
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Способы траблшутинга сетевых проблем
- Метод «сверху вниз»
- Метод «снизу вверх»
- «Разделяй и властвуй»
- «Путь трафика»
- «Поиск отличий»
- «Замена компонентов»
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Обслуживание и траблшутинг сетей
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Способы траблшутинга сетевых проблем
Часть 2. Устранения неполадок
Есть разные причины, по которым все идет не так в наших сетях: люди делают ошибки в своих настройках, оборудование может выйти из строя, обновления программного обеспечения могут включать ошибки, а изменение структуры трафика может вызвать перегрузку в наших сетях. Для устранения этих ошибок существуют различные подходы, и некоторые из них более эффективны, чем другие.
Онлайн курс по Кибербезопасности
Изучи хакерский майндсет и научись защищать свою инфраструктуру! Самые важные и актуальные знания, которые помогут не только войти в ИБ, но и понять реальное положение дел в индустрии

Устранение неполадок состоит из 3 этапов:

Все это начинается, когда кто-то или что-то сообщает о проблеме. Часто это будет пользователь, который звонит в службу поддержки, потому что что-то работает не так, как ожидалось, но также возможно, что вы обнаружите проблемы из-за мониторинга сети (Вы ведь контролируете свою сеть?). Следующий шаг — это диагностика проблемы, и очень важно найти ее корень. Как только вы обнаружите проблему, вы реализуете (временное) решение.
Диагностика проблемы является одним из самых важных шагов, чтобы устранить неполадки в сети. Для начала нам нужно найти первопричину проблемы. И для этого, необходимо выполнить ряд действий:
- Сбор информации: в большинстве случаев отчет о проблеме не дает нам достаточно информации. Пользователи просто нам сообщают, что «сеть не работает» или «Мой компьютер не работает», но это нам ничего не дает. Мы должны собирать информацию, задавая нашим пользователям подробные вопросы, или мы используем сетевые инструменты для сбора информации.
- Анализ информации: как только мы собрали всю информацию, мы проанализируем ее, чтобы увидеть, что не так. Мы можем сравнить нашу информацию с ранее собранной информацией или другими устройствами с аналогичными конфигурациями.
- Устранение возможных причин: нам нужно подумать о возможных причинах и устранить потенциальные причины проблемы. Это требует досконального знания сети и всех протоколов, которые в ней задействованы.
- Гипотеза: после определения возможных причин, вы в конечном итоге получите список этих причин, которые могут вызывать проблему работу сети. Мы выберем самую наиболее вероятную причину возникновения проблемы.
- Проверка гипотезы: мы проверим нашу гипотезу, чтобы увидеть, правы мы или нет. Если мы правы, у нас есть победа. если мы ошибаемся, мы проверяем наши другие возможные причины.
Если вы применяете структурированный подход для устранения неполадок, вы можете просто «следовать интуиции» и запутаться, потому что вы забыли, что вы уже пробовали или нет. Это упрощает поиск проблемы, если вы работаете вместе с другими сетевыми администраторами, потому что вы можете поделиться шагами, которые вы уже выполнили.
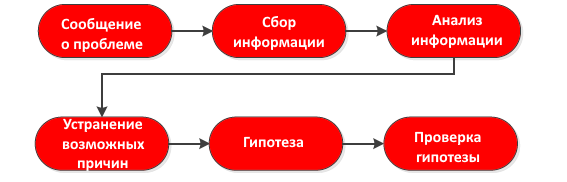
Вот шаги поиска проблемы в хорошей блок-схеме. Мы называем это структурированным подходом к устранению неполадок.
Вместо того чтобы выполнять все различные этапы структурированного подхода к устранению неполадок, мы также можем перейти от этапа «сбор информации» непосредственно к шагу «гипотеза» и пропустить этапы «анализ информации» и «устранение возможных причин«. По мере того, как вы наберётесь опыта в устранении неполадок, вы сможете пропустить некоторые шаги.
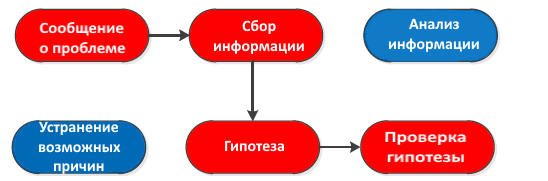
Шаги, которые мы пропускаем, выделены синим цветом. Если вас ваши интуиция подведет, то вы потеряете много времени. Если вы правы, то вы сэкономите много времени.
Устранение возможных причин является важным шагом в процессе устранения неполадок, и есть несколько подходов, как вы можете это сделать.
- Сверху вниз;
- Снизу вверх;
- Разделяй и властвуй;
- Отследить путь трафика;
- Поиск отличий;
- Замена компонентов.
Давайте пройдемся по разным подходам один за другим!

Метод «сверху вниз»
«Сверху вниз» означает, что мы начинаем с верхней части модели OSI (прикладной уровень) и продвигаемся дальше вниз. Идея заключается в том, что мы проверим приложение, чтобы увидеть, работает ли оно, и предположим, что если определенный уровень работает, то все нижеперечисленные уровни также работают. Если вы посылаете эхо-запрос с одного компьютера на другой (ICMP), то можете считать, что уровни 1,2 и 3 работают. Недостатком этого подхода является то, что вам нужен доступ к приложению, в котором устраняете неполадки.

Метод «снизу вверх»
«Снизу вверх» означает, что мы начинаем с нижней части модели OSI и будем продвигаться вверх. Мы начнем с физического уровня, который означает, что мы проверяем наши кабели и разъемы, переходим к канальному уровню, чтобы увидеть, работает ли Ethernet, связующее дерево работает нормально, безопасность портов не вызывает проблем, VLAN настроены правильно, а затем переходим на сетевой уровень. Здесь мы будем проверять наши IP-адреса, списки доступа, протоколы маршрутизации и так далее. Этот подход является очень тщательным, но и отнимает много времени. Если вы новичок в устранении неполадок рекомендуется использовать этот метод, потому что вы устраните все возможные причины проблем.

«Разделяй и властвуй»
Разделяй и властвуй означает, что мы начинаем с середины OSI-модели. Вы можете использовать эту модель, если не уверены, что нисходящее или восходящее движение более эффективно. Идея заключается в том, что вы попытаетесь отправить эхо-запрос с одного устройства на другое. Если ping работает, вы знаете, что уровень 1-3 работает, и вы можете продвинуться вверх по модели OSI.
Если эхо-запрос терпит неудачу, то вы знаете, что что-то не так, и вы будете причину проблемы в нижней части модели OSI.

«Путь трафика»
Изучение путь следования трафика очень полезно. Сначала мы попытаемся отправить эхо-запрос с хоста A на хост B. В случае сбоя мы проверим все устройства на его пути. Сначала мы проверим, правильно ли настроен коммутатор A, и, далее, мы перейдем на коммутатор B, проверим его, а затем перейдем к маршрутизатору A.
«Поиск отличий»
Этот подход вы, скорее всего, делали и раньше. Поиск отличий в конфигурации или вывод команд show может быть полезным, но очень легко что-то пропустить. Если у вас есть несколько маршрутизаторов филиала с похожей конфигурацией, и только один не работает, вы можете заметить отличие в конфигурациях. Сетевые администраторы, которые не имеют большого опыта, обычно используют этот подход. Возможно, вам удастся решить проблему, но есть риск, что вы на самом деле не знаете, что делаете.
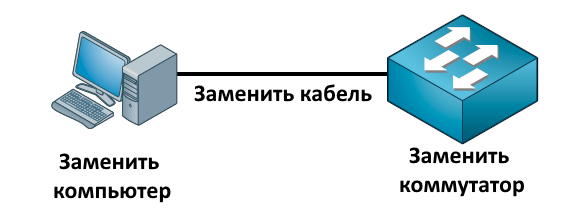
«Замена компонентов»
Последний подход к решению нашей проблемы — это замена компонентов. Допустим, у нас есть сценарий, в котором компьютер не может получить доступ к сети. В приведенном выше примере мы можем заменить компьютер, чтобы устранить любую вероятность того, что компьютер является проблемой. Мы можем заменить кабель, и, если мы подозреваем, что коммутатор не работает или неверно настроен, мы можем заменить его на новый и скопировать старую конфигурацию, чтобы увидеть, есть ли какие-либо проблемы с оборудованием.
Онлайн курс по Кибербезопасности
Изучи хакерский майндсет и научись защищать свою инфраструктуру! Самые важные и актуальные знания, которые помогут не только войти в ИБ, но и понять реальное положение дел в индустрии
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Обслуживание и траблшутинг сетей
10 минут чтения
В этой первой части статьи мы сначала рассмотрим некоторые методы обслуживания сетей. Существуют различные модели, которые помогут вам поддерживать ваши сети и сделать вашу жизнь проще. Во второй части статьи мы рассмотрим некоторые теоретические модели, которые помогут вам в устранении неполадок.
Полный курс по Сетевым Технологиям
В курсе тебя ждет концентрат ТОП 15 навыков, которые обязан знать ведущий инженер или senior Network Operation Engineer


Ну что давайте начнем рассматривать техническое обслуживании сети! Обслуживание сети в основном означает, что вы должны делать все необходимое для поддержания сети в рабочем состоянии, и это включает в себя ряд задач:
- Устранение неполадок в сети;
- Установка и настройка аппаратного и программного обеспечения;
- Мониторинг и повышение производительности сети;
- Планирование будущего расширения сети;
- Создание сетевой документации и поддержание ее в актуальном состоянии;
- Обеспечение соблюдения политики компании;
- Обеспечение соблюдения правовых норм;
- Обеспечение безопасности сети от всех видов угроз.
Конечно, этот список может отличаться для каждой сети, в которой вы работаете. Все эти задачи можно выполнить следующим образом:
- Структурированные задачи;
- Interrupt-driven задачи.
Структурированный означает, что у вас есть заранее определенный план обслуживания сети, который гарантирует, что проблемы будут решены до того, как они возникнут. Как системному администратору, это сделает жизнь намного проще. Управляемый прерыванием означает, что вы просто ждете возникновения проблемы, а затем исправляете ее так быстро, как только можете. Управляемый прерыванием подход больше похож на подход «пожарного» . вы ждете, когда случится беда, а затем пытаетесь решить проблему так быстро, как только можете. Структурированный подход, при котором у вас есть стратегия и план обслуживания сети, сокращает время простоя и является более экономичным.
Конечно, вы никогда не сможете полностью избавиться от Interrupt-driven, потому что иногда все «просто идет не так«, но с хорошим планом мы можем точно сократить количество задач, управляемых прерываниями.
Вам не нужно думать о модели обслуживания сети самостоятельно. Есть ряд хорошо известных моделей обслуживания сети, которые используются сетевыми администраторами. Лучше всего использовать одну из моделей, которая лучше всего подходит для вашей организации и подкорректировать, если это необходимо.
Вот некоторые из известных моделей обслуживания сети:
- FCAPS:
- Управление неисправностями.
- Управление конфигурацией.
- Управление аккаунтингом.
- Управление производительностью.
- Управление безопасностью.
Модель обслуживания сети FCAPS была создана ISO (Международной организацией стандартизации).
- ITIL: библиотека ИТ-инфраструктуры — это набор практик для управления ИТ-услугами, который фокусируется на приведении ИТ-услуг в соответствие с потребностями бизнеса.
- TMN: сеть управления телекоммуникациями — это еще одна модель технического обслуживания, созданная ITU-T (сектор стандартизации телекоммуникаций) и являющаяся вариацией модели FCAPS. TMN нацелена на управление телекоммуникационными сетями.
- Cisco Lifecycle Services: конечно, Cisco имеет свою собственную модель обслуживания сети, которая определяет различные фазы в жизни сети Cisco:
- Подготовка
- Планирование
- Проектирование
- Внедрение
- Запуск
- Оптимизация
Выбор модели обслуживания сети, которую вы будете использовать, зависит от вашей сети и бизнеса. Вы также можете использовать их в качестве шаблона для создания собственной модели обслуживания сети.
Чтобы дать вам представление о том, что такое модель обслуживания сети и как она выглядит, ниже приведен пример для FCAPS:
- Управление неисправностями: мы будем настраивать наши сетевые устройства (маршрутизаторы, коммутаторы, брандмауэры, серверы и т. д.) для захвата сообщений журнала и отправки их на внешний сервер. Всякий раз, когда интерфейс выходит из строя или нагрузка процессора превышает 80%, мы хотим получить сообщение о том, чтобы узнать, что происходит.
- Управление конфигурацией: любые изменения, внесенные в сеть, должны регистрироваться в журнале. Чаще всего используют управление изменениями, чтобы соответствующий персонал был уведомлен о планируемых изменениях в сети. Изменения в сетевых устройствах должны быть зарегистрированы и утверждены до того, как они будут реализованы.
- Управление аккаунтингом: Мы будем взимать плату с (гостевых) пользователей за использование беспроводной сети, чтобы они платили за каждые 100 МБ данных или что-то в этом роде. Он также обычно используется для взимания платы с людей за междугородние VoIP-звонки.
- Управление производительностью: производительность сети будет контролироваться на всех каналах LAN и WAN, чтобы мы знали, когда что-то пойдет не так. QoS (качество обслуживания) будет настроено на соответствующих интерфейсах.
- Управление безопасностью: мы создадим политику безопасности и реализуем ее с помощью брандмауэров, VPN, систем предотвращения вторжений и используем AAA (Authorization, Authentication and Accounting) для проверки учетных данных пользователей. Сетевые нарушения должны регистрироваться, и должны быть приняты соответствующие мероприятия.
Как вы видите, что FCAPS — это не просто «теоретический» метод, но он действительно описывает «что«, «как» и «когда» мы будем делать.
Какую бы модель обслуживания сети вы ни решили использовать, всегда есть ряд рутинных задач обслуживания, которые должны иметь перечисленные процедуры, вот несколько примеров:
- Изменения конфигурации: бизнес никогда не стоит на месте, он постоянно меняется. Иногда вам нужно внести изменения в сеть, чтобы разрешить доступ для гостевых пользователей, обычные пользователи могут перемещаться из одного офиса в другой, и для облегчения этой процедуры вам придется вносить изменения в сеть.
- Замена оборудования: старое оборудование должно быть заменено более современным оборудованием, и также возможна ситуация, когда производственное оборудование выйдет из строя, и нам придется немедленно заменить его.
- Резервные копии: если мы хотим восстановиться после сетевых проблем, таких как отказавшие коммутаторы или маршрутизаторы, то нам нужно убедиться, что у нас есть последние резервные копии конфигураций. Обычно вы используете запланированные резервные копии, поэтому вы будете сохранять текущую конфигурацию каждый день, неделю, месяц или в другое удобное для вас время.
- Обновления программного обеспечения: мы должны поддерживать ваши сетевые устройства и операционные системы в актуальном состоянии. Обновления позволяют исправлять ошибки ПО. Также обновление проводится для того, чтобы убедиться, что у нас нет устройств, на которых работает старое программное обеспечение, имеющее уязвимости в системе безопасности.
- Мониторинг: нам необходимо собирать и понимать статистику трафика и использования полосы пропускания, чтобы мы могли определить (будущие) проблемы сети, но также и планировать будущее расширение сети.
Обычно вы создаете список задач, которые должны быть выполнены для вашей сети. Этим задачам можно присвоить определенный приоритет. Если определенный коммутатор уровня доступа выходит из строя, то вы, вероятно, захотите заменить его так быстро, как только сможете, но нерабочее устройство распределения или основного уровня будет иметь гораздо более высокий приоритет, поскольку оно влияет на большее число пользователей Сети.
Другие задачи, такие как резервное копирование и обновление программного обеспечения, могут быть запланированы. Вы, вероятно, захотите установить обновления программного обеспечения вне рабочего времени, а резервное копирование можно запланировать на каждый день после полуночи. Преимущество планирования определенных задач заключается в том, что сетевые инженеры с меньше всего забудут их выполнить.
Внесение изменений в вашу сеть иногда влияет на производительность пользователей, которые полагаются на доступность сети. Некоторые изменения будут очень важны, изменения в брандмауэрах или правилах списка доступа могут повлиять на большее количество пользователей, чем вы бы хотели. Например, вы можете установить новый брандмауэр и запланировать определенный результат защиты сети. Случайно вы забыли об определенном приложении, использующем случайные номера портов, и в конечном итоге устраняете эту проблему. Между тем некоторые пользователи не получат доступ к этому приложению (и возмущаются, пока вы пытаетесь его исправить. ).
Более крупные компании могут иметь более одного ИТ-отдела, и каждый отдел отвечает за различные сетевые услуги. Если вы планируете заменить определенный маршрутизатор завтра в 2 часа ночи, то вы можете предупредить парней из отдела «ИТ-отдел-2«, о том, что их серверы будут недоступны. Для этого можно использовать управление изменениями. Когда вы планируете внести определенные изменения в сеть, то другие отделы будут проинформированы, и они могут возразить, если возникнет конфликт с их планированием.
Перед внедрением управления изменениями необходимо подумать о следующем:
- Кто будет отвечать за авторизацию изменений в сети?
- Какие задачи будут выполняться во время планового технического обслуживания windows, linux, unix?
- Какие процедуры необходимо соблюдать, прежде чем вносить изменения? (например: выполнение «copy run start» перед внесением изменений в коммутатор).
- Как вы будете измерять успех или неудачу сетевых изменений? (например: если вы планируете изменить несколько IP-адресов, вы запланируете время, необходимое для этого изменения. Если для перенастройки IP-адресов требуется 5 минут, а вы в конечном итоге устраняете неполадки за 2 часа, так как еще не настроили. Из-за этого вы можете «откатиться» к предыдущей конфигурации. Сколько времени вы отводите на устранение неполадок? 5 минут? 10 минут? 1 час?
- Как, когда и кто добавит сетевое изменение в сетевую документацию?
- Каким образом вы создадите план отката, чтобы в случае непредвиденных проблем восстановить конфигурацию к предыдущей конфигурации?
- Какие обстоятельства позволят отменить политику управления изменениями?
Еще одна задача, которую мы должны сделать — это создать и обновить вашу сетевую документацию. Всякий раз, когда разрабатывается и создается новая сеть, она должна быть задокументирована. Более сложная часть состоит в том, чтобы поддерживать ее в актуальном состоянии. Существует ряд элементов, которые вы должны найти в любой сетевой документации:
- Физическая топологическая схема (физическая карта сети): здесь должны быть показаны все сетевые устройства и то, как они физически связаны друг с другом.
- Логическая топологическая схема (логическая карта сети): здесь необходимо отобразить логические связи между устройствами, то есть как все связано друг с другом. Показать используемые протоколы, информация о VLAN и т. д.
- Подключения: полезно иметь диаграмму, которая показывает, какие интерфейсы одного сетевого устройства подключены к интерфейсу другого сетевого устройства.
- Инвентаризация: вы должны провести инвентаризацию всего сетевого оборудования, списков поставщиков, номера продуктов, версии программного обеспечения, информацию о лицензии на программное обеспечение, а также каждое сетевое устройство должно иметь инвентарный номер.
- IP-адреса: у вас должна быть схема, которая охватывает все IP-адреса, используемые в сети, и на каких интерфейсах они настроены.
- Управление конфигурацией: перед изменением конфигурации мы должны сохранить текущую запущенную конфигурацию, чтобы ее можно было легко восстановить в предыдущую (рабочую) версию. Еще лучше хранить архив старых конфигураций для дальнейшего использования.
- Проектная документация: документы, которые были созданы во время первоначального проектирования сети, должны храниться, чтобы вы всегда могли проверить, почему были приняты те или иные проектные решения.
Это хорошая идея, чтобы работать с пошаговыми рекомендациями по устранению неполадок или использовать шаблоны для определенных конфигураций, которые все сетевые администраторы согласны использовать.
Ниже показаны примеры, чтобы вы понимали, о чем идет речь:
Вот пример интерфейсов доступа, подключенных к беспроводным точкам доступа. Portfast должен быть включен для связующего дерева, точки доступа должны быть в VLAN 2, а порт коммутатора должен быть изменен на «доступ» вручную.
Вот шаблон для интерфейсов, которые подключаются к клиентским компьютерам. Интерфейс должен быть настроен на режиме «доступа» вручную. Безопасность портов должна быть включена, поэтому допускается только 1 MAC-адрес (компьютер). Интерфейс должен немедленно перейти в режим переадресации, поэтому мы настраиваем spanning-tree portfast, и, если мы получаем BPDU, интерфейс должен перейти в err-disabled. Работа с предопределенными шаблонами, подобными этим, уменьшит количество ошибок, потому что все согласны с одной и той же конфигурацией. Если вы дадите каждому сетевому администратору инструкции по «»защите интерфейса», вы, вероятно, получите 10 различных конфигураций
Вот еще один пример для магистральных соединений. Если вы скажете 2 сетевым администраторам «настроить магистраль», вы можете в конечном итоге получить один интерфейс, настроенный для инкапсуляции 802.1Q, а другой-для инкапсуляции ISL. Если один сетевой администратор отключил DTP, а другой настроил интерфейс как «dynamic desirable«, то он также не будет работать. Если вы дадите задание им настроить магистраль в соответствии с шаблоном, то у нас будет одинаковая конфигурация с обеих сторон.
Полный курс по Сетевым Технологиям
В курсе тебя ждет концентрат ТОП 15 навыков, которые обязан знать ведущий инженер или senior Network Operation Engineer
Источник



