
Оценка статистической надежности результатов линейного регрессионного моделирования




![]()
![]()
Оценка статистической надежности уравнения регрессии в целом будем производить с помощью F-критерия Фишера. При этом примем нулевую гипотезу H0, что коэффициент регрессии b равен нулю. В таком случае фактор x не оказывает влияние на результат y, то есть длина железной дороги не оказывает влияния на пассажирооборот. Альтернативная гипотеза H1 будет состоять в статистической надежности линейного регрессионного моделирования. Для установления истинной значимости линейной модели необходимо выполнить сравнение факторного Fфакт и критического (табличного) Fтабл значений F-критерия Фишера. Факторный F-критерий Фишера вычисляется по формуле:
где Sфакт 2 – фактическая выборочная дисперсия, вычисленная на одну степень свободы по соотношению:
Sфакт 2 = ((ŷ x1 — 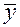 ) 2 + (ŷ x2 — ) 2 + . + (ŷ x16 — ) 2 )/ 1;
) 2 + (ŷ x2 — ) 2 + . + (ŷ x16 — ) 2 )/ 1;
Sост 2 — остаточная выборочная дисперсия, вычисленная на одну степень свободы по соотношению:
Если нулевая гипотеза справедлива, то факторная и остаточная выборочные дисперсии не отличаются друг от друга. Для опровержения нулевой гипотезы H0 необходимо, чтобы факторная дисперсия превышала остаточную дисперсию в несколько раз. Табличное Fтабл значений F-критерия Фишера – это максимальное величина критерия (отношения дисперсий) под влиянием случайных факторов при данных степенях свободы и уровне значимости α, который примем равным 0,05.
Если Fтабл Fфакт, то нулевая гипотеза не отклоняется и признается статическая не значимость и ненадежность уравнения регрессии.
По таблице значений F-критерия Фишера при уровне значимости α = 0,05 и степенях свободы к1 = 1, к2 = 14 получаем Fтабл = 4,63. Выполнив расчет получим Fфакт = 24,93
Полученные значения F-критерия Фишера указывают, что Fтабл
Источник
Проверка надежности регрессионной модели.
Существуют две меры соответствия линии наименьших квадратов имеющимся данным. Стандартная ошибка оценки (или предсказания), которую обозначают 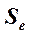 , приблизительно указывает величину ошибок прогнозирования (остатков) для имеющихся данных в тех же единицах, в которых измерена и переменная У. Соответствующие формулы приведены ниже.
, приблизительно указывает величину ошибок прогнозирования (остатков) для имеющихся данных в тех же единицах, в которых измерена и переменная У. Соответствующие формулы приведены ниже.
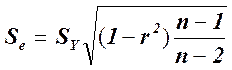 (для вычисления)
(для вычисления)
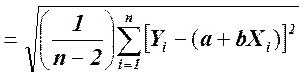 (для интерпретации).
(для интерпретации).
Значение 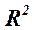 , часто называемое коэффициентом детерминации, говорит о том, какой процент вариации У объясняется поведением X.
, часто называемое коэффициентом детерминации, говорит о том, какой процент вариации У объясняется поведением X.
Доверительные интервалы и проверка гипотез для коэффициента регрессии связаны с определенными предположениями относительно анализируемой совокупности данных, которые должны гарантировать, что она состоит из независимых наблюдений, характеризующихся линейной взаимосвязью с равной вариацией и приблизительно нормально распределенной случайностью. Во-первых, эти данные должны представлять собой произвольную выборку из интересующей нас генеральной совокупности. Во-вторых, линейная модель указывает, что наблюдаемое значение У определяется взаимосвязью в генеральной совокупности плюс случайная ошибка, имеющая нормальное распределение. Существуют параметры генеральной совокупности, соответствующие наклону и сдвигу линии наименьших квадратов, построенной на данных выборки:
= (Взаимосвязь в генеральной совокупности) + случайность.
где ε имеет нормальное распределение со средним значением, равным 0, и постоянным стандартным отклонением σ.
Статистические выводы (использование доверительных интервалов и проверки статистических гипотез) относительно коэффициентов линии наименьших квадратов основываются, как обычно, на их стандартных ошибках и значениях из t-таблицы для п — 2 степеней свободы. Стандартная ошибка коэффициента наклона, 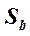 , указывает приблизительную величину отклонения оценки наклона, b (коэффициент регрессии, вычисленный на основе данных выборки), от наклона в генеральной совокупности, β, вызванного случайным характером выборки. Стандартная ошибка сдвига,
, указывает приблизительную величину отклонения оценки наклона, b (коэффициент регрессии, вычисленный на основе данных выборки), от наклона в генеральной совокупности, β, вызванного случайным характером выборки. Стандартная ошибка сдвига, 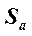 , указывает приблизительно, насколько далеко оценка сдвига а отстоит от истинного сдвига α в генеральной совокупности. Соответствующие формулы выглядят следующим образом:
, указывает приблизительно, насколько далеко оценка сдвига а отстоит от истинного сдвига α в генеральной совокупности. Соответствующие формулы выглядят следующим образом:
стандартная ошибка коэффициента регрессии b:
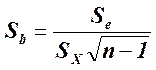
стандартная ошибка сдвига:
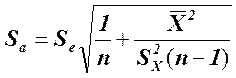 .
.
Доверительный интервал для наклона в генеральной совокупности, β:
от 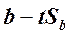 до
до 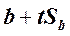 .
.
Доверительный интервал для сдвига в генеральной совокупности, α:
от 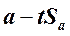 до
до 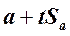 .
.
Один из способов проверки, является ли обнаруженная взаимосвязь между X и У реальной или это просто случайное совпадение, заключается в сравнении β с заданным значением β0 = 0. О значимой связи можно говорить в том случае, если 0 не попадает в доверительный интервал, базирующийся на b и Sb, или если абсолютное значение t = b/Sb превосходит соответствующее t-значение в t—таблице.
Источник
Критерии оценки качества регрессионной модели, или какая модель хорошая, а какая лучше
В данной статье мы поговорим о том, как понять, качественную ли модель мы построили. Ведь именно качественная модель даст нам качественные прогнозы.
Инструмент «Моделирование и прогнозирование» Prognoz Platform обладает обширным списком моделей для построения и анализа. Каждая модель имеет свою специфику и применяется при различных предпосылках.
Объект «Модель» позволяет построить следующие регрессионные модели:
Начнём с модели линейной регрессии. Многое из сказанного будет распространяться и на другие виды.
Модель линейной регрессии (оценка МНК)
Под моделью линейной регрессии будем понимать модель вида:
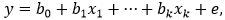
где y – объясняемый ряд, x1, …, xk – объясняющие ряды, e – вектор ошибок модели, b0, b1, …, bk – коэффициенты модели.
Итак, куда смотреть?
Для каждого коэффициента на панели «Идентифицированное уравнение» вычисляется ряд статистик:
- стандартная ошибка,
- t-статистика,
- вероятность значимости коэффициента.
Последняя является наиболее универсальной и показывает, с какой вероятностью удаление из модели фактора, соответствующего данному коэффициенту, не окажется значимым.
Открываем панель и смотрим на последний столбец, ведь он – именно тот, кто сразу же скажет нам о значимости коэффициентов.
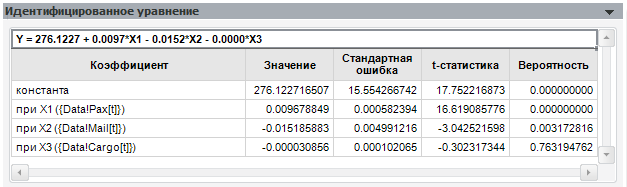
Факторов с большой вероятностью незначимости в модели быть не должно.
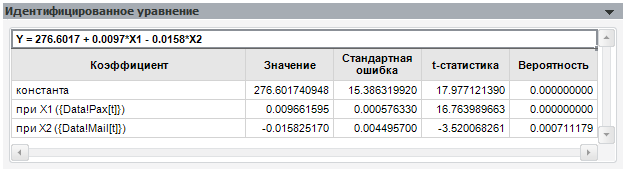
Как вы видите, при исключении последнего фактора коэффициенты модели практически не изменились.
Возможные проблемы: Что делать, если согласно вашей теоретической модели фактор с большой вероятностью незначимости обязательно должен быть? Существуют и другие способы определения значимости коэффициентов. Например, взгляните на матрицу корреляции факторов.
Панель «Корреляция факторов» содержит матрицу корреляции между всеми переменными модели, а также строит облако наблюдений для выделенной пары значений.
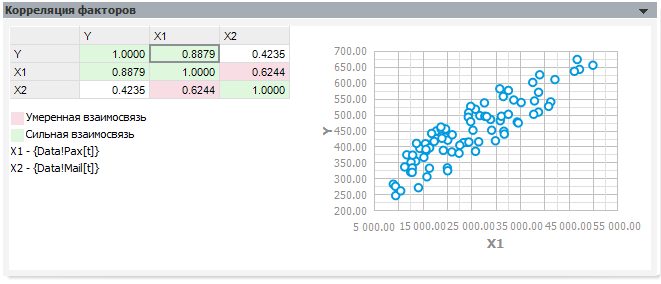
Коэффициент корреляции показывает силу линейной зависимости между двумя переменными. Он изменяется от -1 до 1. Близость к -1 говорит об отрицательной линейной зависимости, близость к 1 – о положительной.
Облако наблюдений позволяет визуально определить, похожа ли зависимость одной переменной от другой на линейную.
Если среди факторов встречаются сильно коррелирующие между собой, исключите один из них. При желании вместо модели обычной линейной регрессии вы можете построить модель с инструментальными переменными, включив в список инструментальных исключённые из-за корреляции факторы.
Матрица корреляции не имеет смысла для модели нелинейной регрессии, поскольку она показывает только силу линейной зависимости.
Помимо проверки каждого коэффициента модели важно знать, насколько она хороша в целом. Для этого вычисляют статистики, расположенные на панели «Статистические характеристики».
Коэффициент детерминации (R 2 ) – наиболее распространённая статистика для оценки качества модели. R 2 рассчитывается по следующей формуле:
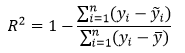
n – число наблюдений;
yi — значения объясняемой переменной;
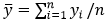 — среднее значение объясняемой переменной;
— среднее значение объясняемой переменной;
ỹi — модельные значения, построенные по оцененным параметрам.
R 2 принимает значение от 0 до 1 и показывает долю объяснённой дисперсии объясняемого ряда. Чем ближе R 2 к 1, тем лучше модель, тем меньше доля необъяснённого.
Возможные проблемы: Проблемы с использованием R 2 заключаются в том, что его значение не уменьшается при добавлении в уравнение факторов, сколь плохи бы они ни были.
Он гарантированно будет равен 1, если мы добавим в модель столько факторов, сколько у нас наблюдений. Поэтому сравнивать модели с разным количеством факторов, используя R 2 , не имеет смысла.
Для более адекватной оценки модели используется скорректированный коэффициент детерминации (Adj R 2 ). Как видно из названия, этот показатель представляет собой скорректированную версию R 2 , накладывая «штраф» за каждый добавленный фактор:
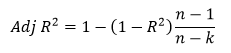
где k – число факторов, включенных в модель.
Коэффициент Adj R 2 также принимает значения от 0 до 1, но никогда не будет больше, чем значение R 2 .
Аналогом t-статистики коэффициента является статистика Фишера (F-статистика). Однако если t-статистика проверяет гипотезу о незначимости одного коэффициента, то F-статистика проверяет гипотезу о том, что все факторы (кроме константы) являются незначимыми. Значение F-статистики также сравнивают с критическим, и для него мы также можем получить вероятность незначимости. Стоит понимать, что данный тест проверяет гипотезу о том, что все факторы одновременно являются незначимыми. Поэтому при наличии незначимых факторов модель в целом может быть значима.
Возможные проблемы: Большинство статистик строится для случая, когда модель включает в себя константу. Однако в Prognoz Platform мы имеем возможность убрать константу из списка оцениваемых коэффициентов. Стоит понимать, что такие манипуляции приводят к тому, что некоторые характеристики могут принимать недопустимые значения. Так, R 2 и Adj R 2 при отсутствии константы могут принимать отрицательные значения. В таком случае их уже не получится интерпретировать как долю, принимающую значение от 0 до 1.
Для моделей без константы в Prognoz Platform рассчитываются нецентрированные коэффициенты детерминации (R 2 и Adj R 2 ). Модифицированная формула приводит их значения к диапазону от 0 до 1 даже в модели без константы.
Посмотрим значения описанных критериев для приведённой выше модели:
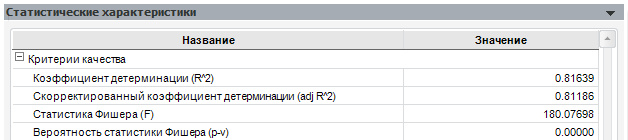
Как мы видим, коэффициент детерминации достаточно велик, однако есть ещё значительная доля необъяснённой дисперсии. Статистика Фишера говорит о том, что выбранная нами совокупность факторов является значимой.
Кроме критериев, позволяющих говорить о качестве модели самой по себе, существует ряд характеристик, позволяющих сравнивать модели друг с другом (при условии, что мы объясняем один и тот же ряд на одном и том же периоде).
Большинство моделей регрессии сводятся к задаче минимизации суммы квадратов остатков (sum of squared residuals, SSR). Таким образом, сравнивая модели по этому показателю, можно определить, какая из моделей лучше объяснила исследуемый ряд. Такой модели будет соответствовать наименьшее значение суммы квадратов остатков.
Возможные проблемы: Стоит заметить, что с ростом числа факторов данный показатель так же, как и R 2 , будет стремиться к граничному значению (у SSR, очевидно, граничное значение 0).
Некоторые модели сводятся к максимизации логарифма функции максимального правдоподобия (LogL). Для модели линейной регрессии эти задачи приводят к одинаковому решению. На основе LogL строятся информационные критерии, часто используемые для решения задачи выбора как регрессионных моделей, так и моделей сглаживания:
- информационный критерий Акаике (Akaike Information criterion, AIC)
- критерий Шварца (Schwarz Criterion, SC)
- критерий Ханнана-Куина (Hannan-Quinn Criterion, HQ)
Все критерии учитывают число наблюдений и число параметров модели и отличаются друг от друга видом «функции штрафа» за число параметров. Для информационных критериев действует правило: наилучшая модель имеет наименьшее значение критерия.
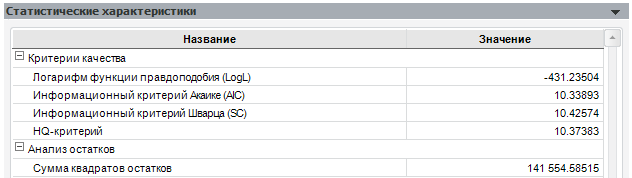
Сравним нашу модель с её первым вариантом (с «лишним» коэффициентом):
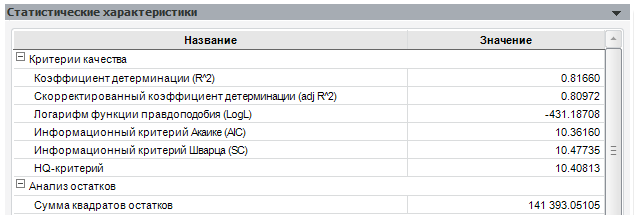
Как можно увидеть, данная модель хоть и дала меньшую сумму квадратов остатков, оказалась хуже по информационным критериям и по скорректированному коэффициенту детерминации.
Модель считается качественной, если остатки модели не коррелируют между собой. В противном случае имеет место постоянное однонаправленное воздействие на объясняемую переменную не учтённых в модели факторов. Это влияет на качество оценок модели, делая их неэффективными.
Для проверки остатков на автокорреляцию первого порядка (зависимость текущего значения от предыдущих) используется статистика Дарбина-Уотсона (DW). Её значение находится в промежутке от 0 до 4. В случае отсутствия автокорреляции DW близка к 2. Близость к 0 говорит о положительной автокорреляции, к 4 — об отрицательной.

Как оказалось, в нашей модели присутствует автокорреляция остатков. От автокорреляции можно избавиться, применив преобразование «Разность» к объясняемой переменной или воспользовавшись другим видом модели – моделью ARIMA или моделью ARMAX.
Возможные проблемы: Статистика Дарбина-Уотсона неприменима к моделям без константы, а также к моделям, которые в качестве факторов используют лагированные значения объясняемой переменной. В этих случаях статистика может показывать отсутствие автокорреляции при её наличии.
Модель линейной регрессии (метод инструментальных переменных)
Модель линейной регрессии с инструментальными переменными имеет вид:
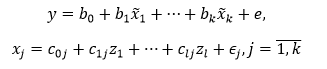
где y – объясняемый ряд, x1, …, xk – объясняющие ряды, x̃1, …, x̃k – смоделированные при помощи инструментальных переменных объясняющие ряды, z1, …, zl – инструментальные переменные, e, ∈j – вектора ошибок моделей, b0, b1, …, bk – коэффициенты модели, c0j, c1j, …, clj – коэффициенты моделей для объясняющих рядов.
Схема, по которой следует проверять качество модели, является схожей, только к критериям качества добавляется J-статистика – аналог F-статистики, учитывающий инструментальные переменные.
Модель бинарного выбора
Объясняемой переменной в модели бинарного выбора является величина, принимающая только два значения – 0 или 1.
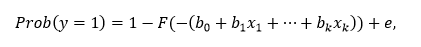
где y – объясняемый ряд, x1, …, xk – объясняющие ряды, e – вектор ошибок модели, b0, b1, …, bk – коэффициенты модели, F – неубывающая функция, возвращающая значения от 0 до 1.
Коэффициенты модели вычисляются методом, максимизирующим значение функции максимального правдоподобия. Для данной модели актуальными будут такие критерии качества, как:
- Коэффициент детерминации МакФаддена (McFadden R 2 ) – аналог обычного R 2 ;
- LR-статистика и её вероятность — аналог F-статистики;
- Сравнительные критерии: LogL, AIC, SC, HQ.
Под моделью линейной регрессии будем понимать модель вида:
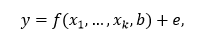
где y – объясняемый ряд, x1, …, xk – объясняющие ряды, e – вектор ошибок модели, b – вектор коэффициентов модели.
Коэффициенты модели вычисляются методом, минимизирующим значение суммы квадратов остатков. Для данной модели будут актуальны те же критерии, что и для линейной регрессии, кроме проверки матрицы корреляций. Отметим ещё, что F-статистика будет проверять, является ли значимой модель в целом по сравнению с моделью y = b0 + e, даже если в исходной модели у функции f (x1, …, xk,b) нет слагаемого, соответствующего константе.
Подведём итоги и представим перечень проверяемых характеристик в виде таблицы:
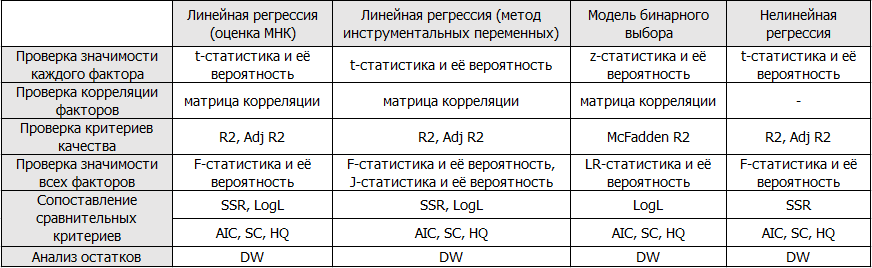
Надеюсь, данная статья была полезной для читателей!
Источник



