
- МЕТОДЫ СТАТИСТИЧЕСКОГО ОБУЧЕНИЯ
- Русские Блоги
- Статистические методы обучения — основы статистического обучения (1)
- Статистические методы обучения — статистическое обучение
- Введение в статистическое обучение (1)
- Статистическое обучение
- Характеристики статистического обучения
- Статистический метод обучения
- Контролируемое обучение
- базовые концепции
- Формализовать проблему
- Три элемента статистического обучения
- модель
- Стратегия
- алгоритм
- Оценка модели и выбор модели (1)
- Ошибка обучения и ошибка теста
- Переоборудование, неполное оснащение и выбор модели
МЕТОДЫ СТАТИСТИЧЕСКОГО ОБУЧЕНИЯ
В гл. 5 детально описаны статистические методы обучения, поэтому здесь приводится лишь обзор этих методов.
Однослойные сети несколько ограничены с точки зрения проблем, которые они могут решать; однако в течение многих лет отсутствовали методы обучения многослойных сетей. Статистическое обучение обеспечивает путь решения этих проблем.
По аналогии обучение сети статистическими способами подобно процессу отжига металла. В процессе отжига температура металла вначале повышается, пока атомы металла не начнут перемещаться почти свободно. Затем температура постепенно уменьшается и атомы непрерывно стремятся к минимальной энергетической конфигурации. При некоторой низкой температуре атомы переходят на низший энергетический уровень.
В искусственных нейронных сетях полная величина энергии сети определяется как функция определенного множества сетевых переменных. Искусственная переменная температуры инициируется в большую величину, тем самым позволяя сетевым переменным претерпевать большие случайные изменения. Изменения, приводящие к уменьшению полной энергии сети, сохраняются; изменения, приводящие к увеличению энергии, сохраняются в соответствии с вероятностной функцией. Искусственная температура постепенно уменьшается с течением времени и сеть конвергирует в состояние минимума полной энергии.
Существует много вариаций на тему статистического обучения. Например, глобальная энергия может быть определена как средняя квадратичная ошибка между полученным и желаемым выходным вектором из обучаемого множества, а переменными могут быть веса сети. В этом случае сеть может быть обучена, начиная с высокой искусственной температуры, путем выполнения следующих шагов:
1. Подать обучающий вектор на вход сети и вычислить выход согласно соответствующим сетевым правилам.
2. Вычислить значение средней квадратичной ошибки между желаемым и полученным выходными векторами.
3. Изменить сетевые веса случайным образом, затем вычислить новый выход и результирующую ошибку. Если ошибка уменьшилась, оставить измененный вес; если ошибка увеличилась, оставить измененный вес с вероятностью, определяемой распределением Больцмана. Если изменения весов не производится, то вернуть вес к его предыдущему •значению.
4. Повторить шаги с 1 по 3, постепенно уменьшая искусственную температуру.
Если величина случайного изменения весов определяется в соответствии с распределением Больцмана, сходимость к глобальному минимуму будет осуществляться только в том случае, если температура изменяется обратно пропорционально логарифму прошедшего времени обучения. Это может привести к невероятной длительности процесса обучения, поэтому большое внимание уделялось поиску более быстрых методов обучения. Выбором размера шага в соответствии с распределением Коши может быть достигнуто уменьшение температуры, обратно пропорциональное обучающему времени, что существенно уменьшает время, требуемое для сходимости.
Заметим, что существует класс статистических методов для нейронных сетей, в которых переменными сети являются выходы нейронов, а не веса. В гл. 5 эти алгоритмы рассматривались подробно.
САМООРГАНИЗАЦИЯ
В работе [3] описывались интересные и полезные результаты исследований Кохонена на самоорганизующихся структурах, используемых для задач распознавания образов. Вообще эти структуры классифицируют образы, представленные векторными величинами, в которых каждый компонент вектора соответствует элементу образа. Алгоритмы Кохонена основываются на технике обучения без учителя. После обучения подача входного вектора из данного класса будет приводить к выработке возбуждающего уровня в каждом выходном нейроне; нейрон с максимальным возбуждением представляет классификацию. Так как обучение проводится без указания целевого вектора, то нет возможности определять заранее, какой нейрон будет соответствовать данному классу входных векторов. Тем не менее это планирование легко проводится путем тестирования сети после обучения.
Алгоритм трактует набор из n входных весов нейрона как вектор в n-мерном пространстве. Перед обучением каждый компонент этого вектора весов инициализируется в случайную величину. Затем каждый вектор нормализуется в вектор с единичной длиной в пространстве весов. Это делается делением каждого случайного веса на квадратный корень из суммы квадратов компонент этого весового вектора.
Все входные вектора обучающего набора также нормализуются и сеть обучается согласно следующему алгоритму:
1. Вектор Х подается на вход сети.
2. Определяются расстояния Dj (в n-мерном пространстве) между Х и весовыми векторами Wj каждого нейрона. В евклидовом пространстве это расстояние вычисляется по следующей формуле
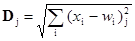 ,
,
где хi – компонента i входного вектораX, wij – вес входа i нейрона j.
3. Нейрон, который имеет весовой вектор, самый близкий к X, объявляется победителем. Этот весовой вектор, называемый Wc, становится основным в группе весовых векторов, которые лежат в пределах расстояния D от Wc.
4. Группа весовых векторов настраивается в соответствии со следующим выражением:
для всех весовых векторов в пределах расстояния D от Wc
5. Повторяются шаги с 1 по 4 для каждого входного вектора.
В процессе обучения нейронной сети значения D и a постепенно уменьшаются. Автор [3] рекомендовал, чтобы коэффициент a в начале обучения устанавливался приблизительно равным 1 и уменьшался в процессе обучения до 0, в то время как D может в начале обучения равняться максимальному расстоянию между весовыми векторами и в конце обучения стать настолько маленьким, что будет обучаться только один нейрон.
В соответствии с существующей точкой зрения, точность классификации будет улучшаться при дополнительном обучении. Согласно рекомендации Кохонена, для получения хорошей статистической точности количество обучающих циклов должно быть, по крайней мере, в 500 раз больше количества выходных нейронов.
Обучающий алгоритм настраивает весовые векторы в окрестности возбужденного нейрона таким образом, чтобы они были более похожими на входной вектор. Так как все векторы нормализуются в векторы с единичной длиной, они могут рассматриваться как точки на поверхности единичной гиперсферы. В процессе обучения группа соседних весовых точек перемещается ближе к точке входного вектора. Предполагается, что входные векторы фактически группируются в классы в соответствии с их положением в векторном пространстве. Определенный класс будет ассоциироваться с определенным нейроном, перемещая его весовой вектор в направлении центра класса и способствуя его возбуждению при появлении на входе любого вектора данного класса.
После обучения классификация выполняется посредством подачи на вход сети испытуемого вектора, вычисления возбуждения для каждого нейрона с последующим выбором нейрона с наивысшим возбуждением как индикатора правильной классификации.
Литература
1. Grossberg S. 1974. Classical and instrumental learning by neural networks. Progress in theoretical biology, vol. 3, pp. 51–141. New York: Academic Press.
2. Hebb D. O. 1949. Organization of behavior. New York: Science Editions.
3. Kohonen T. 1984. Self–organization and associative memory. Series in Information Sciences, vol. 8. Berlin: Springer verlag.
4. Rosenblatt R. 1959. Principles of neurodynamics. New York: Spartan Books.
5. Widrow B. 1959 Adaptive sampled–data systems, a statistical theory of adaptation. 1959. IRE WESCON Convention Record, part 4. New York: Institute of Radio Engineers.
6. Widrow В., Hoff M. 1960. Adaptive switching circuits. I960. IRE WESCON Convention Record. New York: Institute of Radio Engineers.
Источник
Русские Блоги
Статистические методы обучения — основы статистического обучения (1)
Статистические методы обучения — статистическое обучение
Введение в статистическое обучение (1)
Статистическое обучение
Характеристики статистического обучения
- Построен на базе компьютера и сети
- Принимать данные в качестве объекта исследования
- Основные предположения: Подобные данные имеют определенную статистическую закономерность.
- Ориентация на методы
- Общий метод
- Контролируемое обучение
- Обучение без учителя
- Полу-контролируемое обучение
- Обучение с подкреплением
- Общий метод
- Цель — прогнозировать и анализировать данные
Статистический метод обучения
- Обучение с учителем
- Из Дано, ограничено, для обучения Вылет тренировочного набора
- Предполагая, что данные независимы и одинаково распределены
- Предположим, что модель, которую нужно изучить, принадлежит набору функций, называемых Гипотетическое пространство
- использование стандарт оценки Выберите лучшую модель из пространства гипотез
Можно резюмировать Три элемента статистического обучения: модель, стратегия и алгоритм.
Контролируемое обучение
Задача обучения с учителем состоит в том, чтобы изучить модель, чтобы модель могла делать хорошие прогнозы для любых заданных входных данных.
базовые концепции
- Пространство ввода: вся доступная информация, относящаяся к образцу, обозначена как X X X
- Пространство признаков: пространство, в котором существуют все векторы признаков, обычно неотличимое от пространства ввода.
- Выходное пространство: обычно результат классификации (прогноза), обозначается как Y Y Y
- Совместное распределение вероятностей
- Обучение с учителем предполагает случайные переменные для ввода и вывода X X X с участием Y Y Y Следуйте совместному распределению вероятностей P ( X , Y ) P(X,Y) P ( X , Y ) 。
- Данные в обучающем наборе и тестовом наборе рассматриваются как совместное распределение вероятностей. P ( X , Y ) P(X,Y) P ( X , Y ) Независимые и одинаково распределенные производится.
- Пространство гипотез: модель принадлежит набору отображений из входного пространства в выходное пространство. Этот набор является пространством гипотез, обозначенным как F \mathcal
F 。
F = < f ∣ Y = f ( X ) >\mathcal=\left\
На этом этапе A \mathcal A Обычно это семейство функций, определяемых вектором параметров:
F = < f ∣ Y = f θ ( X ) , θ ∈ R n >\mathcal=\left\
вектор параметров θ \theta θ Возьмите значение в n n n Vieux Space R n R^n R n , Вызывается пространство параметров. - Модель обучения с учителем: это может быть вероятностная модель или не вероятностная модель, она определяется условным распределением вероятностей. P ( Y ∣ X ) P(Y|X) P ( Y ∣ X ) Или функция принятия решения Y = f ( x ) Y=f(x) Y = f ( x ) Сказал.
Формализовать проблему
Простая диаграмма показывает процесс обучения с учителем: 
Три элемента статистического обучения
Метод = модель + стратегия + алгоритм
модель
- Пространство гипотез модели содержит все возможные условные распределения вероятностей или решающие функции.
Стратегия
- Обдумывал, как выбрать лучшую модель
- Связанные функции
- Функция потерь
- 0-1 функция потерь:
L ( Y , f ( X ) ) = < 1 Y ≠ f ( X ) 0 Y = f ( X ) L\left(1\quad Y \ne f\left( X \right)\\ 0\quad Y = f\left( X \right) \end \right. L ( Y , f ( X ) ) = < 1 Y ̸ = f ( X ) 0 Y = f ( X ) - Функция квадратичных потерь:
L ( Y , f ( X ) ) = ( Y − f ( X ) ) 2 L\left(\right)^2> L ( Y , f ( X ) ) = ( Y − f ( X ) ) 2 - Функция абсолютных потерь:
L ( Y , f ( X ) ) = ∣ Y − f ( X ) ∣ L\left(\right| L ( Y , f ( X ) ) = ∣ Y − f ( X ) ∣ - Функция потери журнала:
L ( Y , P ( Y ∣ X ) ) = − log P ( Y ∣ X ) L\left(
- 0-1 функция потерь:
- Функция риска:
- Функция риска (ожидаемый убыток)
Ожидание функции потерь (Поскольку ввод и вывод следуют совместному распределению P ( X , Y ) P\left(X,Y\right) P ( X , Y ) ) Называется функцией риска или ожидаемым убытком:
R exp ( f ) = E p [ L ( Y , f ( X ) ) ] = ∫ X × Y L ( y , f ( x ) ) P ( x , y ) d x d y\left[ \times \mathcal > - Риск опыта (потеря опыта)
для Средняя потеря на тренировочной выборке Риск возникновения опыта или потеря опыта:
R e m p ( f ) = 1 N ∑ i = 1 N L ( y i , f ( x i ) )\sum\limits_^N > \right)> \right)> R e m p ( f ) = N 1 i = 1 ∑ N L ( y i , f ( x i ) )
- Функция риска (ожидаемый убыток)
- Функция потерь
- Свести к минимуму риск возникновения проблем и минимизировать структурный риск
- Минимизация эмпирического риска (ERM)
Когда размер выборки достаточно велик, риск опыта сводится к минимуму, чтобы обеспечить хороший эффект обучения, то есть решить оптимальную задачу:
min f ∈ F 1 N ∑ i = 1 N L ( y i ∣ f ( x i ) ) \mathop <\min >\limits_> \frac<1> \sum\limits_^N
Оценка максимального правдоподобия Это пример минимизации риска получения опыта.
Но слишком маленькая выборка приведет к «переобучению». - Структурированная минимизация рисков (SRM)
для Предотвратить переобучение И предлагаемая стратегия. Структурированный риск увеличивается на основе опыта риска Срок регуляризации (или штрафной срок) сложности модели , Поэтому он определяется как:
R s r m ( f ) = 1 N ∑ i = 1 N L ( y i , f ( x i ) ) + λ J ( f )\sum\limits_^N > \right)> \right)> + \lambda J\left( f \right) R s r m ( f ) = N 1 i = 1 ∑ N L ( y i , f ( x i ) ) + λ J ( f )
где J ( f ) J\left( f \right) J ( f ) Чем сложнее модель, чем больше функция, тем сложнее; λ ≥ 0 \lambda\ge 0 λ ≥ 0 Коэффициент используется для взвешивания эмпирического риска и сложности модели.
Оценка максимальной апостериорной вероятности в байесовской оценке Это пример минимизации структурного риска.
- Минимизация эмпирического риска (ERM)
алгоритм
После определения набора обучающих данных, стратегии обучения и выбора лучшей модели из пространства гипотез необходимо подумать, какой алгоритм использовать для решения оптимальной модели.
Оценка модели и выбор модели (1)
Ошибка обучения и ошибка теста
Предположим, что изученный алгоритм Y = f ^ ( X ) Y=\hat f(X) Y = f ^ ( X )
Переоборудование, неполное оснащение и выбор модели
Выбор модели должен основываться на реальной ситуации, которая должна аппроксимировать так называемую «истинную модель», а не только на оценке влияния модели на производительность обучающей выборки.
- Переоснащение и недооборудование
Сначала рассмотрим практический пример:
- Переоснащение
слепо стремиться улучшить предсказательную способность обучающей выборки (узнавая о существовании обучающей выборки Характеристики ),модель Слишком сложно ,довольно часто Более сложный, чем «истинная модель» 。
Возможности: Он хорошо работает с известными данными и плохо работает с неизвестными. - Underfitting
Недостаточную подгонку относительно легко понять, это означает, что обучающие образцы Не умею хорошо учиться в природе 。
На следующем рисунке показаны чрезмерная и недостаточная подгонка под другим углом (M представляет собой количество кратных), которые можно легко найти:
- когда M = 0 M=0 M = 0 Когда, это всего лишь одно и x x x Прямые параллельны оси, никакой полезной информации не узнал;
- когда M = 1 M=1 M = 1 В настоящее время прямая линия в некоторой степени наклонена, но на самом деле она далека от «истинной модели» и все еще находится в состоянии «недостаточного соответствия».
- когда M = 9 M=9 M = 9 Когда изображение проходит все известные точки, но изображение очень сложное и отклоняется от «истинной модели», можно предположить, что его использование для прогнозирования также приведет к очень плохим результатам.
На рисунке ниже также показаны изменения ошибки обучения и ошибки тестирования по мере изменения сложности модели.
- Переоснащение



Источник



