
- Оценка сложности алгоритмов
- Введение
- Определения
- Порядок роста сложности алгоритмов
- Виды асимптотических оценок
- Критерии оценки сложности алгоритмов
- Пример оценки сложности при вычислении факториала
- Оценка сложности алгоритмов, или Что такое О(log n)
- Авторизуйтесь
- Оценка сложности алгоритмов, или Что такое О(log n)
- Оценка сложности
- Примеры
- O(n) — линейная сложность
- O(log n) — логарифмическая сложность
- O(n 2 ) — квадратичная сложность
- Наглядно
- Сложность алгоритмов. Big O. Основы.
- Распространённые сложности алгоритмов
- Константная — O(1).
- Линейная — O(n).
- Логарифмическая — O(log n).
- Линеарифметическая или линеаризованная — O(n * log n).
- Квадратичная — O(n 2 ), O(n^2).
- Зачем изучать Big O
- Шпаргалка
- Полезные ссылки
Оценка сложности алгоритмов
Введение
Для любого программиста важно знать основы теории алгоритмов, так как именно эта наука изучает общие характеристики алгоритмов и формальные модели их представления. Ещё с уроков информатики нас учат составлять блок-схемы, что, в последствии, помогает при написании более сложных задач, чем в школе. Также не секрет, что практически всегда существует несколько способов решения той или иной задачи: одни предполагают затратить много времени, другие ресурсов, а третьи помогают лишь приближённо найти решение.
Всегда следует искать оптимум в соответствии с поставленной задачей, в частности, при разработке алгоритмов решения класса задач.
Важно также оценивать, как будет вести себя алгоритм при начальных значениях разного объёма и количества, какие ресурсы ему потребуются и сколько времени уйдёт на вывод конечного результата.
Этим занимается раздел теории алгоритмов – теория асимптотического анализа алгоритмов.
Предлагаю в этой статье описать основные критерии оценки и привести пример оценки простейшего алгоритма. На Хабрахабре уже есть статья про методы оценки алгоритмов, но она ориентирована, в основном, на учащихся лицеев. Данную публикацию можно считать углублением той статьи.
Определения
Основным показателем сложности алгоритма является время, необходимое для решения задачи и объём требуемой памяти.
Также при анализе сложности для класса задач определяется некоторое число, характеризующее некоторый объём данных – размер входа.
Итак, можем сделать вывод, что сложность алгоритма – функция размера входа.
Сложность алгоритма может быть различной при одном и том же размере входа, но различных входных данных.
Существуют понятия сложности в худшем, среднем или лучшем случае. Обычно, оценивают сложность в худшем случае.
Временная сложность в худшем случае – функция размера входа, равная максимальному количеству операций, выполненных в ходе работы алгоритма при решении задачи данного размера.
Ёмкостная сложность в худшем случае – функция размера входа, равная максимальному количеству ячеек памяти, к которым было обращение при решении задач данного размера.
Порядок роста сложности алгоритмов
Порядок роста сложности (или аксиоматическая сложность) описывает приблизительное поведение функции сложности алгоритма при большом размере входа. Из этого следует, что при оценке временной сложности нет необходимости рассматривать элементарные операции, достаточно рассматривать шаги алгоритма.
Шаг алгоритма – совокупность последовательно-расположенных элементарных операций, время выполнения которых не зависит от размера входа, то есть ограничена сверху некоторой константой.
Виды асимптотических оценок
O – оценка для худшего случая
Рассмотрим сложность f(n) > 0, функцию того же порядка g(n) > 0, размер входа n > 0.
Если f(n) = O(g(n)) и существуют константы c > 0, n0 > 0, то
0 n0.

Функция g(n) в данном случае асимптотически-точная оценка f(n). Если f(n) – функция сложности алгоритма, то порядок сложности определяется как f(n) – O(g(n)).
Данное выражение определяет класс функций, которые растут не быстрее, чем g(n) с точностью до константного множителя.
Примеры асимптотических функций
| f(n) | g(n) |
|---|---|
| 2n 2 + 7n — 3 | n 2 |
| 98n*ln(n) | n*ln(n) |
| 5n + 2 | n |
| 8 | 1 |
Ω – оценка для лучшего случая
Определение схоже с определением оценки для худшего случая, однако
f(n) = Ω(g(n)), если
0 n0 всюду находится между c1*g(n) и c2*g(n), где c – константный множитель.
Например, при f(n) = n 2 + n; g(n) = n 2 .
Критерии оценки сложности алгоритмов
Равномерный весовой критерий (РВК) предполагает, что каждый шаг алгоритма выполняется за одну единицу времени, а ячейка памяти за одну единицу объёма (с точностью до константы).
Логарифмический весовой критерий (ЛВК) учитывает размер операнда, который обрабатывается той или иной операцией и значения, хранимого в ячейке памяти.
Временная сложность при ЛВК определяется значением l(Op), где Op – величина операнда.
Ёмкостная сложность при ЛВК определяется значением l(M), где M – величина ячейки памяти.
Пример оценки сложности при вычислении факториала
Необходимо проанализировать сложность алгоритма вычисление факториала. Для этого напишем на псевдокоде языка С данную задачу:
Временная сложность при равномерном весовом критерии
Достаточно просто определить, что размер входа данной задачи – n.
Количество шагов – (n — 1).
Таким образом, временная сложность при РВК равна O(n).
Временная сложность при логарифмическом весовом критерии
В данном пункте следует выделить операции, которые необходимо оценить. Во-первых, это операции сравнения. Во-вторых, операции изменения переменных (сложение, умножение). Операции присваивания не учитываются, так как предполагается, что она происходят мгновенно.
Итак, в данной задаче выделяется три операции:
Источник
Оценка сложности алгоритмов, или Что такое О(log n)
Авторизуйтесь
Оценка сложности алгоритмов, или Что такое О(log n)
Наверняка вы не раз сталкивались с обозначениями вроде O(log n) или слышали фразы типа «логарифмическая вычислительная сложность» в адрес каких-либо алгоритмов. И если вы хотите стать хорошим программистом, но так и не понимаете, что это значит, — данная статья для вас.
Оценка сложности
Сложность алгоритмов обычно оценивают по времени выполнения или по используемой памяти. В обоих случаях сложность зависит от размеров входных данных: массив из 100 элементов будет обработан быстрее, чем аналогичный из 1000. При этом точное время мало кого интересует: оно зависит от процессора, типа данных, языка программирования и множества других параметров. Важна лишь асимптотическая сложность, т. е. сложность при стремлении размера входных данных к бесконечности.
Допустим, некоторому алгоритму нужно выполнить 4n 3 + 7n условных операций, чтобы обработать n элементов входных данных. При увеличении n на итоговое время работы будет значительно больше влиять возведение n в куб, чем умножение его на 4 или же прибавление 7n . Тогда говорят, что временная сложность этого алгоритма равна О(n 3 ) , т. е. зависит от размера входных данных кубически.
Использование заглавной буквы О (или так называемая О-нотация) пришло из математики, где её применяют для сравнения асимптотического поведения функций. Формально O(f(n)) означает, что время работы алгоритма (или объём занимаемой памяти) растёт в зависимости от объёма входных данных не быстрее, чем некоторая константа, умноженная на f(n) .
Примеры
O(n) — линейная сложность
Такой сложностью обладает, например, алгоритм поиска наибольшего элемента в не отсортированном массиве. Нам придётся пройтись по всем n элементам массива, чтобы понять, какой из них максимальный.
O(log n) — логарифмическая сложность
Простейший пример — бинарный поиск. Если массив отсортирован, мы можем проверить, есть ли в нём какое-то конкретное значение, методом деления пополам. Проверим средний элемент, если он больше искомого, то отбросим вторую половину массива — там его точно нет. Если же меньше, то наоборот — отбросим начальную половину. И так будем продолжать делить пополам, в итоге проверим log n элементов.
O(n 2 ) — квадратичная сложность
Такую сложность имеет, например, алгоритм сортировки вставками. В канонической реализации он представляет из себя два вложенных цикла: один, чтобы проходить по всему массиву, а второй, чтобы находить место очередному элементу в уже отсортированной части. Таким образом, количество операций будет зависеть от размера массива как n * n , т. е. n 2 .
27–28 ноября, Москва, Беcплатно
Бывают и другие оценки по сложности, но все они основаны на том же принципе.
Также случается, что время работы алгоритма вообще не зависит от размера входных данных. Тогда сложность обозначают как O(1) . Например, для определения значения третьего элемента массива не нужно ни запоминать элементы, ни проходить по ним сколько-то раз. Всегда нужно просто дождаться в потоке входных данных третий элемент и это будет результатом, на вычисление которого для любого количества данных нужно одно и то же время.
Аналогично проводят оценку и по памяти, когда это важно. Однако алгоритмы могут использовать значительно больше памяти при увеличении размера входных данных, чем другие, но зато работать быстрее. И наоборот. Это помогает выбирать оптимальные пути решения задач исходя из текущих условий и требований.
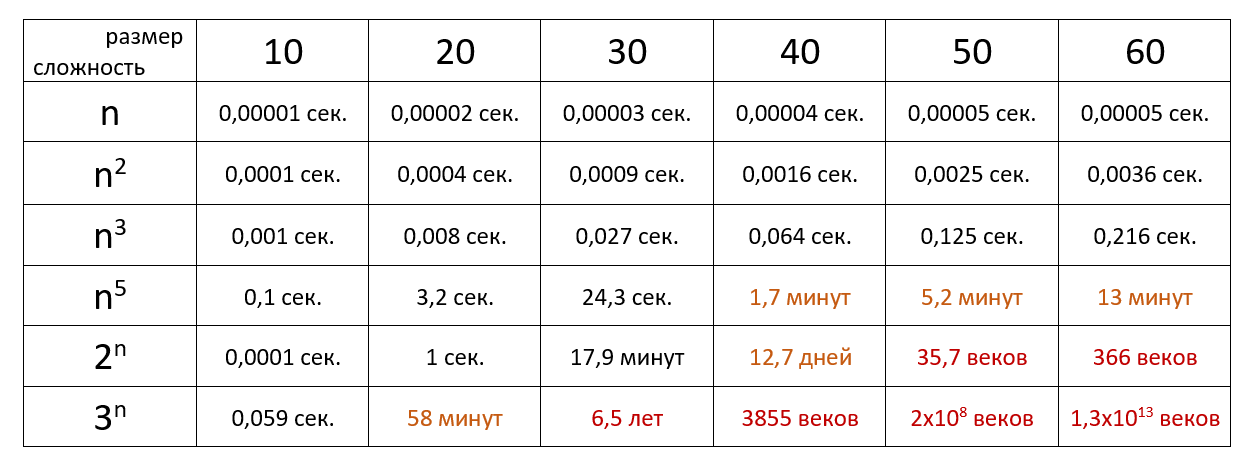
Наглядно
Время выполнения алгоритма с определённой сложностью в зависимости от размера входных данных при скорости 10 6 операций в секунду:
 Тут можно посмотреть сложность основных алгоритмов сортировки и работы с данными.
Тут можно посмотреть сложность основных алгоритмов сортировки и работы с данными.
Если хочется подробнее и сложнее, заглядывайте в нашу статью из серии «Алгоритмы и структуры данных для начинающих».
Источник
Сложность алгоритмов. Big O. Основы.
Сложность алгоритма — это количественная характеристика, которая говорит о том, сколько времени, либо какой объём памяти потребуется для выполнения алгоритма.
Развитие технологий привело к тому, что память перестала быть критическим ресурсом. Поэтому когда говорят об анализе сложности алгоритма, обычно подразумевают то, насколько быстро он работает.
Но ведь время выполнения алгоритма зависит от того, на каком устройстве его запустить. Один и тот же алгоритм запущенный на разных устройствах выполняется за разное время.
Тогда было предложено измерять сложность алгоритмов в элементарных шагах — то, сколько действий необходимо совершить для его выполнения. Любой алгоритм включает в себя определённое количество шагов и не важно на каком устройстве он будет запущен, количество шагов останется неизменным. Эту идею принято представлять в виде Big O (или О-нотации).
Big O показывает то, как сложность алгоритма растёт с увеличением входных данных. При этом она всегда показывает худший вариант развития событий — верхнюю границу.
Big O показывает верхнюю границу зависимости между входными параметрами функции и количеством операций, которые выполнит процессор.
Распространённые сложности алгоритмов
Здесь рассмотрены именно распространённые виды, так как рассмотреть все варианты врядли возможно. Всё зависит от алгоритма, который вы оцениваете. Всегда может появится какая-то дополнительная переменная (не константа), которую необходимо будет учесть в функции Big O.
Константная — O(1).
Означает, что вычислительная сложность алгоритма не зависит от входных данных. Однако, это не значит, что алгоритм выполняется за одну операцию или требует очень мало времени. Это означает, что время не зависит от входных данных.
Пример № 1.
У нас есть массив из 5 чисел и нам надо получить первый элемент.
Насколько возрастет количество операций при увеличении размера входных параметров?
Нинасколько. Даже если массив будет состоять из 100, 1000 или 10 000 элементов нам всеравно потребуется одна операция.
Пример № 2.
Сложение двух чисел. Функция всегда выполняет константное количество операций.
Пример № 3.
Размер массива. Опять же, функция всегда выполняет константной количество операций.
Линейная — O(n).
Означает, что сложность алгоритма линейно растёт с увеличением входных данных. Другими словами, удвоение размера входных данных удвоит и необходимое время для выполнения алгоритма.
Такие алгоритмы легко узнать по наличию цикла по каждому элементу массива.
Пример № 1 — Рекурсивная функция.
Пример № 2 — Линейная функция.
Функция pairSumSequence() в цикле складывает какие-либо пары чисел, вызывая функцию pairSum() . Цикл выполняется от 0 до n. Т.е. чем больше n, тем больше раз выполнится цикл. Поэтому сложность функции pairSumSequence() — O(n).
Пример № 3.
В функции два последовательных цикла for , каждый из которых проходит массив длиной n, следовательно сложность будет: O(n + n) = O(n)
Логарифмическая — O(log n).
Означает, что сложность алгоритма растёт логарифмически с увеличением входных данных. Другими словами это такой алгоритм, где на каждой итерации берётся половина элементов.
К алгоритмам с такой сложностью относятся алгоритмы типа “Разделяй и Властвуй” (Divide and Conquer), например бинарный поиск.
Линеарифметическая или линеаризованная — O(n * log n).
Означает, что удвоение размера входных данных увеличит время выполнения чуть более, чем вдвое.
Примеры алгоритмов с такой сложностью: Сортировка слиянием или множеством n элементов.
Квадратичная — O(n 2 ), O(n^2).
Означает, что удвоение размера входных данных увеличивает время выполнения в 4 раза. Например, при увеличении данных в 10 раз, количество операций (и время выполнения) увеличится примерно в 100 раз. Если алгоритм имеет квадратичную сложность, то это повод пересмотреть необходимость использования данного алгоритма. Но иногда этого не избежать.
Такие алгоритмы легко узнать по вложенным циклам.
Пример № 1.
В функции есть цикл в цикле, каждый из них проходит массив длиной n, следовательно сложность будет: O(n * n) = O(n 2 )
Зачем изучать Big O
- Концепцию Big O необходимо понимать, чтобы уметь видеть и исправлять неоптимальный код.
- Ни один серьёзный проект, как ни одно серьёзное собеседование, не могут обойтись без вопросов о Big O.
- Непонимание Big O ведёт к серьёзной потере производительности ваших алгоритмов.
Шпаргалка
Небольшие подсказки, которые помогут определить сложность алгоритма.
- Получение элемента коллекции это O(1). Будь то получение по индексу в массиве, или по ключу в словаре в нотации Big O это будет O(1).
- Перебор коллекции это O(n).
- Вложенные циклы по той же коллекции это O(n 2 ).
- Разделяй и властвуй (Divide and Conquer) всегда O(log n).
- Итерации которые используют “Разделяй и властвуй” (Divide and Conquer) это O(n log n).
Полезные ссылки
Оценка сложности алгоритма. Сложность алгоритмов. Big O, Большое О — 25-минутное видео, в котором очень доступно (и с примерами) объясняются основы анализа сложности алгоритмов.
Big O — статья на хабре о Big O.
Знай сложности алгоритмов — статья рассказывает о времени выполнения и о расходе памяти большинства алгоритмов.
Источник



