
- ПРИЛОЖЕНИЕ. Существуют различные подходы к классификации интернет-ресурсов
- Классификация интернет-ресурсов в библиотеках
- Содержание
- Основания деления
- По способу доступа
- По отношению владельца ресурса к авторству
- По способу производства ресурса
- По размещению
- По составу
- По регулярности обновления
- По способу передачи информации
- По способу генерации информации
- Источники
- Полезное
- Смотреть что такое «Классификация интернет-ресурсов в библиотеках» в других словарях:
- Полное руководство по инкрементной регенерации статических сайтов с помощью Next.js
- Проблема SSG
- Системы управления контентом
- Разбор примера
- ▍Загрузка данных
- ▍Генерирование путей
- Компромиссы
- ▍Серверный рендеринг
- ▍Генерирование статических сайтов
- ▍Клиентский рендеринг
- Особенности настройки параметра fallback при применении ISR
- ISR — это не только кеширование!
- Примеры применения ISR
ПРИЛОЖЕНИЕ. Существуют различные подходы к классификации интернет-ресурсов
Существуют различные подходы к классификации интернет-ресурсов. Различия в подходах обусловлены целями, для которых разрабатывается классификация. Например, могут быть классификации в целях технического и программного обеспечения, в целях обеспечения бизнес-процессов, в целях удовлетворения тематических запросов, классификации отдельных видов интернет-ресурсов — сайтов и др. В зависимости от подхода выбирается набор признаков классификации.
Теоретически можно объединить все существующие классификации интернет-ресурсов в одну всеобъемлющую классификацию. Однако практическая ценность такой глобальной классификации будет ниже, чем ценность отдельных классификаций, созданных с учётом конкретных потребностей.
В библиотеках интернет-ресурсы рассматриваются преимущественно как источники социально значимой информации (по аналогии с печатными документами). Свою задачу при работе с интернет-ресурсами библиотеки видят в том, чтобы отбирать наиболее ценные с точки зрения своих пользователей ресурсы и обеспечивать к ним удобный доступ. Организация работы по выполнению этих задач невозможна без классификации интернет-ресурсов в интересах библиотечной деятельности.
1-я классификация:
· Интернет-есурсы для образовательных целей и научных исследований (образовательные сайты, порталы, электронные библиотеки, аудио- и видеофрагменты и др.)
· Отечественные и зарубежные справочные ресурсы Интернет (электронные энциклопедии, словари и справочники)
· Отечественные и зарубежные электронные каталоги библиотек и аналитические библиографические базы данных
· Отечественные и зарубежные бесплатные электронные библиотеки
· Отечественные и зарубежные профессиональные коммерческие полнотекстовые базы электронных библиотек
· К вопросу о поиске Интернет-ресурсов. Поисковые системы
· Интернет-книга. Интернет-магазин. Аудиокниги
2-я классификация:
· Первый вид интернет ресурсов – это информационные сайты. На таких сайтах можно найти статьи (например о школьных предметах, таких как информатика, математика, физика и др.), новости, изображения, видео и прочее. Начинающие вебмастера предпочитают создавать информационные сайты.
· Второй вид – это сайты с объявлениями, например, доски, форумы, каталоги. Преимущество досок объявлений в том, что посетители сами будут наполнять сайт, а значит, вам не нужно будет думать о контенте для сайта.
· Третий вид – это блоги. В последнее время они очень популярны. Отличие блогов от обычных сайтов в том, что публикуются не только обычные статьи, а ваш личный опыт, ваши впечатления. На блоге может быть несколько авторов. Ну и последний вид – это крупные порталы. Там собирается вся информация, люди могут добавлять свои объявления, публиковать записи в блогах, комментировать статьи, общаться на форумах. Чем старше портал, тем активнее будут на нем общаться.
3-я классификация:
· По способу доступа:открытый доступ,ограниченный доступ
· По отношению владельца ресурса к авторству:собственного авторства,авторства третьей стороны
· По способу производства ресурса:изначально созданные в цифровом виде,оцифрованные По размещению:автономные сайты,разделы сайтов
· По регулярности обновления:периодически обновляемые,нерегулярно обновляемые, необновляемые
· По способу передачи информации:текст,видео,аудио,графика,мультимедиа,квест
· По способу генерации информации:статические,динамические (генерирующие ответы на запросы к базам данных)
Источник
Классификация интернет-ресурсов в библиотеках
Существуют различные подходы к классификации интернет-ресурсов. Различия в подходах обусловлены целями, для которых разрабатывается классификация. Например, могут быть классификации в целях технического и программного обеспечения, в целях обеспечения бизнес-процессов, в целях удовлетворения тематических запросов, классификации отдельных видов интернет-ресурсов — сайтов и др. В зависимости от подхода выбирается набор признаков классификации.
Теоретически можно объединить все существующие классификации интернет-ресурсов в одну всеобъемлющую классификацию. Однако практическая ценность такой глобальной классификации будет ниже, чем ценность отдельных классификаций, созданных с учётом конкретных потребностей.
В библиотеках интернет-ресурсы рассматриваются преимущественно как источники социально значимой информации (по аналогии с печатными документами). Свою задачу при работе с интернет-ресурсами библиотеки видят в том, чтобы отбирать наиболее ценные с точки зрения своих пользователей ресурсы и обеспечивать к ним удобный доступ. Организация работы по выполнению этих задач невозможна без классификации интернет-ресурсов в интересах библиотечной деятельности.
Для работы с интернет-ресурсами библиотекам важна классификация по следующим признакам:
Содержание
Основания деления
По способу доступа
- открытый доступ
- ограниченный доступ (коммерческие, корпоративные, личные ограничения)
По отношению владельца ресурса к авторству
- собственного авторства
- авторства третьей стороны
По способу производства ресурса
- изначально созданные в цифровом виде
- оцифрованные (владельцем ресурса, третьей стороной)
По размещению
По составу
По регулярности обновления
- периодически обновляемые
- нерегулярно обновляемые
- необновляемые
По способу передачи информации
По способу генерации информации
- статические
- динамические (генерирующие ответы на запросы к базам данных)
Источники
- Антопольский А. Б. Электронные библиотеки: принципы создания: Науч.-метод. пос. / Антопольский А. Б., Майстрович Т. В. . — М.: ЛИБЕРЕЯ-БИБИНФОРМ,2007. — 288 с.
- ГОСТ 7.83-2001 «Электронные издания. Основные виды и выходные сведения
- Елисина Е. Ю. Обеспечение доступа к электронным документам в библиотеках: теория и практика: Автореф. дисс. … канд. пед. н. / Е. Ю. Елисина; РГБ. — М., 2008. — 18 с.
- Земсков А. И. Электронная информация и электронные ресурсы: публикации и документы, фонды и библиотеки / А. И. Земсков, Я. Л. Шрайберг. — М.: ФАИР, 2007. — 528 с.
- Лязина, И. В. Требования к электронным изданиям, как к объектам комплектования библиотечных фондов и регистрации электронных научных изданий (сетевых электронных изданий [Электронный ресурс] : презентация доклада / И. В. Лязина/ / Электронно-библиотечная система в ВУЗе: проблемы и направления развития: Семинар, (Санкт-Петербург, 20-21 октября 2010 г.). — СПб., 2010.
- Писляков В. В. Базы данных научных информационных источников: структура и классификация // Инфометрическое моделирование процесса обращения к электронным информационным ресурсам : Дисс. … канд. физ. — мат. н. / В. В. Писляков. — Казань, 2008. — С. 17 — 19.
- Романюк Э. И. Мировые информационные электронные ресурсы по научной тематике: классификация и возможные варианты доступа и поиска : Обзорная статья [Электронный ресурс]. — 2008.
- Столяров Ю. Н. Электронный библиотечный фонд / Ю. Н. Столяров // Библиотечные фонды: проблемы и решения: Электронный журнал-препринт. — 2003. — № 5.

- Проставить интервики в рамках проекта Интервики.
- Добавить иллюстрации.
Wikimedia Foundation . 2010 .
Полезное
Смотреть что такое «Классификация интернет-ресурсов в библиотеках» в других словарях:
Интернет-издание — Эту страницу предлагается объединить с Новостной сайт. Пояснение причин и обсуждение на странице Википедия:К объединению/27 августа 2012. Обсуждение длится одну неделю (или дол … Википедия
Фильтрация и блокирование интернет-контента: мировой опыт — Ниже приводится справочная информация о законодательном регулировании и способах фильтрации интернет контента в других странах. Великобритания Регулирующий орган: Фонд интернет наблюдения (Internet Watch Foundation); Совет по безопасности детей в … Энциклопедия ньюсмейкеров
Десятичная классификация Дьюи — Эту статью следует викифицировать. Пожалуйста, оформите её согласно правилам оформления статей. Десятичная классификация Дьюи система классификации книг, разработанная в XIX веке … Википедия
Электронная библиотека — У этого термина существуют и другие значения, см. библиотека (значения). Электронная библиотека упорядоченная коллекция разнородных электронных документов (в том числе книг), снабженных средствами навигации и поиска. Может быть веб сайтом,… … Википедия
Документ — Уровни секретности Уровни секретности документов в СССР Максимальный CC/ОП (Совершенно Секретно. Особая Папка) ОП (Особая Папка) ОВ (Особой Важности) СС (Совершенно Секретно) С (Секретно) ДСП (Для служебного пользования) Мин … Википедия
Кодекс — (Code) Кодексы Российской Федерации, классификация кодексов РФ, система и доктрина кодекса Уголовный кодекс РФ, кодексы народов майя, трудовой кодекс, гражданский кодекс, налоговый кодекс, жилищный кодекс, административный кодекс, семейный кодекс … Энциклопедия инвестора
Информация — (Information) Информация это сведения о чем либо Понятие и виды информации, передача и обработка, поиск и хранение информации Содержание >>>>>>>>>>>> … Энциклопедия инвестора
Информация — Для улучшения этой статьи желательно?: Найти и оформить в виде сносок ссылки на авторитетные источники, подтверждающие написанное. Добавить иллюстрации. Добавить информацию для других стран и реги … Википедия
Источник
Полное руководство по инкрементной регенерации статических сайтов с помощью Next.js
Год назад во фреймворке Next.js 9.3 появилась поддержка генерирования статических сайтов (Static Site Generation, SSG), что сделало его первым гибридным фреймворком. Я к тому моменту уже несколько лет с удовольствием пользовался Next.js. Но тот релиз сделал Next.js моим новым стандартным инструментом. После того, как я много и серьёзно поработал с Next.js, я присоединился к Vercel для того чтобы помогать компаниям, вроде Tripadvisor и Washington Post, в деле внедрения Next.js и расширения того, что у них получилось.
В этом материале мне хотелось бы исследовать новый виток эволюции Jamstack — механизм инкрементной регенерации статических сайтов (Incremental Static Regeneration, ISR). Здесь вы найдёте руководство по ISR, а так же — практические примеры использования этой технологии, демонстрационные проекты и рассказ о сопутствующих внедрению ISR компромиссах.

Если в двух словах описать ISR, то окажется, что эта технология позволяет, при внесении каких-то изменений в материалы сайта, мгновенно обновлять статический контент. Полная пересборка проекта при этом не нужна. Гибридный подход Next.js позволяет использовать ISR в сфере электронной коммерции, при подготовке маркетинговых и рекламных страниц, при организации работы блогов и во многих других случаях.
Проблема SSG
В основе Jamstack лежит привлекательная идея: сайты представляют собой заранее отрендеренные статические страницы, которые можно отправить на CDN, и с которыми, через считанные секунды после этого, смогут работать пользователи со всего мира. Статические страницы быстры, статические сайты устойчивы к сбоям, их очень быстро индексируют поисковые роботы. Но и тут имеются некоторые проблемы.
Если архитектура Jamstack используется при разработке крупномасштабного статического сайта, это значит, что создателям сайта, возможно, придётся тратить долгие часы на его сборку. Если количество страниц сайта удвоится — удвоится и время сборки. Взглянем, например, на Target.com. Реально ли сгенерировать миллионы статических страниц товаров при каждом развёртывании сайта?

Проблема генерирования статических сайтов: так как время сборки линейно зависит от количества страниц — сборка сайта может занять многие часы
Даже если каждая статическая страница, что нереально, будет сгенерирована за 1 мс, на пересборку всего сайта, всё равно, уйдёт несколько часов. В случае с большими веб-приложениями использование SSG для всех материалов таких приложений — это крайне неудачная затея. Команды, работающие над крупными проектами, нуждаются в более гибких гибридных решениях, учитывающих индивидуальные особенности таких проектов.
Системы управления контентом
При работе над многими веб-проектами практикуется отделение контента этих проектов от их кода. Использование систем управления контентом (Content Management System, CMS) без пользовательского интерфейса позволяет редакторам сайтов публиковать новые и изменённые материалы, не привлекая к решению этой задачи программистов. Но если речь идёт о традиционных статических сайтах, то этот процесс может быть довольно медленным.
Представим себе интернет-магазин, в котором имеется 100000 товаров. Их цены часто меняются. Когда редактор меняет, в рамках акции, цену наушников с $100 на $75, применяемая на сайте CMS задействует веб-хук для запуска пересборки всего сайта. Нереально ждать многие часы того момента, когда новая цена появится на сайте.
Длительные процессы сборки сайтов, в ходе которых выполняются вычисления, в которых нет необходимости, могут приводить к дополнительным расходам. В идеале приложение должно быть достаточно интеллектуальным для того чтобы понимать то, данные какого именно товара изменены, и инкрементально, не испытывая необходимости в полной пересборке сайта, обновлять соответствующие страницы.
Next.js позволяет создавать или обновлять статические страницы после того, как выполнена сборка сайта. Инкрементная регенерация статических сайтов позволят разработчикам и редакторам использовать механизмы генерирования статических сайтов в применении к отдельным страницам, без необходимости пересобирать весь сайт. Применение ISR позволяет сохранить сильные стороны SSG в масштабах проектов, состоящих из миллионов страниц.
Благодаря использованию ISR статические страницы могут быть сгенерированы во время работы проекта (по запросу), а не во время его сборки. Используя аналитические данные, A/B-тестирование, или другие метрики, разработчик, видя плюсы и минусы ISR и SSG, сознательно идя на определённые компромиссы, получает возможность гибкой настройки процессов сборки проекта.
Вспомним вышеприведённый пример интернет-магазина, в котором имеется 100000 товаров. Если на генерирование страницы для одного товара уйдёт 50 мс, что вполне реально, то без использования ISR на сборку всего сайта понадобится почти 2 часа. Других вариантов тут нет. А вот если применяется ISR — у разработчика сайта появляется возможность выбора одного из сценариев сборки:
- Ускорение сборки. Во время сборки проекта генерируются страницы для 1000 самых популярных товаров. Запросы, выполненные к страницам других товаров, рассматриваются как промахи кеша. Запрошенные страницы, статические, генерируются по запросу. Речь идёт о сборках длительностью в 1 минуту.
- Повышение частоты попаданий в кеш. Во время сборки проекта генерируется 10000 страниц, что позволяет обеспечить кеширование большего числа страниц товаров до поступления запросов на их загрузку. Этот вариант предусматривает выполнение сборок длительностью 8 минут.
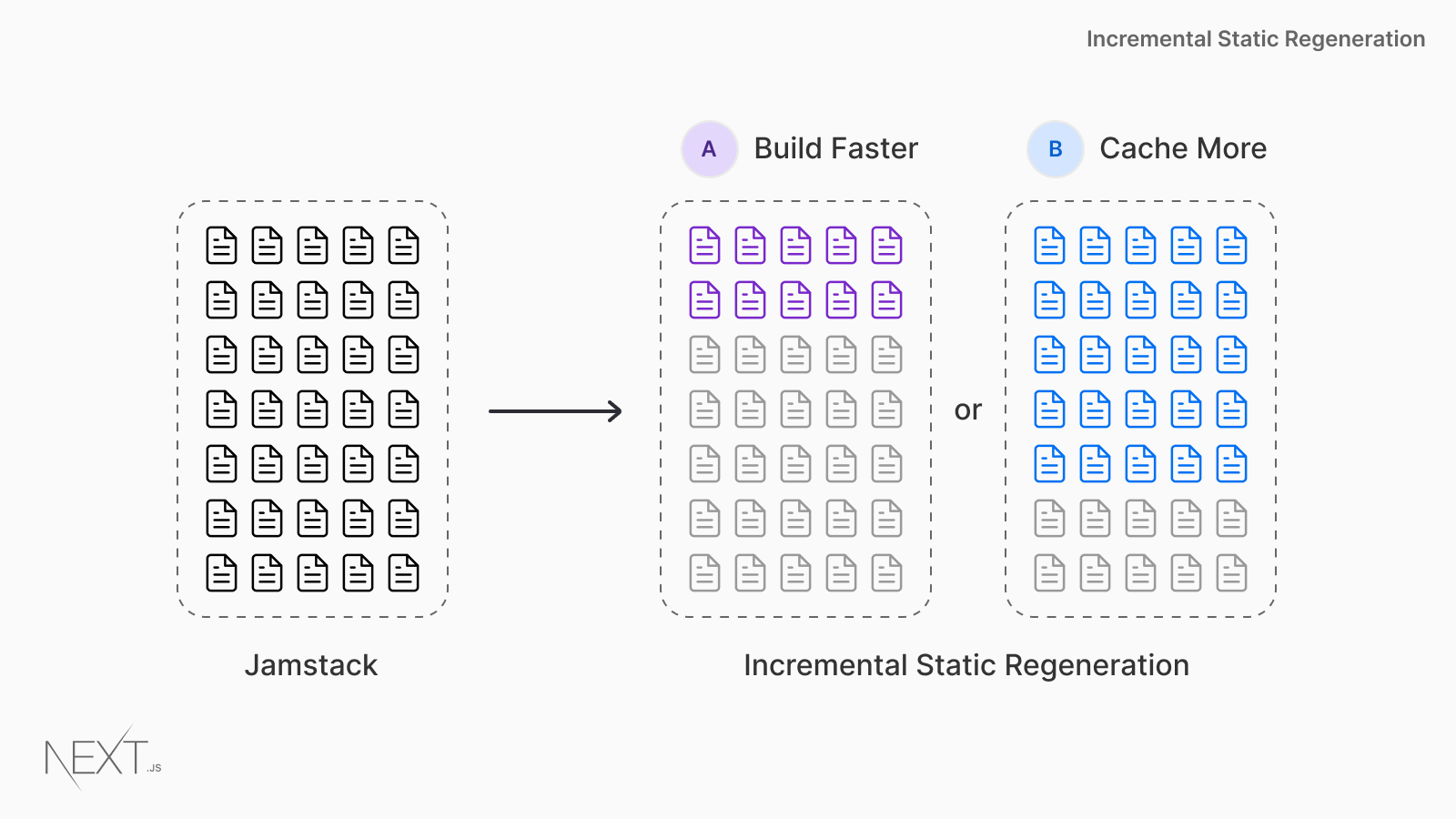
Преимущества ISR: у разработчика есть возможность выбора стратегии генерирования страниц во время сборки проекта. Вариант A позволяет ускорить сборки, вариант B позволяет кешировать больше готовых страниц
Теперь давайте подробнее рассмотрим наш пример использования ISR в интернет-магазине.
Разбор примера
▍Загрузка данных
Если вы не пользовались раньше Next.js, то я порекомендовал бы почитать этот материал для того чтобы разобраться с основами. ISR использует тот же API, который применяется при генерировании статических сайтов — getStaticProps. Мы, устанавливая параметр revalidate в значение 60 , сообщаем Next.js о том, что для обрабатываемой страницы нужно применять ISR.
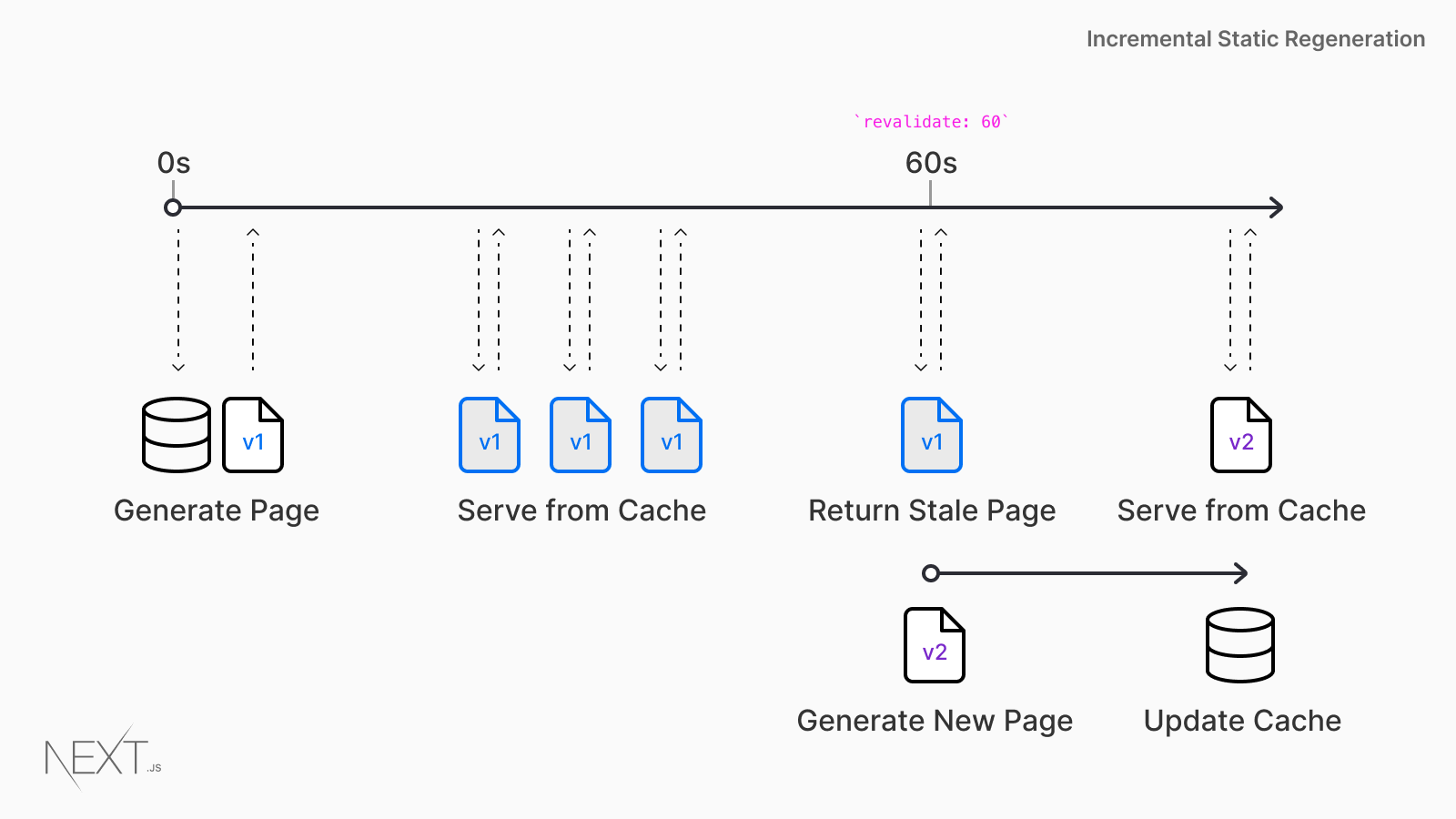
Последовательность запросов, используемых при реализации ISR
- Next.js позволяет указать время повторной валидации для каждой страницы. Установим его в 60 секунд.
- Первый запрос к странице товара приведёт к передаче клиенту кешированной страницы с исходной ценой товара.
- В данные товара, хранящиеся в CMS, вносятся изменения.
- Запросы, выполняемые к странице после первого запроса и до истечения 60 секунд, обслуживаются из кеша, ответы на них отдают клиенту мгновенно.
- Если по истечении интервала в 60 секунд поступает запрос на загрузку той же страницы — в ответ на него выдаётся её кешированная (устаревшая) версия. Next.js запускает фоновый процесс регенерации страницы.
- После того, как страница будет успешно сгенерирована, Next.js инвалидирует кеш и в ответ на запросы к этой странице выдаётся её обновлённый вариант. Если фоновая регенерация страницы не удалась — в кеше остаётся старая неизменённая страница.
▍Генерирование путей
Next.js позволяет настраивать то, какие страницы товаров нужно генерировать во время сборки проекта, а какие — по запросу. Сгенерируем во время сборки проекта лишь страницы для 1000 самых популярных товаров, передав системе в getStaticPath список идентификаторов соответствующих товаров.
Нам нужно настроить поведение системы в ситуации, когда кто-то запрашивает страницу продукта, которая не была сгенерирована в ходе первоначальной сборки проекта. Для этого используется параметр fallback , который может принимать значения blocking и true .
- fallback: blocking (рекомендуется использовать именно это значение). Когда возникает необходимость в странице, которая ещё не сгенерирована, Next.js выполнит серверный рендеринг этой страницы по первому запросу. При обработке следующих запросов к этой странице в ответ на них из кеша будет выдаваться статический файл.
- fallback: true . Когда возникает необходимость в ещё не сгенерированной странице — Next.js немедленно, по первому запросу, возвратит статическую страницу с индикатором загрузки. Когда завершится загрузка данных — будет выполнен повторный рендеринг этой страницы, новые данные будут помещены в кеш. При обслуживании следующих запросов к той же странице будет использован статический файл из кеша.
Компромиссы
Конечный пользователь — это основной объект внимания Next.js. Понятие «лучший способ работы со статическими страницами» относительно, его смысл зависит от отрасли экономики, к которой принадлежит проект, от его аудитории, от внутренних особенностей приложения. Next.js позволяет разработчикам реализовывать разные стратегии работы со статическим контентом и при этом не покидать границ фреймворка. Благодаря этому, используя Next.js, можно подобрать именно то, что лучше всего подходит для конкретного проекта.
▍Серверный рендеринг
ISR — это не всегда именно то, что нужно некоему проекту. Например, лента новостей Facebook не может выводить устаревшие данные. В данном случае имеет смысл прибегнуть к серверному рендерингу (Server-Side Rendering, SSR) и, возможно, к использованию собственных заголовков Cache-Control с суррогатными ключами для инвалидации содержимого различных кешей. Так как Next.js — это гибридный фреймворк — у разработчика есть возможность пойти на компромисс, связанный с использованием SSR, но при этом не покидать границ фреймворка.
SSR и кеширование данных на пограничных системах напоминает ISR (особенно — при использовании заголовков stale-while-revalidate для управления кешем). Основная разница между ними заключается в том, как именно обрабатывается первый запрос. При использовании ISR можно сделать так, чтобы в ответ на первый запрос к некоей странице, при условии её предварительного рендеринга, гарантированно выдавался бы её статический вариант. Даже если база данных проекта вдруг оказалась недоступной, или если возникли проблемы, относящиеся к взаимодействию с API, пользователь проекта, всё равно, увидит правильную статическую страницу. Но SSR позволяет настраивать страницы, ориентируясь на особенности входящих запросов.
Обратите внимание на то, что использование SSR без кеширования может привести к ухудшению производительности проекта. Когда пользователь ждёт вывода страницы проекта — важна каждая миллисекунда. Использование SSR без кеширования, кроме того, может очень плохо сказаться на показателе TTFB (Time to First Byte, время до первого байта).
▍Генерирование статических сайтов
ISR не всегда имеет смысл применять на маленьких сайтах. Если период ревалидации контента больше, чем время, необходимое на пересборку всего сайта, то вместо ISR вполне можно использовать традиционный подход по генерированию статических сайтов.
▍Клиентский рендеринг
Если React на сайте используется без Next.js — это значит, что речь идёт о клиентском рендеринге сайта (Client-Side Rendering, CSR). Приложение отдаёт посетителю страницу, пребывающую в некоем исходном состоянии, после чего, из JavaScript-кода, работающего на клиенте, выполняются запросы на загрузку дополнительных данных (например — с применением useEffect ). Хотя это и расширяет возможности по хостингу сайтов (так как при таком подходе нет абсолютной необходимости в сервере приложения), у такого подхода есть и свои недостатки.
Например, то, что в CSR-проектах нет страниц, заранее отрендеренных на основе исходной HTML-разметки, ухудшает возможности по SEO. Кроме того, CSR-страницы не будут работать при выключенном на клиенте JavaScript.
Особенности настройки параметра fallback при применении ISR
Если данные могут быть загружены очень быстро — имеет смысл присмотреться к параметру fallback: blocking . Тогда не придётся заботиться о показе клиенту страницы, предлагающей подождать, и при обращении к любой странице клиент всегда получит одно и то же (вне зависимости от того, кеширована ли эта страница). Если же данные загружаются медленно — применение fallback: true позволяет немедленно показать пользователю временную страницу.
ISR — это не только кеширование!
Хотя я, говоря об ISR, всё время обсуждал кеширование, я не могу не отметить того факта, что эта технология спроектирована так, чтобы сохранять сгенерированные страницы между сеансами развёртывания проектов. Это значит, что у владельца проекта есть возможность мгновенного отката на его предыдущую версию и возможность не терять ранее сгенерированные страницы.
Каждому развёртыванию можно назначить ключ, представляющий собой некий идентификатор (ID). Этот ID Next.js использует для организации постоянного хранения сгенерированных страниц. При откате проекта можно поменять ключ так, чтобы он указывал бы на предыдущее развёртывание, что позволяет выполнять атомарные развёртывания проектов. Это значит, что можно заглянуть на предыдущий иммутабельный вариант развёрнутого проекта, и то, что он будет работать так, как ожидается. Вот пример возврата к предыдущей версии кода с помощью ISR:
- В проект внесён новый код, развёртыванию назначен ID 123.
- Оказалось, что на одной из страниц имеется опечатка — «Smshng Magazine», а надо — «Smashing Magazine».
- Страницу редактируют в CMS, при этом для исправления ошибки не нужно выполнять повторное развёртывание проекта.
- После того, как на странице окажется нужный текст — «Smashing Magazine» — она, на постоянной основе, размещается в хранилище.
- Потом в проект внесён новый код, который содержит серьёзные ошибки, развёртывание получило ID 354.
- Было принято решение откатиться к релизу с ID 123.
- После этого на странице, где была опечатка, остался правильный текст — «Smashing Magazine».
Возможность отката к предыдущим развёртываниям сайта и организация постоянного хранения статических страниц не входят в сферу ответственности Next.js. Они зависят от провайдера. Обратите внимание на то, что ISR отличается от SSR с применением заголовков Cache-Control , так как кешированные данные, по своей природе, действительны лишь ограниченное время. Подобные кеши действительны лишь при работе с определённой версией сайта и при откате к его предыдущей версии очищаются.
Примеры применения ISR
Как уже было сказано, ISR находит успешное применение в самых разных проектах. Вот несколько примеров:
Источник



