
Теория графов. Часть третья (Представление графа с помощью матриц смежности, инцидентности и списков смежности)
Все, что познается, имеет число, ибо невозможно ни понять ничего, ни познать без него – Пифагор
Список смежности (инцидентности)
Взвешенный граф (коротко)
Итак, мы умеем задавать граф графическим способом. Но есть еще два способа как можно задавать граф, а точнее представлять его. Для экономии памяти в компьютере граф можно представлять с помощью матриц или с помощью списков.
Матрица является удобной для представления плотных графов, в которых число ребер близко к максимально возможному числу ребер (у полного графа).
Другой способ называется списком. Данный способ больше подходит для более разреженных графов, в котором число ребер намного меньше максимально возможного числа ребер (у полного графа).
Перед чтением материала рекомендуется ознакомится с предыдущей статьей, о смежности и инцидентности, где данные определения подробно разбираются.
Матрица смежности
Но тем кто знает, но чуть забыл, что такое смежность есть краткое определение.
Смежность – понятие, используемое только в отношении двух ребер или в отношении двух вершин: два ребра инцидентные одной вершине, называются смежными; две вершины, инцидентные одному ребру, также называются смежными.
Матрица (назовем ее L) состоит из n строк и n столбцов и поэтому занимает n^2 места.
Каждая ячейка матрицы равна либо 1, либо 0;
Ячейка в позиции L (i, j) равна 1 тогда и только тогда, когда существует ребро (E) между вершинами (V) i и j. Если у нас положение (j, i), то мы также сможем использовать данное правило. Из этого следует, что число единиц в матрице равно удвоенному числу ребер в графе. (если граф неориентированный). Если ребра между вершинами i и j не существует, то ставится 0.
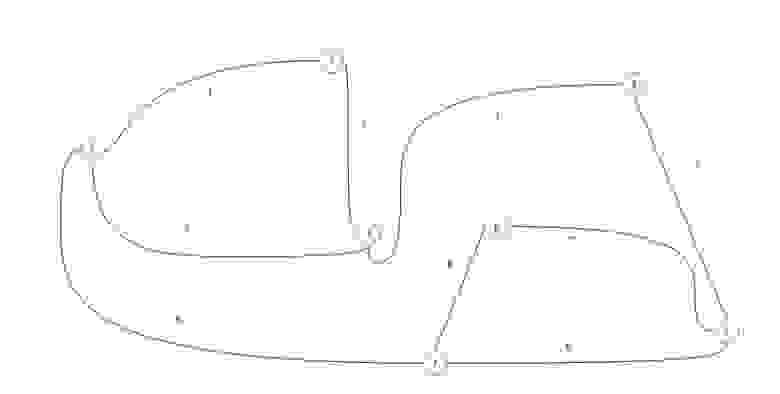
Для практического примера возьмем самый обыкновенный неориентированный граф:
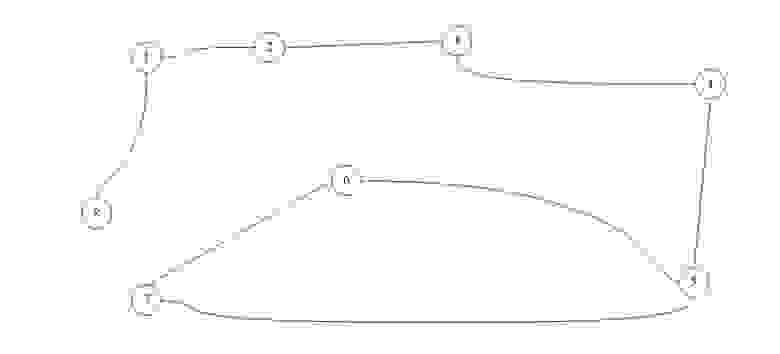
А теперь представим его в виде матрицы:
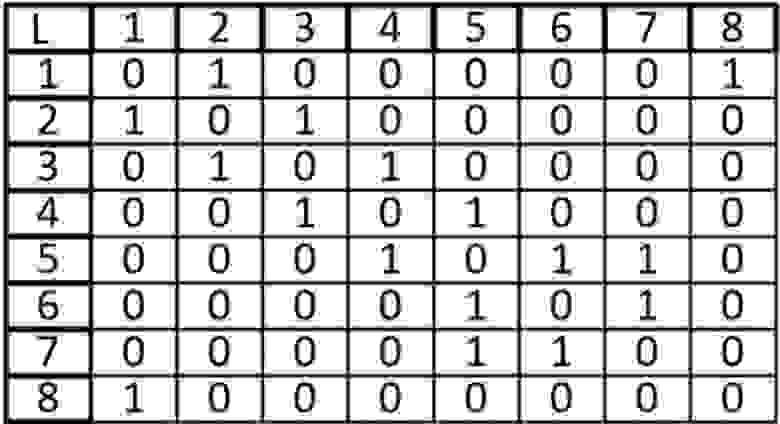
Ячейки, расположенные на главной диагонали всегда равны нулю, потому что ни у одной вершины нет ребра, которое и начинается, и заканчивается в ней только если мы не используем петли. То есть наша матрица симметрична относительно главной диагонали. Благодаря этому мы можем уменьшить объем памяти, который нам нужен для хранения.
С одной стороны объем памяти будет:

Но используя вышеописанный подход получается:

Потому что нижнюю часть матрицы мы можем создать из верхней половины матрицы. Только при условии того, что у нас главная диагональ должна быть пустой, потому что при наличии петель данное правило не работает.
Если граф неориентированный, то, когда мы просуммируем строку или столбец мы узнаем степень рассматриваемой нами вершины.
Если мы используем ориентированный граф, то кое-что меняется.
Здесь отсутствует дублирование между вершинами, так как если вершина 1 соединена с вершиной 2, наоборот соединена она не может быть, так у нас есть направление у ребра.
Возьмем в этот раз ориентированный граф и сделаем матрицу смежности для него:
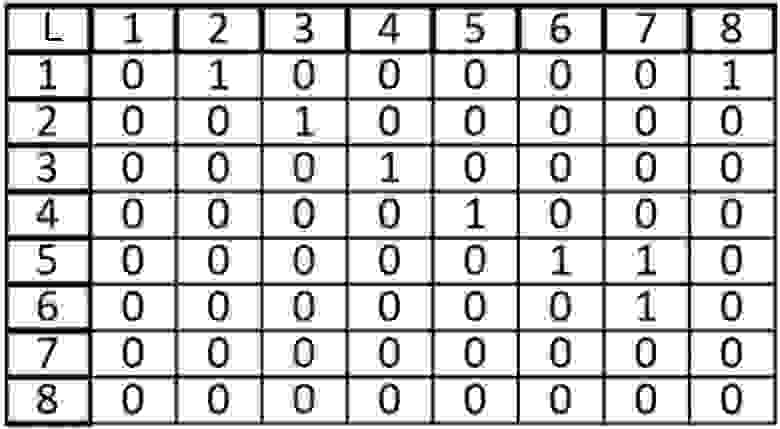
Если мы работаем со строкой матрицы, то мы имеем элемент из которого выходит ребро, в нашем случаи вершина 1 входит в вершину 2 и 8. Когда мы работаем со столбцом то мы рассматриваем те ребра, которые входят в данную вершину. В вершину 1 ничего не входит, значит матрица верна.

Если бы на главной диагонали была бы 1, то есть в графе присутствовала петля, то мы бы работали уже не с простым графом, с каким мы работали до сих пор.
Используя петли мы должны запомнить, что в неориентированном графе петля учитывается дважды, а в ориентированном — единожды.
Матрица инцидентности
Инцидентность – понятие, используемое только в отношении ребра и вершины: две вершины (или два ребра) инцидентными быть не могут.
Матрица (назовем ее I) состоит из n строк которое равно числу вершин графа, и m столбцов, которое равно числу ребер. Таким образом полная матрица имеет размерность n x m. То есть она может быть, как квадратной, так и отличной от нее.
Ячейка в позиции I (i, j) равна 1 тогда, когда вершина инцидентна ребру иначе мы записываем в ячейку 0, такой вариант представления верен для неориентированного графа.
Сразу же иллюстрируем данное правило:
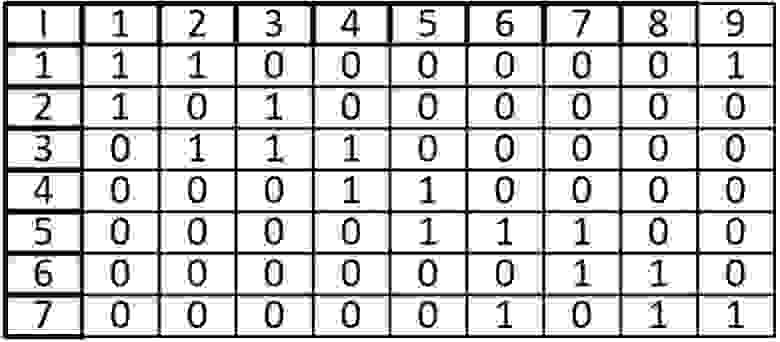
Сумма элементов i-ой строки равна степени вершины.
При ориентированным графе, ячейка I (i, j) равна 1, если вершина V (i) начало дуги E(j) и ячейка I (i, j) равна -1 если вершина V (i) конец дуги E (j), иначе ставится 0.
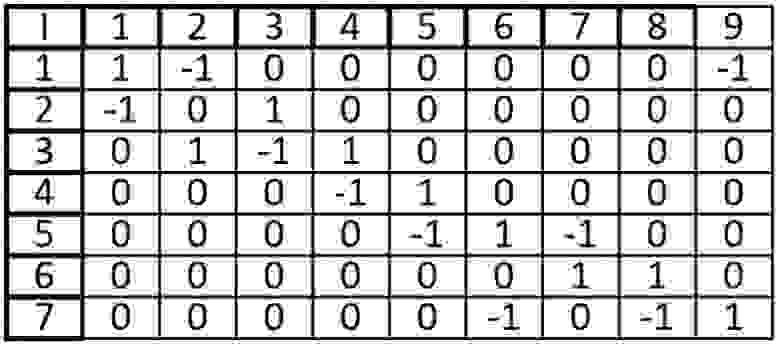
Одной из особенностей данной матрицы является то, что в столбце может быть только две ненулевых ячейки. Так как у ребра два конца.
При суммировании строки, ячейки со значением -1, могут складываться только с ячейками, также имеющими значение -1, то же касается и 1, мы можем узнать степень входа и степень выхода из вершины. Допустим при сложении первой вершины, мы узнаем, что из нее исходит 1 ребро и входят два других ребра. Это является еще одной особенностью (при том очень удобной) данной матрицы.

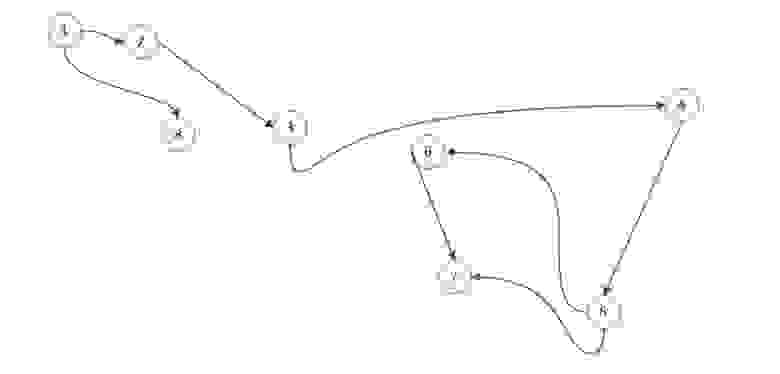
Список смежности (инцидентности)
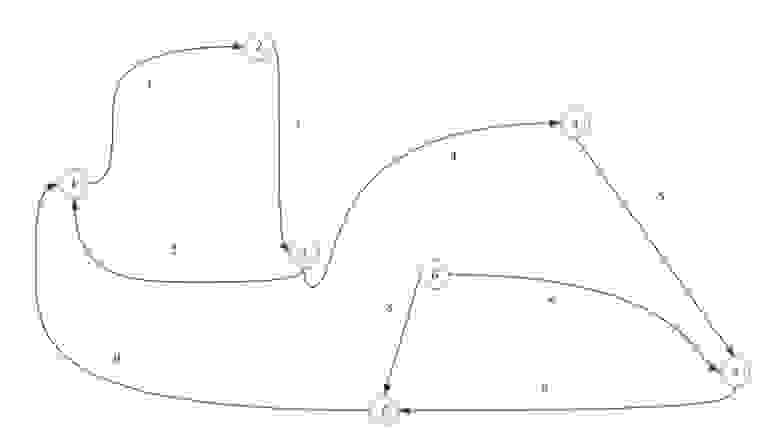
Список смежности подразумевает под собой, то что мы работаем с некоторым списком (массивом). В нем указаны вершины нашего графа. И каждый из них имеет ссылку на смежные с ним вершины.
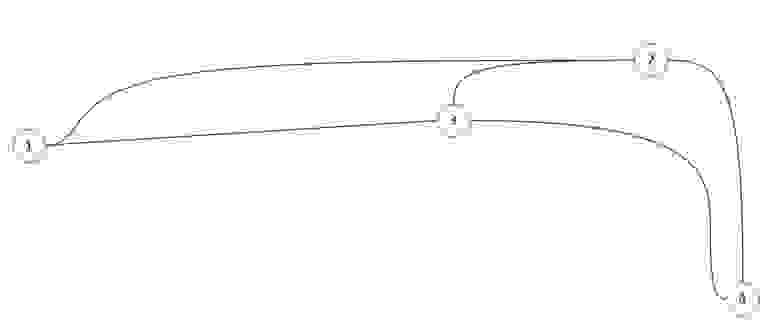
В виде списка это будет выглядеть так:
Неважно в каком порядке вы расположите ссылку так как вы рассматриваете смежность относительно первой ячейки, все остальные ссылки указывают лишь на связь с ней, а не между собой.
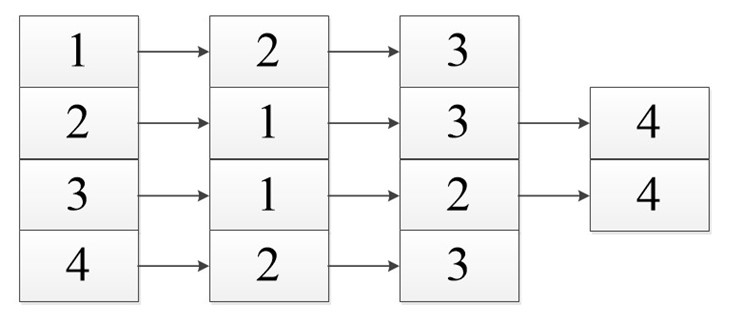
Так как здесь рассматривается смежность, то здесь не обойдется без дублирования вершин. Поэтому сумма длин всех списков считается как:


Когда мы работаем с ориентированным графом, то замечаем, что объем задействованной памяти будет меньше, чем при неориентированном (из-за отсутствия дублирования).

Сумма длин всех списков:


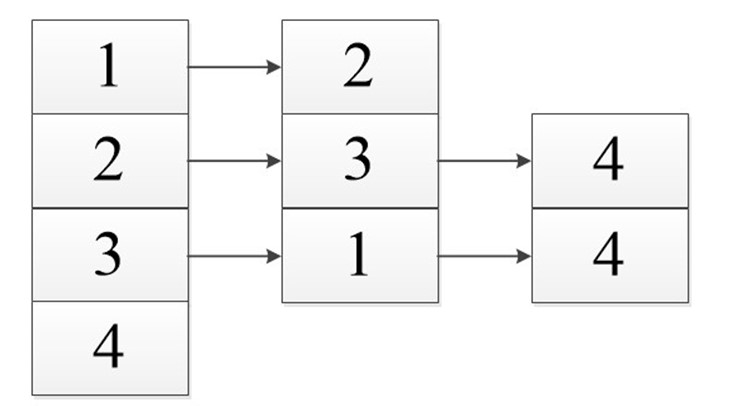
Со списком инцидентности все просто. Вместо вершин в список (массив) вы вставляете рёбра и потом делаете ссылки на те вершины, с которыми он связан.
К недостатку списка смежности (инцидентности) относится то что сложно определить наличие конкретного ребра (требуется поиск по списку). А если у вас большой список, то удачи вам и творческих успехов! Поэтому, чтобы работать максимальной отдачей в графе должно быть мало рёбер.
Взвешенность графа
Взвешенный граф — это граф, в котором вместо 1 обозначающее наличие связи между вершинами или связи между вершиной и ребром, хранится вес ребра, то есть определённое число с которым мы будем проводить различные действия.
К примеру, возьмем граф с весами на ребрах:
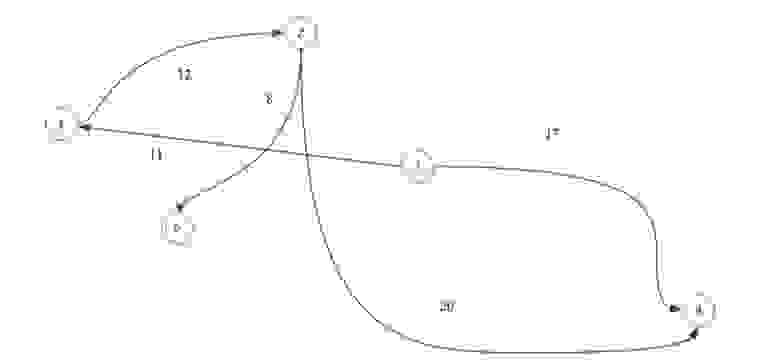
И сделаем матрицу смежности:

В ячейках просто указываем веса ребра, а в местах где отсутствует связь пишем 0 или -∞.
Более подробно данное определение будет рассмотрено при нахождении поиска кратчайшего пути в графе.
Итак, мы завершили разбор представления графа с помощью матрицы смежности и инцидентности и списка смежности (инцидентности). Это самые известные способы представления графа. В дальнейшем мы будем рассматривать и другие матрицы, и списки, которые в свою очередь будут удобны для представления графа с определёнными особенностями.
Если заметили ошибку или есть предложения пишите в комментарии.
Источник
Алгоритмы на графах — Часть 0: Базовые понятия
Как оказалось тема алгоритмов интересна Хабра-сообществу. Поэтому я как и обещал, начну серию обзоров «классических» алгоритмов на графах.
Так как публика на Хабре разная, а тема интересна многим, я должен начать с нулевой части. В этой части я расскажу что такое граф, как он представлен в компьютере и зачем он используется. Заранее прошу прощения у тех кто это все уже прекрасно знает, но для того чтобы объяснять алгоритмы на графах, нужно сначала объяснить что такое граф. Без этого никак.
В математике, Граф — это абстрактное представление множества объектов и связей между ними. Графом называют пару (V, E) где V это множество вершин, а E множество пар, каждая из которых представляет собой связь (эти пары называют рёбрами).
Граф может быть ориентированным или неориентированным. В ориентированном графе, связи являются направленными (то есть пары в E являются упорядоченными, например пары (a, b) и (b, a) это две разные связи). В свою очередь в неориентированном графе, связи ненаправленные, и поэтому если существует связь (a, b) то значит что существует связь (b, a).

Неориентированный граф: Соседство (в жизни). Если (1) сосед (3), то (3) сосед (1). См рис. 1.а
Ориентированный граф: Ссылки. Сайт (1) может ссылаться на сайт (3), но совсем не обязательно (хотя возможно) что сайт (3) ссылается сайт (1). См рис. 1.б
Степень вершины может быть входящая и исходящая (для неориентированных графов входящая степень равна исходящей).
Входящая степень вершины v это количество ребер вида (i, v), то есть количество ребер которые «входят» в v.
Исходящая степень вершины v это количество ребер вида (v , i), то есть количество ребер которые «выходят» из v.
Это не совсем формальное определение (более формально определение через инцидентность), но оно вполне отражает суть
Путь в графе это конечная последовательность вершин, в которой каждые две вершины идущие подряд соединены ребром. Путь может быть ориентированным или неориентированным в зависимости от графа. На рис 1.а, путем является например последовательность [(1), (4), (5)] на рис 1.б, [(1), (3), (4), (5)].
У графов есть ещё много разных свойств (например они могут быть связными, двудольными, полными), но я не буду описывать все эти свойства сейчас, а в следующих частях когда эти понятия понадобятся нам.
Представление графов
Существует два способа представления графа, в виде списков смежности и в виде матрицы смежности. Оба способа подходят для представления ориентированных и неориентированных графов.
Матрица смежности
Этот способ является удобным для представления плотных графов, в которых количество рёбер (|E|) примерно равно количеству вершин в квадрате (|V| 2 ).
В данном представлении мы заполняем матрицу размером |V| x |V| следущим образом:
A[i][j] = 1 (Если существует ребро из i в j)
A[i][j] = 0 (Иначе)
Данный способ подходит для ориентированных и неориентированных графов. Для неориентированных графов матрица A является симметричной (то есть A[i][j] == A[j][i], т.к. если существует ребро между i и j, то оно является и ребром из i в j, и ребром из j в i). Благодаря этому свойству можно сократить почти в два раза использование памяти, храня элементы только в верхней части матрицы, над главной диагональю)
Понятно что с помощью данного способа представления, можно быстро проверить есть ли ребро между вершинами v и u, просто посмотрев в ячейку A[v][u].
С другой стороны этот способ очень громоздкий, так как требует O (|V| 2 ) памяти для хранения матрицы.
На рис. 2 приведены представления графов из рис. 1 с помощью матриц смежности.
Списки смежности
Данный способ представления больше подходит для разреженных графов, то есть графов у которых количество рёбер гораздо меньше чем количество вершин в квадрате (|E| 2 ).
В данном представлении используется массив Adj содержащий |V| списков. В каждом списке Adj[v] содержатся все вершины u, так что между v и u есть ребро. Память требуемая для представления равна O (|E| + |V|) что является лучшим показателем чем матрица смежности для разреженных графов.
Главный недостаток этого способа представления в том, что нет быстрого способа проверить существует ли ребро (u, v).
На рис. 3 приведены представления графов из рис. 1 с помощью списков смежности.
Применение
Те кто дочитал до этого места, наверное задали себе вопрос, а где же собственно я смогу применить графы. Как я и обещал я буду стараться приводить примеры. Самый первый пример который приходит в голову это социальная сеть. Вершинами графа являются люди, а ребрами отношения (дружба). Граф может быть неориентированным, то есть я могу дружить только с теми кто дружит со мной. Либо ориентированным (как например в ЖЖ), где можно добавить человека в друзья, без того чтобы он добавлял вас. Если же он да добавит вас вы будете «взаимными друзьями». То есть будет существовать два ребра: (Он, Вы) и (Вы, Он)
Ещё одно из применений графа, которое я уже упоминал это ссылки с сайта на сайт. Представим Вы хотите сделать поисковую систему и хотите учесть на какие сайты есть больше ссылок (например сайт A), при этом учитывать сколько сайтов ссылается на сайт B, который ссылается на сайт A. У вас будет матрица смежности этих ссылок. Вы захотите ввести какую то систему подсчёта рейтинга, которая делает какие то подсчёты на этой матрице, ну, а дальше… это Google (точнее PageRank) =)
Заключение
Это небольшая часть теории которая понадобится нам чтобы для следующих частей. Надеюсь вам было понятно, а главное понравилось и заинтересовало читать дальнейшие части! Оставляйте свои отзывы и пожелания в комментариях.
В следующей части
BFS — Алгоритм поиска в ширину
Библиография
Кормен, Лайзерсон, Риверст, Штайн — Алгоритмы. Построение и анализ. Издательство Вильямс, 2007.
Словарь терминов теории графов
Граф — статья в английской Википедии
Статья это кросс-пост из моего блога — «Programing as is — записки программиста»
Источник



