
- Типы баз данных по способу сохранения данных
- Классификация баз данных
- Вступление
- Классификация баз данных пи типу хранимых данных
- Классификация баз данных по обращению к ним
- Классификация БД по способу организации данных
- Модели БД
- Реляционная база данных
- Другие статьи раздела: База данных
- Что такое база данных — понятие база данных в информатике
- Функции СУБД обеспечивающие управление базой данных
- PhpMyAdmin на локальном сервере
- Что такое База Данных (БД)
- Содержание
- Что такое база данных
- Как она выглядит
- Как получить информацию из базы
- Как связать данные между собой
Типы баз данных по способу сохранения данных
Классификация баз данных
По типу хранимой информации БД делятся на
- документальные,
- фактографические и
- лексикографические.
Среди документальных баз различают библиографические, реферативные и полнотекстовые.
К лексикографическим базам данных относятся различные словари (классификаторы, многоязычные словари, словари основ слов и т. п.).
В системах фактографического типа в БД хранится информация об интересующих пользователя объектах предметной области в виде «фактов» (например, биографические данные о сотрудниках, данные о выпуске продукции производителями и т.п.); в ответ на запрос пользователя выдается требуемая информация об интересующем его объекте (объектах) или сообщение о том, что искомая информация отсутствует в БД.
В документальных БД единицей хранения является какой-либо документ (например, текст закона или статьи), и пользователю в ответ на его запрос выдается либо ссылка на документ, либо сам документ, в котором он может найти интересующую его информацию.
БД документального типа могут быть организованы по- разному: без хранения и с хранением самого исходного документа на машинных носителях. К системам первого типа можно отнести библиографические и реферативные БД, а также БД- указатели, отсылающие к источнику информации. Системы, в которых предусмотрено хранение полного текста документа, называются полнотекстовыми.
В системах документального типа целью поиска может быть не только какая-то информация, хранящаяся в документах, но и сами документы. Так, возможны запросы типа «сколько документов было создано за определенный период времени» и т. п. Часто в критерий поиска в качестве признаков включаются «дата принятия документа», «кем принят» и другие «выходные данные» документов.
Специфической разновидностью баз данных являются базы данных форм документов. Они обладают некоторыми чертами документальных систем (ищется документ, а не информация о конкретном объекте, форма документа имеет название, по которому обычно и осуществляется его поиск), и специфическими особенностями (документ ищется не с целью извлечь из него информацию, а с целью использовать его в качестве шаблона).
В последние годы активно развивается объектно- ориентированный подход к созданию информационных систем. Объектные базы данных организованы как объекты и ссылки к объектам. Объект представляет собой данные и правила, по которым осуществляются операции с этими данными. Объект включает метод, который является частью определения объекта и запоминается вместе с объектом. В объектных базах данных данные запоминаются как объекты, классифицированные по типам классов и организованные в иерархическое семейство классов. Класс — коллекция объектов с одинаковыми свойствами. Объекты принадлежат классу. Классы организованы в иерархии.
По характеру организации хранения данных и обращения к ним различают
- локальные (персональные),
- общие (интегрированные, централизованные) и
- распределенные базы данных
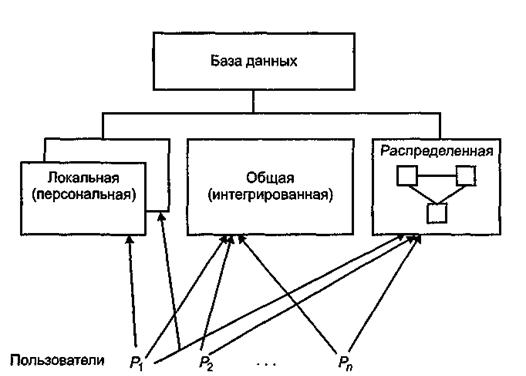
Персональная база данных — это база данных, предназначенная для локального использования одним пользователем. Локальные БД могут создаваться каждым пользователем самостоятельно, а могут извлекаться из общей БД.
Интегрированные и распределенные БД предполагают возможность одновременного обращения нескольких пользователей к одной и той же информации (многопользовательский, параллельный режим доступа). Это привносит специфические проблемы при их проектировании и в процессе эксплуатации БнД. Распределенные БД, кроме того, имеют характерные особенности, связанные с тем, что физически разные части БД могут быть расположены на разных ЭВМ, а логически, с точки зрения пользователя, они должны представлять собой единое целое.
БД классифицируются по объему. Особое место здесь занимают так называемые очень большие базы данных. Это вызвано тем, что для больших баз данных по-иному ставятся вопросы обеспечения эффективности хранения информации и обеспечения ее обработки.
По характеру организации данных БД могут быть разделены на
- неструктурированные,
- частично структурированные и
- структурированные.
Этот классификационный признак относится к информации, представленной в символьном виде. К неструктурированным БД могут быть отнесены базы, организованные в виде семантических сетей. Частично структурированными можно считать базы данных в виде обычного текста или гипертекстовые системы. Структурированные БД требуют предварительного проектирования и описания структуры БД. Только после этого базы данных такого типа могут быть заполнены данными.
Структурированные БД, в свою очередь, по типу используемой модели делятся на
- иерархические,
- сетевые,
- реляционные,
- смешанные и
- мультимодельные.
Классификация по типу модели распространяется не только на базы данных, но и на СУБД.
Иерархические, сетевые, реляционные
Источник
Классификация баз данных
Вступление
Напомню, что база данных это большой объем данных, которая в ней хранится, может обрабатываться, дополняться, удаляться, причем в удобной для пользователя форме. Также нужно четко понимать, что в БД хранится не всякая информация, а информация, которую можно организовать по тем или иным свойствам. Например, большое количество различных фотографий или документов это не данные, а информация. Но мы можем организовать фотографии, например по сути: фото людей, фото животных, фото городов и т.д. или организовать их по размеру: большие, средние, маленькие. Организованная, таким образом информация превращается в данные и пригодна для автоматической обработки с использованием баз данных. Переходим к классификации баз данных.

Классификация баз данных пи типу хранимых данных
Базы данных, объединяющие документы, сгруппированные (организованные) по разным свойствам, классифицируются, как документальные БД.
Под документом понимается текстовой документ или ссылка на него. Документальные БД разделили по типу документов на полнотекстовые, реферативные (рефераты) и библиографические. Это деление не так важно, как важен способ хранения информации. Здесь следующее разделение: базы данных хранящие исходный документ или хранящие ссылки, по которым можно обратиться к исходному документу.
Фактографические БД объединяют данные по факту совершения события (дата выпуска товара, год рождения сотрудника).
Лексикографические БД объединяют словари, классификаторы, и т.л. документы.
Характерным примером, документальных баз данных могут послужить базы объединяющие документы по нормативным «формам». Вы встречались с такими документами, например в паспортом столе или отделе кадров, заполняя «бумажку» по форме № такой то.
Классификация баз данных по обращению к ним
Базы данных индивидуального пользования классифицируют, как персональные или локальные базы данных.
Интегрированные иначе централизованные базы данный предоставляют коллективный доступ к данным. Такой доступ может быть как многопользовательский (сразу все), так и параллельный (независимый).
Распределительные базы данных аналогичны интегрированным, но могут быть физически разнесены на разные машины, и при этом логически считаться единым целым.
Перечисленные выше классификации не особо интересны пользователям. Для пользователя интересна классификация по способу организации данных и по типу используемой модели.
Классификация БД по способу организации данных
Не буду останавливаться на неструктурированных и частично структурированных базах данных. Они имеют узкое применение. Более важно понятие структурированной базы данных, в которых данные хранятся по предварительно спроектированной модели.
Модели БД
Моделями структурированной БД могут быть:
- БД иерархической модели;
- Сетевой модели;
- И самой используемой моделью БД – реляционной базой данных.
Реляционная база данных
Реляционная база данных самая используемая и самая математическая модель БД. Эта модель используется везде, где есть формализованная информация. Основа этой модели таблица, а взаимоотношения данных происходят по «доменам», «атрибутам», «кортежам» или более понятно и знакомо, по «типам данных», «столбцам» и «строкам».
В завершении замечу, что классификации БД перечисленных в статье, с уверенностью применяются для классификации СУБД.
Другие статьи раздела: База данных

Что такое база данных — понятие база данных в информатике
Содержание статьи: Что такое база данных в информатикеЧто такое СУБД и SQLСУБД MySQLСтатьи по теме “База данных” Информация основа современного общества. Объем ее огромен и растет с каждым годом. Огромный объем информации уже давно поставил задачу ее хранения и обработки. Решает эту задачу понятие база данных. Похожие статьи: Что такое целевой рынок, как его найти […]

Функции СУБД обеспечивающие управление базой данных
В этой статье вы познакомитесь с основными функциями СУБД системами управления базами данных.

PhpMyAdmin на локальном сервере
В этой статье мы рассматриваем работу с phpMyAdmin на локальном сервере, то есть в рамках настольного компьютера.
Источник
Что такое База Данных (БД)
База данных — это место для хранения данных. Используется в том числе в клиент-серверной архитектуре. Это все интернет-магазины, сайты кинотеатров или авиабилетов. Вы делаете заказ, а система сохраняет ваши данные в базе.

В этот статье я на простых примерах расскажу, что такое база данных и как она выглядит. А потом поясню некоторые термины из конкретной (реляционной) базы. Те, с которыми вы почти наверняка столкнетесь на работу.
Статья рассчитана на начинающих тестировщиков или аналитиков, то есть тех, кто будет работать с базой, но не на супер-глубоком уровне. Она для тех, кто только входит в мир ИТ, и многого не знает. Она объясняет, что это за звено в клиент-серверной архитектуре такое, и зачем оно нужно.
Содержание
Что такое база данных
База данных — хранилище, куда приложение складывает свои данные. Если приложение небольшое, отдельная база не нужна. Но потом это становится удобнее и выгоднее с точки зрения памяти.
Катя решила открыть свой магазинчик. Она нашла хорошую марку обуви, которую «днем с огнем» не сыскать в ее городе. Заказала оптовую партию и стала потихоньку распродавать через знакомых. Пришлось освободить половину шкафа под коробки, но вроде всё поместилось.
Обувь хорошая, в розницу заказывать в других местах невыгодно — и вот уже у Кати есть постоянные клиенты, которые приводят друзей. Как только какая-то пара заканчивается, Катя делает новый заказ.
Но покупатели хотят новинок, разных размеров. Да и самих покупателей становится все больше и больше. В шкаф коробки уже не влезают!
Теперь, если покупатель просит определенную пару, Катьке сложно её найти. Пока коробок было мало, она помнила наизусть, где что лежит. А теперь уже нет, да и все попытки организовать систему провалились. Места мало, да и детки любят с коробками поиграть.
Тогда Катька решила арендовать складское помещение. И вот теперь красота! Не надо теснить своих домашних, дома чисто и свободно! И на складе место есть, появилась система — тут босоножки, тут сапоги.
Чем больше объемы производства, тем больше нужно места. Если в начале пути склад не нужен, всё поместится дома, то потом это будет оправданно.
Тоже самое и в приложениях. Если приложение маленькое, то все данные можно хранить в памяти. Но учтите, что это память на вашем компьютере, вашем телефоне. И чем больше данных туда пихать, тем медленнее будет работать программа.
Место в памяти ограничено. Поэтому когда данных много, их нужно куда-то сложить. Можно писать в файлики, а можно сохранять информацию в базу данных (сокращенно БД). Выбор за вами. А точнее, за вашим разработчиком.
Как она выглядит
Да примерно как excel-табличка! Есть колонки с заголовками, и информация внутри:
Это называется реляционная база данных — набор таблиц, хранящихся в одном пространстве.
Что за пространство? Ну вот представьте, что вы храните все данные в excel. Можно запихать всю-всю-всю информацию в одну огро-о-о-о-мную таблицу, но это неудобно. Обычно табличек несколько: тут информация по клиентам, там по заказам, а тут по адресам. Эти таблицы удобно хранить в одном месте, поэтому кладем их в отдельную папочку:
Так вот пространство внутри базы данных — это та же самая папочка в винде. Место, куда мы сложили свои таблички, чтобы они все были в одном месте.
Пример базы Oracle
Цель та же — выделить отдельное место, чтобы у вас не была одна большая свалка:
заходишь в папку в винде → видишь файлики только из этой папки
заходишь в пространство → видишь только те таблицы, которые в нем есть
Хранение данных в виде табличек — это не единственно возможный вариант. Вот вам для примера запись из таблицы в системе Users. Там используется MongoDB база данных, она не реляционная. Поэтому вместо таблички «словно в excel» каждая запись хранится в виде объекта, вот так:
А еще есть файловые базы — когда у вас вся информация хранится в файликах. Да-да, простых текстовых файликах!
Почитать о разных видах баз данных можно в википедии. Я не буду в этой статье углубляться в эту тему, потому что моя задача — объяснить «что это вообще такое» для ребят, которые базу в глаза не видели. А на работе они скорее всего столкнутся именно с реляционной базой данных, поэтому о ней и речь.
Да, базы бывают разные. Классификацию можно изучить, можно выучить. Но по факту от начинающего тестировщика обычно нужно уметь достать информацию из реляционной БД («обычно» != «всегда», если что).
Как получить информацию из базы
Нужно записать свой запрос в понятном для базы виде — на SQL. SQL (Structured Query Language) — язык общения с базой данных. В нем есть ключевые слова, которые помогут вам сделать выборку:
select — выбери мне такие-то колонки.
from — из такой-то таблицы базы.
where — такую-то информацию.
Например, я хочу получить информацию по клиенту «Назина Ольга». Составляю в уме ТЗ:
Переделываю в SQL:
В дословном переводе:
Комментарии в Oracle/PLSQL — мой перевод остается работающим запросом, потому что я убрала «лишнее» в комментарии
Если бы у меня была не база данных, а простые excel-файлики, то же действие было бы:
Открыть файл с нужными данными (clients)
Поставить фильтр на колонку «ФИО» — «Назина Ольга».
То есть нам в любом случае надо знать название таблицы, где лежат данные, и название колонки, по которой фильтруем. Это не что-то страшное, что есть только в базе данных. Тоже самое есть в простом экселе.
Бывают запросы и сложнее — когда надо достать данные не из одной таблицы, а из разных. В базе это будет выглядеть даже лучше, чем в эксельке. В экселе вам нужно открыть 1-2-3 таблицы и смотреть в каждую. Неудобно.
А в базе данных вы внутри запроса SQL указываете, какие колонки из каких таблиц вам нужны. И результат запроса их отрисовывает. Скажем, мы хотим увидеть заказ, который сделал клиент, ФИО клиента, и его номер телефона. И всё это в разных таблицах! А мы написали запрос и увидели то, что нам надо:
id_order
order (таблица order)
fio (таблица client)
phone (таблица contacts)
И пусть в таблице клиентов у нас будет 30 колонок, а в таблице заказов 50, в результате выборки мы видим ровно 4 запрошенные. Удобно, ничего лишнего!
Конечно, написать такой запрос будет немного сложнее обычного селекта. Это уже select join, почитать о нем можно тут. И я рекомендую вам его изучить, потому что он входит в «базовое знание sql», которое требуется на собеседованиях.
Результаты выборки можно группировать, сортировать — это следующий уровень сложности. См раздел «статьи и книги по теме» для получения большей информации.
Как связать данные между собой
Вот например, у нас есть интернет-магазин по доставке пиццы. Так выглядит его база данных:
В таблице «client» лежат данные по клиентам: ФИО, пол, дата рождения и т.д.
last_name
first_name
birthdate
VIP
В таблице «orders» лежат данные по заказам. Что заказали (пиццу, суши, роллы), когда, насколько довольны доставкой?
order
addr
date
time
Роллы «Филадельфия» и «Канада»
Студеный пр-д, д 10
Пицца 35 см, роллы комбо 1
Пицца с сосиками по краям
Комбо набор 3, обед №4
Но как понять, где чей был заказ? Сколько раз заказывал Вася, а сколько Алина?
Тут есть несколько вариантов:
1. Запихать все данные в одну таблицу: тут и заказы, и информация по клиентам. В целом удобно, открыл табличку и сразу видишь — ага, это Васин заказ, а это Машин.
Таблица все растет и растет, в итоге получается просто огромной! А когда данных много, легкость чтения пропадает, придется листать до нужной колонки.
Поиск будет работать медленнее. Чем меньше информации в таблице, тем быстрее поиск. Когда у нас много строк, количество колонок становится существенным.
Много дублей — один человек может сделать хоть сотню заказов. И вся информация по нему будет продублирована сто раз. Неоптимальненько!
Чтобы избежать дублей, таблицы принято разделять:
Новые объекты отдельно
Но надо при этом их как-то связать между собой, мы ведь всё еще хотим знать, чей конкретно был заказ. Для связи таблиц используется foreign key, внешний ключ.
Нам надо у заказа сделать отметку о клиенте. Значит, таблица «orders» будет ссылаться на таблицу «clients». Ключ можно поставить на любую колонку таблицы (в некоторых базах колонка должна быть уникальной, сначала её нужно такой указать). Какую бы выбрать?
Можно ссылаться на имя. А что, миленько, в таблице заказов будем сразу имя видеть! Но минуточку. А если у нас два клиента Ивана? Или три Маши? Десять Саш. Ну вы поняли =) И как тогда разобраться, где какой клиент? Не подходит!
Можно вешать foreign key на несколько колонок. Например, на фамилию + имя, или фамилию + имя + отчество. Но ведь и ФИО бывают неуникальные! Что тогда? Можно добавить в связку дату рождения. Тогда шанс ошибиться будет минимален, хотя и такие ребята существуют. И чем больше клиентов у вас будет, тем больше шанс встретить дубликат.
А можно не усложнять! Вместо того, чтобы делать внешний ключ на 10 колонок, лучше создать в таблице клиентов primary key, первичный ключ. Первичный ключ отвечает за то, чтобы каждое значение в поле было уникальным, никаких дублей. При попытке добавить в таблицу запись с неуникальным первичным ключом получаешь ошибку:
Здесь ключ — «id_order»
Вот на него и нужно ссылаться! Обычно таким ключом является ID, идентификатор записи. Его можно сделать автоинкрементальным — это значит, что он генерируется сам по алгоритму «прошлое значение + 1».
Например, у нас гостиница для котиков. Это когда хозяева едут в отпуск, а котика оставить не с кем — оставляем в гостинице!
Источник



