко используется в информатике.
В данной статье мы рассмотрим обычные алгоритмы сортировки и их реализации на Python. Для сравнения их производительности мы будем рассматривать задачу с сайта Leetcode о сортировке массива. Размеры данных этой задачи ограничены следующим образом:
Мы решили эту задачу при помощи всех известных алгоритмов сортировки. Вот какие у нас получились результаты:
Сортировка методом пузырька
Это самый простой алгоритм сортировки. В процессе его выполнения мы перебираем наш список и на каждой итерации сравниваем элементы попарно. При необходимости элементы меняются местами, чтобы больший элемент отправлялся в конец списка.
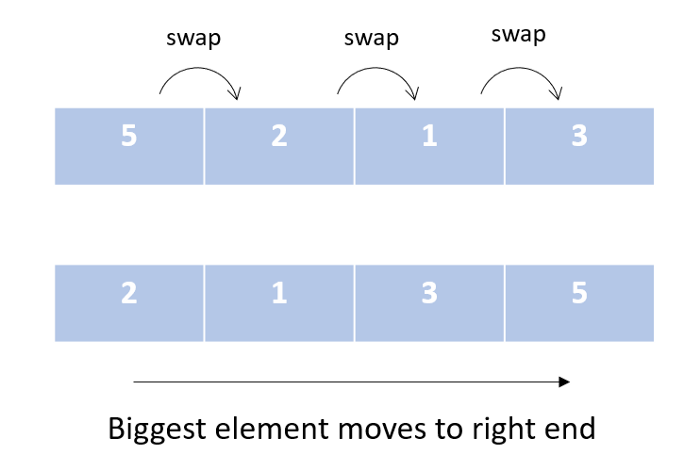
- нерекурсивный;
- устойчивый;
- преобразует входные данные без использования вспомогательной структуры данных (in place);
- имеет сложность O(n 2 );
Сортировка выбором
В этом алгоритме мы создаем два сегмента нашего списка: один отсортированный, а другой несортированный.
В процессе выполнения алгоритма мы каждый раз удаляем самый маленький элемент из несортированного сегмента списка и добавляем его в отсортированный сегмент. Мы не меняем местами промежуточные элементы. Следовательно, этот алгоритм сортирует массив с минимальным количеством перестановок.
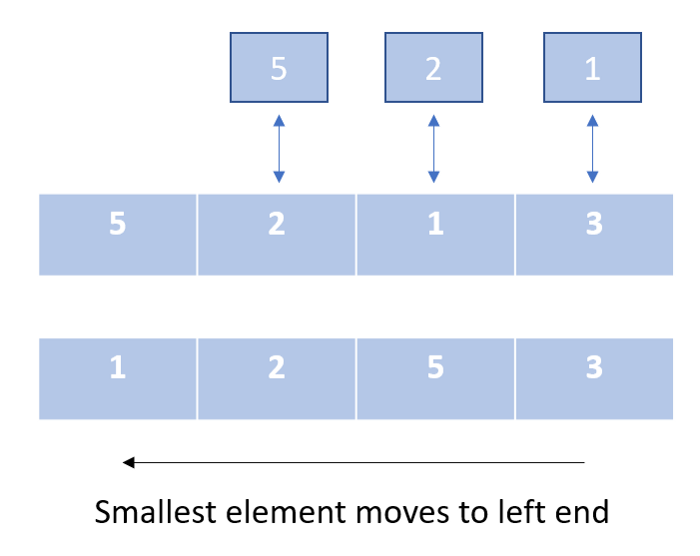
- нерекурсивный;
- может быть как устойчивым, так и неустойчивым;
- преобразует входные данные без использования вспомогательной структуры данных (in place);
- имеет сложность O(n 2 );
Сортировка вставками
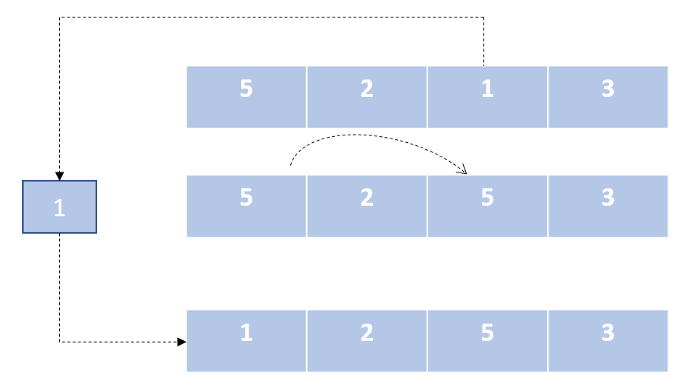
Подобно алгоритму сортировки выбором, мы делим наш список на две части. Далее мы перебираем неотсортированную часть и вставляем каждый элемент из данного сегмента на его правильное место в отсортированной части списка.
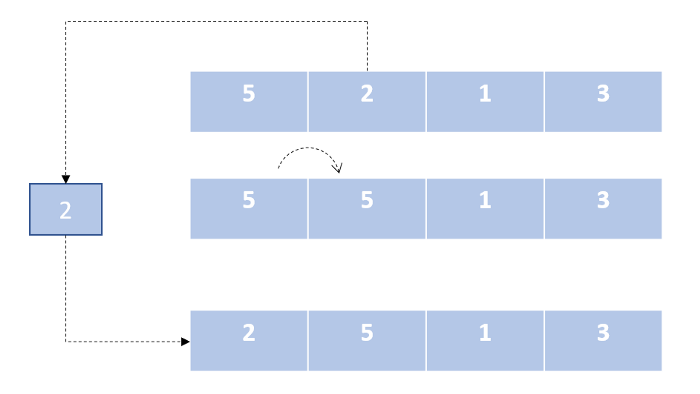
- нерекурсивный;
- устойчивый;
- преобразует входные данные без использования вспомогательной структуры данных (in place);
- имеет сложность O(n 2 );
Марк Лутц «Изучаем Python»
Скачивайте книгу у нас в телеграм
Сортировка Шелла
Сортировка Шелла является оптимизированным вариантом сортировки вставками.
Оптимизация достигается путем сравнения не только соседних элементов, но и элементов на определенном расстоянии, которое в течении работы алгоритма уменьшается. На последней итерации это расстояние равно 1. После этого алгоритм становится обычным алгоритмом сортировки вставками, что гарантирует правильный результат сортировки.
Но следует отметить один момент: к тому времени, когда это произойдет, наш массив будет почти отсортирован, поэтому итерации будут выполнятся очень быстро.
- нерекурсивный;
- устойчивый;
- преобразует входные данные без использования вспомогательной структуры данных (in place);
- имеет сложность O(n 2 ), но это также зависит от выбора длины интервала;
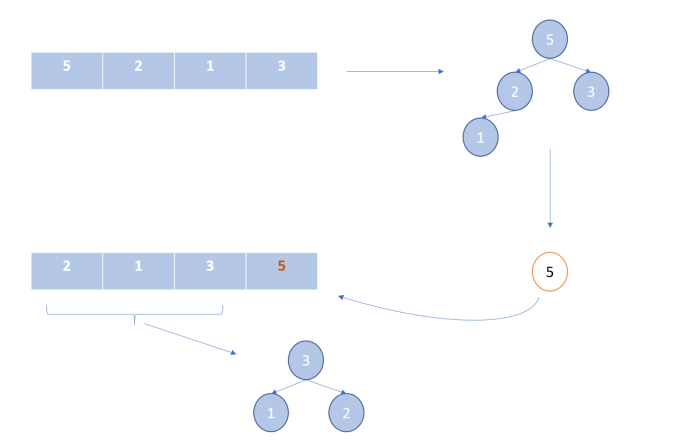
Пирамидальная сортировка («сортировка кучей»)
Как и в двух предыдущих алгоритмах, мы создаем два сегмента списка: отсортированный и несортированный.
В данном алгоритме для эффективного нахождения максимального элемента в неотсортированной части списка мы используем структуру данных «куча».
Метод heapify в примере кода использует рекурсию для получения элемента с максимальным значением на вершине.
- нерекурсивный;
- неустойчивый;
- преобразует входные данные без использования вспомогательной структуры данных (in place);
- имеет сложность O(nlog(n));
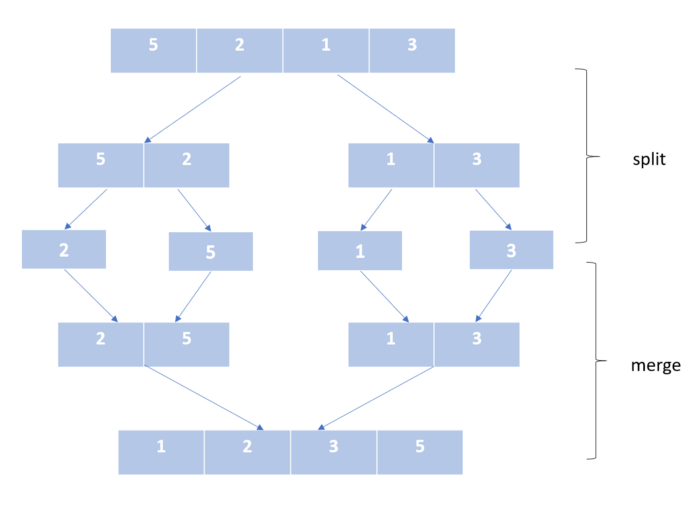
Сортировка слиянием
Этот алгоритм работает по принципу «разделяй и властвуй».
Здесь мы делим список ровно пополам и продолжаем это делать, пока в нем не останется только один элемент. Затем мы объединяем уже упорядоченные части нашего списка. Мы продолжаем это делать, пока не получим отсортированный список со всеми элементами несортированного входного списка.
- рекурсивный;
- устойчивый;
- требует дополнительной памяти;
- имеет сложность O(nlog(n));
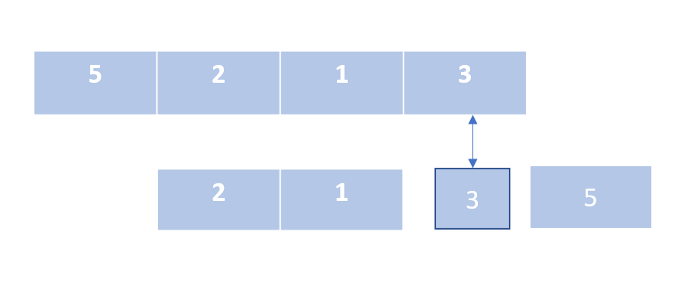
Быстрая сортировка
В этом алгоритме мы разбиваем список при помощи опорного элемента, сортируя значения вокруг него.
В нашей реализации мы выбрали опорным элементом последний элемент массива. Наилучшая производительность достигается тогда, когда опорный элемент делит список примерно пополам.
- рекурсивный;
- неустойчивый;
- преобразует входные данные без использования вспомогательной структуры данных (in place);
- имеет сложность O(nlog(n));
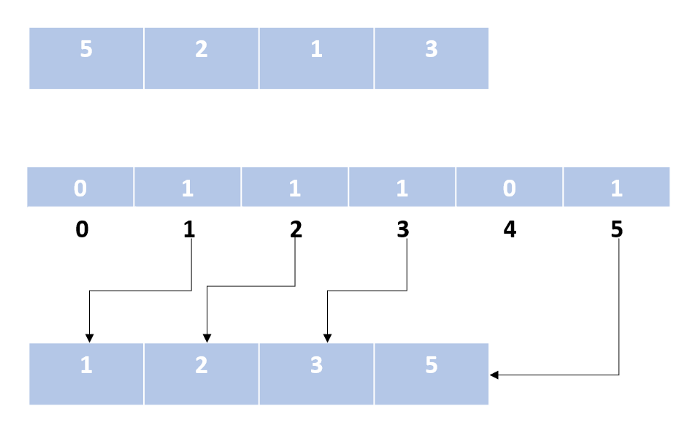
Сортировка подсчетом
Этот алгоритм не производит сравнение элементов. Для сортировки используются математические свойства целых чисел. Мы подсчитываем вхождения числа в массиве и сохраняем результат во вспомогательном массиве, где индексу соответствует значение ключа.
- нерекурсивный;
- устойчивый;
- преобразует входные данные без использования вспомогательной структуры данных (in place), но все же требует дополнительной памяти;
- имеет сложность O(n);
Следует также упомянуть поразрядную сортировку, которая использует сортировку подсчетом либо блочную (корзинную) сортировку в качестве подпрограммы. Этот метод сортировки заслуживает отдельной статьи для разбора.
Для удобства соберем весь наш код вместе:
Испытав все эти алгоритмы, мы ради любопытства запустили встроенную в Python функцию sorted() . Она показала весьма быстрое время в 152 мс. В данной функции используется алгоритм Timsort, который сочетает в себе сортировку слиянием и сортировку вставками. Реализация данного алгоритма также может быть рассмотрена в отдельной статье.
Мы нашли потрясающий плейлист, в котором алгоритмы сортировки демонстрируются при помощи народного танца. Посмотрите это видео, оно того стоит!
В нашем небольшом исследовании мы изучили различные алгоритмы сортировки и определили время их выполнения, а также их потребности в памяти. Теперь мы понимаем, что значит время выполнения, стабильность алгоритма и используемая память. Чтобы выбрать подходящий алгоритм, мы должны оценивать эти параметры. Также, для создания более эффективных решений, типа Timsort, мы можем комбинировать наши базовые алгоритмы.
Источник
Всё о сортировке в Python: исчерпывающий гайд
Авторизуйтесь
Всё о сортировке в Python: исчерпывающий гайд
Сортировка в Python выполняется функцией sorted() , если это итерируемые объекты, и методом list.sort() , если это список. Рассмотрим подробнее, как это работало в старых версиях и как работает сейчас.
Примечание Вы читаете улучшенную версию некогда выпущенной нами статьи.
Основы сортировки
Для сортировки по возрастанию достаточно вызвать функцию сортировки Python sorted() , которая вернёт новый отсортированный список:
Также можно использовать метод списков list.sort() , который изменяет исходный список (и возвращает None во избежание путаницы). Обычно это не так удобно, как использование sorted() , но если вам не нужен исходный список, то так будет немного эффективнее:
Прим.перев. В Python вернуть None и не вернуть ничего — одно и то же.
Ещё одно отличие заключается в том, что метод list.sort() определён только для списков, в то время как sorted() работает со всеми итерируемыми объектами:
Прим.перев. При итерировании по словарю Python возвращает его ключи. Если вам нужны их значения или пары «ключ-значение», используйте методы dict.values() и dict.items() соответственно.
Рассмотрим основные функции сортировки Python.
Функции-ключи
С версии Python 2.4 у list.sort() и sorted() появился параметр key для указания функции, которая будет вызываться на каждом элементе до сравнения. Вот регистронезависимое сравнение строк:
Значение key должно быть функцией, принимающей один аргумент и возвращающей ключ для сортировки. Работает быстро, потому что функция-ключ вызывается один раз для каждого элемента.
Часто можно встретить код, где сложный объект сортируется по одному из его индексов. Например:
Тот же метод работает для объектов с именованными атрибутами:
Функции модуля operator
Показанные выше примеры функций-ключей встречаются настолько часто, что Python предлагает удобные функции, чтобы сделать всё проще и быстрее. Модуль operator содержит функции itemgetter() , attrgetter() и, начиная с Python 2.6, methodcaller() . С ними всё ещё проще:
Функции operator дают возможность использовать множественные уровни сортировки в Python. Отсортируем учеников сначала по оценке, а затем по возрасту:
Используем функцию methodcaller() для сортировки учеников по взвешенной оценке:
Сортировка по возрастанию и сортировка по убыванию в Python
У list.sort() и sorted() есть параметр reverse , принимающий boolean-значение. Он нужен для обозначения сортировки по убыванию. Отсортируем учеников по убыванию возраста:
Стабильность сортировки и сложные сортировки в Python
Начиная с версии Python 2.2, сортировки гарантированно стабильны: если у нескольких записей есть одинаковые ключи, их порядок останется прежним. Пример:
Обратите внимание, что две записи с ‘blue’ сохранили начальный порядок. Это свойство позволяет составлять сложные сортировки путём постепенных сортировок. Далее мы сортируем данные учеников сначала по возрасту в порядке возрастания, а затем по оценкам в убывающем порядке, чтобы получить данные, отсортированные в первую очередь по оценке и во вторую — по возрасту:
Алгоритмы сортировки Python вроде Timsort проводят множественные сортировки так эффективно, потому что может извлечь пользу из любого порядка, уже присутствующего в наборе данных.
Декорируем-сортируем-раздекорируем
- Сначала исходный список пополняется новыми значениями, контролирующими порядок сортировки.
- Затем новый список сортируется.
- После этого добавленные значения убираются, и в итоге остаётся отсортированный список, содержащий только исходные элементы.
Вот так можно отсортировать данные учеников по оценке:
Это работает из-за того, что кортежи сравниваются лексикографически, сравниваются первые элементы, а если они совпадают, то сравниваются вторые и так далее.
Не всегда обязательно включать индекс в декорируемый список, но у него есть преимущества:
- Сортировка стабильна — если у двух элементов одинаковый ключ, то их порядок не изменится.
- У исходных элементов не обязательно должна быть возможность сравнения, так как порядок декорированных кортежей будет определяться максимум по первым двум элементам. Например, исходный список может содержать комплексные числа, которые нельзя сравнивать напрямую.
Ещё эта идиома называется преобразованием Шварца в честь Рэндела Шварца, который популяризировал её среди Perl-программистов.
Для больших списков и версий Python ниже 2.4, «декорируем-сортируем-раздекорируем» будет оптимальным способом сортировки. Для версий 2.4+ ту же функциональность предоставляют функции-ключи.
Использование параметра cmp
Все версии Python 2.x поддерживали параметр cmp для обработки пользовательских функций сравнения. В Python 3.0 от этого параметра полностью избавились. В Python 2.x в sort() можно было передать функцию, которая использовалась бы для сравнения элементов. Она должна принимать два аргумента и возвращать отрицательное значение для случая «меньше чем», положительное — для «больше чем» и ноль, если они равны:
Можно сравнивать в обратном порядке:
При портировании кода с версии 2.x на 3.x может возникнуть ситуация, когда нужно преобразовать пользовательскую функцию для сравнения в функцию-ключ. Следующая обёртка упрощает эту задачу:
Чтобы произвести преобразование, оберните старую функцию:
В Python 2.7 функция cmp_to_key() была добавлена в модуль functools.
Поддержание порядка сортировки
В стандартной библиотеке Python нет модулей, аналогичных типам данных C++ вроде set и map . Python делегирует эту задачу сторонним библиотекам, доступным в Python Package Index: они используют различные методы для сохранения типов list , dict и set в отсортированном порядке. Поддержание порядка с помощью специальной структуры данных может помочь избежать очень медленного поведения (квадратичного времени выполнения) при наивном подходе с редактированием и постоянной пересортировкой данных. Вот некоторые из модулей, реализующих эти типы данных:
- SortedContainers — реализация сортированных типов list , dict и set на чистом Python, по скорости не уступает реализациям на C. Тестирование включает 100% покрытие кода и многие часы стресс-тестирования. В документации можно найти полный справочник по API, сравнение производительности и руководства по внесению своего вклада.
- rbtree — быстрая реализация на C для типов dict и set . Реализация использует структуру данных, известную как красно-чёрное дерево.
- treap — сортированный dict . В реализации используется Декартово дерево, а производительность улучшена с помощью Cython.
- bintrees — несколько реализаций типов dict и set на основе деревьев на C. Самые быстрые основаны на АВЛ и красно-чёрных деревьях. Расширяет общепринятый API для предоставления операций множеств для словарей.
- banyan — быстрая реализация dict и set на C.
- skiplistcollections — реализация на чистом Python, основанная на списках с пропусками, предлагает ограниченный API для типов dict и set .
- blist — предоставляет сортированные типы list , dict и set , основанные на типе данных «blist», реализация на Б-деревьях. Написано на Python и C.
Прочее
Для сортировки с учётом языка используйте locale.strxfrm() в качестве ключевой функции или locale.strcoll() в качестве функции сравнения. Параметр reverse всё ещё сохраняет стабильность сортировки. Этот эффект можно сымитировать без параметра, использовав встроенную функцию reversed() дважды:
Чтобы создать стандартный порядок сортировки для класса, просто добавьте реализацию соответствующих методов сравнения:
Источник



