
Язык структурных запросов SQL




![]()
![]()
Стандарт и реализация языка SQL.Увеличение объемов информации, необходимость хранения огромных массивов данных и их обработки привели к тому, что возникла потребность в создании стандартного языка БД, который мог бы использоваться в многочисленных компьютерных системах различных видов (на персональном компьютере, сетевой рабочей станции, универсальной ЭВМ и т. д.). Таким языком, согласно известным сведениям [1, 21, 22], стал язык SQL (Structured Query Language). В настоящее время он получил очень широкое распространение и фактически превратился в стандартный язык реляционных БД. В 1986 г. Американский национальный институт стандартов (ANSI) выпустил стандарт на язык SQL, а в 1987 г. Международная организация стандартов (ISO) приняла его в качестве международного; сейчас это SQL/92.
Однако использование любых стандартов наряду с очевидными преимуществами, порождает определенные недостатки. Прежде всего, стандарты направляют в определенное русло развитие соответствующей индустрии; в случае языка SQL наличие твердых основополагающих принципов приводит, в конечном счете, к совместимости его различных реализаций и способствует как повышению переносимости программного обеспечения и БД в целом, так и универсальности работы администраторов БД. С другой стороны, стандарты ограничивают гибкость и функциональные возможности конкретной реализации. Под реализацией языка SQL понимается программный продукт SQL соответствующего производителя. Для расширения функциональных возможностей добавляют к стандартному языку SQL различные расширения. Следует отметить, что стандарты требуют от любой законченной реализации языка SQL наличия определенных характеристик и в общих чертах отражают основные тенденции, которые не только приводят к совместимости между всеми конкурирующими реализациями, но и способствуют повышению значимости программистов SQL и пользователей реляционных БД на современном рынке программного обеспечения.
Все конкретные реализации языка несколько отличаются друг от друга, и в то же время соответствуют современным стандартам ANSI в части переносимости и удобства работы пользователей. Отличия в реализациях заключаются в усовершенствовании или расширении языка SQL, которые представляют собой дополнительные команды и опции, являющиеся добавлениями к стандартному пакету, доступные в данной конкретной реализации.
В настоящее время язык SQL поддерживают десятки СУБД различных типов, разработанных для самых разнообразных вычислительных платформ.
Языки манипулирования данными, созданные для СУБД до появления реляционных БД, были ориентированы на операции с данными, представленными в виде логических записей файлов. Поэтому пользователь должен был детально знать организацию хранения данных и предпринимать серьезные усилия для указания типов и структур данных, их размещения и способа получения.
Язык SQL ориентирован на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц-отношений. Важнейшая особенность его структур — ориентация на конечный результат обработки данных, а не на процедуру этой обработки. Язык SQL сам определяет, где находятся данные, индексы и даже то, какие наиболее эффективные последовательности операций следует использовать для получения результата, а потому указывать эти детали в запросе к БД не требуется.
Формы языка SQL.Структурированный язык запросов SQL реализуется в следующих формах:
Интерактивный SQL позволяет конечному пользователю в интерактивном режиме выполнять SQL-операторы. Все СУБД предоставляют инструментальные средства для работы с БД в интерактивном режиме. Например, СУБД Oracle включает утилиту SQL*Plus, позволяющую в строчном режиме выполнять большинство SQL-операторов.
Статический SQL может реализовываться как встроенный SQL или модульный SQL. Операторы статического SQL определены уже в момент компиляции программы.
Динамический SQL позволяет формировать операторы SQL во время выполнения программы.
Встроенный SQL позволяет включать операторы SQL в код программы на другом языке программирования (например, C++).

Типы данных SQL.Данные, хранящиеся в столбцах таблиц SQL-ориентированной БД, являются типизированными, т. е. представляют собой значения одного из типов данных, предопределенных в языке SQL или определяемых пользователями путем применения соответствующих средств языка. Для этого при определении таблицы каждому ее столбцу назначается некоторый тип данных (или домен), и в дальнейшем СУБД должна следить, чтобы в каждом столбце каждой строки каждой таблицы присутствовали только допустимые значения. В этом разделе мы обсудим систему типов языка SQL.
Все допустимые в SQL типы данных, которые можно использовать при определении столбцов, разбиваются на следующие категории [22]:
1. точные числовые типы;
2. приближенные числовые типы;
3. типы символьных строк;
4. типы битовых строк;
5. типы даты и времени;
6. типы временных интервалов;
7. булевский тип;
8. типы коллекций;
9. анонимные строчные типы;
10. типы, определяемые пользователем;
11. ссылочные типы.
В столбцах таблиц, определенных на любых типах данных, наряду со значениями этих типов, допускается сохранение неопределенного значения, которое обозначается ключевым словом NULL.
Подробная информация о типах данных языка содержится в специальной литературе.
Понятие домена.Домен — это набор допустимых значений для одного или нескольких атрибутов. Если в таблице БД или в нескольких таблицах присутствуют столбцы, обладающие одними и теми же характеристиками, можно описать тип такого столбца и его поведение через домен, а затем поставить в соответствие каждому из одинаковых столбцов имя домена. Домен определяет все потенциальные значения, которые могут быть присвоены атрибуту [21].
Стандарт SQL позволяет определить домен с помощью следующего оператора:

Каждому создаваемому домену присваивается имя, тип данных, значение по умолчанию и набор допустимых значений. Следует отметить, что приведенный формат оператора является неполным. Теперь при создании таблицы можно указать вместо типа данных имя домена.
Удаление доменов из БД выполняется с помощью оператора:
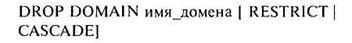
Альтернативой доменам в среде SQL Server являются пользовательские типы данных.
Подробная информация о доменах содержится в специальной литературе.
Группы операторов SQL.Язык SQL определяет:
1. операторы языка, называемые иногда командами языка SQL;
3. набор встроенных функций.
По своему логическому назначению операторы языка SQL часто разбиваются на следующие группы [23]:
1. язык определения данных DDL (Data Definition Language);
2. язык манипулирования данными DML (Data Manipulation Language).
Язык определения данныхвключает операторы, управляющие объектами БД. К последним относятся таблицы, индексы, представления. Для каждой конкретной БД существует свой набор объектов БД, который может значительно расширять набор объектов, предусмотренный стандартом. В некоторых СУБД, таких как Oracle, все объекты БД, принадлежащие одному пользователю, образуют схему БД. С другой стороны, в стандарте SQL92 термином «схема» стали называть группу взаимосвязанных таблиц:
CREATE SCHEMA — создать схему БД;
DROP SHEMA — удалить схему БД;
CREATE TABLE — создать таблицу;
ALTER TABLE — изменить таблицу;
DROP TABLE — удалить таблицу;
CREATE DOMAIN — создать домен;
ALTER DOMAIN — изменить домен;
DROP DOMAIN — удалить домен;
CREATE COLLATION — создать последовательность;
DROP COLLATION — удалить последовательность;
CREATE VIEW — создать представление;
DROP VIEW — удалить представление.
Язык манипулирования даннымивключает операторы, управляющие содержанием таблиц БД и извлекающие информацию из этих таблиц. К таким операторам относятся:
SELECT — извлечение данных из одной или нескольких таблиц;
INSERT — добавление строк в таблицу;
DELETE — удаление строк из таблицы;
UPDATE — изменение значений полей в таблице.
Оператор INSERT вставляет в таблицу новую запись:
Число значений должно соответствовать числу указанных полей. Полям, не перечисленным в списке, присваивается значение NULL. Полю SERIAL, если его нет в списке или указано значение 0, присваивается новое уникальное значение. Если значение указано явно, то оно и присваивается.
Кроме констант для задания значений можно использовать выражения: строковые, арифметические, дату и др., и функции:
USER — имя пользователя, выполняющего данный оператор;
TODAY — дата выполнения оператора;
CURRENT — момент времени выполнения оператора.
Для удаления ненужных записей в таблице используется оператор DELETE:
DELETE FROM [WHERE ].
Фазы выполнения SQL-оператора приведены в табл. 3.4.
Понятие транзакции.Транзакцией называется последовательность действий, которая или полностью фиксируется в БД, или полностью отменяется. Иногда под транзакцией также подразумевают не группу SQL-операторов, а интервал времени, выполняемые в течение которого SQL-операторы можно или все зафиксировать или все отменить [24].
Таблица 3.4. Фазы выполнения SQL-оператора

Так, операция перевода денег с одного счета на другой должна составлять единую транзакцию. Иначе может возникнуть ситуация, когда первый SQL-оператор переведет деньги на другой счет, а второй, выполняющий снятие их со счета, не доведет дело до конца из-за непредвиденного сбоя.
Фиксация транзакции может производиться принудительно по SQL-оператору или неявно после завершения каждого SQL-оператора. Во втором случае применяется режим автокоммита. Как правило, выполнение SQL-операторов в интерактивном режиме всегда использует автокоммит. Очень часто в интегрированных средах разработки классы, инкапсулирующие работу с базой данных, по умолчанию предполагают режим автокоммита [24].
Новая транзакция начинается с начала каждого сеанса работы с базой данных. Далее все выполняемые SQL-операторы будут входить в одну транзакцию до тех пор, пока не будет выполнен оператор COMMIT WORK или ROLLBACK WORK.
Оператор COMMIT WORK завершает текущую транзакцию, выполняя фиксацию сделанных изменений в базе данных. Иногда говорят, что оператор COMMIT WORK фиксирует транзакцию.
Оператор ROLLBACK WORK выполняет откат транзакции, отменяя действие всех SQL-операторов, выполненных в текущей транзакции.
Логически транзакция должна объединять только выполнение взаимосвязанных операций. Так, если делать транзакции «очень большими», состоящими из последовательности не связанных между собой операторов, то любой сбой, автоматически выполняющий откат транзакции, повлияет на отмену действий, которые могли бы быть успешно завершены при более «коротких» транзакциях [24].
Источник
Стандарт и реализация языка SQL
Дата добавления: 2013-12-23 ; просмотров: 2694 ; Нарушение авторских прав
Реляционные связи между таблицами баз данных
Связи между объектами реального мира могут находить свое отражение в структуре данных, а могут и подразумеваться, т.е. присутствовать на неформальном уровне.
Между двумя или более таблицами базы данных могут существовать отношения подчиненности, которые определяют, что для каждой записи главной таблицы (называемой еще родительской) возможно наличие одной или нескольких записей в подчиненной таблице (называемой еще дочерней).
Выделяют три разновидности связи между таблицами базы данных:
Отношение «один–ко–многим»
Отношение «один–ко–многим» имеет место, когда одной записи родительской таблицы может соответствовать несколько записей дочерней. Связь «один–ко–многим» иногда называют связью «многие–к–одному». И в том, и в другом случае сущность связи между таблицами остается неизменной. Связь «один–ко–многим» является самой распространенной для реляционных баз данных. Она позволяет моделировать также иерархические структуры данных.
Отношение «один–к–одному»
Отношение «один–к–одному» имеет место, когда одной записи в родительской таблице соответствует одна запись в дочерней. Это отношение встречается намного реже, чем отношение «один–ко–многим». Его используют, если не хотят, чтобы таблица БД «распухала» от второстепенной информации, однако для чтения связанной информации в нескольких таблицах приходится производить ряд операций чтения вместо одной, когда данные хранятся в одной таблице.
Отношение «многие–ко–многим»
Отношение «многие–ко–многим» применяется в следующих случаях:
- одной записи в родительской таблице соответствует более одной записи в дочерней;
- одной записи в дочерней таблице соответствует более одной записи в родительской.
Всякую связь «многие–ко–многим» в реляционной базе данных необходимо заменить на связь «один–ко–многим» (одну или более) с помощью введения дополнительных таблиц.
Рост количества данных, необходимость их хранения и обработки привели к тому, что возникла потребность в создании стандартного языка баз данных, который мог бы функционировать в многочисленных компьютерных системах различных видов. Действительно, с его помощью пользователи могут манипулировать данными независимо от того, работают ли они на персональном компьютере, сетевой рабочей станции или универсальной ЭВМ.
Одним из языков, появившихся в результате разработки реляционной модели данных, является язык SQL (Structured Query Language), который в настоящее время получил очень широкое распространение и фактически превратился в стандартный язык реляционных баз данных. Стандарт на язык SQL был выпущен Американским национальным институтом стандартов (ANSI) в 1986 г., а в 1987 г. Международная организация стандартов (ISO) приняла его в качестве международного. Нынешний стандарт SQL известен под названием SQL/92.
С использованием любых стандартов связаны не только многочисленные и вполне очевидные преимущества, но и определенные недостатки. Прежде всего, стандарты направляют в определенное русло развитие соответствующей индустрии; в случае языка SQL наличие твердых основополагающих принципов приводит, в конечном счете, к совместимости его различных реализаций и способствует как повышению переносимости программного обеспечения и баз данных в целом, так и универсальности работы администраторов баз данных. С другой стороны, стандарты ограничивают гибкость и функциональные возможности конкретной реализации. Под реализацией языка SQL понимается программный продукт SQL соответствующего производителя. Для расширения функциональных возможностей многие разработчики, придерживающиеся принятых стандартов, добавляют к стандартному языку SQL различные расширения. Следует отметить, что стандарты требуют от любой законченной реализации языка SQL наличия определенных характеристик и в общих чертах отражают основные тенденции, которые не только приводят к совместимости между всеми конкурирующими реализациями, но и способствуют повышению значимости программистов SQL и пользователей реляционных баз данных на современном рынке программного обеспечения.
Все конкретные реализации языка несколько отличаются друг от друга. В интересах самих же производителей гарантировать, чтобы их реализация соответствовала современным стандартам ANSI в части переносимости и удобства работы пользователей. Тем не менее каждая реализация SQL содержит усовершенствования, отвечающие требованиям того или иного сервера баз данных. Эти усовершенствования или расширения языка SQL представляют собой дополнительные команды и опции, являющиеся добавлениями к стандартному пакету и доступные в данной конкретной реализации.
В настоящее время язык SQL поддерживается многими десятками СУБД различных типов, разработанных для самых разнообразных вычислительных платформ, начиная от персональных компьютеров и заканчивая мейнфреймами.
Все языки манипулирования данными, созданные для многих СУБД до появления реляционных баз данных, были ориентированы на операции с данными, представленными в виде логических записей файлов. Разумеется, это требовало от пользователя детального знания организации хранения данных и серьезных усилий для указания того, какие данные необходимы, где они размещаются и как их получить.
Рассматриваемый язык SQL ориентирован на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц -отношений. Важнейшая особенность его структур – ориентация на конечный результат обработки данных, а не на процедуру этой обработки. Язык SQL сам определяет, где находятся данные, индексы и даже какие наиболее эффективные последовательности операций следует использовать для получения результата, а потому указывать эти детали в запросе к базе данных не требуется.
Источник



