
Создание логической модели
Первым шагом при создании логической модели БД является построение диаграммы ERD (Entity Relationship Diagram). ERD-диаграммы состоят из трех частей: сущностей, атрибутов и взаимосвязей. Сущностями являются существительные, атрибуты — прилагательными или модификаторами, взаимосвязи — глаголами.
ERD-диаграмма позволяет рассмотреть систему целиком и выяснить требования, необходимые для ее разработки, касающиеся хранения информации.
ERD-диаграммы можно подразделить на отдельные куски, соответствующие отдельным задачам, решаемым проектируемой системой. Это позволяет рассматривать систему с точки зрения функциональных возможностей, делая процесс проектирования управляемым.
ERD-диаграммы
Как известно основным компонентом реляционных БД является таблица. Таблица используется для структуризации и хранения информации. В реляционных БД каждая ячейка таблицы содержит одно значение. Кроме того, внутри одной БД существуют взаимосвязи между таблицами, каждая из которых задает совместное пользование данными таблицы.
ERD-диаграмма графически представляет структуру данных проектируемой информационной системы. Сущности отображаются при помощи прямоугольников, содержащих имя. Имена принято выражать существительными в единственном числе, взаимосвязи — при помощи линий, соединяющих отдельные сущности. Взаимосвязь показывает, что данные одной сущности ссылаются или связаны с данными другой.
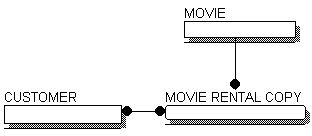
Рис. 6.1. Пример ERD-диаграммы,
Определение сущностей и атрибутов
Сущность — это субъект, место, вещь, событие или понятие, содержащие информацию. Точнее, сущность — это набор (объединение) объектов, называемых экземплярами. В приведенном на рис. 6.1 примере сущность CUSTOMER (клиент) представляет всех возможных клиентов. Каждый экземпляр сущности обладает набором характеристик. Так, каждый клиент может иметь имя, адрес, телефон и т. д. В логической модели все эти характеристики называются атрибутами сущности.
На рис. 6.2 показана ERD-диаграмма, включающая в себя атрибуты сущностей.
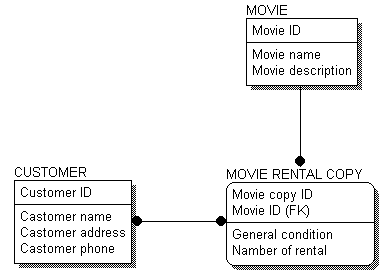
Рис. 6.2. ERD-диаграмма с атрибутами
Логические взаимосвязи
Логические взаимосвязи представляют собой связи между сущностями. Они определяются глаголами, показывающими, как одна сущность относится к другой.
Некоторые примеры взаимосвязей:
- команда включает много игроков,
- самолет перевозит много пассажиров,
- продавец продает много продуктов.
Во всех этих случаях взаимосвязи отражают взаимодействие между двумя сущностями, называемое «один-ко-многим». Это означает, что один экземпляр первой сущности взаимодействует с несколькими экземплярами другой сущности. Взаимосвязи отображаются линиями, соединяющими две сущности с точкой на одном конце и глаголом, располагаемым над линией.
Кроме взаимосвязи «один-ко-многим» существует еще один тип — это «многие-ко-многим». Этот тип связи описывает ситуацию, при которой экземпляры сущностей могут взаимодействовать с несколькими экземплярами других сущностей. Связь «многие-ко-многим» используют на первоначальных стадиях проектирования. Этот тип взаимосвязи отображается сплошной линией с точками на обоих концах.
Связь «многие-ко-многим» может не учитывать определенные ограничения системы, поэтому может быть заменена на «один-ко-многим» при последующем пересмотре проекта.
Проверка адекватности логической модели
Если взаимосвязи между сущностями были правильно установлены, то можно составить предложения, их описывающие. Например, по модели, показанной на рис. 6.3, можно составить следующие предложения:
Самолет перевозит пассажиров. Много пассажиров перевозятся одним самолетом.
Составление таких предложений позволяет проверить соответствие полученной модели требованиям и ограничениям создаваемой системы.
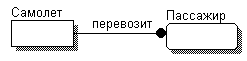
Рис. 6.3. Пример логической модели со взаимосвязью
Модель данных, основанная на ключах
Каждая сущность содержит горизонтальную линию, разделяющую атрибуты на две группы. Атрибуты, расположенные над линией, называются первичным ключом. Первичный ключ предназначен для уникальной идентификации экземпляра сущности.
Выбор первичного ключа
При создании сущности необходимо выделить группу атрибутов, которые потенциально могут стать первичным ключом (потенциальные ключи), затем произвести отбор атрибутов для включения в состав первичного ключа, следуя следующим рекомендациям:
Первичный ключ должен быть подобран таким образом, чтобы по значениям атрибутов, в него включенных, можно было точно идентифицировать экземпляр сущности. Никакой из атрибутов первичного ключа не должен иметь нулевое значение. Значения атрибутов первичного ключа не должны меняться. Если значение изменилось, значит, это уже другой экземпляр сущности.
При выборе первичного ключа можно внести в сущность дополнительный атрибут и сделать его ключом. Так, для определения первичного ключа часто используют уникальные номера, которые могут автоматически генерироваться системой при добавлении экземпляра сущности в БД. Применение уникальных номеров облегчает процесс индексации и поиска в БД.
Первичный ключ, выбранный при создании логической модели, может быть неудачным для осуществления эффективного доступа к БД и должен быть изменен при проектировании физической модели.
Потенциальный ключ, не ставший первичным, называется альтернативным ключом (Alternate Key). ERWin позволяет выделить атрибуты альтернативных ключей, и по умолчанию в дальнейшем при генерации схемы БД по этим атрибутам будет генерироваться уникальный индекс. При создании альтернативного ключа на диаграмме рядом с атрибутом появляются символы (АК).
Атрибуты, участвующие в неуникальных индексах, называются инверсионными входами (Inversion Entries). Инверсионные входы — это атрибут или группа атрибутов, которые не определяют экземпляр уникальным образом, но часто используются для обращения к экземплярам сущности. ERWin генерирует неуникальный индекс для каждого инверсионного входа.
При проведении связи между двумя сущностями в дочерней сущности автоматически образуются внешние ключи (foreign key). Связь образует ссылку на атрибуты первичного ключа в дочерней сущности, и эти атрибуты образуют внешний ключ в дочерней сущности. Атрибуты внешнего ключа обозначаются символами (FK) после своего имени.
Пример
Рассмотрим процесс построения логической модели на примере БД студентов системы «Служба занятости в рамках вуза». Первым этапом является определение сущностей и атрибутов. В БД будут храниться записи о студентах, следовательно, сущностью будет студент.
Таблица 6.1. Атрибуты сущности «Студент»
| Атрибут | Описание |
| Номер | Уникальный номер для идентификации пользователя |
| Ф.И.О. | Фамилия, имя и отчество пользователя |
| Пароль | Пароль для доступа в систему |
| Возраст | Возраст студента |
| Пол | Пол студента |
| Характеристика | Memo-поле с общей характеристикой пользователя |
| Адреса электронной почты | |
| Телефон | Номера телефонов студента (домашний, рабочий) |
| Опыт работы | Специальности и опыт работы студента по каждой из них |
| Специальность | Специальность, получаемая студентом при окончании учебного заведения |
| Специализация | Направление специальности, по которому обучается студент |
| Иностранный язык | Список иностранных языков и уровень владения ими |
| Тестирование | Список тестов и отметки о их прохождении |
| Экспертная оценка | Список предметов с экспертными оценками по каждому из них |
| Оценки по экзаменам | Список сданных предметов с оценками |
В полученном списке существуют атрибуты, которые нельзя определить в виде одного поля БД. Такие атрибуты требуют дополнительных определений и должны рассматриваться как сущности, состоящие, в свою очередь, из атрибутов. К таковым относятся: опыт работы, иностранный язык, тестирование, экспертная оценка, оценки по экзаменам. Определим их атрибуты.
Таблица 6.2. Атрибуты сущности «Опыт работы»
Атрибут
Описание
| Опыт | Опыт работы по данной специальности в годах |
| Место работы | Наименование предприятия, где приобретался опыт |
Таблица 6.3. Атрибуты сущности «Иностранный язык»
| Атрибут | Описание |
| Язык | Название иностранного языка, которым владеет студент |
| Уровень владения | Численная оценка уровня владения иностранным языком |
Таблица 6.4. Атрибуты сущности «Тестирование»
| Атрибут | Описание |
| Название | Название теста, который прошел студент |
| Описание | Содержит краткое описание теста |
| Оценка | Оценка, которую получил студент в результате прохождения теста |
Таблица 6.5. Атрибуты сущности «Экспертная оценка»
| Атрибут | Описание | |
| Дисциплина | Наименование дисциплины, по которой оценивался студент | |
| Ф.И.О. преподавателя | Ф.И.О. преподавателя, который оценивал студента | |
| Оценка | Экспертная оценку преподавателя | |
| Атрибут | Описание | |
| Предмет | Название предмета, экзамен по которому сдавался | |
| Оценка | Полученная оценка | |
Составим ERD-диаграмму, определяя типы атрибутов и проставляя связи между сущностями (рис. 6.4). Все сущности будут зависимыми от сущности «Студент». Связи будут типа «один-ко-многим».
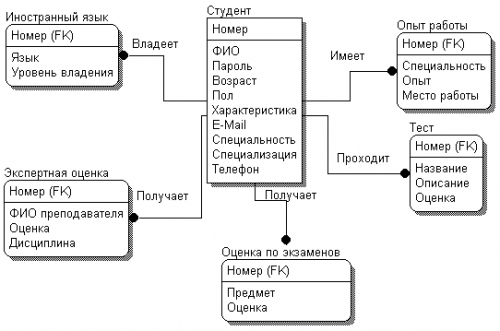
Рис. 6.4. ERD-диаграмма БД студентов
На полученной диаграмме рядом со связью отражается ее имя, показывающее соотношение между сущностями. При проведении связи между сущностями первичный ключ мигрирует в дочернюю сущность.
Следующим этапом при построении логической модели является определение ключевых атрибутов и типов атрибутов.
Таблица 6.7. Типы атрибутов
Источник
Способы построения логической модели
7.4. Логическое проектирование с использованием методологии IDEF1X
Цель логического проектирования – развить концептуальную схему БД с учетом принимаемой модели БД (иерархической, сетевой, реляционной и т. д.).
Примем в качестве модели реляционную БД в третьей нормальной форме (набор нормализованных отношений с кратностью связей 1:N). Поэтому необходимо будет проверить концептуальную схему с помощью методов нормализации и контроля выполнения транзакций [1, 21]. Транзакция – одно действие или их последовательность, выполняемых как единое целое одним или несколькими пользователями (прикладными программами) с целью осуществления доступа к БД и изменению ее содержимого.
1. Удаление и проверка элементов, не отвечающих принятой модели данных.
Если в концептуальной схеме присутствуют связи N:M, то их следует устранить путем определения промежуточной сущности. Связь N:M заменяется двумя связями типа 1:M, устанавливаемыми со вновь созданной сущностью.
Рис. 7.7. Замена связи N:M
1.2. Удаление связей с атрибутами.
Связи с атрибутами должны быть преобразованы в сущности.
В разработанной концептуальной схеме существовала связь N:M («Раздельные пункты» : «Пути»), которая имела собственные атрибуты. После устранения связь N:M, ее атрибуты перешли в сущность «Раздельные пункты на пути» (см. рис. 7.7, неключевые атрибуты).
В графической нотации IDEF1X не предусмотрено отображение связей с атрибутами, хотя некоторые методологии ERD допускают их наличие и отображение.
1.3. Удаление сложных связей (со степенью участия более 2).
Сложную связь заменяют необходимым количеством бинарных связей 1:N со вновь созданной сущностью, которая и показывает эту связь.
1.4. Удаление рекурсивных связей (со степенью участия 1).
Рекурсивную связь заменяют, определив дополнительную сущность и необходимое количество связей.
Рис. 7.8. Замена рекурсивной связи
В данной схеме можно принять следующее правило: если в сущности «Сотрудник» атрибуты «Табельный номер» и «Табельный номер руков.» совпадают, то набор атрибутов в сущности «Сотрудник» характеризует руководителя.
1.5. Удаление многозначных атрибутов (атрибутов имеющих несколько значений).
Многозначность устраняется путем введения новой сущности и связи 1:N.
Рис. 7.9. Удаление многозначных атрибутов
Данное преобразование, помимо соответствия реляционной модели данных, также позволяет хранить любое количество телефонов по одному филиалу.
1.6. Удаление избыточных связей.
Связь является избыточной, если одна и та же информация может быть получена не только через нее, но и с помощью другой связи.
Рис. 7.10. Избыточные связи
В приведенном примере одну из связей «Руководит» можно смело удалить (лучше между «Руководителем филиала» и «Сотрудником»).
1.7. Перепроверка связей 1:1.
В процессе определения сущностей могли быть созданы сущности, которые на самом деле являются одной. В этом случае их следует объединить. Например, в приведенном выше примере (рис. 46) сущности «Филиал» и «Руководитель филиала» лучше объединить.
В то же время не всегда можно выполнить такое объединение.
Рис. 7.11. Связи 1:1
Офисный пакет состоит из строго определенного набора компонентов, причем каждый из них характеризуется большим количеством атрибутов. Кроме этого, некоторые компоненты могут отсутствовать в офисном пакете (например, почтовый клиент) или они не входят в его состав (выступают в качестве самостоятельного продукта). В описанных случаях рекомендуется не объединять сущности.
2. Проверка модели с помощью правил нормализации.
Основная идея нормализации заключается в том, чтобы каждый факт хранился в одном месте, т. е. чтобы не было дублирования данных. Многие из требований нормализации, как правило, уже учитываются при выполнении предыдущих шагов проектирования.
Ниже приводятся краткие сведения из теории нормализации.
Проектирование реляционной БД представляет собой пошаговый процесс создания набора отношений (таблиц, сущностей), в которых отсутствуют нежелательные функциональные зависимости.
Функциональная зависимость определяется следующим образом. Пусть A и B – произвольные наборы атрибутов отношения. Тогда B функционально зависит от A (A → B), в том и только в том случае, если каждому значению A соответствует в точности одно значение B. Левая часть функциональной зависимости (A) называется детерминантом, а правая (B) – зависимой частью. В частности, в отношении А может быть первичным ключом, а B – набором неключевых атрибутов, так как одному значению первичного ключа в точности соответствует одно значение набора неключевых атрибутов.
Если в БД отсутствуют нежелательные функциональные зависимости, то это обеспечивает минимальную избыточность данных, что в свою очередь ведет к уменьшению объема памяти, необходимой для хранения данных. Процесс устранения таких зависимостей получил название нормализация. Она выполняется в виде последовательности тестов для некоторого отношения (таблицы, сущности) с целью проверки его соответствия (или несоответствия) набору ограничений для заданной нормальной формы.
Процесс нормализации впервые был предложен Э.Ф. Коддом в 1972 г. Сначала было предложено три вида нормальных форм (1NF, 2NF и 3NF). Затем Р. Бойсом и Э.Ф. Коддом (1974 г.) было сформулировано более строгое определение третьей нормальной формы, которое получило название нормальная форма Бойса–Кодда (BCNF). Вслед за BCNF появились определения четвертой (4NF) и пятой (5NF или PJNF) нормальных форм (Р. Фагин, 1977 и 1979 г.). На практике нормальные формы более высоких порядков используются крайне редко. При проектировании БД, как правило, ограничиваются третьей нормальной формой, что позволяет предотвратить возможное возникновение избыточности данных и аномалии обновлений.
1NF. Отношение находится в 1NF, если на пересечении каждого столбца и строки находятся только элементарные (атомарные, неделимые) значения атрибутов.
Степень неделимости (атомарности), т. е. решение о том, следует разбивать неатомарный атрибут на атомарные или оставить его псевдоатомарным, определяется проектировщиком БД исходя из конкретных условий. Если при обработке таблиц нет необходимости различать атомарные составляющие псевдоатомарного атрибута, то его можно не делить (например, атрибуты «Фамилия, имя, отчество», «Адрес» и т. д.).
2NF. Отношение находится во 2NF, если оно находится в 1NF, и каждый неключевой атрибут характеризуется полной функциональной зависимостью от первичного ключа.
Полная функциональная зависимость определяется следующим образом. В некотором отношении атрибут В полностью зависит от атрибута А, если атрибут В функционально зависит от полного значения атрибута А и не зависит от какого-либо подмножества полного значения атрибута А.
Например, таблица «Оценки по экзаменам» характеризуется следующим набором атрибутов <Номер зачетной книжки, Дисциплина, Дата сдачи, ФИО студента, № группы, Оценка>. Очевидно, что первичным ключом является набор <Номер зачетной книжки, Дисциплина, Дата сдачи>. Полной функциональной зависимостью обладает только один неключевой атрибут «Оценка». Атрибуты «ФИО студента» и «№ группы» могут быть однозначно определены по части первичного ключа – «Номер зачетной книжки». Таким образом, требуется разбиение исходной таблицы на две.
Рис. 7.12. Обеспечение полной функциональной зависимости
3NF. Отношение находится в 3NF, если оно находится во 2NF и никакой неключевой атрибут функционально не зависит от другого неключевого атрибута, т. е. нет транзитивных зависимостей.
Транзитивная зависимость. Если для атрибутов А, В и С некоторого отношения существуют зависимости вида А → В и В → С, то атрибут С транзитивно зависит от атрибута А через атрибут В.
Например, таблица «Работник» характеризуется набором атрибутов <Табельный номер, Фамилия, Имя, Отчество, Должность, Зарплата, …>, первичный ключ – <Табельный номер>. В этой таблице от первичного ключа («Табельный номер») зависит неключевой атрибут «Должность», а от «Должности» другой неключевой атрибут «Зарплата». Для приведения к 3NF необходимо добавить новую таблицу.
Рис. 7.13. Устранение транзитивной зависимости
BCNF. Отношение находится в BCNF, если оно находится в 3NF и каждый детерминант отношения является его возможным ключом.
Отступление от BCNF возможно, когда в таблице имеется несколько составных потенциальных ключей (детерминантов), причем часть атрибутов одного потенциального ключа характеризуется полной функциональной зависимостью от части другого потенциального ключа.
Например, таблица «Поставка деталей» характеризуется набором атрибутов
Рис. 7.14. Приведения отношения к BCNF
Отличие BCNF от 2NF заключается в том, что выносимый в отдельную таблицу атрибут («Наименование поставщика») входит в состав потенциального ключа, а не является простым неключевым атрибутом («ФИО студента» и «№ группы» на рис. 7.12).
4NF. Отношение находится в 4NF в том и только в том случае, если в нем отсутствуют нетривиальные многозначные зависимости.
Нетривиальная многозначная зависимость. В отношении с атрибутами А, В и С существует нетривиальная многозначная зависимость, если для каждого значения атрибута А имеется набор значений атрибута В (A −>> B) и набор значений атрибута С (A −>> С), но между атрибутами В и С нет зависимостей.
Например, таблица «Экзамены» характеризуется набором атрибутов <Номер группы, Номер зачетной книжки, Дисциплина>, первичный ключ – весь набор атрибутов. В данной таблице имеется две многозначные зависимости: номер группы определяет список студентов, которые в ней учатся (Номер группы −>> Номер зачетной книжки), и номеру группы соответствует список дисциплин учебного плана, по которым требуется сдавать экзамены (Номер группы −>> Дисциплина). В то же время между номером зачетной книжки и дисциплиной зависимость отсутствует. Для приведения таблицы к 4NF требуется разбить ее на две.
Рис. 7.15. Приведения отношения к 4NF
5NF (нормальная форма проекции соединения, PJNF). Отношение находится в 5NF, если в нем нет зависимостей соединения.
Зависимость соединения. В отношении с атрибутами А, В и С существует зависимость соединения, если для каждого значения атрибута А имеется набор значений атрибута В (A −>> B) и набор значений атрибута С (A −>> С), а также существует многозначная зависимость между атрибутами В и С (В −>> С или С −>> B).
Например, таблица «Дисциплины» характеризуется набором атрибутов <Кафедра, Преподаватель, Дисциплины>, первичный ключ – весь набор атрибутов. В данной таблице имеется несколько многозначных зависимостей: на кафедре работает несколько преподавателей (Кафедра −>> Преподаватель), кафедра ведет несколько дисциплин учебного плана (Кафедра −>> Дисциплина), преподаватель может вести несколько дисциплин (Преподаватель −>> Дисциплина) и, наоборот, одну дисциплину могут вести разные преподаватели (Дисциплина −>> Преподаватель). Для устранения зависимости соединения следует разбить исходную таблицу на три.
Рис. 7.16. Приведения отношения к 5NF
3. Определение требований поддержки целостности данных.
Ограничения целостности данных представляют собой ограничения, которые вводятся с целью предотвращения помещения в базу противоречивых данных.
К этим ограничениям относятся:
— обязательные данные – атрибуты, которые всегда должны содержать одно из допустимых значений (NOT NULL). Например, поворот кривой (влево или вправо) должен быть обязательно задан. Обязательными также являются все атрибуты, входящие в первичный ключ сущности;
— домены – наборы допустимых значений для атрибута. Например, радиус кривой должен быть положительным числом не более 4 цифр или поворот кривой может принимать одно из двух допустимых значений – «Л» (влево) или «П» (вправо);
— бизнес-правила (бизнес-ограничения) – ограничения, принятые в рассматриваемой предметной области. Например, сумма длин переходных кривых не должна быть более длины всей кривой, километраж начала или конца кривой должен быть в пределах общего километража пути и т.д.;
— ссылочная целостность – набор ограничений, определяющих действия при вставке, обновлении и удалении записей (экземпляров сущности). Например:
o при наличии обязательной связи вставка записи в дочернюю сущность требует обязательного заполнения атрибутов внешнего ключа, и введенному значению должна соответствовать запись родительской сущности;
o аналогичное требование выдвигается при обновлении внешнего ключа в дочерней сущности;
o удаление записи из дочерней сущности или вставка записи в родительскую не вызывают нарушения ссылочной целостности;
o удаление записи в родительской сущности может требовать удаления всех связанных записей в дочерней сущности.
Автоматическая поддержка всех видов ограничений целостности возможна за счет использования операторов SQL.
Ссылочная целостность может быть обеспечена за счет использования триггеров. Триггер – это хранимая в БД процедура, исполняемая СУБД автоматически при удалении (DELETE), вставке (INSERT) или обновлении (UPDATE) записи. Набор команд, входящих в триггер, зависит от принятой стратегии (типа триггера) поддержания целостности:
— RESTRICT или NO ACTION — на выполнение действия накладываются ограничения (условия). Под NO ACTION обычно понимаются триггеры, срабатывающие на изменение данных в родительской таблице. При соблюдении условий изменения в БД принимаются, в противном случае отклоняются;
— CASCADE — каскадное удаление или обновление данных;
— SET NULL — установка неопределенного значения (NULL) в атрибутах внешнего ключа дочерней таблицы;
— SET DEFAULT — установка значения по умолчанию в атрибутах внешнего ключа дочерней таблицы;
— NO CHECK, NONE или IGNORE — поддержка ссылочной целостности встроенными средствами СУБД не предусмотрена, но может быть выполнена за счет клиентских программ, работающих с БД. Данная стратегия принята в СУБД по умолчанию.
Рассмотрим работу различных типов триггеров на примере двух таблиц — «Участки» и «Пути». Железная дорога состоит из участков, которые, в свою очередь, состоят из главных путей. Возможны три варианта организации связи между таблицами.
| а) идентифицирующая (обязательная) связь | б) неидентифицирующая обязательная связь | в) неидентифицирующая необязательная связь |
Рис. 7.17. Варианты организации связи между таблицами
В первом случае (рис. 7.17а) уникальность значений атрибута «Идентификатор пути» должна быть обеспечена в рамках одного участка, в остальных (рис. 7.19б и 7.19в) — по всей дороге (по всей таблице «Пути»).
Согласованные данные для этих случаев могут выглядеть следующим образом.
Рис. 7.18. Пример данных в таблицах «Участки» и «Пути»
В следующей таблице приведены последствия срабатывания триггеров при выполнении различных операций по изменению данных.
Таблица 7.2. Принципы работы триггеров
| Операция | Тип триггера | Таблица | Связь | Последствия применения триггера и/или условия фиксации изменений в БД | Пример | |
| SQL-оператор | Измененные данные | |||||
| INSERT — вставка записи | RESTRICT | Дочерняя | При вставке записи в дочернюю таблицу во внешний ключ обязательно должно быть внесено значение (явно прописано в операторе INSERT), соответствующее одному из значений первичного ключа родительской таблицы | INSERT INTO puti (ID, IdUchastok, Name) VALUES (6, 3, ‘Нечетный’) | ||
| INSERT INTO puti (ID, IdUchastok, Name) VALUES (6, 4, «Нечетный») | Изменение данных запрещается триггером | |||||
| SET DEFAULT | Дочерняя | При вставке записи в дочернюю таблицу во внешний ключ автоматически заносится значение по умолчанию. В операторе INSERT поля внешнего ключа могут не упоминаться. Значение по умолчанию должно соответствовать одному из значений первичного ключа родительской таблицы. Т.е. в родительской таблице на момент выполнения оператора INSERT должна присутствовать запись, значение первичного ключа которой соответствует значению по умолчанию | Значение по умолчанию поля «Идентификатор участка» = «3» | |||
INSERT INTO puti (ID, Name) VALUES (6, ‘Нечетный’)
INSERT INTO puti (ID, Name) VALUES (6, ‘Нечетный’)
INSERT INTO puti (ID, Name) VALUES (6, ‘Нечетный’)
INSERT INTO puti (ID, Name) VALUES (6, ‘Нечетный’)
UPDATE uchastki SET WHERE >
UPDATE uchastki SET WHERE >
UPDATE uchastki SET WHERE >
UPDATE uchastki SET WHERE >
DELETE FROM uchastki WHERE >
DELETE FROM uchastki WHERE >
DELETE FROM uchastki WHERE >
DELETE FROM uchastki WHERE >
1. Измененные данные в таблицах «Участки» и «Пути» показаны относительно приведенных на рис. 7.20 после выполнения SQL-оператора.
2. Под связанными записями понимаются записи дочерней таблицы, у которых значения внешнего ключа совпадает со значением первичного ключа родительской таблицы.
Назначение типа триггера на действия с записями является ответственной операцией. Выбор неверного типа может привести к нарушению ссылочной целостности в БД. Особой осторожности требует выбор каскадного удаления, ведь при таком удалении по цепочке могут быть удалены сотни и тысячи записей из разных таблиц.
7.5. Пример построения логической схемы
На рис. 7.19 приведен блок «Информация об участках дороги» логической схемы информационной модели, построенной с использованием ERwin v9.2. Данная модель соответствует третьей нормальной форме.
Рис. 7.19. Блок «Информация об участках дороги» логической схемы информационной модели
На рисунке также показаны триггеры на действия, выполняемые как со стороны родительской сущности, так и со стороны дочерней. Триггеры показаны в следующем формате «Действие : Тип триггера». Действие может быть одного из трех типов: D (DELETE), I (INSERT) и U (UPDATE). Тип триггера обозначается: C (CASCADE) и R (RESTRICT).
Источник



