
Способы поиска информации с помощью разных браузеров

Полезные советы
При поиске нужной вам информации, лучше использовать несколько поисковых систем, этим вы повысите эффективность ваших запросов.

Поиск по сайту
Поиск информации в Интернете
Для поиска информации в обычно используются три способа (См. Рис.1). Первый из них — поиск по адресу. Он применяется, когда пользователю известен адрес информационного ресурса, содержащего необходимую ему информацию. При организации поиска информации по адресу (форма адреса — IP, доменный или URL — в этом случае значения не имеет) пользователю достаточно просто ввести адрес ресурса в соответствующее поле браузера – программы, предназначенной для обеспечения доступа к сетевым ресурсам.
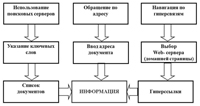
Рис. 1. Способы поиска информации в гипертекстовых базах данных
Второй – поиск с помощью навигации по гиперсвязям. При использовании этого вида поиска случае пользователь сначала должен получить доступ к серверу, связанному с соответствующей БД. После этого можно найти документ, используя гиперссылки. Очевидно, что этот способ удобен, когда адрес ресурса неизвестен пользователю. Для использования в качестве исходной точки для поиска при реализации этого способа предназначены Web-порталы — серверы, предоставляющие прямой доступ к некоторому множеству серверов, включая установленные на них информационные ресурсы, а также Web-приложения, которые реализуют Web-сервисы, соответствующие назначению портала. Доступные через портал серверы могут относиться к определенной системе (например — корпоративной) или различным системам и быть специально подобраны по видовому, тематическому или другим признакам документов и данных, содержащихся на их сайтах. Обычно порталы совмещают в себе разнообразные функции с целью удержать клиента как можно дольше. Доминирующим сервисом портала является сервис справочной службы: поиск, рубрикаторы, финансовые индексы, информация о погоде и т.д. Если Web-сайты в большинстве случаев представляют собой наборы статических Web-страниц, то порталы являются совокупностями программных средств и заранее неструктурированной информации, которую эти средства превращают в структурированные данные по запросу конкретных пользователей.
Третий способ поиска предполагает использование поисковых серверов Интернета. Поисковыми серверами называют выделенные хост — компьютеры, в которых размещаются базы данных ресурсов Интернета. Пользовательский интерфейс такого сервера имеет поле для ввода ключевых слов, описывающих тему, интересующую пользователя (См. Рис. 2).
Рис.2. Вид окна поискового сервера системы Яндекс
Эти слова сервер воспринимает как информационный запрос, в соответствии с которым он осуществляет поиск ресурсов и представляет список найденных документов пользователю. Очевидно, что при реализации этого способа возможны ошибки как 1-го (пропуск цели), так и 2-го рода (информационный шум). Следует упомянуть, что различаются две группы поисковых серверов: поисковые машины и предметные каталоги. Их отличие обусловлено способом создания и последующего пополнения базы данных ресурсов Интернета, которой данный сервер осуществляет информационный поиск. Так, поисковые машины имеют в своем составе специальную программу — поисковый робот. Она осуществляет постоянный мониторинг сети, собирает информацию с Web- страниц, индексирует их и фиксирует их поисковый образ в своей базе данных. В предметных каталогах база данных о документах Интернета формируется «вручную» специалистами-редакторами. Поскольку в Интернете отсутствует единое администрирование, постольку его информационные ресурсы постоянно меняются. В нём могут появляться новые и исчезать существующие документы. Частота обновления информации в документах для разных сайтов различна: для некоторых — это несколько раз в час, для некоторых — раз в сутки, день, месяц и т.д. Поэтому очень важно понимать, что при использовании информационно-поисковых систем для нахождения информации в Интернете, поиск осуществляется не на реальном пространстве документов Сети, а в некоторой модели, содержание которой может значительно отличаться от действительного содержания Интернет в момент проведения поиска. По степени охвата индексируемых ресурсов поисковые системы можно разделить на две группы: международные и русскоязычные. Первые индексируют все опубликованные в Интернете документы подряд. Вторые индексируют ресурсы, расположенные в доменных зонах с преобладанием русского языка. Список наиболее популярных систем приведен в Табл. 1.
Табл. 1. Наиболее популярные поисковые системы
| Международные | Русскоязычные |
|---|---|
| Яндекс (44,4 % Рунета) | |
| Yahoo! | Rambler (10,6 % Рунета) |
| Bing | Mail.ru (7,3 % Рунета) |
| MSN | Nigma (0,5 % Рунета) |
| AltaVista | Gogo.ru (0,3 % Рунета) |
| Ask | Aport (0,2 % Рунета) |
Примечание: Рунет – это русскоязычная часть Интернета, составляющая домены с именами ru и рф.
Необходимо упомянуть, что существует особая категория поисковых серверов – метапоисковые системы. Их принципиальное отличие от поисковых машин и предметных каталогов состоит в том, что у них отсутствует собственная индексная база данных, и поэтому они, получив запрос пользователя, перенаправляют его сразу к нескольким поисковым серверам (См. Рис. 3).
Источник
Способы поиска информации с помощью разных браузеров
Браузер (или броузер) (от англ. слова browse — просматривать) представляет собой специальную программу для просмотра информации в Internet. Существует большое число разных браузеров, среди которых наибольшей популярностью пользуются Netscape Navigator (NN) фирмы Netscape Communications (он входит в состав пакета Netscape Communicator) и Internet Explorer (IE) фирмы Microsoft.
Браузер предоставляет возможность параллельной работы с несколькими Web-страницами (см. меню File (Файл)). Переключение между окнами можно осуществлять с помощью панели задач Windows. Указав разные адреса в разных окнах, мы можем начать работать с одной Web-страницей, а в это время в другом окне будет загружаться следующая. При необходимости можно прервать процесс загрузки Web-страницы нажатием кнопки Stop (Стоп).
При чтении Web-страниц, написанных на русском языке, нередко возникают проблемы связанные с различием кодировок русских букв (кириллицы) на Web-сервере, откуда читается страница, и той кодировки, которая установлена на нашем браузере. В качестве стандартной кодировки русских букв в Internet принята кодировка KOI8-R, которую поддерживают компьютеры под управлением операционной системы Unix. Однако повсеместное внедрение операционной системы Windows привело к тому, что все чаще используется ее кодировка кириллицы — Windows1251.
Браузеры хранят историю (History) блуждания по сети Internet на протяжении определенного времени. Есть система электронных закладок — Bookmarks (Закладки) для NN браузера и Favorites (Избранные страницы) для IE браузера. Наиболее удобно добавлять новые адреса в папку с закладками с помощью контекстных всплывающих меню, которые появляются при нажатии правой кнопки мыши. Если при этом курсор мыши находился на гиперслове, то с помощью команды Add Bookmark в случае NN браузера, или Добавить в папку в случае IE браузера, мы можем добавить определяемый этой гиперссылкой URL-адрес в папку Bookmarks (Избранное). С помощью команды Copy Link Location этот адрес можно скопировать в буфер обмена Windows с тем, чтобы затем поместить его в какой-либо документ, например, в создаваемую нами свою собственную Web-страницу.
Классификация поисковых систем
Выделяют так называемые тематические каталоги (например, Yahoo!) и автоматические индексы (например, AltaVista), хотя необходимо иметь в виду, что целый ряд поисковых систем занимает некоторое промежуточное положение между этими двумя «полюсами», то есть они содержат в себе элементы обоих этих классов. Каждая из поисковых систем имеет свою обширную базу данных об адресах (местоположении) различных Web-документов, и поиск ссылок на необходимую нам информацию происходит, не в самих Web-документах, а именно в этой базе данных.
Тематические каталоги и автоматические индексы различаются по тому, как формируются и пополняются их базы данных: принимают ли в этом процессе участие люди, или все происходит автоматически.
Тематический каталог представляет пользователю Internet некоторую древовидную структуру категорий (разделов и подразделов), на верхнем уровне которой собраны самые общие понятия, такие как Наука, Искусство, Бизнес и т.п., а элементы самого нижнего уровня представляют собой ссылки на отдельные Web-страницы и серверы вместе с кратким описанием их содержимого. Например, для нахождения информации о состоянии научных исследований по теории суперструн можно спуститься вниз по следующей «лестнице понятий»: Science (Наука) — Physics (Физика) — Theoretical Physics (Теоретическая физика) -Theories (Теории) — String Theories (Теории струн).
Главным достоинством тематических каталогов является большая ценность получаемой пользователем информации, что обеспечивается присутствием «человеческого фактора» в процессе анализа и сортировки новых Web-страниц. С другой стороны, тематические каталоги имеют существенный недостаток, связанный опять же с человеческим фактором, т.к. из-за ограниченных возможностей человека их базы данных охватывают лишь небольшую часть всего информационного Web-пространства (менее 1 %).
В отличие от тематических каталогов, базы данных для автоматических индексов создаются и пополняются полностью автоматически некоторыми специальными, внутренними поисковыми программами-роботами, которые в круглосуточном режиме просматривают Internet-узлы (сайты) в поисках вновь появившихся Web-документов. В отличие от тематических каталогов, автоматические индексы охватывают до 25 % общего Web-пространства.
Некоторой разновидностью поисковых служб являются рейтинговые службы. Они предоставляют клиенту готовый список некоторых ссылок, к которым обращались наиболее часто другие пользователи сети Internet. Такие услуги, в частности, обеспечивает отечественная служба Rambler.
Все поисковые указателя реализуют несколько алгоритмов поиска.
1. Простой поиск . В поле запроса вводится одно или несколько слов, которые могут характеризовать содержание документа. Если это слово одно, то в ответ выдается большое количество ссылок. Если несколько слов, то результат зависит от того, как эти слова введены, а это зависит от каждой конкретной системы.
2. Расширенный поиск – подразумевает запрос из группы слов. Слова связываются логическими операторами И, ИЛИ, НЕ и др.
3. Контекстный поиск – реализован не во всех поисковых указателях. Если этот метод есть, то ключевая фраза должна быть заключена в кавычки.
4. Специальный поиск — позволяет найти дополнительную информацию. Например, такие команды позволяют определить, как часто в Сети встречаются гиперссылки, указывающие на какой-то ресурс, с их помощью можно найти ключевые слова, входящие в заголовки Web -страниц и т.п.
Особенности группировки слов в поисковых системах
1. Поисковые системы по-разному трактуют группы слов, введенные через пробел, как И или как ИЛИ. В большинстве систем в качестве оператора И используется «+» перед словом без пробела. Большинство российских поисковых систем по умолчанию считают, что два слова должны присутствовать в документе. На Яндексе — в одном предложении. ИЛИ в системах задается так: Апорт – ИЛИ, Рамблер – OR , Яндекс — ç .
2. Прописные буквы . «хлеб» = «ХЛЕБ», но «ХЛЕБ» ≠ «хлеб». Если введены строчные символы, то разыскиваются как строчные, так и прописные символы, но если использованы прописные, то ищется точное совпадение с прописными. В системе Рамблер при индексации все прописные буквы принудительно «понижаются до строчных».
3. Зарезервированные слова – это слова, которые не учитываются при обработке запроса. К ним относятся неинформативные слова: предлоги, союзы, местоимения, артикли и др. слова малого размера. В некоторых системах зарезервированными могут быть слова, которые часто встречаются, поэтому информативными не являются. Например, в системе, ориентированной на поиск книг слово «книга» будет не информативным. При контекстном поиске необходимо точное (!) соответствие между заказом и результатом поиска. Если поисковая система «зачистила» Web -документы от зарезервированных слов, то с контекстным поиском она справиться не может. На Яндексе и Рамблере только делают вид контекстного поиска (через кавычки). В России честный контекстный поиск проводит только Апорт, но у него невелика база указателей.
4. Формы поиска . С 1997 г . Поисковые системы предоставляют услуги по розыску данных, записанных в разных форматах: рисунки, видеофайлов, звуковые клипы и т.д. Для этого следует включить переключатель, соответствующий типу разыскиваемых данных. Яндекс позволяет найти тексты, товары и рисунки, Апорт – плюс MP 3 , Рамблер – только тексты. Из зарубежных служб подходит для домашнего пользования Fast Search , для делового потребления – Northern Light .
5. Действия после поиска . Если представлен объемный документ, то можно воспользоваться кнопкой Правка – Найти на этой странице.
6. Приемы поиска в системе «Яндекс» . Поиск по одному слову ведется на основе корня этого слова. Например, если введено слово «снег», то система выдаст документы, в состав которых входят однокоренные слова. Если поиск словоформ не требуется, то его отменить с помощью «!», например, !снегом.
Поиск по группе слов
· Знак «+» пишется слитно со словом без пробела.
· Можно ввести оператор И (&), справа и слева от & должны быть пробелы.
· Если требуется присутствие слов не только в предложении, но и во всем документе, применяется оператор &&.
» — строгое исключение из предложения
» — исключение из всего документа
· Пример: «Москва ç Петербург&&+столица»
Поиск с указанием расстояния
· «/ ± n », «/(- n + n )» Оператор NEAR позволяет находить документы, в которых искомые слова находятся близко друг от друга. Например, «Город/+1Москва» = «Город Москва».
» , например, «Город/+1&&Москва» — словосочетание будет ли в одном предложении или в соседних.
Использование скобок . Служат для управления порядком действий. «Москва ç Петербург& (столица ç город-герой)».
Управление ранжированием производится с использованием весовых коэффициентов. Его можно присваивать любому ключевому слову или выражению, если оно заключено в скобки. «Москва:5 Петербург столица».
Ввод уточняющего слова осуществляется после знаков
Источник



