
- Как правильно вычислить среднее значение?
- В чем проблема?
- Какие способы вычисления среднего бывают?
- Вычисляем среднее арифметическое на SQL
- Вычисляем моду на SQL
- Вычисляем медиану на SQL
- Какой способ все-таки использовать?
- Вывод:
- Средние величины и показатели вариации
- Понятие и виды средних величин
- Степенные средние величины
- Средняя арифметическая
- Средняя гармоническая
- Средняя геометрическая
- Средняя квадратическая
- Средняя кубическая
- Структурные средние величины
- Статистическая мода
- Статистическая медиана
- Показатели вариации
- Размах вариации
- Cреднее линейное отклонение
- Линейный коэффициент вариации
- Дисперсия
- Cреднее квадратическое отклонение
- Квадратический коэффициент вариации
Как правильно вычислить среднее значение?

Средняя зарплата… Средняя продолжительность жизни… Практически каждый день мы с вами слышим эти словосочетания, используемые для описания множества одним единственным числом. Но как ни странно, «среднее значение» — достаточно коварное понятие, часто вводящее в заблуждение обычного, неискушенного в математической статистике, человека.
В чем проблема?
Под средним значением чаще всего подразумевается среднее арифметическое, которое очень сильно варьируется под воздействием единичных фактов или событий. И вы не получите реального представления о том, как именно распределены значения, которые вы изучаете.
Давайте обратимся к классическому примеру со средней зарплатой.
В какой-то абстрактной компании работает десять сотрудников. Девять из них получают зарплату около 50 000 рублей, а один 1 500 000 рублей (по странному совпадению он же является генеральным директором этой компании).
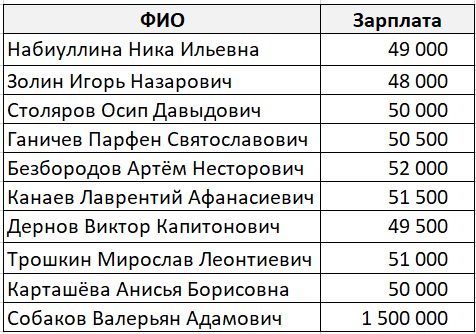
Средним значением в данном случае будет 195 150 рублей, что согласитесь, неправильно.
Какие способы вычисления среднего бывают?
Первым способом является вычисление уже упомянутого среднего арифметического, являющегося суммой всех значений, деленной на их количество.
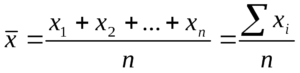
- x – среднее арифметическое;
- xn – конкретное значение;
- n – количество значений .
- Хорошо работает при нормальном распределении значений в выборке;
- Легко вычислить;
- Интуитивно понятно.
- Не дает реального представления о распределении значений;
- Неустойчивая величина легко поддающаяся выбросам (как в случае с генеральным директором).
Вторым способом является вычисление моды, то есть наиболее часто встречающегося значения.
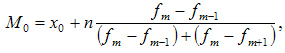
- M0 – мода;
- x0 – нижняя граница интервала, который содержит моду;
- n – величина интервала;
- fm– частота (сколько раз в ряду встречается то или иное значение);
- fm-1 – частота интервала предшествующего модальному;
- fm+1 – частота интервала следующего за модальным.
- Прекрасно подходит для получения представления об общественном мнении;
- Хорошо подходит для нечисловых данных (цвета сезона, хиты продаж, рейтинги);
- Проста для понимания.
- Моды может просто не быть (нет повторов);
- Мод может быть несколько (многомодальное распределение).
Третий способ — это вычисление медианы, то есть значения, которое делит упорядоченную выборку на две половины и находится между ними. А если такого значения нет, то за медиану принимается среднее арифметическое между границами половин выборки.
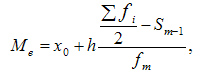
- Me – медиана;
- x0 – нижняя граница интервала, который содержит медиану;
- h – величина интервала;
- f i – частота (сколько раз в ряду встречается то или иное значение);
- Sm-1 – сумма частот интервалов предшествующих медианному;
- fm – число значений в медианном интервале (его частота).
- Дает самую реалистичную и репрезентативную оценку;
- Устойчива к выбросам.
- Сложнее вычислить, так как перед вычислением выборку нужно упорядочить.
Мы рассмотрели основные методы нахождения среднего значения, называющиеся мерами центральной тенденции (на самом деле их больше, но это наиболее популярные).
А теперь давайте вернемся к нашему примеру и посчитаем все три варианта среднего при помощи специальных функций Excel:
- СРЗНАЧ(число1;[число2];…) — функция для определения среднего арифметического;
- МОДА.ОДН(число1;[число2];. ) — функция моды (в более старых версиях Excel использовалась МОДА(число1;[число2];. ) );
- МЕДИАНА(число1;[число2];. ) — функция для поиска медианы.
И вот какие значения у нас получились:
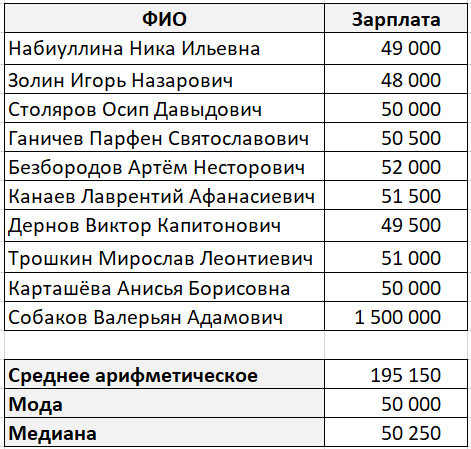
В данном случае мода и медиана гораздо лучше характеризуют среднюю зарплату в компании.
Но что делать, когда в выборке не 10 значений, как в примере, а миллионы? В Excel это не посчитать, а вот в базе данных где хранятся ваши данные, без проблем.
Вычисляем среднее арифметическое на SQL
Тут все достаточно просто, так как в SQL предусмотрена специальная агрегатная функция AVG .
И чтобы ее использовать достаточно написать вот такой запрос:
Вычисляем моду на SQL
В SQL нет отдельной функции для нахождения моды, но ее легко и быстро можно написать самостоятельно. Для этого нам необходимо узнать, какая из зарплат чаще всего повторяется и выбрать наиболее популярную.
Вычисляем медиану на SQL
Как и в случае с модой, в SQL нет встроенной функции для вычисления медианы, зато есть универсальная функция для вычисления процентилей PERCENTILE_CONT .
Выглядит все это так:
Подробнее о работе функции PERCENTILE_CONT лучше почитать в справке Microsoft и Google BigQuery.
Какой способ все-таки использовать?
Из сказанного выше следует, что медиана лучший способ для вычисления среднего значения.
Но это не всегда так. Если вы работаете со средним, то остерегайтесь многомодального распределения:
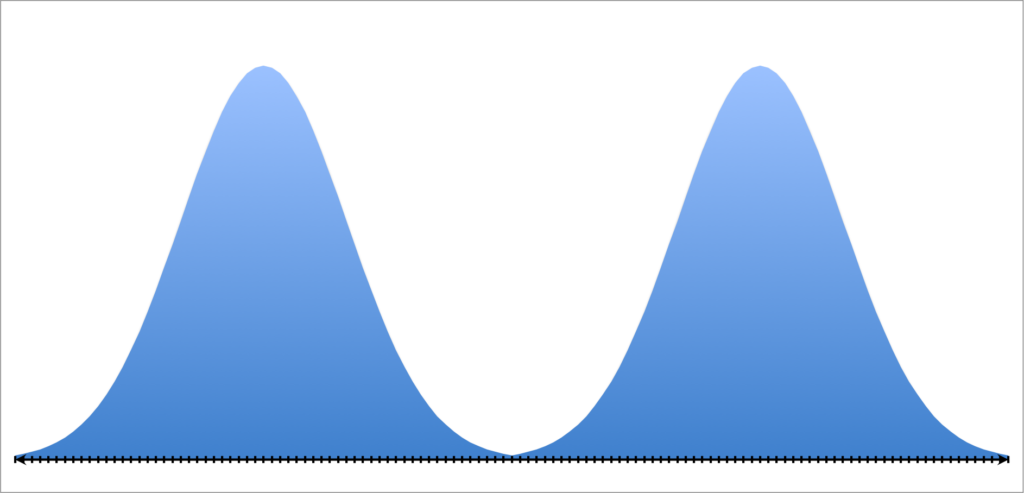
На графике представлено бимодальное распределение с двумя пиками. Такая ситуация может возникнуть, например, при голосовании на выборах.
В данном случае среднее арифметическое и медиана — это значения, находящиеся где-то посередине и они ничего не скажут о том, что происходит на самом деле и лучше сразу признать, что вы имеете дело с бимодальным распределением, сообщив о двух модах.
А еще лучше разделить выборку на две группы и собрать статистические данные для каждой.
Вывод:
При выборе метода нахождения среднего нужно учитывать наличие выбросов, а также нормальность распределения значений в выборке.
Окончательный выбор меры центральной тенденции всегда лежит на аналитике.
Источник
Средние величины и показатели вариации
Понятие и виды средних величин
Средняя величина — это обобщающий показатель статистической совокупности, который погашает индивидуальные различия значений статистических величин, позволяя сравнивать разные совокупности между собой.
Существует 2 класса средних величин: степенные и структурные.
К структурным средним относятся мода и медиана, но наиболее часто применяются степенные средние различных видов.
Степенные средние величины
Степенные средние могут быть простыми и взвешенными.
Простая средняя величина рассчитывается при наличии двух и более несгруппированных статистических величин, расположенных в произвольном порядке по следующей общей формуле:

Взвешенная средняя величина рассчитывается по сгруппированным статистическим величинам с использованием следующей общей формулы:

где X – значения отдельных статистических величин или середин группировочных интервалов;
m — показатель степени, от значения которого зависят следующие виды степенных средних величин:
при m = -1 средняя гармоническая;
при m = 0 средняя геометрическая;
при m = 1 средняя арифметическая;
при m = 2 средняя квадратическая;
при m = 3 средняя кубическая.
Используя общие формулы простой и взвешенной средних при разных показателях степени m, получаем частные формулы каждого вида, которые будут далее подробно рассмотрены.
Средняя арифметическая
Средняя арифметическая — это самая часто используемая средняя величина, которая получается, если подставить в общую формулу m=1. Средняя арифметическая простая имеет следующий вид:

где X — значения величин, для которых необходимо рассчитать среднее значение; N — общее количество значений X (число единиц в изучаемой совокупности).
Например, студент сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5. Рассчитаем средний балл по формуле средней арифметической простой: (3+4+4+5)/4 = 16/4 = 4.
Средняя арифметическая взвешенная имеет следующий вид:

где f — количество величин с одинаковым значением X (частота).
Например, студент сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5. Рассчитаем средний балл по формуле средней арифметической взвешенной: (3*1 + 4*2 + 5*1)/4 = 16/4 = 4.
Если значения X заданы в виде интервалов, то для расчетов используют середины интервалов X, которые определяются как полусумма верхней и нижней границ интервала. А если у интервала X отсутствует нижняя или верхняя граница (открытый интервал), то для ее нахождения применяют размах (разность между верхней и нижней границей) соседнего интервала X.
Например, на предприятии 10 работников со стажем работы до 3 лет, 20 — со стажем от 3 до 5 лет, 5 работников — со стажем более 5 лет. Тогда рассчитаем средний стаж работников по формуле средней арифметической взвешенной, приняв в качестве X середины интервалов стажа (2, 4 и 6 лет):
(2*10+4*20+6*5)/(10+20+5) = 3,71 года.
Средняя арифметическая применяется чаще всего, но бывают случаи, когда необходимо применение других видов средних величин. Рассмотрим такие случаи далее.
Средняя гармоническая
Средняя гармоническая применяется, когда исходные данные не содержат частот f по отдельным значениям X, а представлены как их произведение Xf. Обозначив Xf=w, выразим f=w/X, и, подставив эти обозначения в формулу средней арифметической взвешенной, получим формулу средней гармонической взвешенной:

Таким образом, средняя гармоническая взвешенная применяется тогда, когда неизвестны частоты f, а известно w=Xf. В тех случаях, когда все w=1, то есть индивидуальные значения X встречаются по 1 разу, применяется формула средней гармонической простой:

Например, автомобиль ехал из пункта А в пункт Б со скоростью 90 км/ч, а обратно — со скоростью 110 км/ч. Для определения средней скорости применим формулу средней гармонической простой, так как в примере дано расстояние w1=w2 (расстояние из пункта А в пункт Б такое, же как и из Б в А), которое равно произведению скорости (X) на время (f). Средняя скорость = (1+1)/(1/90+1/110) = 99 км/ч.
Средняя геометрическая
Средняя геометрическая применяется при определении средних относительных изменений, о чем сказано в теме Ряды динамики. Геометрическая средняя величина дает наиболее точный результат осреднения, если задача стоит в нахождении такого значения X, который был бы равноудален как от максимального, так и от минимального значения X.

Например, в период с 2005 по 2008 годы индекс инфляции в России составлял: в 2005 году — 1,109; в 2006 — 1,090; в 2007 — 1,119; в 2008 — 1,133. Так как индекс инфляции — это относительное изменение (индекс динамики), то рассчитывать среднее значение нужно по средней геометрической: (1,109*1,090*1,119*1,133)^(1/4) = 1,1126, то есть за период с 2005 по 2008 ежегодно цены росли в среднем на 11,26%. Ошибочный расчет по средней арифметической дал бы неверный результат 11,28%.
Средняя квадратическая
Средняя квадратическая применяется в тех случая, когда исходные значения X могут быть как положительными, так и отрицательными, например при расчете средних отклонений.

Главной сферой применения квадратической средней является измерение вариации значений X, о чем пойдет речь позднее в этой лекции.
Средняя кубическая
Средняя кубическая применяется крайне редко, например, при расчете индексов нищеты населения для развивающихся стран (ИНН-1) и для развитых (ИНН-2), предложенных и рассчитываемых ООН.

Структурные средние величины
К наиболее часто используемым структурным средним относятся статистическая мода и статистическая медиана.
Статистическая мода
Статистическая мода — это наиболее часто повторяющееся значение величины X в статистической совокупности.
Если X задан дискретно, то мода определяется без вычисления как значение признака с наибольшей частотой. В статистической совокупности бывает 2 и более моды, тогда она считается бимодальной (если моды две) или мультимодальной (если мод более двух), и это свидетельствует о неоднородности совокупности.
Например, на предприятии работает 16 человек: 4 из них — со стажем 1 год, 3 человека — со стажем 2 года, 5 — со стажем 3 года и 4 человека — со стажем 4 года. Таким образом, модальный стаж Мо=3 года, поскольку частота этого значения максимальна (f=5).
Если X задан равными интервалами, то сначала определяется модальный интервал как интервал с наибольшей частотой f. Внутри этого интервала находят условное значение моды по формуле:

где Мо – мода;
ХНМо – нижняя граница модального интервала;
hМо – размах модального интервала (разность между его верхней и нижней границей);
fМо – частота модального интервала;
fМо-1 – частота интервала, предшествующего модальному;
fМо+1 – частота интервала, следующего за модальным.
Например, на предприятии 10 работников со стажем работы до 3 лет, 20 — со стажем от 3 до 5 лет, 5 работников — со стажем более 5 лет. Рассчитаем модальный стаж работы в модальном интервале от 3 до 5 лет: Мо = 3 + 2*(20-10)/(2*20-10-5) = 3,8 (года).
Если размах интервалов h разный, то вместо частот f необходимо использовать плотности интервалов, рассчитываемые путем деления частот f на размах интервала h.
Статистическая медиана
Статистическая медиана – это значение величины X, которое делит упорядоченную по возрастанию или убыванию статистическую совокупность на 2 равных по численности части. В итоге у одной половины значение больше медианы, а у другой — меньше медианы.
Если X задан дискретно, то для определения медианы все значения нумеруются от 0 до N в порядке возрастания, тогда медиана при четном числе N будет лежать посередине между X c номерами 0,5N и (0,5N+1), а при нечетном числе N будет соответствовать значению X с номером 0,5(N+1).
Например, имеются данные о возрасте студентов-заочников в группе из 10 человек — X: 18, 19, 19, 20, 21, 23, 23, 25, 28, 30 лет. Эти данные уже упорядочены по возрастанию, а их количество N=10 — четное, поэтому медиана будет находиться между X с номерами 0,5*10=5 и (0,5*10+1)=6, которым соответствуют значения X5=21 и X6=23, тогда медиана: Ме = (21+23)/2 = 22 (года).
Если X задан в виде равных интервалов, то сначала определяется медианный интервал (интервал, в котором заканчивается одна половина частот f и начинается другая половина), в котором находят условное значение медианы по формуле:

где Ме – медиана;
ХНМе – нижняя граница медианного интервала;
hМе – размах медианного интервала (разность между его верхней и нижней границей);
fМе – частота медианного интервала;  fМе-1 – сумма частот интервалов, предшествующих медианному.
fМе-1 – сумма частот интервалов, предшествующих медианному.
В ранее рассмотренном примере при расчете модального стажа (на предприятии 10 работников со стажем работы до 3 лет, 20 — со стажем от 3 до 5 лет, 5 работников — со стажем более 5 лет) рассчитаем медианный стаж. Половина общего числа работников составляет (10+20+5)/2 = 17,5 и находится в интервале от 3 до 5 лет, а в первом интервале до 3 лет — только 10 работников, а в первых двух — (10+20)=30, что больше 17,5, значит интервал от 3 до 5 лет — медианный. Внутри него определяем условное значение медианы: Ме = 3+2*(0,5*30-10)/20 = 3,5 (года).
Также как и в случае с модой, при определении медианы если размах интервалов h разный, то вместо частот f необходимо использовать плотности интервалов, рассчитываемые путем деления частот f на размах интервала h.
Показатели вариации
Вариация — это различие значений величин X у отдельных единиц статистической совокупности. Для изучения силы вариации рассчитывают следующие показатели вариации: размах вариации, среднее линейное отклонение, линейный коэффициент вариации, дисперсия, среднее квадратическое отклонение, квадратический коэффициент вариации.
Размах вариации
Размах вариации – это разность между максимальным и минимальным значениями X из имеющихся в изучаемой статистической совокупности:

Недостатком показателя H является то, что он показывает только максимальное различие значений X и не может измерять силу вариации во всей совокупности.
Cреднее линейное отклонение
Cреднее линейное отклонение — это средний модуль отклонений значений X от среднего арифметического значения. Его можно рассчитывать по формуле средней арифметической простой — получим среднее линейное отклонение простое:

Например, студент сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5. Ранее уже была рассчитана средняя арифметическая = 4. Рассчитаем среднее линейное отклонение простое: Л = (|3-4|+|4-4|+|4-4|+|5-4|)/4 = 0,5.
Если исходные данные X сгруппированы (имеются частоты f), то расчет среднего линейного отклонения выполняется по формуле средней арифметической взвешенной — получим среднее линейное отклонение взвешенное:

Вернемся к примеру про студента, который сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5. Ранее уже была рассчитана средняя арифметическая = 4 и среднее линейное отклонение простое = 0,5. Рассчитаем среднее линейное отклонение взвешенное: Л = (|3-4|*1+|4-4|*2+|5-4|*1)/4 = 0,5.
Линейный коэффициент вариации
Линейный коэффициент вариации — это отношение среднего линейного отклонение к средней арифметической:

С помощью линейного коэффициента вариации можно сравнивать вариацию разных совокупностей, потому что в отличие от среднего линейного отклонения его значение не зависит от единиц измерения X.
В рассматриваемом примере про студента, который сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5, линейный коэффициент вариации составит 0,5/4 = 0,125 или 12,5%.
Дисперсия
Дисперсия — это средний квадрат отклонений значений X от среднего арифметического значения. Дисперсию можно рассчитывать по формуле средней арифметической простой — получим дисперсию простую:

В уже знакомом нам примере про студента, который сдал 4 экзамена и получил оценки: 3, 4, 4 и 5, ранее уже была рассчитана средняя арифметическая = 4. Тогда дисперсия простая Д = ((3-4) 2 +(4-4) 2 +(4-4) 2 +(5-4) 2 )/4 = 0,5.
Если исходные данные X сгруппированы (имеются частоты f), то расчет дисперсии выполняется по формуле средней арифметической взвешенной — получим дисперсию взвешенную:

В рассматриваемом примере про студента, который сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5, рассчитаем дисперсию взвешенную: Д = ((3-4) 2 *1+(4-4) 2 *2+(5-4) 2 *1)/4 = 0,5.
Если преобразовать формулу дисперсии (раскрыть скобки в числителе, почленно разделить на знаменатель и привести подобные), то можно получить еще одну формулу для ее расчета как разность средней квадратов и квадрата средней:

В уже знакомом нам примере про студента, который сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5, рассчитаем дисперсию методом разности средней квадратов и квадрата средней:
Д = (3 2 *1+4 2 *2+5 2 *1)/4-4 2 = 16,5-16 = 0,5.
Если значения X — это доли совокупности, то для расчета дисперсии используют частную формулу дисперсии доли:
 .
.
Cреднее квадратическое отклонение
Выше уже было рассказано о формуле средней квадратической, которая применяется для оценки вариации путем расчета среднего квадратического отклонения, обозначаемое малой греческой буквой сигма:

Еще проще можно найти среднее квадратическое отклонение, если предварительно рассчитана дисперсия, как корень квадратный из нее:

В примере про студента, в котором выше рассчитали дисперсию, найдем среднее квадратическое отклонение как корень квадратный из нее:
.
 .
.Квадратический коэффициент вариации
Квадратический коэффициент вариации — это самый популярный относительный показатель вариации:

Критериальным значением квадратического коэффициента вариации V служит 0,333 или 33,3%, то есть если V меньше или равен 0,333 — вариация считает слабой, а если больше 0,333 — сильной. В случае сильной вариации изучаемая статистическая совокупность считается неоднородной, а средняя величина — нетипичной и ее нельзя использовать как обобщающий показатель этой совокупности.
В примере про студента, в котором выше рассчитали среднее квадратическое отклонение, найдем квадратический коэффициент вариации V = 0,707/4 = 0,177, что меньше критериального значения 0,333, значит вариация слабая и равна 17,7%.



- Разработка интернет-магазина
- Редизайн сайта эвакуации
- Редизайн сайта доставки суши
 Разработка интернет-магазина
Разработка интернет-магазина Редизайн сайта эвакуации
Редизайн сайта эвакуации Редизайн сайта доставки суши
Редизайн сайта доставки сушиИсточник



