
- Основные структуры данных. Матчасть. Азы
- Что такое структура данных?
- Какие бывают?
- Основные структуры данных.
- Массивы
- Бывают
- Основные операции
- Вопросы
- Стеки
- Основные операции
- Вопросы
- Очереди
- Основные операции
- Вопросы
- Связанный список
- Бывают
- Основные операции
- Вопросы
- Графы
- Бывают
- Встречаются в таких формах как
- Общие алгоритмы обхода графа
- Вопросы
- Деревья
- Три способа обхода дерева
- Вопросы
- Trie ( префиксное деревое )
- Вопросы
- Хэш таблицы
- Вопросы
- Список ресурсов
- Вместо заключения
- 10 типов структур данных, которые нужно знать + видео и упражнения
- Связные списки
- Упражнения от freeCodeCamp
- Стеки
- Упражнения от freeCodeCamp
- Очереди
- Упражнения от freeCodeCamp
- Множества
- Упражнения от freeCodeCamp
- Структуры данных для самых маленьких
- Что такое структуры данных?
- Алгоритмы
- О большое
- Память
- Списки
- Хеш-таблицы
- Стеки
- Очереди
- Графы
- Связные списки
- Деревья
- Двоичные деревья поиска
- Конец
Основные структуры данных. Матчасть. Азы
Все чаще замечаю, что современным самоучкам очень не хватает матчасти. Все знают языки, но мало основы, такие как типы данных или алгоритмы. Немного про типы данных.
Еще в далеком 1976 швейцарский ученый Никлаус Вирт написал книгу Алгоритмы + структуры данных = программы.
40+ лет спустя это уравнение все еще верно. И если вы самоучка и надолго в программировании пробегитесь по статье, можно по диагонали. Можно код кофе.

В статье так же будут вопросы, которое вы можете услышать на интервью.
Что такое структура данных?
Структура данных — это контейнер, который хранит данные в определенном макете. Этот «макет» позволяет структуре данных быть эффективной в некоторых операциях и неэффективной в других.
Какие бывают?
Линейные, элементы образуют последовательность или линейный список, обход узлов линеен. Примеры: Массивы. Связанный список, стеки и очереди.
Нелинейные, если обход узлов нелинейный, а данные не последовательны. Пример: граф и деревья.
Основные структуры данных.
Массивы
Массив — это самая простая и широко используемая структура данных. Другие структуры данных, такие как стеки и очереди, являются производными от массивов.
Изображение простого массива размера 4, содержащего элементы (1, 2, 3 и 4).
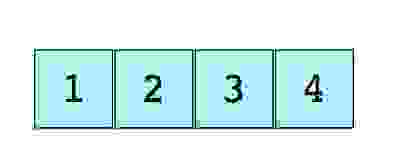
Каждому элементу данных присваивается положительное числовое значение (индекс), который соответствует позиции элемента в массиве. Большинство языков определяют начальный индекс массива как 0.
Бывают
Одномерные, как показано выше.
Многомерные, массивы внутри массивов.
Основные операции
Вопросы
Стеки
Стек — абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
Это не массивы. Это очередь. Придумал Алан Тюринг.
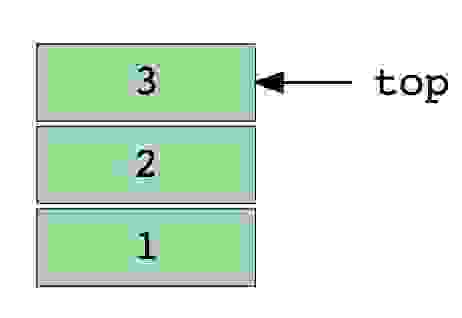
Примером стека может быть куча книг, расположенных в вертикальном порядке. Для того, чтобы получить книгу, которая где-то посередине, вам нужно будет удалить все книги, размещенные на ней. Так работает метод LIFO (Last In First Out). Функция «Отменить» в приложениях работает по LIFO.
Изображение стека, в три элемента (1, 2 и 3), где 3 находится наверху и будет удален первым.
Основные операции
Вопросы
Очереди
Подобно стекам, очередь — хранит элемент последовательным образом. Существенное отличие от стека – использование FIFO (First in First Out) вместо LIFO.
Пример очереди – очередь людей. Последний занял последним и будешь, а первый первым ее и покинет.
Изображение очереди, в четыре элемента (1, 2, 3 и 4), где 1 находится наверху и будет удален первым

Основные операции
Вопросы
Связанный список
Связанный список – массив где каждый элемент является отдельным объектом и состоит из двух элементов – данных и ссылки на следующий узел.
Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком расположения элементов данных в памяти компьютера, а порядок обхода списка всегда явно задаётся его внутренними связями.
Бывают
Однонаправленный, каждый узел хранит адрес или ссылку на следующий узел в списке и последний узел имеет следующий адрес или ссылку как NULL.
Двунаправленный, две ссылки, связанные с каждым узлом, одним из опорных пунктов на следующий узел и один к предыдущему узлу.
Круговой, все узлы соединяются, образуя круг. В конце нет NULL. Циклический связанный список может быть одно-или двукратным циклическим связанным списком.
Самое частое, линейный однонаправленный список. Пример – файловая система.

Основные операции
Вопросы
Графы
Граф-это набор узлов (вершин), которые соединены друг с другом в виде сети ребрами (дугами).

Бывают
Ориентированный, ребра являются направленными, т.е. существует только одно доступное направление между двумя связными вершинами.
Неориентированные, к каждому из ребер можно осуществлять переход в обоих направлениях.
Смешанные
Встречаются в таких формах как
Общие алгоритмы обхода графа
Вопросы
Деревья
Дерево-это иерархическая структура данных, состоящая из узлов (вершин) и ребер (дуг). Деревья по сути связанные графы без циклов.
Древовидные структуры везде и всюду. Дерево скилов в играх знают все.
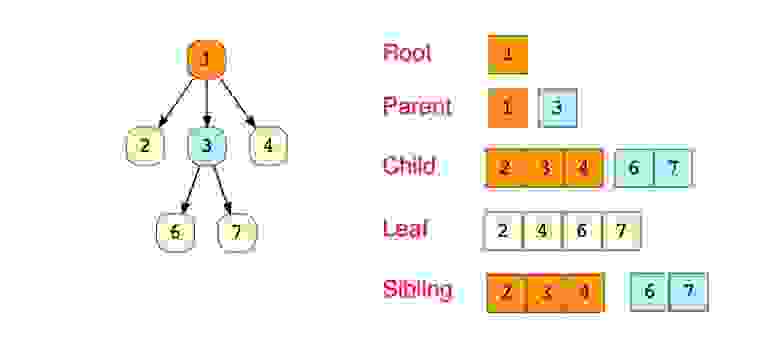
Типы деревьев
- N дерево
- Сбалансированное дерево
- Бинарное дерево
- Дерево Бинарного Поиска
- AVL дерево
- 2-3-4 деревья
Бинарное дерево самое распространенное.
«Бинарное дерево — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. » — Procs
Три способа обхода дерева
Вопросы
Trie ( префиксное деревое )
Разновидность дерева для строк, быстрый поиск. Словари. Т9.
Вот как такое дерево хранит слова «top», «thus» и «their».
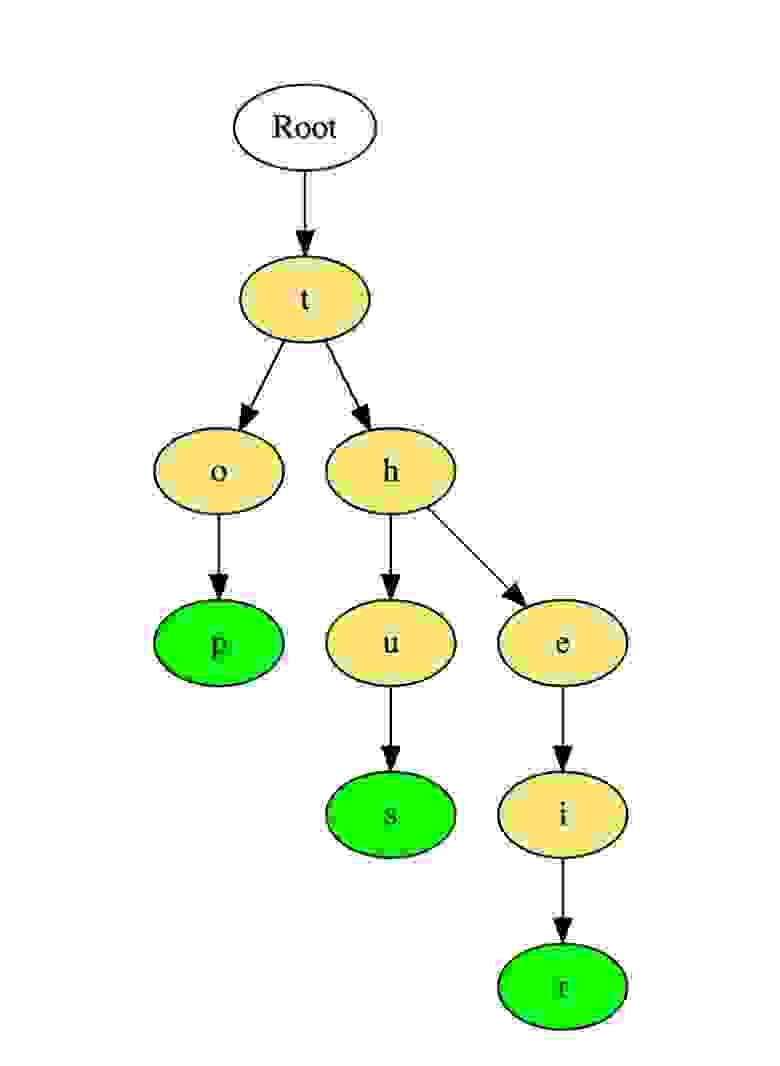
Слова хранятся сверху вниз, зеленые цветные узлы «p», «s» и «r» указывают на конец «top», «thus « и «their» соответственно.
Вопросы
Хэш таблицы
Хэширование — это процесс, используемый для уникальной идентификации объектов и хранения каждого объекта в заранее рассчитанном уникальном индексе (ключе).
Объект хранится в виде пары «ключ-значение», а коллекция таких элементов называется «словарем». Каждый объект можно найти с помощью этого ключа.
По сути это массив, в котором ключ представлен в виде хеш-функции.
Эффективность хеширования зависит от
- Функции хеширования
- Размера хэш-таблицы
- Метода борьбы с коллизиями
Пример сопоставления хеша в массиве. Индекс этого массива вычисляется через хэш-функцию. 
Вопросы
Список ресурсов
Вместо заключения
Матчасть так же интересна, как и сами языки. Возможно, кто-то увидит знакомые ему базовые структуры и заинтересуется.
Спасибо, что прочли. Надеюсь не зря потратили время =)
PS: Прошу извинить, как оказалось, перевод статьи уже был тут и очень недавно, я проглядел.
Если интересно, вот она, спасибо Hokum, буду внимательнее.
Источник
10 типов структур данных, которые нужно знать + видео и упражнения
Екатерина Малахова, редактор-фрилансер, специально для блога Нетологии адаптировала статью Beau Carnes об основных типах структур данных.
«Плохие программисты думают о коде. Хорошие программисты думают о структурах данных и их взаимосвязях», — Линус Торвальдс, создатель Linux.
Структуры данных играют важную роль в процессе разработки ПО, а еще по ним часто задают вопросы на собеседованиях для разработчиков. Хорошая новость в том, что по сути они представляют собой всего лишь специальные форматы для организации и хранения данных.
В этой статье я покажу вам 10 самых распространенных структур данных. Для каждой из них приведены видео и примеры их реализации на JavaScript. Чтобы вы смогли попрактиковаться, я также добавил несколько упражнений из бета-версии новой учебной программы freeCodeCamp.
Обратите внимание, что некоторые структуры данных включают временную сложность в нотации «большого О». Это относится не ко всем из них, так как иногда временная сложность зависит от реализации. Если вы хотите узнать больше о нотации «большого О», посмотрите это видео от Briana Marie.
В статье я привожу примеры реализации этих структур данных на JavaScript: они также пригодятся, если вы используете низкоуровневый язык вроде С. В многие высокоуровневые языки, включая JavaScript, уже встроены реализации большинства структур данных, о которых пойдет речь. Тем не менее, такие знания станут серьезным преимуществом при поиске работы и пригодятся при написании высокопроизводительного кода.
Связные списки
Связный список — одна из базовых структур данных. Ее часто сравнивают с массивом, так как многие другие структуры можно реализовать с помощью либо массива, либо связного списка. У этих двух типов есть преимущества и недостатки.

Так устроен связный список
Связный список состоит из группы узлов, которые вместе образуют последовательность. Каждый узел содержит две вещи: фактические данные, которые в нем хранятся (это могут быть данные любого типа) и указатель (или ссылку) на следующий узел в последовательности. Также существуют двусвязные списки: в них у каждого узла есть указатель и на следующий, и на предыдущий элемент в списке.
Основные операции в связном списке включают добавление, удаление и поиск элемента в списке.
Упражнения от freeCodeCamp
Стеки
Стек — это базовая структура данных, которая позволяет добавлять или удалять элементы только в её начале. Она похожа на стопку книг: если вы хотите взглянуть на книгу в середине стека, сперва придется убрать лежащие сверху.
Стек организован по принципу LIFO (Last In First Out, «последним пришёл — первым вышел») . Это значит, что последний элемент, который вы добавили в стек, первым выйдет из него.
Так устроен стек
В стеках можно выполнять три операции: добавление элемента (push), удаление элемента (pop) и отображение содержимого стека (pip).
Упражнения от freeCodeCamp
Очереди
Эту структуру можно представить как очередь в продуктовом магазине. Первым обслуживают того, кто пришёл в самом начале — всё как в жизни.
Так устроена очередь
Очередь устроена по принципу FIFO (First In First Out, «первый пришёл — первый вышел»). Это значит, что удалить элемент можно только после того, как были убраны все ранее добавленные элементы.
Очередь позволяет выполнять две основных операции: добавлять элементы в конец очереди (enqueue) и удалять первый элемент (dequeue).
Упражнения от freeCodeCamp
Множества
Так выглядит множество
Множество хранит значения данных без определенного порядка, не повторяя их. Оно позволяет не только добавлять и удалять элементы: есть ещё несколько важных функций, которые можно применять к двум множествам сразу.
- Объединение комбинирует все элементы из двух разных множеств, превращая их в одно (без дубликатов).
- Пересечение анализирует два множества и создает еще одно из тех элементов, которые присутствуют в обоих изначальных множествах.
- Разность выводит список элементов, которые есть в одном множестве, но отсутствуют в другом.
- Подмножество выдает булево значение, которое показывает, включает ли одно множество все элементы другого множества.
Пример реализации на JavaScript
Упражнения от freeCodeCamp
Map — это структура, которая хранит данные в парах ключ/значение, где каждый ключ уникален. Иногда её также называют ассоциативным массивом или словарём. Map часто используют для быстрого поиска данных. Она позволяет делать следующие вещи:
- добавлять пары в коллекцию;
- удалять пары из коллекции;
- изменять существующей пары;
- искать значение, связанное с определенным ключом.
Источник
Структуры данных для самых маленьких
James Kyle как-то раз взял и написал пост про структуры данных, добавив их реализацию на JavaScript. А я взял и перевёл.
Дисклеймер: в посте много ascii-графики. Не стоит его читать с мобильного устройства — вас разочарует форматирование текста.
Сегодня мы узнаем всё о структурах данных.
«Оооооой как интересно. », да?
Да уж, не самая сочная тема на сей день, однако крайне важная. Не для того, чтобы сдавать курсы наподобие CS101, а чтобы лучше разбираться в программировании.
Знание структур данных поможет вам:
- Управлять сложностью своих программ, делая их доступней для понимания.
- Создавать высокопроизводительные программы, эффективно работающие с памятью.
Я считаю, что первое важнее. Правильная структура данных может кардинально упростить код, устраняя запутанную логику.
Второй пункт тоже важен. Когда учитываются производительность или память программы, правильный выбор структуры данных значительно сказывается на работе.
Чтобы познакомиться со структурами данных, мы реализуем некоторые из них. Не беспокойтесь, код будет лаконичен. На самом деле, тут больше комментариев, а кода между ними — раз, два и обчёлся.
Что такое структуры данных?
По сути, это способы хранить и организовывать данные, чтобы эффективней решать различные задачи. Данные можно представить по-разному. В зависимости от того, что это за данные и что вы собираетесь с ними делать, одно представление подойдёт лучше других.
Чтобы понять, почему так происходит, сперва поговорим об алгоритмах.
Алгоритмы
Алгоритм — такое хитроумное название для последовательности совершаемых действий.
Структуры данных реализованы с помощью алгоритмов, алгоритмы — с помощью структур данных. Всё состоит из структур данных и алгоритмов, вплоть до уровня, на котором бегают микроскопические человечки с перфокартами и заставляют компьютер работать. (Ну да, у Интела в услужении микроскопические люди. Поднимайся, народ!)
Любая данная задача реализуется бесконечным количеством способов. Как следствие, для решения распространённых задач изобрели множество различных алгоритмов.
Например, для сортировки неупорядоченного множества элементов существует до смешного большое количество алгоритмов:
Сортировка вставками, Сортировка выбором, Сортировка слиянием, Сортировка пузырьком, Cортировка кучи, Быстрая сортировка, Сортировка Шелла, Сортировка Тима, Блочная сортировка, Поразрядная сортировка.
Некоторые из них значительно быстрее остальных. Другие занимают меньше памяти. Третьи легко реализовать. Четвёртые построены на допущениях относительно наборов данных.
Каждая из сортировок подходит лучше других для определённой задачи. Поэтому вам надо будет сперва решить, какие у вас потребности и критерии, чтобы понять, как сравнивать алгоритмы между собой.
Для сравнения производительности алгоритмов используется грубое измерение средней производительности и производительности в худшем случае, для обозначения которых используется термин «О» большое.
О большое
«О» большое — обозначение способа приблизительной оценки производительности алгоритмов для относительного сравнения.
О большое — заимствованное информатикой математические обозначение, определяющее, как алгоритмы соотносятся с передаваемым им некоторым количеством N данных.
О большое характеризует две основные величины:
Оценка времени выполнения — общее количество операций, которое алгоритм проведёт на данном множестве данных.
Оценка объёма — общее количество памяти, требующееся алгоритму для обработки данного множества данных.
Оценки делаются независимо друг от друга: одни алгоритмы могут производить меньше операций, чем другие, занимая при этом больше памяти. Определив свои требования, вы сможете выбрать соответствующий алгоритм.
Вот некоторые распространённые значения О большого:
Чтобы дать представление, о каких порядках чисел мы говорим, давайте взглянем, что это будут за значения в зависимости от N.
Как видите, даже при относительно небольших числах можно сделать *дофига* дополнительной работы.
Структуры данных позволяют производить 4 основных типа действий: доступ, поиск, вставку и удаление.
Замечу, что структуры данных могут быть хороши в одном из действий, но плохи в другом.
Кроме того, некоторые действия имеют разную «среднюю» производительность и производительность в «самом худшем случае».
Идеальной структуры данных не существует. Вы выбираете самую подходящую, основываясь на данных и на том, как они будут обрабатываться. Чтобы сделать правильный выбор, важно знать различные распространённые структуры данных.
Память
Компьютерная память — довольно скучная штука. Это группа упорядоченных слотов, в которых хранится информация. Чтобы получить к ней доступ, вы должны знать её адрес в памяти.
Фрагмент памяти можно представить так:
Если вы задумывались, почему в языках программирования отсчёт начинается с 0 — потому, что так работает память. Чтобы прочитать первый фрагмент памяти, вы читаете с 0 до 1, второй — с 1 до 2. Адреса этих фрагментов соответственно равны 0 и 1.
Конечно же, в компьютере больше памяти, чем показано в примере, однако её устройство продолжает принцип рассмотренного шаблона.
Просторы памяти — как Дикий Запад. Каждая работающая на компьютере программа хранится внутри одной и той же *физической* структуры данных. Использование памяти — сложная задача, и для удобной работы с ней существуют дополнительные уровни абстракции.
Абстракции имеют два дополнительных назначения:
— Сохраняют данные в памяти таким образом, чтобы с ними было эффективно и/или быстро работать.
— Сохраняют данные в памяти так, чтобы их было проще использовать.
Списки
Для начала реализуем список, чтобы показать сложности взаимодействия между памятью и структурой данных.
Список — представление пронумерованной последовательности значений, где одно и то же значение может присутствовать сколько угодно раз.
Начнём с пустого блока памяти, представленного обычным JavaScript-массивом. Также нам понадобится хранить значение длины списка.
Заметьте, что мы хотим хранить длину отдельно, поскольку в реальности у «памяти» нет значения length, которое можно было бы взять и прочитать.
Первым делом нужно получать данные из списка. Обычный список позволяет очень быстро получить доступ к памяти, поскольку вы уже знаете нужный адрес.
Сложность операции доступа в список — O(1) — «ОХРЕНЕННО!!»
У списков есть порядковые номера, поэтому можно вставлять значения в начало, середину и конец.
Мы сфокусируемся на добавлении и удалении значений в начало или конец списка. Для этого понадобятся 4 метода:
- Push — Добавить значение в конец.
- Pop — Удалить значение из конца.
- Unshift — Добавить значение в начало.
- Shift — Удалить значение из начала.
Начнём с операции «push» — реализуем добавление элементов в конец списка.
Это настолько же легко, как добавить значение в адрес, следующий за нашим списком. Поскольку мы храним длину, вычислить адрес — проще простого. Добавим значение и увеличим длину.
Добавление элемента в конец списка — константа O(1) — «ОХРЕНЕННО!!»
Комментарии хабра: poxu не согласен с автором и объясняет, что существует операция расширения памяти, увеличивающая сложность добавления элементов в список.
Далее, реализуем метод «pop», убирающий элемент из конца нашего списка. Аналогично push, всё, что нужно сделать — убрать значение из последнего адреса. Ну, и уменьшить длину.
Удаление элемента из конца списка — константа O(1) — «ОХРЕНЕННО!!»
«Push» и «pop» работают с концом списка, и в общем-то являются простыми операциями, поскольку не затрагивают весь остальной список.
Давайте посмотрим, что происходит, когда мы работаем с началом списка, с операциями «unshift» и «shift».
Чтобы добавить новый элемент в начало списка, нужно освободить пространство для этого значения, сдвинув на один все последующие значения.
Чтобы сделать такой сдвиг, нужно пройтись по каждому из элементов и поставить на его место предыдущий.
Поскольку мы вынуждены пройтись по каждому из элементов списка:
Добавление элемента в начало списка — линейно O(N) — «НОРМАС.»
Осталось написать функцию сдвига списка в противоположном направлении — shift.
Мы удаляем первое значение и затем сдвигаем каждый элемент списка на предшествующий адрес.
Удаление элемента из начала списка — линейно O(N) — «НОРМАС.»
Списки отлично справляются с быстрым доступом к элементам в своём конце и работой с ними. Однако, как мы увидели, для элементов из начала или середины они не слишком хороши, так как приходится вручную обрабатывать адреса памяти.
Давайте посмотрим на иную структуру данных и её методы по добавлению, доступу и удалению значений без необходимости знать адреса элементов.
Хеш-таблицы
Хеш-таблица — неупорядоченная структура данных. Вместо индексов мы работаем с «ключами» и «значениями», вычисляя адрес памяти по ключу.
Смысл в том, что ключи «хешируются» и позволяют эффективно работать с памятью — добавлять, получать, изменять и удалять значения.
Вновь используем обычный JavaScript-массив, представляющий память.
Чтобы сохранять пары ключ-значение из хеш-таблицы в память, нужно превращать ключи в адреса. Этим занимается операция «хеширования».
Она принимает на вход ключ и преобразовывает его в уникальное число, соответствующее этому ключу.
Такая операция требует осторожности. Если ключ слишком большой, он будет сопоставляться несуществующему адресу в памяти.
Следовательно, хеш-функция должна ограничивать размер ключей, т.е. ограничивать число доступных адресов памяти для неограниченного количества значений.
Любая реализация хеш-таблиц сталкивается с этой проблемой.
Однако, поскольку мы собираемся рассмотреть лишь устройство их работы, предположим, что коллизий не случится.
Давайте определим функцию «hashKey».
Не вдавайтесь во внутреннюю логику, просто поверьте, что она принимает на вход строку и возвращает (практически всегда) уникальный адрес, который мы будем использовать в остальных функциях.
Теперь определим функцию «get», получающую значение по ключу.
Сложность чтения значения из хеш-таблицы — константа O(1) — «ОХРЕНЕННО!!»
Перед тем, как получать данные, неплохо бы их сперва добавить. В этом нам поможет функция «set».
Сложность установки значения в хеш-таблицу — константа O(1) — «ОХРЕНЕННО!!»
Наконец, нужен способ удалять значения из хеш-таблицы. Сложность удаления значения из хеш-таблицы — константа O(1) — «ОХРЕНЕННО!!»
Теперь мы прекратим работать с памятью напрямую: все последующие структуры данных будут реализовываться через другие структуры данных.
Новые структуры фокусируются на двух вещах:
- Организовывают данные, исходя из особенностей их применения
- Абстрагируют детали реализации
Цель таких структур данных — организовать информацию для применения в программах различного типа. Они предоставляют язык, позволяющий выражать более сложную логику. При этом абстрагируются детали реализации, т.е. можно изменить реализацию, сделав её быстрее.
Стеки
Стеки похожи на списки. Они также упорядочены, но ограничены в действиях: можно лишь добавлять и убирать значения из конца списка. Как мы увидели ранее, это происходит очень быстро, если обращаться к памяти напрямую.
Однако стеки могут быть реализованы через другие структуры данных, чтобы получить дополнительную функциональность.
Наиболее общий пример использования стеков — у вас есть один процесс, добавляющий элементы в стек и второй, удаляющий их из конца — приоритизируя недавно добавленные элементы.
Нам вновь понадобится JavaScript-массив, но на этот раз он символизирует не память, а список, вроде реализованного выше.
Нам понадобится реализовать два метода, функционально идентичных методам списка — «push» и «pop».
Push добавляет элементы на верхушку стека.
Pop удаляет элементы из верхушки.
Кроме того, добавим функцию peek, показывающую элемент на верхушке стека без его удаления. Прим. переводчика: peek – взглянуть.
Очереди
Теперь создадим очередь — структуру, комплементарную стеку. Разница в том, что элементы очереди удаляются из начала, а не из конца, т.е. сначала старые элементы, потом новые.
Как уже оговаривалось, поскольку функциональность ограничена, существуют разные реализации очереди. Хорошим способом будет использование связного списка, о котором мы поговорим чуть позже.
И вновь мы призываем на помощь JavaScript-массив! В случае с очередью мы опять рассматриваем его как список, а не как память.
Аналогично стекам мы определяем две функции для добавления и удаления элементов из очереди.
Первым будет «enqueue» — добавление элемента в конец списка.
Далее — «dequeue». Элемент удаляется не из конца списка, а из начала.
Аналогично стекам объявим функцию «peek», позволяющую получить значение в начале очереди без его удаления.
Важно заметить, что, поскольку для реализации очереди использовался список, она наследует линейную производительность метода shift (т.е. O(N) — «НОРМАС.»).
Как мы увидим позже, связные списки позволяют реализовать более быструю очередь.
С этого места и далее мы будем работать со структурами данных, где значения ссылаются друг на друга.
Элементы структуры данных становятся сами по себе министруктурами, содержащими значение и дополнительную информацию — ссылки на другие элементы родительской структуры.
Сейчас вы поймёте, что я имею ввиду.
Графы
На самом деле граф — совсем не то, о чём вы подумали, увидев ascii-график.
Граф — структура наподобие этой:
У нас есть множество «вершин» (A, B, C, D, . ), связанных линиями.
Эти вершины можно представить вот так:
А весь граф будет выглядеть вот так:
Представим список вершин JavaScript-массивом. Массив используется не с целью специально упорядочить вершины, а как место для хранения вершин.
Начнём добавлять значения в граф, создавая вершины без каких-либо линий.
Теперь нужен способ искать вершины в графе. Обычно для ускорения поиска делается ещё одна структура данных поверх графа.
Но в нашем случае мы просто переберём все вершины, чтобы найти соответствующую значению. Способ медленный, но работающий.
Теперь мы можем связать две вершины, проведя «линию» от одной до другой (прим. переводчика: дугу графа).
Полученный граф можно использовать вот так:
Кажется, что для такой мелкой задачи сделано слишком много работы, однако это мощный паттерн.
Он часто применяется для поддержания прозрачности в сложных программах. Это достигается оптимизацией взаимосвязей между данными, а не операций над самими данными. Если вы выберете одну вершину в графе, невероятно просто найти связанные с ней элементы.
Графами можно представлять уйму вещей: пользователей и их друзей, 800 зависимостей в папке node_modules, даже сам интернет, являющийся графом связанных друг с другом ссылками веб-страниц.
Связные списки
Давайте теперь посмотрим, как графоподобная структура может оптимизировать упорядоченный список данных.
Связные списки — распространённая структура данных, зачастую используемая для реализации других структур. Преимущество связного списка — эффективность добавления элементов в начало, середину и конец.
Связный список по своей сути похож на граф: вы работаете с вершинами, указывающими на другие вершины. Они расположены таким образом:
Если представить эту структуру в виде JSON, получится нечто такое:
В отличие от графа, связный список имеет единственную вершину, из которой начинается внутренняя цепочка. Её называют «головой», головным элементом или первым элементом связного списка.
Также мы собираемся отслеживать длину списка.
Первым делом нужен способ получать значение по данной позиции.
В отличие от обычных списков мы не можем перепрыгнуть на нужную позицию. Вместо этого мы должны перейти к ней через отдельные вершины.
Теперь необходим способ добавлять вершины в выбранную позицию.
Создадим метод add, принимающий значение и позицию.
Последний метод, который нам понадобится — remove. Найдём вершину по позиции и выкинем её из цепочки.
Две оставшиеся структуры данных относятся к семейству «деревьев».
Как и в жизни, существует множество различных древовидных структур данных.
Прим. переводчика: ну не-е-е-е, я пас…
Binary Trees:
AA Tree, AVL Tree, Binary Search Tree, Binary Tree, Cartesian Tree, left child/right sibling tree, order statistic tree, Pagoda,…
B Trees:
B Tree, B+ Tree, B* Tree, B Sharp Tree, Dancing Tree, 2-3 Tree,…
Heaps:
Heap, Binary Heap, Weak Heap, Binomial Heap, Fibonacci Heap, Leonardo Heap, 2-3 Heap, Soft Heap, Pairing Heap, Leftist Heap, Treap,…
Trees:
Trie, Radix Tree, Suffix Tree, Suffix Array, FM-index, B-trie,…
Multi-way Trees:
Ternary Tree, K-ary tree, And-or tree, (a,b)-tree, Link/Cut Tree,…
Space Partitioning Trees:
Segment Tree, Interval Tree, Range Tree, Bin, Kd Tree, Quadtree, Octree, Z-Order, UB-Tree, R-Tree, X-Tree, Metric Tree, Cover Tree,…
Application-Specific Trees:
Abstract Syntax Tree, Parse Tree, Decision Tree, Minimax Tree,…
Чего уж вы не ожидали, так это что будете изучать сегодня дендрологию… И это ещё не все деревья. Пусть они вас не смущают, большинство из них вообще не имеет смысла. Надо же было людям как-то защищать кандидатские степени и что-то для этого доказывать.
Деревья похожи на графы или связные списки, с той разницей, что они «однонаправленые». Это значит, что в них не может существовать циклических ссылок.
Если вы можете пройти круг по вершинам дерева… что ж, поздравляю, но это не дерево.
Деревья применяются во множестве задач. Они используются для оптимизации поиска или сортировки. Они могут лучше организовывать программу. Они могут создать представление, с которым проще работать.
Деревья
Начнём с простой древовидной структуры. В ней нет особых правил, и выглядит она примерно так:
Дерево должно начинаться с единственного родителя, «корня» дерева.
Нам нужен способ обходить наше дерево и вызывать определённую функцию в каждой его вершине.
Теперь нужен способ добавлять вершины в дерево.
Это простое дерево, возможно, полезное лишь в случае, когда отображаемые данные на него похожи.
Однако при наличии дополнительных правил деревья могут выполнять кучу различных задач.
Двоичные деревья поиска
Двоичные деревья поиска — распространённая форма деревьев. Они умеют эффективно читать, искать, вставлять и удалять значения, сохраняя при этом отсортированный порядок.
Представьте, что у вас есть последовательность чисел:
Развернём её в дерево, начинающееся из центра.
Вот пример, как работает бинарное дерево. У каждой вершины есть два потомка:
- Левый — меньше, чем значение вершины-родителя.
- Правый – больше, чем значение вершины-родителя.
Замечание: для того, чтобы это работало, все значения в дереве должны быть уникальны.
Это делает обход дерева при поиске значения очень эффективным. Например, попробуем найти число 5 в нашем дереве.
Заметьте, чтобы добраться до 5, потребовалось сделать лишь 3 проверки. А если бы дерево состояло из 1000 элементов, путь был бы таким:
Всего 10 проверок на 1000 элементов!
Ещё одной важной особенностью двоичных деревьев поиска является их схожесть со связными списками — при добавлении или удалении значения вам нужно обновлять лишь непосредственно окружающие элементы.
Как и в прошлой секции, сперва нужно установить “корень” двоичного дерева поиска.
Чтобы проверить, находится ли значение в дереве, нужно провести поиск по дереву.
Чтобы добавить элемент в дерево, нужно произвести такой же обход, как и раньше, перепрыгивая по левым и правым вершинам в зависимости от того, больше или меньше ли они по сравнению с добавляемым значением.
Однако теперь, когда мы доберёмся до левой или правой вершины, равной null,
мы добавим вершину в эту позицию.
Конец
Надеюсь, вы получили хорошую дозу знаний. Если вам понравилось,
ставьте звездочки в репозитории и подписывайтесь на меня в твиттере.
Также можете прочитать другую мою статью, «The Super Tiny Compiler» github.com/thejameskyle/the-super-tiny-compiler
Также эту статью можно прочитать на гитхабе.
Перевод: aalexeev, редактура: iamo0, Чайка Чурсина.
Источник



