
- Сжатие без потерь: как это работает
- Сжатие с потерями и без потерь
- Алгоритмы сжатия без потерь
- Сжатие без потерь на примере аудио
- Где ещё применяется сжатие без потерь
- Что дальше
- Простым языком о том, как работает сжатие файлов
- Авторизуйтесь
- Простым языком о том, как работает сжатие файлов
- Что такое сжатие?
- Сжатие с потерями
- Где используется сжатие с потерями
- Сжатие без потерь
- Где используется сжатие без потерь
- Сжатие с потерями vs сжатие без потерь
- Проблемы во время сжатия файлов
- Заключение
- Алгоритмы сжатия данных без потерь
- Введение
- История
- Проблемы с правами
- Рост популярности Deflate
- Современные архиваторы
- Будущее алгоритмов сжатия
Сжатие без потерь: как это работает
Когда копия не отличается от оригинала.
Мы уже разобрались с тем, как оцифровывается звук. Одна из проблем — если качественно его оцифровывать, то нам нужно очень много данных, а это значит большие файлы, большой расход места на диске, дорогие флешки, много трафика в интернете. Хочется, чтобы файлики были поменьше.
Для этого используется сжатие — различные алгоритмы, которые творят с данными свою магию и на выходе получаются данные меньшего объёма.
Сжатие с потерями и без потерь
Есть два принципиальных вида сжатия — с потерями и без.
Сжатие с потерями означает, что в процессе мы лишились части информации. Алгоритмы сжатия с потерями стараются сделать так, чтобы мы потеряли только те данные, которые нам не слишком важны.
Представьте, что сжатие с потерями — это краткий пересказ произведения из школьной программы: школьнику не так важны описания природы и авторский стиль, ему главное сюжет. Краткий пересказ сохранил только важное, но передал это намного быстрее.
Сжатие без потерь — это когда мы уменьшаем размер файла, при этом не теряя в качестве. Для этого используются интересные математические приёмы и кодирование. Главная мысль — чтобы при раскодировании все данные остались на месте.
Алгоритмы сжатия без потерь
Есть два основных варианта: алгоритм Хаффмана или LZW. LZW используется повсеместно, но объяснить его довольно сложно, он неинтуитивный и требует целой лекции. Гораздо приятнее объяснить алгоритм Хаффмана.
Алгоритм Хаффмана берёт файл, разбивает его на фрагменты, с которыми ему удобно работать, а потом смотрит, насколько часто встречается каждый фрагмент. Самые частые слова этот алгоритм обозначает коротким кодом, а самые редкие — кодом подлиннее. Так как самые частые слова занимают теперь гораздо меньше места, то и готовый файл становится меньше.
Но есть и минус: иногда нужно хранить эту таблицу соответствий слов и кода прямо в этом же файле, а она может сама по себе получиться большой. Чаще всего алгоритм Хаффмана применяется для сжатия текстовых файлов и видео без потерь.
Вот пример: берём песню Beyonce — All The Single Ladies. Там есть два таких пассажа:
All the single ladies
All the single ladies
All the single ladies
Now put your hands up
If you like it then you shoulda put a ring on it
If you like it then you shoulda put a ring on it
Don’t be mad once you see that he want it
If you like it then you shoulda put a ring on it
Здесь 281 знак. Мы видим, что некоторые строчки повторяются. Закодируем их:
ТАБЛИЦА СЖАТИЯ
\a\ All the single ladies
\b\ Now put your hands up
\c\ If you like it then you shoulda put a ring on it
\d\ Don’t be mad once you see that he want it
ТЕКСТ ПЕСНИ
Вместе таблицей сжатия этот текст теперь занимает 187 знаков — мы сжали текст почти на треть благодаря тому, что он довольно монотонный.
Сжатие без потерь на примере аудио
В среднем минута несжатого аудио занимает 10 мегабайт. Это довольно много: если у вас, например, часовая запись концерта, то она будет занимать полгигабайта. С другой стороны, в этой записи захвачены все нюансы звука, есть много высоких частот и вообще красота.
Для таких ситуаций используют сжатие без потерь: оно уменьшает файл в 2–3 раза, не искажая звук. Алгоритмы, которые сжимают аудио, называются кодеками. FLAC и Apple Lossless — два популярных кодека для сжатия аудио без потерь.
Сравните сами размер и качество двухминутного аудио:
Оригинал — без сжатия, формат WAV, 23 мегабайта
Сжатие без потерь — формат FLAC с теми же параметрами, что и WAV, 10 мегабайт
Где ещё применяется сжатие без потерь
В архиваторах. Задача программ-архиваторов — упаковать выбранные файлы так, чтобы архив занимал как можно меньше места, при этом не повреждая то, что внутри. Например, текстовая версия «Войны и мира» может занимать 4 мегабайта, а заархивированная — 100 килобайт, в 40 раз меньше.
В программировании. Есть специальные упаковщики, которые берут готовую программу и оптимизируют код так, чтобы он занимал меньше места, но сохранил свою работоспособность. Например:
- Удаляют комментарии
- Сокращают до минимума названия переменных и функций
- Удаляют символы, которые нужны были человеку для удобочитаемости
Что дальше
В следующей части разберём, как работает сжатие с потерями и почему благодаря этому у нас есть ТикТок и Ютуб.
Источник
Простым языком о том, как работает сжатие файлов
Авторизуйтесь
Простым языком о том, как работает сжатие файлов
Сжатие файлов позволяет быстрее передавать, получать и хранить большие файлы. Оно используется повсеместно и наверняка хорошая вам знакомо: самые популярные расширения сжатых файлов — ZIP, JPEG и MP3. В этой статье кратко рассмотрим основные виды сжатия файлов и принципы их работы.
Что такое сжатие?
Сжатие файла — это уменьшение его размера при сохранении исходных данных. В этом случае файл занимает меньше места на устройстве, что также облегчает его хранение и передачу через интернет или другим способом. Важно отметить, что сжатие не безгранично и обычно делится на два основных типа: с потерями и без потерь. Рассмотрим каждый из них по отдельности.
Сжатие с потерями
Такой способ уменьшает размер файла, удаляя ненужные биты информации. Чаще всего встречается в форматах изображений, видео и аудио, где нет необходимости в идеальном представлении исходного медиа. MP3 и JPEG — два популярных примера. Но сжатие с потерями не совсем подходит для файлов, где важна вся информация. Например, в текстовом файле или электронной таблице оно приведёт к искажённому выводу.
MP3 содержит не всю аудиоинформацию из оригинальной записи. Этот формат исключает некоторые звуки, которые люди не слышат. Вы заметите, что они пропали, только на профессиональном оборудовании с очень высоким качеством звука, поэтому для обычного использования удаление этой информации позволит уменьшить размер файла практически без недостатков.
3–5 декабря, Онлайн, Беcплатно
Аналогично файлы JPEG удаляют некритичные части изображений. Например, в изображении с голубым небом сжатие JPEG может изменить все пиксели на один или два оттенка синего вместо десятков.
Чем сильнее вы сжимаете файл, тем заметнее становится снижение качества. Вы, вероятно, замечали такое, слушая некачественную музыку в формате MP3, загруженную на YouTube. Например, сравните музыкальный трек высокого качества с сильно сжатой версией той же песни.
Сжатие с потерями подходит, когда файл содержит больше информации, чем нужно для ваших целей. Например, у вас есть огромный файл с исходным (RAW) изображением. Целесообразно сохранить это качество для печати изображения на большом баннере, но загружать исходный файл в Facebook будет бессмысленно. Картинка содержит множество данных, не заметных при просмотре в социальных сетях. Сжатие картинки в высококачественный JPEG исключает некоторую информацию, но изображение выглядит почти как оригинал.
При сохранении в формате с потерями, вы зачастую можете установить уровень качества. Например, у многих графических редакторов есть ползунок для выбора качества JPEG от 0 до 100. Экономия на уровне 90 или 80 процентов приводит к небольшому уменьшению размера файла с незначительной визуальной разницей. Но сохранение в плохом качестве или повторное сохранение одного и того же файла в формате с потерями ухудшит его.
Посмотрите на этот пример.
Оригинальное изображение, загруженное с Pixabay в формате JPEG. 874 КБ:

Результат сохранения в формате JPEG с 50-процентным качеством. Выглядит не так уж плохо. Вы можете заметить артефакты по краям коробок только при увеличении. 310 КБ:
Исходное изображение, сохранённое в формате JPEG с 10-процентным качеством. Выглядит ужасно. 100 КБ:
Где используется сжатие с потерями
Как мы уже упоминали, сжатие с потерями отлично подходит для большинства медиафайлов. Это крайне важно для таких компаний как Spotify и Netflix, которые постоянно транслируют большие объёмы информации. Максимальное уменьшение размера файла при сохранении качества делает их работу более эффективной.
Сжатие без потерь
Сжатие без потерь позволяет уменьшить размер файла так, чтобы в дальнейшем можно было восстановить первоначальное качество. В отличие от сжатия с потерями, этот способ не удаляет никакую информацию. Рассмотрим простой пример. На картинке ниже стопка из 10 кирпичей: два синих, пять жёлтых и три красных.

Вместо того чтобы показывать все 10 блоков, мы можем удалить все кирпичи одного цвета, кроме одного. Используя цифры, чтобы показать, сколько кирпичей каждого цвета было, мы представляем те же данные используя гораздо меньше кирпичей — три вместо десяти.
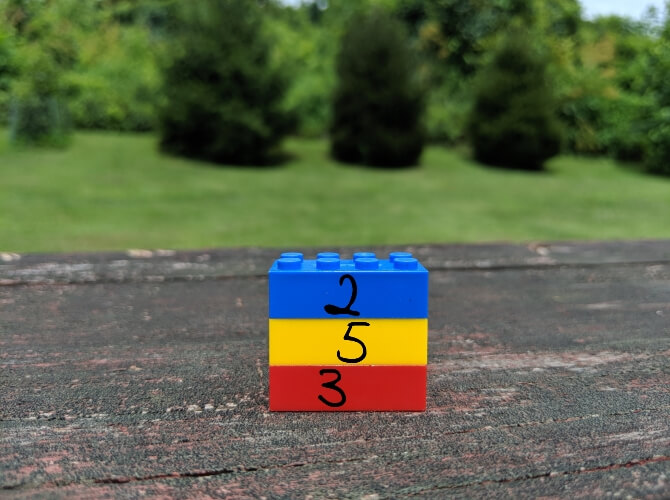
Это простая иллюстрация того, как осуществить сжатие без потерь. Та же информация сохраняется более эффективным способом. Рассмотрим реальный файл: mmmmmuuuuuuuoooooooooooo. Его можно сжать до гораздо более короткой формы: m5u7o12. Это позволяет использовать 7 символов вместо 24 для представления одних и тех же данных.
Где используется сжатие без потерь
ZIP-файлы — популярный пример сжатия без потерь. Хранить информацию в виде ZIP-файлов более эффективно, при этом когда вы распаковываете архив, там присутствует вся оригинальная информация. Это актуально для исполняемых файлов, так как после сжатия с потерями распакованная версия будет повреждена и непригодна для использования.
Другие распространённые форматы без потерь — PNG для изображений и FLAC для аудио. Форматы видео без потерь встречаются редко, потому что они занимают много места.
Сжатие с потерями vs сжатие без потерь
Теперь, когда мы рассмотрели обе формы сжатия файлов, может возникнуть вопрос, когда и какую следует использовать. Здесь всё зависит от того, для чего вы используете файлы.
Скажем, вы только что откопали свою старую коллекцию компакт-дисков и хотите оцифровать её. Когда вы копируете свои компакт-диски, имеет смысл использовать формат FLAC, формат без потерь. Это позволяет получить мастер-копию на компьютере, которая обладает тем же качеством звука, что и оригинальный компакт-диск.
Позже вы, возможно, захотите загрузить музыку на телефон или старый MP3-плеер. Здесь не так важно, чтобы музыка была в идеальном качестве, поэтому вы можете конвертировать файлы FLAC в MP3. Это даст вам аудиофайл, который по-прежнему достаточно хорош для прослушивания, но не занимает много места на мобильном устройстве. Качество MP3, преобразованного из FLAC, будет таким же, как если бы вы создали сжатый MP3 с оригинального CD.
Тип данных, представленных в файле, также может определять, какой вид сжатия подходит больше. В PNG используется сжатие без потерь, поэтому его хорошо использовать для изображений, в которых много однотонного пространства. Например, для скриншотов. Но PNG занимает гораздо больше места, когда картинка состоит из смеси множества цветов, как в случае с фотографиями. В этом случае с точки зрения размера файлов лучше использовать JPEG.
Проблемы во время сжатия файлов
Бесполезно конвертировать формат с потерями в формат без потерь. Это пустая трата пространства. Скажем, у вас есть MP3-файл весом в 3 МБ. Преобразование его в FLAC может привести к увеличению размера до 30 МБ. Но эти 30 МБ содержат только те звуки, которые имел уже сжатый MP3. Качество звука от этого не улучшится, но объём станет больше.
Также стоит иметь в виду, что преобразовывая один формат с потерями в аналогичный, вы получаете дальнейшее снижение качества. Каждый раз, когда вы применяете сжатие с потерями, вы теряете больше деталей. Это становится всё более и более заметно, пока файл по существу не будет разрушен. Помните также, что форматы с потерями удаляют некоторые данные и их невозможно восстановить.
Заключение
Мы рассмотрели как сжатие файлов с потерями, так и без потерь, чтобы увидеть, как они работают. Теперь вы знаете, как можно уменьшить размер файла и как выбрать лучший способ для этого.
Алгоритмы, которые определяют, какие данные выбрасываются в методах с потерями и как лучше хранить избыточные данные при сжатии без потерь, намного сложнее, чем описано здесь. На эту тему можно почитать больше информации здесь, если вам интересно.
Источник
Алгоритмы сжатия данных без потерь
Часть первая – историческая.
Введение
История
Иерархия алгоритмов: 
Хотя сжатие данных получило широкое распространение вместе с интернетом и после изобретения алгоритмов Лемпелем и Зивом (алгоритмы LZ), можно привести несколько более ранних примеров сжатия. Морзе, изобретая свой код в 1838 году, разумно назначил самым часто используемым буквам в английском языке, “e” и “t”, самые короткие последовательности (точка и тире соотв.). Вскоре после появления мейнфреймов в 1949 году был придуман алгоритм Шеннона — Фано, который назначал символам в блоке данных коды, основываясь на вероятности их появления в блоке. Вероятность появления символа в блоке была обратно пропорциональна длине кода, что позволяло сжать представление данных.
Дэвид Хаффман был студентом в классе у Роберта Фано и в качестве учебной работы выбрал поиск улучшенного метода бинарного кодирования данных. В результате ему удалось улучшить алгоритм Шеннона-Фано.
Ранние версии алгоритмов Шеннона-Фано и Хаффмана использовали заранее определённые коды. Позже для этого стали использовать коды, созданные динамически на основе данных, предназначаемых для сжатия. В 1977 году Лемпель и Зив опубликовали свой алгоритм LZ77, основанный на использования динамически создаваемого словаря (его ещё называют «скользящим окном»). В 78 году они опубликовали алгоритм LZ78, который сначала парсит данные и создаёт словарь, вместо того, чтобы создавать его динамически.
Проблемы с правами
Алгоритмы LZ77 и LZ78 получили большую популярность и вызвали волну улучшателей, из которых до наших дней дожили DEFLATE, LZMA и LZX. Большинство популярных алгоритмов основаны на LZ77, потому что производный от LZ78 алгоритм LZW был запатентован компанией Unisys в 1984 году, после чего они начали троллить всех и каждого, включая даже случаи использования изображений в формате GIF. В это время на UNIX использовали вариацию алгоритма LZW под названием LZC, и из-за проблем с правами их использование пришлось сворачивать. Предпочтение отдали алгоритму DEFLATE (gzip) и преобразованию Барроуза — Уилера, BWT (bzip2). Что было и к лучшему, так как эти алгоритмы почти всегда превосходят по сжатию LZW.
К 2003 году срок патента истёк, но поезд уже ушёл и алгоритм LZW сохранился, пожалуй, только в файлах GIF. Доминирующими являются алгоритмы на основе LZ77.
В 1993 году была ещё одна битва патентов – когда компания Stac Electronics обнаружила, что разработанный ею алгоритм LZS используется компанией Microsoft в программе для сжатия дисков, поставлявшейся с MS-DOS 6.0. Stac Electronics подала в суд и им удалось выиграть дело, в результате чего они получили более $100 миллионов.
Рост популярности Deflate
Большие корпорации использовали алгоритмы сжатия для хранения всё увеличивавшихся массивов данных, но истинное распространение алгоритмов произошло с рождением интернета в конце 80-х. Пропускная способность каналов была чрезвычайно узкой. Для сжатия данных, передаваемых по сети, были придуманы форматы ZIP, GIF и PNG.
Том Хендерсон придумал и выпустил первый коммерчески успешный архиватор ARC в 1985 году (компания System Enhancement Associates). ARC была популярной среди пользователей BBS, т.к. она одна из первых могла сжимать несколько файлов в архив, к тому же исходники её были открыты. ARC использовала модифицированный алгоритм LZW.
Фил Катц, вдохновлённый популярностью ARC, выпустил программу PKARC в формате shareware, в которой улучшил алгоритмы сжатия, переписав их на Ассемблере. Однако, был засужен Хендерсоном и был признан виновным. PKARC настолько открыто копировала ARC, что иногда даже повторялись опечатки в комментариях к исходному коду.
Но Фил Катц не растерялся, и в 1989 году сильно изменил архиватор и выпустил PKZIP. После того, как его атаковали уже в связи с патентом на алгоритм LZW, он изменил и базовый алгоритм на новый, под названием IMPLODE. Вновь формат был заменён в 1993 году с выходом PKZIP 2.0, и заменой стал DEFLATE. Среди новых возможностей была функция разбиения архива на тома. Эта версия до сих пор повсеместно используется, несмотря на почтенный возраст.
Формат изображений GIF (Graphics Interchange Format) был создан компанией CompuServe в 1987. Как известно, формат поддерживает сжатие изображения без потерь, и ограничен палитрой в 256 цветов. Несмотря на все потуги Unisys, ей не удалось остановить распространение этого формата. Он до сих пор популярен, особенно в связи с поддержкой анимации.
Слегка взволнованная патентными проблемами, компания CompuServe в 1994 году выпустила формат Portable Network Graphics (PNG). Как и ZIP, она использовала новый модный алгоритм DEFLATE. Хотя DEFLATE был запатентован Катцем, он не стал предъявлять никаких претензий.
Сейчас это самый популярный алгоритм сжатия. Кроме PNG и ZIP он используется в gzip, HTTP, SSL и других технологиях передачи данных.
К сожалению Фил Катц не дожил до триумфа DEFLATE, он умер от алкоголизма в 2000 году в возрасте 37 лет. Граждане – чрезмерное употребление алкоголя опасно для вашего здоровья! Вы можете не дожить до своего триумфа!
Современные архиваторы
ZIP царствовал безраздельно до середины 90-х, однако в 1993 году простой русский гений Евгений Рошал придумал свой формат и алгоритм RAR. Последние его версии основаны на алгоритмах PPM и LZSS. Сейчас ZIP, пожалуй, самый распространённый из форматов, RAR – до недавнего времени был стандартом для распространения различного малолегального контента через интернет (благодаря увеличению пропускной способности всё чаще файлы распространяются без архивации), а 7zip используется как формат с наилучшим сжатием при приемлемом времени работы. В мире UNIX используется связка tar + gzip (gzip — архиватор, а tar объединяет несколько файлов в один, т.к. gzip этого не умеет).
Прим. перев. Лично я, кроме перечисленных, сталкивался ещё с архиватором ARJ (Archived by Robert Jung), который был популярен в 90-х в эру BBS. Он поддерживал многотомные архивы, и так же, как после него RAR, использовался для распространения игр и прочего вареза. Ещё был архиватор HA от Harri Hirvola, который использовал сжатие HSC (не нашёл внятных объяснений — только «модель ограниченного контекста и арифметическое кодирование»), который хорошо справлялся со сжатием длинных текстовых файлов.
В 1996 году появился вариант алгоритма BWT с открытыми исходниками bzip2, и быстро приобрёл популярность. В 1999 году появилась программа 7-zip с форматом 7z. По сжатию она соперничает с RAR, её преимуществом является открытость, а также возможность выбора между алгоритмами bzip2, LZMA, LZMA2 и PPMd.
В 2002 году появился ещё один архиватор, PAQ. Автор Мэтт Махоуни использовал улучшенную версию алгоритма PPM с использованием техники под названием «контекстное смешивание». Она позволяет использовать больше одной статистической модели, чтобы улучшить предсказание по частоте появления символов.
Будущее алгоритмов сжатия
Конечно, бог его знает, но судя по всему, алгоритм PAQ набирает популярность благодаря очень хорошей степени сжатия (хотя и работает он очень медленно). Но благодаря увеличению быстродействия компьютеров скорость работы становится менее критичной.
С другой стороны, алгоритм Лемпеля-Зива –Маркова LZMA представляет собой компромисс между скоростью и степенью сжатия и может породить много интересных ответвлений.
Ещё одна интересная технология «substring enumeration» или CSE, которая пока мало используется в программах.
В следующей части мы рассмотрим техническую сторону упомянутых алгоритмов и принципы их работы.
Источник



