
- 13. Методика расчёта ошибок выборки для средней и доли. Определение численности выборочной совокупности
- Выборка. Типы выборок. Расчет ошибки выборки
- Калькуляторы
- Генеральная совокупность
- Выборка (Выборочная совокупность)
- Репрезентативность выборки
- Ошибка выборки (доверительный интервал)
- Типы выборок
- Курс лекций по теории статистики
- Калькулятор расчета ошибки и размера выборки (для простой случайной выборки)
- Калькулятор расчета статистической значимости различий
- Выборочное наблюдение в статистике
- 11.2. Оценка результатов выборочного наблюдения
- 11.2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
- 11.2.2. Определение численности выборочной совокупности
13. Методика расчёта ошибок выборки для средней и доли. Определение численности выборочной совокупности
Основные характеристики параметров генеральной и выборочной совокупностей обозначаются символами: N – объем генеральной совокупности (число входящих в нее единиц); n – объем выборки (число обследованных единиц); 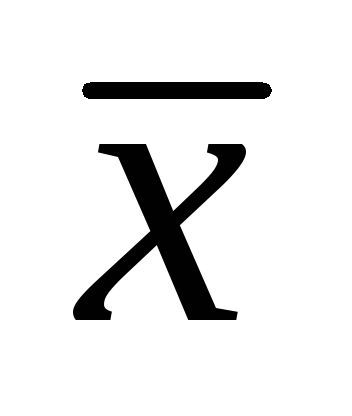 — генеральная средняя (среднее значение признака в генеральной совокупности);
— генеральная средняя (среднее значение признака в генеральной совокупности);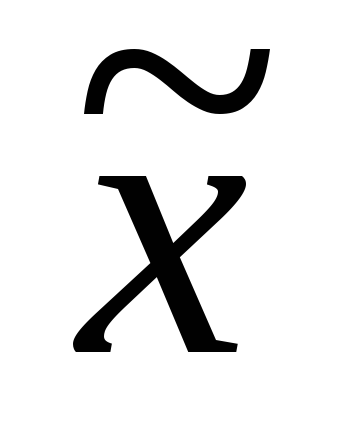 — выборочная средняя;p – генеральная доля (доля единиц, обладающих данным значением признака в общем числе единиц генеральной совокупности); w – выборочная доля. Доля выборки есть отношение числа единиц выборочной совокупности к числу единиц генеральной совокупности:
— выборочная средняя;p – генеральная доля (доля единиц, обладающих данным значением признака в общем числе единиц генеральной совокупности); w – выборочная доля. Доля выборки есть отношение числа единиц выборочной совокупности к числу единиц генеральной совокупности: 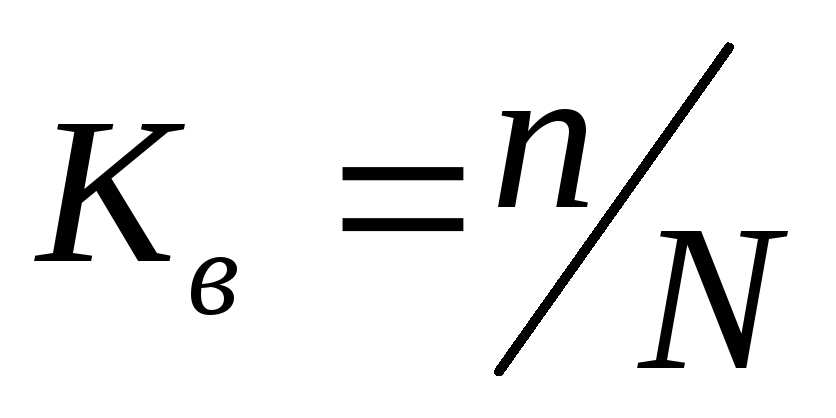 . Выборочная доля (w ), определяется отношением числа единиц, обладающих изучаемым признаком m, к общему числу единиц выборочной совокупности n: w = m / n . Для характеристики надежности выборочных показателей различают среднюю и предельную ошибки выборки. Ошибка выборки
. Выборочная доля (w ), определяется отношением числа единиц, обладающих изучаемым признаком m, к общему числу единиц выборочной совокупности n: w = m / n . Для характеристики надежности выборочных показателей различают среднюю и предельную ошибки выборки. Ошибка выборки  — разность соответствующих выборочных и генеральных характеристик: для средней количественного признака
— разность соответствующих выборочных и генеральных характеристик: для средней количественного признака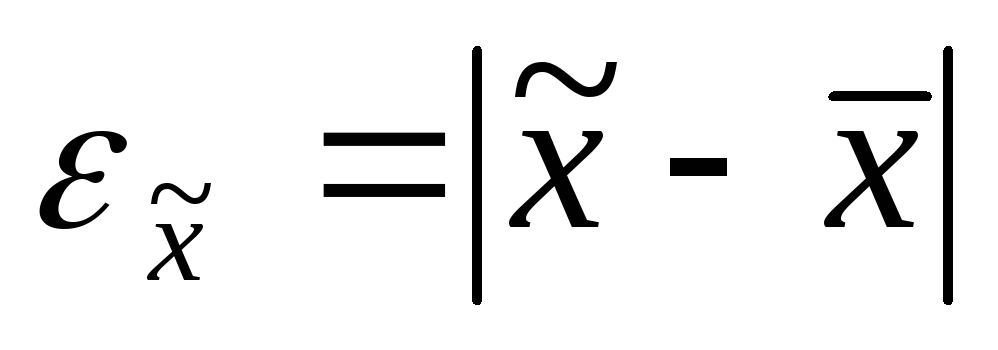 ; для доли (альтернативного признака)
; для доли (альтернативного признака)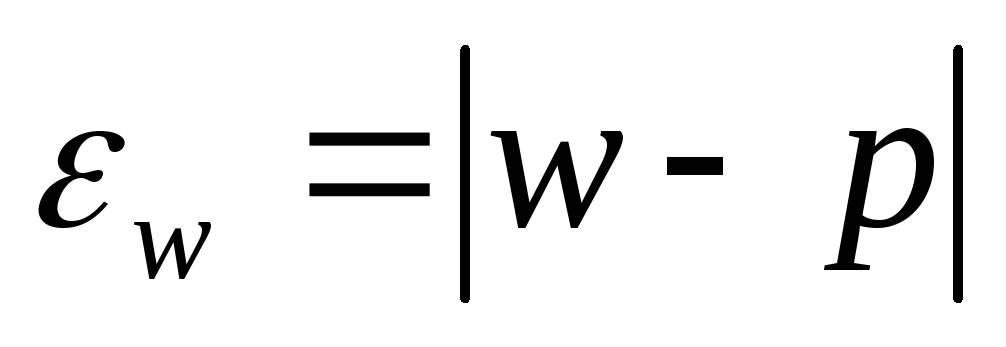 . Выборочная средняя и выборочная доля являются случайными величинами, которые могут принимать различные значения.
. Выборочная средняя и выборочная доля являются случайными величинами, которые могут принимать различные значения.
Предельная ошибка выборки для средней при повторном отборе 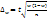 . При случайном бесповторном отборе нужно умножить подкоренное выражение на 1 – (n/N).
. При случайном бесповторном отборе нужно умножить подкоренное выражение на 1 – (n/N).
Формулы для определения необходимой численности выборки n получают из формул ошибок выборки (нужно выразить n). Формулы показывают, что с увеличением предполагаемой ошибки выборки значительно уменьшается необходимый объем выборки. Для расчета объема нужно знать дисперсию.
14. Виды и формы взаимосвязей социально-экономических явлений. Корреляционная связь, ее особенности, методы выявления и оценки тесноты связи. Корреляционная связь – частный случай статистической связи при котором разным значениям переменной соответствуют разные средние значения другой переменной. Классификация связи:1.По степени тесноты связи: -функциональные у=f(х)
—стахостические коррялиционные связи у = f(х) + ε 2. По направлении:
-прямые и обратные.При прямой связи с увеличением факторного признака, увеличивается результативный. При обратной с увеличением факторного признака, результативный уменьшается. 3. По аналитическому выражению.-прямолинейная у = ах+в -криволинейная у = х 3 4. По количеству взаимодействующих факторов:
5. По силе связи: -слабые и сильные. Чем ближе она к функциональной, тем она считается сильнее.I.Исследование связи начинается с качественного, теоретического анализа явления, определение факторного и результативного признака и проверки наличие связи.Наличие связи проверяется с использованием методов: 1.Метод параллельных рядов. Факторные признаки располагаются в порядке возрастания. Параллельно им записываются значение результативного признака.. Связь существует с возрастанием одного растет другое, связь прямая. Сопоставляя значение этих двух рядов делают вывод о наличии и направление связи.2.Графический метод. Заключается в построении графика, где по оси х откладывается значение факторного признака, по оси у – результативного признака. Совокупность точек х и у образуют корреляционное поле, по их расположению можно сделать вывод о наличии и направлении связи. 3.Метод корреляционных таблиц. Корреляционная таблица – это таблица в подлежащей которой перечисляется значение факторного признака или группы, сказуемым значение результативного признака или их группы. В клетке таблицы записываются частоты.Если частоты концентрируются вдоль главной диагонали, то делают вывод о наличии прямой связи, если она концентрируется вдоль побочной диагонали – то наличие обратной связи, если расположены беспорядочно, то отсутствие связи.4.Метод аналитической группировки. Совокупность разбивается на группы по факторному признаку.И каждая группа характеризуется средним значением факторного и результативного признака.Сопоставляя среднее значение делают вывод о наличии направление связи.
II.Этап изучение совокупности. Оценка существенности связи. Оцениваются с помощью критерия Филлера. Для этого рассчитывается фактическое значение критерия. Ф расч. сравнивается с табличной. Фрасч.>Фтабл. – вывод о существенности связи. Фрасч. Фтабл. – вывод о существенности связи. Фрасч. 6 / 11 6 7 8 9 10 11 > Следующая > >>
Тут вы можете оставить комментарий к выбранному абзацу или сообщить об ошибке.
Источник
Выборка. Типы выборок. Расчет ошибки выборки
Калькуляторы
Генеральная совокупность
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и времени. Примеры генеральных совокупностей
- Все жители Москвы (10,6 млн. человек по данным переписи 2002 года)
- Мужчины-Москвичи (4,9 млн. человек по данным переписи 2002 года)
- Юридические лица России (2,2 млн. на начало 2005 года)
- Розничные торговые точки, осуществляющие продажу продуктов питания (20 тысяч на начало 2008 года) и т.д.
Выборка (Выборочная совокупность)
Часть объектов из генеральной совокупности, отобранных для изучения, с тем чтобы сделать заключение обо всей генеральной совокупности. Для того чтобы заключение, полученное путем изучения выборки, можно было распространить на всю генеральную совокупность, выборка должна обладать свойством репрезентативности.
Репрезентативность выборки
Свойство выборки корректно отражать генеральную совокупность. Одна и та же выборка может быть репрезентативной и нерепрезентативной для разных генеральных совокупностей.
Пример:
- Выборка, целиком состоящая из москвичей, владеющих автомобилем, не репрезентирует все население Москвы.
- Выборка из российских предприятий численностью до 100 человек не репрезентирует все предприятия России.
- Выборка из москвичей, совершающих покупки на рынке, не репрезентирует покупательское поведение всех москвичей.
В то же время, указанные выборки (при соблюдении прочих условий) могут отлично репрезентировать москвичей-автовладельцев, небольшие и средние российские предприятия и покупателей, совершающих покупки на рынках соответственно.
Важно понимать, что репрезентативность выборки и ошибка выборки – разные явления. Репрезентативность, в отличие от ошибки никак не зависит от размера выборки.
Пример:
Как бы мы не увеличивали количество опрошенных москвичей-автовладельцев, мы не сможем репрезентировать этой выборкой всех москвичей.
Ошибка выборки (доверительный интервал)
Отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности.
Ошибка выборки бывает двух видов – статистическая и систематическая. Статистическая ошибка зависит от размера выборки. Чем больше размер выборки, тем она ниже.
Пример:
Для простой случайной выборки размером 400 единиц максимальная статистическая ошибка (с 95% доверительной вероятностью) составляет 5%, для выборки в 600 единиц – 4%, для выборки в 1100 единиц – 3% Обычно, когда говорят об ошибке выборки, подразумевают именно статистическую ошибку.
Систематическая ошибка зависит от различных факторов, оказывающих постоянное воздействие на исследование и смещающих результаты исследования в определенную сторону.
Пример:
- Использование любых вероятностных выборок занижает долю людей с высоким доходом, ведущих активный образ жизни. Происходит это в силу того, что таких людей гораздо сложней застать в каком-либо определенном месте (например, дома).
- Проблема респондентов, отказывающихся отвечать на вопросы анкеты (доля «отказников» в Москве, для разных опросов, колеблется от 50% до 80%)
В некоторых случаях, когда известны истинные распределения, систематическую ошибку можно нивелировать введением квот или перевзвешиванием данных, но в большинстве реальных исследований даже оценить ее бывает достаточно проблематично.
Типы выборок
Выборки делятся на два типа:
1. Вероятностные выборки
1.1 Случайная выборка (простой случайный отбор)
Такая выборка предполагает однородность генеральной совокупности, одинаковую вероятность доступности всех элементов, наличие полного списка всех элементов. При отборе элементов, как правило, используется таблица случайных чисел.
1.2 Механическая (систематическая) выборка
Разновидность случайной выборки, упорядоченная по какому-либо признаку (алфавитный порядок, номер телефона, дата рождения и т.д.). Первый элемент отбирается случайно, затем, с шагом ‘n’ отбирается каждый ‘k’-ый элемент. Размер генеральной совокупности, при этом – N=n*k
1.3 Стратифицированная (районированная)
Применяется в случае неоднородности генеральной совокупности. Генеральная совокупность разбивается на группы (страты). В каждой страте отбор осуществляется случайным или механическим образом.
1.4 Серийная (гнездовая или кластерная) выборка
При серийной выборке единицами отбора выступают не сами объекты, а группы (кластеры или гнёзда). Группы отбираются случайным образом. Объекты внутри групп обследуются сплошняком.
2.Невероятностные выборки
Отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям – доступности, типичности, равного представительства и т.д..
2.1. Квотная выборка
Изначально выделяется некоторое количество групп объектов (например, мужчины в возрасте 20-30 лет, 31-45 лет и 46-60 лет; лица с доходом до 30 тысяч рублей, с доходом от 30 до 60 тысяч рублей и с доходом свыше 60 тысяч рублей) Для каждой группы задается количество объектов, которые должны быть обследованы. Количество объектов, которые должны попасть в каждую из групп, задается, чаще всего, либо пропорционально заранее известной доле группы в генеральной совокупности, либо одинаковым для каждой группы. Внутри групп объекты отбираются произвольно. Квотные выборки используются в маркетинговых исследованиях достаточно часто.
2.2. Метод снежного кома
Выборка строится следующим образом. У каждого респондента, начиная с первого, просятся контакты его друзей, коллег, знакомых, которые подходили бы под условия отбора и могли бы принять участие в исследовании. Таким образом, за исключением первого шага, выборка формируется с участием самих объектов исследования. Метод часто применяется, когда необходимо найти и опросить труднодоступные группы респондентов (например, респондентов, имеющих высокий доход, респондентов, принадлежащих к одной профессиональной группе, респондентов, имеющих какие-либо схожие хобби/увлечения и т.д.)
2.3 Стихийная выборка
Опрашиваются наиболее доступные респонденты. Типичные примеры стихийных выборок – опросы в газетах/журналах, анкеты, отданные респондентам на самозаполнение, большинство интернет-опросов. Размер и состав стихийных выборок заранее не известен, и определяется только одним параметром – активностью респондентов.
2.4 Выборка типичных случаев
Отбираются единицы генеральной совокупности, обладающие средним (типичным) значением признака. При этом возникает проблема выбора признака и определения его типичного значения.
Курс лекций по теории статистики
Калькулятор расчета ошибки и размера выборки (для простой случайной выборки)
Пояснения к полям:
Доверительная вероятность
Вероятность того, что доверительный интервал накроет неизвестное истинное значение параметра, оцениваемого по выборочным данным. В практике исследований чаще всего используют 95%-ую доверительную вероятность
Ошибка выборки (доверительный интервал)
Интервал, вычисленный по выборочным данным, который с заданной вероятностью (доверительной) накрывает неизвестное истинное значение оцениваемого параметра распределения.
Доля признака
Ожидаемая доля признака, для которого рассчитывается ошибка. В случае, если данные о доле признака отсутствуют, необходимо использовать значение равное 50, при котором достигается максимальная ошибка.
Калькулятор расчета статистической значимости различий
Калькулятор позволяет проверить есть ли статистически значимая разница между долями признака, полученными из независимых выборок.
Например, если до начала рекламной кампании марку знали 55% респондентов, а по окончании – 60% — есть ли между этими долями статистически значимая разница, или же эта разница укладывается в ошибку выборки?
Примечание. Эта процедура может законно использоваться, только если обе выборки удовлетворяют следующему условию: произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, должны быть не меньше 5.
Оставить свои комментарии по затронутой теме Вы можете на наших страницах в Facebook и Вконтакте.
Источник
Выборочное наблюдение в статистике
11.2. Оценка результатов выборочного наблюдения
11.2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ( ).
).
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
 — при оценивании среднего значения признака;
— при оценивании среднего значения признака;
 — если признак альтернативный, и оценивается доля.
— если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
 — для среднего значения признака;
— для среднего значения признака;
 — для доли.
— для доли.
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.
Предельная ошибка выборки ( ) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
 .
.
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
| Значение доверительной вероятности P | 0,683 | 0,954 | 0,997 |
|---|---|---|---|
| Значение коэффициента доверия t | 1,0 | 2,0 | 3,0 |
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:

Итак, определение границ генеральной средней и доли состоит из следующих этапов:
- нахождение в выборке среднего значения признака (или доли);
- определение
 в соответствии с выбранной схемой отбора и вида выборки;
в соответствии с выбранной схемой отбора и вида выборки; - задание доверительной вероятности Р и определение коэффициента доверия t по соответствующей таблице;
- вычисление предельной ошибки выборки ;
- построение доверительного интервала для средней (или доли).
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| где Пример 11.2. Для изучения уровня фондоотдачи было проведено выборочное обследование 90 предприятий из 225 методом случайной повторной выборки, в результате которого получены данные, представленные в таблице.
В рассматриваемом примере имеем 40%-ную выборку (90 : 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
Выборочная дисперсия изучаемого признака
Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
Таким образом, в 954 случаях из 1000 среднее значение фондоотдачи будет не выше 1,88 руб. и не ниже 1,74 руб. Выше была использована повторная схема случайного отбора. Посмотрим, изменятся ли результаты обследования, если предположить, что отбор осуществлялся по схеме бесповторного отбора. В этом случае расчет средней ошибки проводится по формуле
Тогда при вероятности равной 0,954 величина предельной ошибки выборки составит:
Доверительные границы для среднего значения признака при бесповторном случайном отборе будут иметь следующие значения:
Сравнив результаты двух схем отбора, можно сделать вывод о том, что применение бесповторной случайной выборки дает более точные результаты по сравнению с применением повторного отбора при одной и той же доверительной вероятности. При этом, чем больше объем выборки, тем существеннее сужаются границы значений средней при переходе от одной схемы отбора к другой. По данным примера определим, в каких границах находится доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., в генеральной совокупности: Количество предприятий в выборке с уровнем фондоотдачи, не превышающим значения 2,0 руб., составляет 60 единиц. Тогда m = 60, n = 90, w = m/n = 60 : 90 = 0,667;
Если предположить, что была использована бесповторная схема отбора, то средняя ошибка выборки с учетом поправки на конечность совокупности составит При значении вероятности Р = 0,997 по таблице нормального распределения получаем значение для коэффициента доверия t = 3 (см. выдержку из нее, приведенную в Приложении 1):
Таким образом, с вероятностью 0,997 можно утверждать, что в генеральной совокупности доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., не меньше, чем 54,7%, и не больше 78,7%.
Объем извлекаемых из каждой типической группы единиц зависит от принятого способа отбора; их общее количество образует необходимый объем выборки Существуют следующие два способа организации отбора внутри типической группы: пропорциональной объему типических групп и пропорциональной степени колеблемости значений признака у единиц наблюдения в группах. Рассмотрим первый из них, как наиболее часто используемый. Отбор, пропорциональный объему типических групп, предполагает, что в каждой из них будет отобрано следующее число единиц совокупности: где ni — количество извлекаемых единиц для выборки из i-й типической группы; n — общий объем выборки; Ni — количество единиц генеральной совокупности, составивших i-ю типическую группу; N — общее количество единиц генеральной совокупности. Отбор единиц внутри групп происходит в виде случайной или механической выборки. Формулы для оценивания средней ошибки выборки для среднего и доли представлены в табл. 11.6.
Здесь Пример 11.3. В одном из московских вузов проведено выборочное обследование студентов с целью определения показателя средней посещаемости вузовской библиотеки одним студентом за семестр. Для этого была использована 5%-ная бесповторная типическая выборка, типические группы которой соответствуют номеру курса. При отборе, пропорциональном объему типических групп, получены следующие данные:
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
n = 2550/130*5 =128 (чел.); аналогично для других групп: Проведем необходимые расчеты.
С вероятностью 0,954 находим предельную ошибку выборки:
Таким образом, с вероятностью 0,954 можно утверждать, что один студент за семестр посещает вузовскую библиотеку в среднем от семи до девяти раз.
Среднюю ошибку малой выборки определяют по формуле
Предельная ошибка малой выборки:
Распределение значений выборочных средних всегда имеет нормальный закон распределения (или приближается к нему) при п > 100, независимо от характера распределения генеральной совокупности. Однако в случае малых выборок действует иной закон распределения — распределение Стьюдента. В этом случае коэффициент доверия находится по таблице t-распределения Стьюдента в зависимости от величины доверительной вероятности Р и объема выборки п. В Приложении 1 приводится фрагмент таблицы t-распределения Стьюдента, представленной в виде зависимости доверительной вероятности от объема выборки и коэффициента доверия t. Пример 11.4. Предположим, что выборочное обследование восьми студентов академии показало, что на подготовку к контрольной работе по статистике они затратили следующее количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4; 6,6. Оценим выборочные средние затраты времени и построим доверительный интервал для среднего значения признака в генеральной совокупности, приняв доверительную вероятность равной 0,95.
То есть с вероятностью 0,95 можно утверждать, что затраты времени студента на подготовку к контрольной работе находятся в пределах от 6,9 до 8,5 ч. 11.2.2. Определение численности выборочной совокупностиПеред непосредственным проведением выборочного наблюдения всегда решается вопрос, сколько единиц исследуемой совокупности необходимо отобрать для обследования. Формулы для определения численности выборки выводят из формул предельных ошибок выборки в соответствии со следующими исходными положениями (табл. 11.7):
Кроме того, следует заранее определиться со значением доверительной вероятности, устраивающей потребителя информации, и с размером допустимой предельной ошибки выборки.
Примечание: при использовании приведенных в таблице формул рекомендуется получаемую численность выборки округлять в большую сторону для обеспечения некоторого запаса в точности. Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05. При использовании повторного случайного отбора следует проверить
При бесповторном случайном отборе потребуется проверить
Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов. Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.
Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек. Источник | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 — дисперсия признака в выборочной совокупности.
— дисперсия признака в выборочной совокупности.






 ;
;


 ) при использовании типического отбора, пропорционального объему типических групп
) при использовании типического отбора, пропорционального объему типических групп 





















