
Методы сжатия графических изображений
Для уменьшения объема дискового пространства файлы подвергаются компрессии (сжатию). Существует два основных принципа сжатия: сжатие без потерь, когда информация полностью восстанавливается, и сжатие с потерями, когда информация до и после сжатия отличается в определенной и регулируемой степени.
Алгоритмы сжатия без потерь
В качестве примеров таких алгоритмов сжатия без потерь можно рассмотреть следующие:
Ø кодирование длин серий;
Ø метод Хаффмана;
Кодирование длин серий (Run Length Encoding )
Как известно, все документы (графика, тексты, программы и т. п.) хранятся в компьютере в виде файлов — организованных записей. Изображения хранятся в файлах специальных графических форматов, которых сейчас насчитывается более десятка. Основой для разложения изображения на множество элементов является пиксель. Основа файла — это описание цветов всех пикселей. Описание цвета пикселя (три / четыре числа) является кодом цвета в соответствии с той или иной цветовой моделью. Указание на цветовую модель также включается в файл. Кроме того, записывается размер изображения в пикселях.
Итак, условная структура файла (аналог формата BMP), будет содержать: сведения о цветовой модели; габаритах изображения; и, например, об авторе картинки, включенные в специальный раздел файла, называемый заголовком . После заголовка в файле записываются друг за другом коды цветов (или параметров цветовой модели) отдельных пикселей, слева направо и сверху вниз.
Пиксельное изображение при сохранении фактически вытягивается в цепочку и логично предположить, что встречаются цепочки (последовательности) одинаковых байтов. Самым простым способом, который позволяет уменьшить объем файла, является поиск повторяющихся кодов (символов, цвета и т. п.) — серий одинаковых значений. Каждая такая серия фиксируется двумя числами: первое указывает количество одинаковых значений, а второе — само значение.
Заменим для простоты значения цвета буквами. Если в документе, скажем, имеется такая последовательность «АААААВВВВВВВСССССС», ее можно сжать таким образом: 5А7В6С. В результате вместо 18 символов в документе достаточно хранить всего 6.
Алгоритм рассчитан на деловую или декоративную графику — изображения с большими областями локального (повторяющегося) цвета.
Достоинством такого алгоритма является простота (что очень важно, т. к. позволяет выполнять процедуры компрессии и декомпрессии достаточно быстро), а недостатками — необходимость различать собственно данные и числа повторений, а также возможное увеличение объема файла, если в документе мало повторений (например, серия АВСАВС не уменьшит, а увеличит объем документа, поскольку будет иметь следующий вид: 1А1В1С1А1В1С, т. е. вместо 6 символов получится вдвое больше).
Если система выводит ошибку, возможно программа, считывающая файл ожидает появление данных в ином порядке, чем программа, сохраняющая этот файл на диске. Требуется преобразование в иной формат
Метод RLE включается в некоторые графические форматы, например:
Ø BMP (для 16 и 256 по желанию);
Ø TGA (по желанию);
Алгоритм Хаффмана
Алгоритм Хаффмана основан на определенном анализе документа и вычислении частоты встречаемости цветовых значений (или значений других видов информации), а затем этим значениям в соответствии с рангом присваиваются коды сначала с минимальным количеством битов, а затем по мере снижения частоты (уменьшения ранга) используется все большее количество двоичных разрядов. Такой способ кодирования иногда называют алфавитным кодированием.
Заменим также для простоты значения цвета буквами. Например, в следующей последовательности букв ААСАААВАВАВВАВСАСВСАСААССС заметно, что чаще всего встречается символ А (12 раз), затем символ С (9 раз) и, наконец, символ В (5 раз). Следовательно, символ А можно заменять кодом 0, символ С — кодом 1, а символ В — кодом 00. И так далее, если элементов для кодирования больше. В результате, если считать, что каждый символ в нашем примере кодируется 1 битом, то для передачи строки потребуется 208 битов, а в сжатом виде объем информации составит только 31 бит.
Алгоритм LZW
Алгоритм, названный в честь своих создателей Лемпеля, Зива и Велча (Lempel, Ziv и Welch), не требует вычисления вероятностей встречаемости символов или кодов. Основная идея состоит в замене совокупности байтов в исходном файле ссылкой на предыдущее появление той же совокупности.
Процесс сжатия выглядит следующим образом. Последовательно считываются символы входного потока и происходит проверка, существует ли в созданной таблице строк такая строка. Если такая строка существует, считывается следующий символ, а если строка не существует, в поток заносится код для предыдущей найденной строки, строка заносится в таблицу, а поиск начинается снова.
Например, если сжимают байтовые данные (текст), то строк в таблице окажется 256 (от «0» до «255»). Для кода очистки и кода конца информации используются коды 256 и 257. Если используется 10-битный код, то под коды для строк остаются значения в диапазоне от 258 до 1023. Новые строки формируют таблицу последовательно, т. е. можно считать индекс строки ее кодом.
Пусть сжимается последовательность символов АВВСВВВ. Сначала в сжатый документ сохраняется код удаления [256], затем считывается символ «А» и проверяется, существует ли в таблице строка «А». Поскольку при инициализации в таблицу сохраняются все строки длиной в один символ, то строка «А», конечно, существует в таблице.
Далее считывается следующий символ «В» и проверяется, существует ли в таблице строка «АВ». Такая строка в таблице пока отсутствует, поэтому с первым свободным кодом [258] в таблицу вносится строка «АВ», а в документе сохраняется код [А]. Последовательность «АВ» в таблице отсутствует, поэтому в таблицу добавляется код [258] для сочетания «АВ», а в документе сохраняется код [А].
Далее рассматривается последовательность «ВВ», которая отсутствует в таблице, в таблицу заносится код [259] для символов «ВВ», а в документе сохраняется код [В].
Считывается символ «С» и проверяется наличие символов «ВС» в таблице, поскольку такая последовательность отсутствует, то в таблицу заносится кед [260] для последовательности «ВС», а в документ — код [В].
Снова добавляется из исходного файла символ «В» и теперь уже проверяется сочетание «СВ», которое тоже отсутствует. В таблицу записывается код [261] для «СВ», а в документ — код [С].
Затем считывается символ «В» и строка «ВВ», наконец, имеется в таблице, поэтому считывается следующий символ и рассматривается последовательность «ВВВ», которая, конечно, в таблице отсутствует. В таблицу заносится код [262] для «ВВВ», а в документ (внимание!) — код [259].
В результате в документе окажется следующая последовательность кодов [256][А][В][В][С][259], что короче исходной последовательности. К сожалению, последовательность слишком короткая, а алгоритм достатчно сложен, чтобы выгода оказалась реальной. При значительном объеме коэффициент сжатия может достигать несколько сот единиц.
Особенностью рассматриваемого алгоритма LZW является то, что для выполнения обратного процесса («распаковки») нет необходимости сохранять таблицу в документе (алгоритм позволяет восстановить таблицу строк только из сохраненных в документе кодов).
Этот метод гораздо совершеннее RLE для областей с переходами цветов, однако кодировка в него требует больше системных ресурсов.
Метод LZW включается в некоторые графические форматы, например: TIFF ; GIF .
Алгоритмы сжатия с потерями
JPEG (Joint Photographic Experts Group)
Исследователями визуального восприятия человека отмечено, что далеко не вся информация требуется для того, чтобы адекватно воспринимать цветное изображение. Для реализации этого закона были разработаны алгоритмы с потерей информации, которые обеспечивают выбор уровня компрессии с уровнем качества изображения (рис. 1). Тем самым достигается компромисс между размером и качеством изображений.
Наиболее известным методом компрессии с потерями является JPEG-компрессия. Метод компрессии основан на особенности человеческого восприятия: глаз достаточно четко различает яркость объекта и цветовые контрасты, а плавные изменения в светах и тенях значительно меньше. При записи такой изобразительной информации часть цветовых данных может быть опущена, как предполагается, без заметного ущерба для восприятия.

Рис. 1. Компромисс между качеством и уровнем компрессии
Для этого обработка изображения происходит в несколько этапов. Сначала изображение конвертируется в особое цветовое пространство, напоминающее цветовую модель CIE Lab, в котором один канал сохраняет яркостные характеристики, а в остальных двух цветовых каналах уменьшается разрешение (по методу мозаики).
Замечание: RGB-изображение конвертируется в пространство YUV (иногда называемое также YcrCb), основанное на характеристиках яркости (составляющая Y) и цветности (составляющие U и V).
Затем изображение разбивается на фрагменты квадратной формы со стороной в 8 пикселей. Каждый фрагмент подвергается достаточно сложным математическим преобразованиям. Записывается два типа информации — усредненная информация о блоке и информация о его деталях, далее, в зависимости от выбранной степени сжатия, удаляется то или иное количество дополнительной информации. Чем меньше будет размер файла, тем хуже будет его качество.
Одновременно каждый блок разлагается на составляющие цвета и производится подсчет частоты встречаемости каждого цвета. Информация о частоте позволяет исключить небольшую часть яркостной характеристики и довольно значительную цветовой. Уровень исключения информации как раз и определяется установкой требуемого качества.
Затем информация о яркости и цвете кодируется таким образом, что остаются только различия между соседними блоками. Результатом всего процесса обработки являются последовательности простых чисел, которые в свою очередь легко сжимать каким-либо алгоритмом сжатия без потерь из уже упомянутых, например алгоритмом Хаффмана.
Алгоритмы сжатия с потерями, в частности алгоритм JPEG, не позволяют полностью восстановить изображение до его исходного состояния, а, следовательно, не рекомендуется сжимать изображения несколько раз.
Источник
Методы сжатия растровых данных
Перед тем как закончить обсуждение растровых моделей данных, мы должны рассмотреть четыре метода хранения растровых данных, которым свойственна существенная экономия дискового пространства. Методы сжатия растровых данных работают внутри подсистемы хранения и редактирования ГИС, но они могут вызываться и напрямую на этапе ввода информации в ГИС. Мы вернемся к этим методам в следующей главе при рассмотрении ввода данных. Подходы, освещаемые в этой главе, проиллюстрированы на Рисунке 4.12.
Первый метод сжатия растровых (и не только растровых) данных называется групповым кодированием. Когда-то растровые данные вводились в ГИС с помощью пронумерованной прозрачной сетки, которая накладывалась на кодируемую карту. Каждая ячейка имела численное значение, соответствующее данным карты, которые вводились (обычно с клавиатуры) в компьютер. Например, для карты размером 200 х 200 ячеек потребуется ввести 40’000 чисел. Если ваш преподаватель сейчас услышит ваше хихиканье, не удивляйтесь, обнаружив себя за этим занятием в качестве упражнения по истории ГИС или урока скромности. На самом деле, вы можете попробовать его как-нибудь, если у вас есть доступ к какой-либо растровой ГИС. Начав вводить, вы быстро обнаружите повторения данных, которые могут быть использованы для уменьшения работы. Конкретнее, в каждом ряду существуют длинные цепочки одинаковых чисел. Подумайте, сколько времени вы сэкономите на одной строке, если бы могли сказать компьютеру, что, например, с позиции 8 по позицию 56 идут одни единицы, ас 57-й позиции до конца ряда идут двойки. В действительности, вы могли бы также сохранить немало объема памяти, записывая только начальную и конечную позицию для каждой цепочки и значение, которое в ней присутствует. В этом и состоит идея группового кодирования.
Конечно, этот метод действует в пределах одной строки растра. Что, если бы вы могли сказать компьютеру начать с отдельной ячейки со значением 1, затем перейти в определенном направлении, скажем вертикально, на 27 ячеек и тогда изменить значение. Это позволило бы кодировать цепочки в любом направлении. Но принцип может быть расширен и дальше. Допустим,
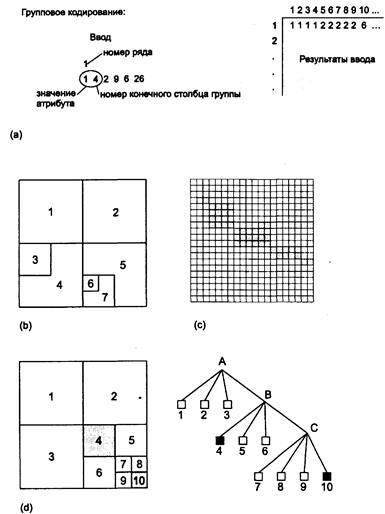
Рисунок 4.12. Методы сжатия растровых данных, а) групповое кодирование, b) блочное кодирование, с) цепочечное кодирование, d) квадродерево.
что вы видите большую группу ячеек растра, представляющую некоторую область. Если вы начнете с одного угла, задав его координаты и значение ячейки, затем перейдете по главным направлениям (вниз, вверх, вправо, влево) вдоль области, записав число, представляющее направление, и еще одно, равное количеству ячеек, на которое вы переместились, то для записи области потребуется всего лишь несколько чисел. Таким образом, вы бы сохранили еще больше места на диске и, конечно, времени ручного ввода. Этот метод называетсяцепочечным кодированием (raster chain codes), он буквально прокладывает цепь ячеек растра вдоль границы каждой области. В общем, вы указываете координаты (X,Y) начала, значение ячеек для всей области, а затем вектора направлений, показывающие, куда двигаться дальше, где повернуть и как далеко идти. Обычно векторы описываются количеством ячеек и направлением в виде чисел 0,1,2,3, соответствующих движению вверх, вниз, вправо и влево.
Есть еще два подхода к сжатию растровой информации, оба ориентированы на квадратные матрицы. Первый, называемыйблочным кодированием (block codes), является модификацией группового кодирования. Вместо указания начальной и конечной точек и значения ячеек, мы выбираем квадратную группу ячеек растра и назначаем начальную точку, скажем, центр или угол, берем значение ячейки и сообщаем компьютеру ширину квадрата ячеек. Как видите, это, в сущности, двухмерное групповое кодирование. Таким образом может быть записана каждая квадратная группа ячеек, включая и отдельные ячейки, с минимальным количеством чисел. Конечно, если ваше покрытие имеет очень мало больших квадратных групп ячеек, этот метод не даст значительного выигрыша в объеме памяти. Но в таком случае и групповое кодирование может быть неэффективно, когда есть мало длинных цепочек одной величины. Но все же большинство тематических карт имеют достаточно большое количество таких групп, и блочное кодирование поэтому очень эффективно.
Квадродерево (Quadtree), последний рассматриваемый нами метод сжатия растровых данных, несколько сложнее, и ваш преподаватель может посчитать ненужным его освещать. Все же существует по меньшей мере одна коммерческая система компании Tydac под названием SPANS и одна экспериментальная система под названием Quilt [Shaffer, Samet, and Nelson, 1987], которые основаны на этой схеме. Как и блочное кодирование, квадродерево основано на квадратных группах ячеек растра, но в данном случае вся карта последовательно делится на квадраты с одинаковым значением атрибута внутри. Вначале квадрат размером со всю карту делится на четыре квадранта (СЗ, СВ, ЮЗ, ЮВ). Если один из них однороден (т.е. содержит ячейки с одним и тем же значением), то этот квадрант записывается и больше не участвует в делении. Каждый оставшийся квадрант опять делится на четыре квадранта, опять СЗ, СВ, ЮЗ, ЮВ. Опять каждый квадрант проверяется на однородность. Все однородные квадранты записываются, и каждый из оставшихся делится далее и проверяется, пока вся карта не будет записана как множество квадратных групп ячеек, каждая с одинаковым значением атрибута внутри. Мельчайшим квадратом является одна ячейка растра [Burrough, 1983].
Системы, основанные на квадродереве, называются системами с переменным разрешением, так как они могут оперировать на любом уровне деления квадродерева. Пользователи могут решать, какой уровень разрешения нужен для их расчетов. Кроме того, благодаря высокой степени компрессии данных этого метода, в одной системе могут храниться очень большие базы данных — масштаба континента и даже всей Земли.
Наибольшей трудностью для квадродерева является метод разделения ячеек растра на регионы. В блочном кодировании решение принимается целиком на основе существования квадратных групп однородности независимо от того, где они находятся на карте. В квадродереве деление на квадранты фиксировано, поэтому некоторые однородные регионы оказываются разбитыми на несколько квадрантов. Это приводит к некоторым трудностям при анализе формы и распределения, которые приходится преодолевать достаточно сложными вычислительными методами, выходящими за рамки данной книги. ГИС, использующие квадродерево, функционируют на рабочих станциях и PC в среде разных операционных систем. Такие программы используются по всему миру и предлагают некоторые интересные возможности, особенно для тех, кто работает с очень большими базами данных.
Источник



