
- Объяснение алгоритмов сортировки с примерами на Python
- Авторизуйтесь
- Объяснение алгоритмов сортировки с примерами на Python
- Пузырьковая сортировка
- Алгоритм
- Реализация
- Время сортировки
- Сортировка выборкой
- Алгоритм
- Реализация
- Время сортировки
- Сортировка вставками
- Алгоритм
- Реализация
- Время сортировки
- Пирамидальная сортировка
- Алгоритм
- Реализация
- Время сортировки
- Сортировка слиянием
- Алгоритм
- Реализация
- Время сортировки
- Быстрая сортировка
- Алгоритм
- Реализация
- Время выполнения
- Встроенные функции сортировки на Python
- Сравнение скоростей сортировок
- Всё о сортировке в Python: исчерпывающий гайд
- Авторизуйтесь
- Всё о сортировке в Python: исчерпывающий гайд
- Основы сортировки
- Функции-ключи
- Функции модуля operator
- Сортировка по возрастанию и сортировка по убыванию в Python
- Стабильность сортировки и сложные сортировки в Python
- Декорируем-сортируем-раздекорируем
- Использование параметра cmp
- Поддержание порядка сортировки
- Прочее
Объяснение алгоритмов сортировки с примерами на Python
Авторизуйтесь
Объяснение алгоритмов сортировки с примерами на Python

В этой статье будут рассмотрены популярные алгоритмы, принципы их работы и реализация на Python. А ещё сравним, как быстро они сортируют элементы в списке.
В качестве общего примера возьмём сортировку чисел в порядке возрастания. Но эти методы можно легко адаптировать под ваши потребности.
Пузырьковая сортировка
Этот простой алгоритм выполняет итерации по списку, сравнивая элементы попарно и меняя их местами, пока более крупные элементы не «всплывут» в начало списка, а более мелкие не останутся на «дне».
Алгоритм
Сначала сравниваются первые два элемента списка. Если первый элемент больше, они меняются местами. Если они уже в нужном порядке, оставляем их как есть. Затем переходим к следующей паре элементов, сравниваем их значения и меняем местами при необходимости. Этот процесс продолжается до последней пары элементов в списке.
При достижении конца списка процесс повторяется заново для каждого элемента. Это крайне неэффективно, если в массиве нужно сделать, например, только один обмен. Алгоритм повторяется n² раз, даже если список уже отсортирован.
ABBYY , Москва, можно удалённо , До 230 000 ₽
Для оптимизации алгоритма нужно знать, когда его остановить, то есть когда список отсортирован.
Чтобы остановить алгоритм по окончании сортировки, нужно ввести переменную-флаг. Когда значения меняются местами, устанавливаем флаг в значение True , чтобы повторить процесс сортировки. Если перестановок не произошло, флаг остаётся False и алгоритм останавливается.
Реализация
Алгоритм работает в цикле while и прерывается, когда элементы ни разу не меняются местами. Вначале присваиваем swapped значение True , чтобы алгоритм запустился хотя бы один раз.
Время сортировки
Если взять самый худший случай (изначально список отсортирован по убыванию), затраты времени будут равны O(n²), где n — количество элементов списка.
Сортировка выборкой
Этот алгоритм сегментирует список на две части: отсортированную и неотсортированную. Наименьший элемент удаляется из второго списка и добавляется в первый.
Алгоритм
На практике не нужно создавать новый список для отсортированных элементов. В качестве него используется крайняя левая часть списка. Находится наименьший элемент и меняется с первым местами.
Теперь, когда нам известно, что первый элемент списка отсортирован, находим наименьший элемент из оставшихся и меняем местами со вторым. Повторяем это до тех пор, пока не останется последний элемент в списке.
Реализация
По мере увеличения значения i нужно проверять меньше элементов.
Время сортировки
Затраты времени на сортировку выборкой в среднем составляют O(n²), где n — количество элементов списка.
Сортировка вставками
Как и сортировка выборкой, этот алгоритм сегментирует список на две части: отсортированную и неотсортированную. Алгоритм перебирает второй сегмент и вставляет текущий элемент в правильную позицию первого сегмента.
Алгоритм
Предполагается, что первый элемент списка отсортирован. Переходим к следующему элементу, обозначим его х . Если х больше первого, оставляем его на своём месте. Если он меньше, копируем его на вторую позицию, а х устанавливаем как первый элемент.
Переходя к другим элементам несортированного сегмента, перемещаем более крупные элементы в отсортированном сегменте вверх по списку, пока не встретим элемент меньше x или не дойдём до конца списка. В первом случае x помещается на правильную позицию.
Реализация
Время сортировки
Время сортировки вставками в среднем равно O(n²), где n — количество элементов списка.
Пирамидальная сортировка
Также известна как сортировка кучей. Этот популярный алгоритм, как и сортировки вставками или выборкой, сегментирует список на две части: отсортированную и неотсортированную. Алгоритм преобразует второй сегмент списка в структуру данных «куча» (heap), чтобы можно было эффективно определить самый большой элемент.
Алгоритм
Сначала преобразуем список в Max Heap — бинарное дерево, где самый большой элемент является вершиной дерева. Затем помещаем этот элемент в конец списка. После перестраиваем Max Heap и снова помещаем новый наибольший элемент уже перед последним элементом в списке.
Этот процесс построения кучи повторяется, пока все вершины дерева не будут удалены.
Реализация
Создадим вспомогательную функцию heapify() для реализации этого алгоритма:
Время сортировки
В среднем время сортировки кучей составляет O(n log n), что уже значительно быстрее предыдущих алгоритмов.
Сортировка слиянием
Этот алгоритм относится к алгоритмам «разделяй и властвуй». Он разбивает список на две части, каждую из них он разбивает ещё на две и т. д. Список разбивается пополам, пока не останутся единичные элементы.
Соседние элементы становятся отсортированными парами. Затем эти пары объединяются и сортируются с другими парами. Этот процесс продолжается до тех пор, пока не отсортируются все элементы.
Алгоритм
Список рекурсивно разделяется пополам, пока в итоге не получатся списки размером в один элемент. Массив из одного элемента считается упорядоченным. Соседние элементы сравниваются и соединяются вместе. Это происходит до тех пор, пока не получится полный отсортированный список.
Сортировка осуществляется путём сравнения наименьших элементов каждого подмассива. Первые элементы каждого подмассива сравниваются первыми. Наименьший элемент перемещается в результирующий массив. Счётчики результирующего массива и подмассива, откуда был взят элемент, увеличиваются на 1.
Реализация
Обратите внимание, что функция merge_sort() , в отличие от предыдущих алгоритмов, возвращает новый список, а не сортирует существующий. Поэтому такая сортировка требует больше памяти для создания нового списка того же размера, что и входной список.
Время сортировки
В среднем время сортировки слиянием составляет O(n log n).
Быстрая сортировка
Этот алгоритм также относится к алгоритмам «разделяй и властвуй». Его используют чаще других алгоритмов, описанных в этой статье. При правильной конфигурации он чрезвычайно эффективен и не требует дополнительной памяти, в отличие от сортировки слиянием. Массив разделяется на две части по разные стороны от опорного элемента. В процессе сортировки элементы меньше опорного помещаются перед ним, а равные или большие — позади.
Алгоритм
Быстрая сортировка начинается с разбиения списка и выбора одного из элементов в качестве опорного. А всё остальное передвигаем так, чтобы этот элемент встал на своё место. Все элементы меньше него перемещаются влево, а равные и большие элементы перемещаются вправо.
Реализация
Существует много вариаций данного метода. Способ разбиения массива, рассмотренный здесь, соответствует схеме Хоара (создателя данного алгоритма).
Время выполнения
В среднем время выполнения быстрой сортировки составляет O(n log n).
Обратите внимание, что алгоритм быстрой сортировки будет работать медленно, если опорный элемент равен наименьшему или наибольшему элементам списка. При таких условиях, в отличие от сортировок кучей и слиянием, обе из которых имеют в худшем случае время сортировки O(n log n), быстрая сортировка в худшем случае будет выполняться O(n²).
Встроенные функции сортировки на Python
Иногда полезно знать перечисленные выше алгоритмы, но в большинстве случаев разработчик, скорее всего, будет использовать функции сортировки, уже предоставленные в языке программирования.
Отсортировать содержимое списка можно с помощью стандартного метода sort() :
Или можно использовать функцию sorted() для создания нового отсортированного списка, оставив входной список нетронутым:
Оба эти метода сортируют в порядке возрастания, но можно изменить порядок, установив для флага reverse значение True :
В отличие от других алгоритмов, обе функции в Python могут сортировать также списки кортежей и классов. Функция sorted() может сортировать любую последовательность, которая включает списки, строки, кортежи, словари, наборы и пользовательские итераторы, которые вы можете создать.
Функции в Python реализуют алгоритм Tim Sort, основанный на сортировке слиянием и сортировке вставкой.
Сравнение скоростей сортировок
Для сравнения сгенерируем массив из 5000 чисел от 0 до 1000. Затем определим время, необходимое для завершения каждого алгоритма. Повторим каждый метод 10 раз, чтобы можно было более точно установить, насколько каждый из них производителен.
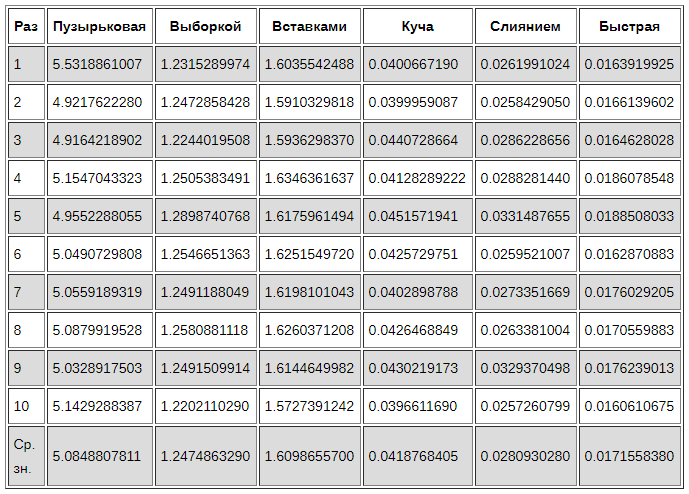
Пузырьковая сортировка — самый медленный из всех алгоритмов. Возможно, он будет полезен как введение в тему алгоритмов сортировки, но не подходит для практического использования.
Быстрая сортировка хорошо оправдывает своё название, почти в два раза быстрее, чем сортировка слиянием, и не требуется дополнительное место для результирующего массива.
Сортировка вставками выполняет меньше сравнений, чем сортировка выборкой и в реальности должна быть производительнее, но в данном эксперименте она выполняется немного медленней. Сортировка вставками делает гораздо больше обменов элементами. Если эти обмены занимают намного больше времени, чем сравнение самих элементов, то такой результат вполне закономерен.
Вы познакомились с шестью различными алгоритмами сортировок и их реализациями на Python. Масштаб сравнения и количество перестановок, которые выполняет алгоритм вместе со средой выполнения кода, будут определяющими факторами в производительности. В реальных приложениях Python рекомендуется использовать встроенные функции сортировки, поскольку они реализованы именно для удобства разработчика.
Лучше понять эти алгоритмы вам поможет их визуализация.
Источник
Всё о сортировке в Python: исчерпывающий гайд
Авторизуйтесь
Всё о сортировке в Python: исчерпывающий гайд
Сортировка в Python выполняется функцией sorted() , если это итерируемые объекты, и методом list.sort() , если это список. Рассмотрим подробнее, как это работало в старых версиях и как работает сейчас.
Примечание Вы читаете улучшенную версию некогда выпущенной нами статьи.
Основы сортировки
Для сортировки по возрастанию достаточно вызвать функцию сортировки Python sorted() , которая вернёт новый отсортированный список:
Также можно использовать метод списков list.sort() , который изменяет исходный список (и возвращает None во избежание путаницы). Обычно это не так удобно, как использование sorted() , но если вам не нужен исходный список, то так будет немного эффективнее:
Прим.перев. В Python вернуть None и не вернуть ничего — одно и то же.
Ещё одно отличие заключается в том, что метод list.sort() определён только для списков, в то время как sorted() работает со всеми итерируемыми объектами:
Прим.перев. При итерировании по словарю Python возвращает его ключи. Если вам нужны их значения или пары «ключ-значение», используйте методы dict.values() и dict.items() соответственно.
Рассмотрим основные функции сортировки Python.
Функции-ключи
С версии Python 2.4 у list.sort() и sorted() появился параметр key для указания функции, которая будет вызываться на каждом элементе до сравнения. Вот регистронезависимое сравнение строк:
Значение key должно быть функцией, принимающей один аргумент и возвращающей ключ для сортировки. Работает быстро, потому что функция-ключ вызывается один раз для каждого элемента.
Часто можно встретить код, где сложный объект сортируется по одному из его индексов. Например:
Тот же метод работает для объектов с именованными атрибутами:
Функции модуля operator
Показанные выше примеры функций-ключей встречаются настолько часто, что Python предлагает удобные функции, чтобы сделать всё проще и быстрее. Модуль operator содержит функции itemgetter() , attrgetter() и, начиная с Python 2.6, methodcaller() . С ними всё ещё проще:
Функции operator дают возможность использовать множественные уровни сортировки в Python. Отсортируем учеников сначала по оценке, а затем по возрасту:
Используем функцию methodcaller() для сортировки учеников по взвешенной оценке:
Сортировка по возрастанию и сортировка по убыванию в Python
У list.sort() и sorted() есть параметр reverse , принимающий boolean-значение. Он нужен для обозначения сортировки по убыванию. Отсортируем учеников по убыванию возраста:
Стабильность сортировки и сложные сортировки в Python
Начиная с версии Python 2.2, сортировки гарантированно стабильны: если у нескольких записей есть одинаковые ключи, их порядок останется прежним. Пример:
Обратите внимание, что две записи с ‘blue’ сохранили начальный порядок. Это свойство позволяет составлять сложные сортировки путём постепенных сортировок. Далее мы сортируем данные учеников сначала по возрасту в порядке возрастания, а затем по оценкам в убывающем порядке, чтобы получить данные, отсортированные в первую очередь по оценке и во вторую — по возрасту:
Алгоритмы сортировки Python вроде Timsort проводят множественные сортировки так эффективно, потому что может извлечь пользу из любого порядка, уже присутствующего в наборе данных.
Декорируем-сортируем-раздекорируем
- Сначала исходный список пополняется новыми значениями, контролирующими порядок сортировки.
- Затем новый список сортируется.
- После этого добавленные значения убираются, и в итоге остаётся отсортированный список, содержащий только исходные элементы.
Вот так можно отсортировать данные учеников по оценке:
Это работает из-за того, что кортежи сравниваются лексикографически, сравниваются первые элементы, а если они совпадают, то сравниваются вторые и так далее.
Не всегда обязательно включать индекс в декорируемый список, но у него есть преимущества:
- Сортировка стабильна — если у двух элементов одинаковый ключ, то их порядок не изменится.
- У исходных элементов не обязательно должна быть возможность сравнения, так как порядок декорированных кортежей будет определяться максимум по первым двум элементам. Например, исходный список может содержать комплексные числа, которые нельзя сравнивать напрямую.
Ещё эта идиома называется преобразованием Шварца в честь Рэндела Шварца, который популяризировал её среди Perl-программистов.
Для больших списков и версий Python ниже 2.4, «декорируем-сортируем-раздекорируем» будет оптимальным способом сортировки. Для версий 2.4+ ту же функциональность предоставляют функции-ключи.
Использование параметра cmp
Все версии Python 2.x поддерживали параметр cmp для обработки пользовательских функций сравнения. В Python 3.0 от этого параметра полностью избавились. В Python 2.x в sort() можно было передать функцию, которая использовалась бы для сравнения элементов. Она должна принимать два аргумента и возвращать отрицательное значение для случая «меньше чем», положительное — для «больше чем» и ноль, если они равны:
Можно сравнивать в обратном порядке:
При портировании кода с версии 2.x на 3.x может возникнуть ситуация, когда нужно преобразовать пользовательскую функцию для сравнения в функцию-ключ. Следующая обёртка упрощает эту задачу:
Чтобы произвести преобразование, оберните старую функцию:
В Python 2.7 функция cmp_to_key() была добавлена в модуль functools.
Поддержание порядка сортировки
В стандартной библиотеке Python нет модулей, аналогичных типам данных C++ вроде set и map . Python делегирует эту задачу сторонним библиотекам, доступным в Python Package Index: они используют различные методы для сохранения типов list , dict и set в отсортированном порядке. Поддержание порядка с помощью специальной структуры данных может помочь избежать очень медленного поведения (квадратичного времени выполнения) при наивном подходе с редактированием и постоянной пересортировкой данных. Вот некоторые из модулей, реализующих эти типы данных:
- SortedContainers — реализация сортированных типов list , dict и set на чистом Python, по скорости не уступает реализациям на C. Тестирование включает 100% покрытие кода и многие часы стресс-тестирования. В документации можно найти полный справочник по API, сравнение производительности и руководства по внесению своего вклада.
- rbtree — быстрая реализация на C для типов dict и set . Реализация использует структуру данных, известную как красно-чёрное дерево.
- treap — сортированный dict . В реализации используется Декартово дерево, а производительность улучшена с помощью Cython.
- bintrees — несколько реализаций типов dict и set на основе деревьев на C. Самые быстрые основаны на АВЛ и красно-чёрных деревьях. Расширяет общепринятый API для предоставления операций множеств для словарей.
- banyan — быстрая реализация dict и set на C.
- skiplistcollections — реализация на чистом Python, основанная на списках с пропусками, предлагает ограниченный API для типов dict и set .
- blist — предоставляет сортированные типы list , dict и set , основанные на типе данных «blist», реализация на Б-деревьях. Написано на Python и C.
Прочее
Для сортировки с учётом языка используйте locale.strxfrm() в качестве ключевой функции или locale.strcoll() в качестве функции сравнения. Параметр reverse всё ещё сохраняет стабильность сортировки. Этот эффект можно сымитировать без параметра, использовав встроенную функцию reversed() дважды:
Чтобы создать стандартный порядок сортировки для класса, просто добавьте реализацию соответствующих методов сравнения:
Источник



