
- Обработка недостающих значений в машинном обучении: часть 2
- Среднее, Медиана в сочетании с групповым
- Линейная регрессия
- k-Neareast Neighbor (kNN) Импутация
- Множественное вменение с использованием MICE (Множественное вменение по цепочечным уравнениям)
- Вывод
- Что делать, если в датасете пропущены данные? — 6 способов импутации данных с примерами
- Авторизуйтесь
- Что делать, если в датасете пропущены данные? — 6 способов импутации данных с примерами
- Способ первый: не делать ничего
- Способ второй: импутация данных средним/медианой
- Способ третий: импутация данных самым частым значением или константой
- Способ четвёртый: импутация данных с помощью k-NN
- Способ пятый: импутация данных с помощью MICE
- Способ шестой: импутация данных с помощью глубокого обучения
- Другие методы импутации данных
- Стохастическая регрессия
- Экстраполяция и интерполяция
- Hot-deck
Обработка недостающих значений в машинном обучении: часть 2
Дата публикации Aug 1, 2018
Обработка пропущенных значений — один из худших ночных кошмаров, о которых мечтает аналитик данных. Особенно, если количество пропущенных значений в данных достаточно велико (как правило, выше 5%). В этом случае значения не могут быть отброшены, и мудрый ученый должен вместо этого «вменять» недостающие значения. В моей предыдущей историиОбработка недостающих значений в машинном обучении: часть 1Я представил основные методы обработки пропущенных значений в наборе данных. Цель сегодняшней статьи — представить некоторые более продвинутые методы, где недостающие значения заполняются путем изучения корреляций.

Во-первых, важно понимать, что не существует хорошего способа справиться с отсутствующими данными. Существуют различные решения для вменения данных, которые, однако, зависят от вида проблемы — анализа временных рядов, ML, регрессии и т. Д., И трудно найти общее решение.
Методы прогнозирования должны использоваться только в том случае, если пропущенные значения не наблюдаются полностью случайным образом, и переменные, выбранные для вменения таких пропущенных значений, имеют с ним определенную связь, иначе это может привести к неточным оценкам.
В общем, различные алгоритмы машинного обучения могут использоваться для определения пропущенных значений. Это работает, превращая отсутствующие объекты в сами метки, и теперь использует столбцы без пропущенных значений для прогнозирования столбцов с пропущенными значениями.
Среднее, Медиана в сочетании с групповым
В этом случае мы вменяем пропущенные значения, не рассматривая глобальное среднее / медианное значение наблюдений, а исследуя некоторую зависимость с другими переменными. Команды, примененные длятитановыйнабор данных.
Линейная регрессия
Для начала несколько предикторов переменной с отсутствующими значениями (в нашем случае функция «Возраст») идентифицируются с использованием матрицы корреляции. Лучшие предикторы выбираются и используются в качестве независимых переменных в уравнении регрессии. Переменная с отсутствующими данными используется в качестве целевой переменной.

Мы видим, что наша целевая переменная «Возраст» связана с функциями «Pclass», «SibSp», «Parch», «Fare», и они не содержат пропущенных значений.
Таким образом, мы собираемся подобрать линейную модель и постараемся предсказать недостающие значения функции «Возраст». Мы использовали модель линейной регрессии, чтобы заменить нули в функции «Возраст». В общем, можно экспериментировать с различными алгоритмами и проверять, что дает лучшую точность, а не придерживаться одного алгоритма.
Оценка недостающих значений с использованием взвешенной модели наименьших квадратов или обобщенной модели наименьших квадратов приводит к лучшим результатам (Лассо и Ридж).
Ограничения модели, как правило, перевешивают ее преимущества. Они приводят к недооценке стандартных ошибок и, таким образом, к переоценке тестовой статистики. Основная причина в том, что замененные значения полностью определяются моделью, применяемой к другим переменным, и они имеют тенденцию совмещаться «слишком хорошо», другими словами, они не содержат ошибок. Кроме того, следует также предположить, что существует линейная зависимость между переменными, используемыми в уравнении регрессии, когда их может не быть.
k-Neareast Neighbor (kNN) Импутация
Хотя XGBoost и Random Forest также могут быть использованы для вменения данных, мы будем обсуждать KNN, поскольку он широко используется. Для вычисления ближайшего соседа пропущенные значения основаны на алгоритме kNN. В этом методе k соседей выбираются на основе некоторой меры расстояния, и их среднее значение используется в качестве оценки вменения.
Метод требует выбора количества ближайших соседей и метрики расстояния. KNN может прогнозировать как дискретные (наиболее часто встречающиеся значения среди k ближайших соседей), так и непрерывные атрибуты (средние значения среди k ближайших соседей). Метрика расстояния варьируется в зависимости от типа данных:
- Непрерывные данные:Обычно используемые метрики расстояния для непрерывных данных — евклидовы, манхэттенские и косинусные.
- Категориальные данные:В этом случае обычно используется расстояние Хэмминга. Он принимает все категориальные атрибуты и для каждого считается один, если значение не совпадает между двумя точками. Расстояние Хемминга тогда равно количеству атрибутов, для которых значение было другим.
Одна из наиболее привлекательных особенностей KNN заключается в том, что он прост для понимания и легок в реализации. Основным недостатком использования вменения kNN является то, что он занимает много времени при анализе больших наборов данных. Кроме того, точность KNN может быть серьезно ухудшена с помощью данных большого размера, потому что существует небольшая разница между ближайшим и самым дальним соседом. Наконец, число соседей (k) должно быть тщательно выбрано при использовании вменения kNN.
Множественное вменение с использованием MICE (Множественное вменение по цепочечным уравнениям)
Бесспорно один из самых передовых методологии для выполнения отсутствующего вменения данных является Многофакторным вменением по прикованным уравнениям (MICE)
Создание нескольких вменений, в отличие от отдельных вменений для «полных» наборов данных, объясняет статистическую неопределенность вменений. В целом, ограничение для одного вменения состоит в том, что, поскольку эти методы находят максимально вероятные значения, они не генерируют записи, которые точно отражают распределение лежащих в основе данных. Кроме того, подход цепных уравнений очень гибок и может обрабатывать переменные различных типов (например, непрерывные или двоичные).
Обратите внимание, что все методы, обсуждавшиеся до сих пор, представляют собой то, что можно назвать «одиночным вменением»: каждое значение в наборе данных заполняется ровно один раз.
Алгоритм MICE работает: при запуске нескольких моделей регрессии и каждое отсутствующее значение моделируется условно в зависимости от наблюдаемых (не пропущенных) значений.

Например, давайте рассмотрим крайний случай, когда мы приписываем значения miisng среднему значению. В действительности, мы ожидаем увидеть некоторую изменчивость: экстремальные значения, выбросы и записи, которые не полностью соответствуют «шаблону» данных. Все наборы данных содержат шум в некоторой степени, и замена среднего значения не пытается представить его в результате. Это приводит к смещению в любых моделях, которые подвержены тренду (наличию среднего значения в наборе данных), которого нет в базовых данных. Это в конечном итоге приведет к снижению точности как на этапе обучения, так и на этапе испытаний Алгоритм состоит из трех этапов.
- вменение в вину: Вычислить недостающие записи в неполных наборах данныхмраз (м= 3 на рисунке). Обратите внимание, что вмененные значения взяты из распределения. Моделирование случайных ничьих не включает неопределенности в параметрах модели. Лучше всего использовать симуляцию Маркова Цепи Монте-Карло (MCMC). Этот шаг приводит к m полных наборов данных.
- Анализ: Проанализировать каждый измзавершенные наборы данных.
- объединение: Интегрироватьмрезультаты анализа в окончательный результат

Вот рецепт для вменения с использованием fancyimpute.MICE :
По умолчаниюfancyimputeиспользует собственную реализацию регрессии Байесовского хребта.
Это, по сути, байесовская реализация sklearn.linear_model.Ridge , lambda_reg эквивалентно alpha параметр. Таким образом, слабо наказан Ridge Регрессор — это авторский (разумный) пакет по умолчанию.
На сегодняшний день это наиболее предпочтительный метод вменения по следующим причинам:
— Легко использовать
— Никаких смещений (если модель вменения верна)
Вывод
Главная идея заключается в том, что усовершенствованные методы вменения предназначены для решения проблемы пропущенных данных, используют взаимосвязи между переменными и вменяют множество значений, а не одно значение. Подходящее решение, особенно для больших массивов данных, зависит от вычислительного ресурса, а также от допуска к ошибкам при аппроксимации пропущенных значений.
Среди всех способов, обсуждаемых выше, широко используется множественное вменение и KNN, и, как правило, предпочтительнее множественное вменение, являющееся более простым.
П.С .: Следите за моей следующей статьей, в которой обобщены стратегии отсутствующих ценностей.
Источник
Что делать, если в датасете пропущены данные? — 6 способов импутации данных с примерами
Авторизуйтесь
Что делать, если в датасете пропущены данные? — 6 способов импутации данных с примерами
Автор перевода Алексей Морозов
Реальные наборы данных могут быть неполными. Не в том смысле, что в анализ не вошли какие-то важные точки или неудачно были выбраны параметры, а просто отсутствуют некоторые данные, которые в принципе должны были там быть.
Это может случиться из-за технических проблем, или если датасет собран из нескольких источников с разными наборами параметров; важно то, что в таблице присутствуют пустые ячейки. Вместо значений в них ставится какая-нибудь заглушка — NaN, просто пустая ячейка или ещё что-нибудь в этом роде. Если их много — тренировка на таких данных сильно ухудшит качество модели, а то и окажется вовсе невозможной. Многие алгоритмы того же scikit-learn не только требуют массив чисел (а не NaN или «missing»), но и ожидают, что этот массив будет состоять из валидных данных.
Что делать? Можно, конечно, просто выкинуть все неполные наблюдения, но так можно потерять ценную информацию. Лучше попытаться восстановить недостающие значения на основании остальных данных в наборе, или хотя бы вставить в пустые ячейки что-нибудь более-менее осмысленное. Этот процесс называется импутацией данных.
3–5 декабря, Онлайн, Беcплатно
В этой статье будет описано 6 популярных способов импутации для наборов однородных точек. Для временных серий они непригодны, там всё делается совсем иначе.
Способ первый: не делать ничего
Тут всё просто: отдаём алгоритму датасет в исходном виде и надеемся, что он с ним как-нибудь разберётся. Некоторые алгоритмы умеют принимать во внимание и даже восстанавливать пропущенные значения в данных. Например, XGBoost делает это за счёт уменьшения функции потерь при обучении. У алгоритма может быть параметр, позволяющий их проигнорировать (пример — LightGBM с параметром use_missing=False ). Но таких опций может и не быть: линейная регрессия в scikit-learn просто объявит массив некорректным и выбросит исключение. Так что в её случае (как и в случае многих других алгоритмов) готовить данные к анализу всё-таки придётся пользователю.
Плюсы:
- Не надо думать об алгоритмах импутации — выставил соответствующие параметры и всё работает.
Минусы
- Нужно понимать, как именно алгоритм обойдётся с недостающими данными. В противном случае есть риск получить какие-нибудь артефакты и даже не узнать, какие именно.
Способ второй: импутация данных средним/медианой
Тоже не особенно сложно: считаем среднее или медиану имеющихся значений для каждого столбца в таблице и вставляем то, что получилось, в пустые ячейки. Естественно, этот метод работает только с численными данными.

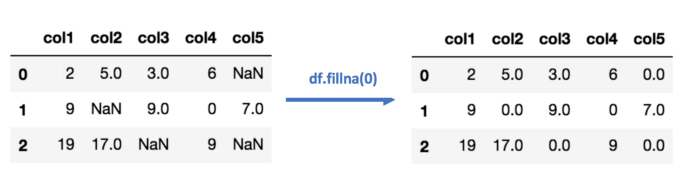
В коде это выглядит примерно так:
Плюсы:
- Просто и быстро.
- Хорошо работает на небольших наборах численных данных.
Минусы:
- Значения вычисляются независимо для каждого столбца, так что корреляции между параметрами не учитываются.
- Не работает с качественными переменными.
- Метод не особенно точный.
- Никак не оценивается погрешность импутации.
Способ третий: импутация данных самым частым значением или константой
Импутация самым часто встречающимся значением — ещё одна простая стратегия для компенсации пропущенных значений, не учитывающая корреляций между параметрами. Плюсы и минусы те же, что и в предыдущем пункте, но этот метод предназначен для качественных переменных.
В случае импутации нулём или константой (как можно догадаться из названия) все пропущенные значения в данных заменяются определённым значением.
Способ четвёртый: импутация данных с помощью k-NN
k-Nearest Neighbour (k ближайших соседей) — простой алгоритм классификации, который можно модифицировать для импутации недостающих значений. Он использует сходство точек, чтобы предсказать недостающие значения на основании k ближайших точек, у которых это значение есть. Иными словами, выбирается k точек, которые больше всего похожи на рассматриваемую, и уже на их основании выбирается значение для пустой ячейки. Это можно сделать с помощью библиотеки Impyute:
Алгоритм сперва проводит импутацию простым средним, потом на основании получившегося набора данных строит дерево и использует его для поиска ближайших соседей. Взвешенное среднее их значений и вставляется в исходный набор данных вместо недостающего.
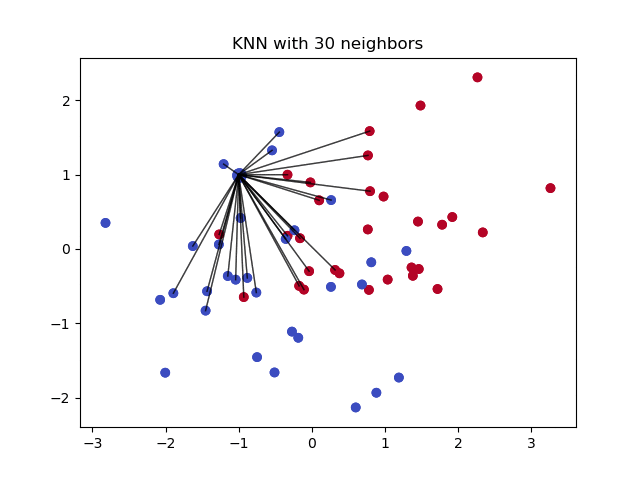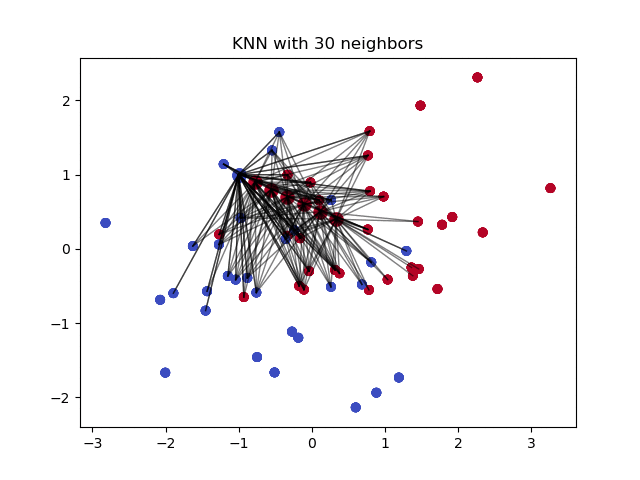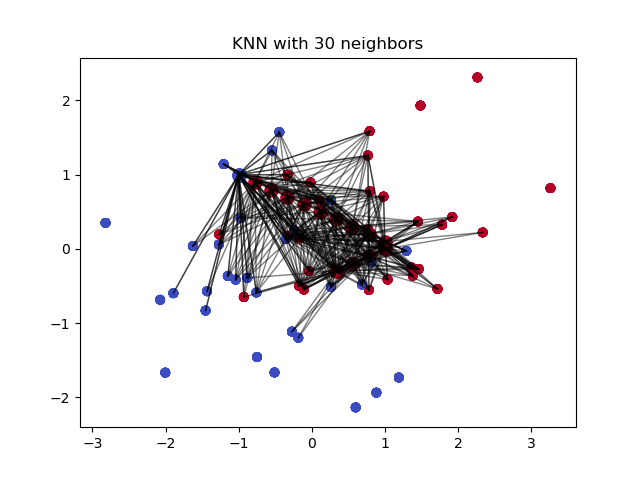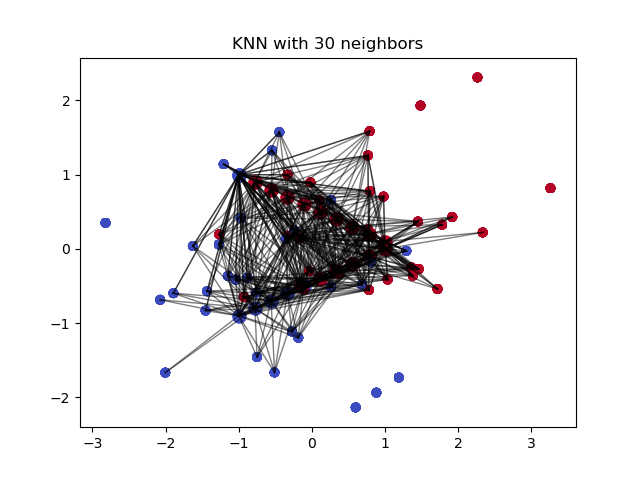
Плюсы:
- На некоторых датасетах может быть точнее среднего/медианы или константы.
- Учитывает корреляцию между параметрами.
Минусы:
- Вычислительно дороже, так как требует держать весь набор данных в памяти.
- Важно понимать, какая метрика дистанции используется для поиска соседей. Имплементация в impyute поддерживает только манхэттенскую и евклидову дистанцию, так что анализ соотношений (скажем, количества входов на сайты людей разных возрастов) может потребовать предварительной нормализации.
- Чувствителен к выбросам в данных (в отличие от SVM).
Способ пятый: импутация данных с помощью MICE
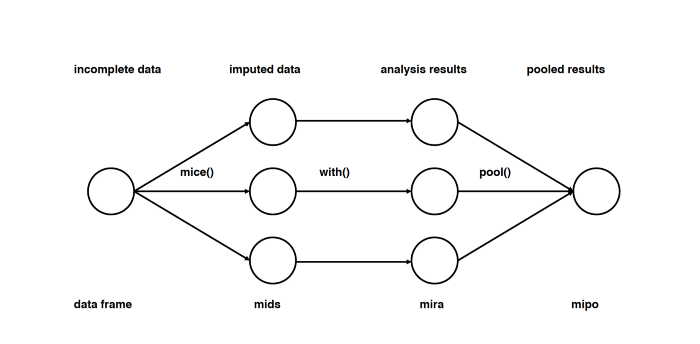
Этот подход основан на том, что импутация каждого значения проводится не один раз, а много. Множественные импутации, в отличие от однократных, позволяют понять, насколько надёжно или ненадёжно предложенное значение. Кроме того, MICE позволяет работать с переменными разных типов (например двоичными и количественными), а также со сложными штуками вроде предельных значений и паттернов артефактов в исходных данных. Подробный разбор математики есть в оригинальной статье.
Прим. пер. Судя по статье, метод MICE подразумевает не просто множественные импутации, а многократное повторение дальнейшего анализа на разных импутированных наборах данных и интеграцию получившихся результатов.
Способ шестой: импутация данных с помощью глубокого обучения
Показано, что глубокое обучение хорошо работает с дискретными и другими не-численными значениями. Библиотека datawig позволяет восстанавливать недостающие значения за счёт тренировки нейросети на тех точках, для которых есть все параметры. Поддерживается тренировка на CPU и GPU.
Плюсы:
- Точнее других методов.
- Может работать с качественными параметрами.
- Поддерживает CPU и GPU.
Минусы:
- Восстанавливает только один столбец.
- На больших наборах данных может быть вычислительно дорого.
- Нужно заранее решить, какие столбцы будут использоваться для предсказания недостающего значения.
Другие методы импутации данных
Стохастическая регрессия
Примерно похоже на регрессионную импутацию, в которой значения восстанавливаются регрессией от имеющихся значений для той же точки, но добавляет случайный шум.
Экстраполяция и интерполяция
Пытается восстановить значения на основании ограниченного набора известных точек.
Hot-deck
Значение берётся из другой точки, похожей по имеющимся параметрам на восстанавливаемую. Грубо говоря, это похоже на k-NN, но используется только один «сосед».
Как мы видим, универсального метода импутации не существует. Одни стратегии работают лучше на одних наборах данных или типах недостающих переменных, другие на других. Если не считать очевидных правил насчёт типов данных (например, у качественных переменных просто не может быть среднего), то можно только посоветовать экспериментировать и смотреть, какой метод сработает лучше на данном конкретном датасете.
Источник



