
Способы отбора данных. Способы распространения данных выборки на всю генеральную совокупность




![]()
![]()
Для формирования выборочной совокупности применяются различные способы отбора .
1. Отбор, при котором генеральная совокупность не разбивается на части:
1) простой случайный повторный отбор . Он характеризуется следующими чертами:
а) отбор единиц выборочной совокупности производится из всей генеральной совокупности;
б) отбор носит случайный характер;
в) единицы генеральной совокупности, попавшие в выборочную совокупность, вновь возвращаются в генеральную совокупность после изучения;
2) простой случайный бесповторный отбор . Он характеризуется следующими чертами:
а) отбор единиц выборочной совокупности производится из всей генеральной совокупности;
б) отбор носит случайный характер;
в) единицы генеральной совокупности после об следования не возвращаются в генеральную совокупность.
В случае применения простого случайного отбора все единицы генеральной совокупности имеют одинаковую вероятность попасть в выборочную совокупность.
2. Отбор, при котором генеральная совокупность разбивается на части:
1) типический отбор , характеризующийся следующими чертами:
а) вся генеральная совокупность разбивается на типически однородные группы или части;
б) отбор единиц производится не из всей генеральной совокупности, а из отдельных типичных групп либо механически, либо случайно.
При типическом способе отбора в выборочную совокупность попадают все представители типических групп, что обеспечивает большую репрезентативность и точность полученных результатов. Одной из предпосылок применения типического отбора являются большое разнообразие генеральной совокупности и ее элементов и значительная неоднородность изучаемых при этом признаков. Его применение связано со сложными социально‑экономическими явлениями. Типический отбор является достаточно дорогим, но самым точным способом отбора;
2) серийный отбор, характеризующийся следующими чертами:
а) вся генеральная совокупность разбивается на части (серии или гнезда);
б) отбор единиц генеральной совокупности производится целыми сериями;
в) наблюдению подвергаются все без исключения единицы отобранной серии;
г) отбор носит случайный характер; Серийный отбор является менее точным способом отбора, однако его легче организовать;
3) механический отбор, который характеризует ся следующими чертами:
а) отбор осуществляется из всей генеральной совокупности;
б) отбор производится по механическому принципу (по списку, в шахматном порядке, по географическому признаку, в порядке убывания или возрастания).
Механический отбор является более точным, чем случайный, однако уступает типическому отбору.
На практике также часто применяется комбинированный отбор , при котором сочетаются указанные выше способы отбора.
Существуют два способа распространения данных выборочной совокупности на всю генеральную совокупность:
1) прямой, или способ прямого счета;
2) косвенный, или способ поправочных коэффициентов. При первом способе показатели, найденные посредством выборки (выборочная средняя или выборочная доля) умножаются на число единиц генеральной совокупности.
Второй способ применяется в целях проверки и уточнения данных сплошного наблюдения. В этом случае сопоставляют по соответствующим объектам данные выборочного наблюдения со сплошным, исчисляют поправочный коэффициент, которым и пользуются для внесения поправок в материалы сплошного наблюдения.
Источник
Отбор признаков в задачах машинного обучения. Часть 1
Часто наборы данных, с которыми приходится работать, содержат большое количество признаков, число которых может достигать нескольких сотен и даже тысяч. При построении модели машинного обучения не всегда понятно, какие из признаков действительно для неё важны (т.е. имеют связь с целевой переменной), а какие являются избыточными (или шумовыми). Удаление избыточных признаков позволяет лучше понять данные, а также сократить время настройки модели, улучшить её точность и облегчить интерпретируемость. Иногда эта задача и вовсе может быть самой значимой, например, нахождение оптимального набора признаков может помочь расшифровать механизмы, лежащие в основе исследуемой проблемы. Это может быть полезным для разработки различных методик, например, банковского скоринга, поиска фрода или медицинских диагностических тестов. Методы отбора признаков обычно делят на 3 категории: фильтры (filter methods), встроенные методы (embedded methods) и обёртки (wrapper methods). Выбор подходящего метода не всегда очевиден и зависит от задачи и имеющихся данных. Цель настоящего цикла статей — провести краткий обзор некоторых популярных методов отбора признаков с обсуждением их достоинств, недостатков и особенностей реализации. Первая часть посвещена фильтрам и встроенным методам.
1. Методы фильтрации
Методы фильтрации применяются до обучения модели и, как правило, имеют низкую стоимость вычислений. К ним можно отнести визуальный анализ (например, удаление признака, у которого только одно значение, или большинство значений пропущено), оценку признаков с помощью какого-нибудь статистического критерия (дисперсии, корреляции, X 2 и др.) и экспертную оценку (удаление признаков, которые не подходят по смыслу, или признаков с некорректными значениями).
Простейшим способом оценки пригодности признаков является разведочный анализ данных (например, с библиотекой pandas-profiling). Эту задачу можно автоматизировать с помощью библиотеки feature-selector, которая отбирает признаки по следующим параметрам:
Количество пропущенных значений (удаляются признаки у которых процент пропущенных значений больше порогового).
Коэффициент корреляции (удаляются признаки, у которых коэффициент корреляции больше порогового).
Вариативность (удаляются признаки, состоящие из одного значения).
Оценка важности признаков с помощью lightgbm (удаляются признаки, имеющие низкую важность в модели lightgbm. Следует применять только если lightgbm имеет хорошую точность.)
Туториал по этой библиотеке находится здесь.
Более сложные методы автоматического отбора признаков реализованы в sklearn. VarianceThreshold отбирает признаки, у которых дисперсия меньше заданного значения. SelectKBest и SelectPercentile оценивают взаимосвязь предикторов с целевой переменной используя статистические тесты, позволяя отобрать соответственно заданное количество и долю наилучших по заданному критерию признаков. В качестве статистических тестов используются F-тест,
и взаимная информация.
F-тест
F-тест оценивает степень линейной зависимости между предикторами и целевой переменной, поэтому он лучше всего подойдёт для линейных моделей. Реализован в sklearn как f_regression и f_classif соответственно для регрессии и классификации.
Этот тест используется в задах классификации и оценивает зависимость между признаками и классами целевой пременной. Описание метода приведено здесьи здесь (для sklearn). Стоит отметить, что этот тип тестов требует неотрицательных и правильно отмасштабированных признаков.
Взаимная информация
Взаимная информация показывает насколько чётко определена целевая переменная если известны значения предиктора (подробнее здесь и здесь). Этот тип тестов считается самым удобным в использовании — он хорошо работает «из коробки» и позволяет находить нелинейные зависимости. Реализован в sklearn как mutual_info_regression и mutual_info_classif соответственно для регрессии и классификации.
2. Встроенные методы
Встроенные методы выполняют отбор признаков во время обучения модели, оптимизируя их набор для достижения лучшей точности. К этим методам можно отнести регуляризацию в линейных моделях (обычно L1) и расчёт важности признаков в алгоритмах с деревьями (который хорошо разобран здесь). Отметим, что для линейных моделей требуется масштабирование и нормализация данных.
Пример
Рассмотрим применение описанных выше методов в реальной задаче – предсказать, зарабатывает ли человек больше $50 тыс. Загрузим библиотеки и данные, для удобства оставив только численные признаки:
fnlwgt (final weight) – примерная оценка количества людей, которое представляет каждая строка данных
educational-num – длительность обучения
capital-gain – прирост капитала
capital-loss – потеря капитала
hours-per-week – количество рабочих часов в неделю
Источник
Виды, методы и способы отбора
Выборочная совокупность будет полно и адекватно отражать свойства генеральной совокупности в том случае, если она будет репрезентативной (представительной). Репрезентативность выборки зависит от применяемых видов, методов и способов отбора единиц.
Достоверность результатов наблюдения достигается за счет соблюдения основного принципа выборочного наблюдения: обеспечение случайности отбора единиц (равная возможность единиц попасть в выборку)
В теории выборочного наблюдения разработаны различные виды, методы и способы отбора единиц из генеральной совокупности.
Различают два вида отбора единиц в выборочную совокупность: повторный и бесповторный.
При повторном отбореотобранная единица подвергается обследованию, возвращается в генеральную совокупность и снова может быть выбранной («схема возвратного шара»). В результате вероятность попадания отдельной единицы в выборку не меняется независимо от числа отобранных единиц. На практике такой отбор применяется, когда объем генеральной совокупности не известен и теоретически возможно повторение единиц с уже встречавшимися значениями регистрируемых признаков (например, в маркетинговых исследованиях). В социально-экономических исследованиях повторный отбор встречается редко.
При бесповторном отбореотобранная единица подвергается обследованию и в дальнейшей процедуре отбора не участвует («схема безвозвратного шара»). Тем самым, вероятность попасть в выборку для оставшихся единиц увеличивается с каждым шагом отбора. Такой вид отбора практически возможен, когда объем генеральной совокупности четко определен.
В ходе выборочного наблюдения могут применяться следующие способы отбора единиц из генеральной совокупности:
§ индивидуальный отбор — в выборку отбираются отдельные единицы совокупности;
§ групповой отбор — в выборку попадают качественно однородные группы или серии единиц;
§ комбинированный отбор – сочетание индивидуального и группового способов отбора.
Выборочная совокупность может быть сформирована с помощью следующих методов отбораединиц:
1. случайный (собственно-случайный);
3. типический (расслоенный, стратифицированный);
4. серийный (гнездовой);
Приведем краткую характеристику этих методов отбора единиц.
Собственно-случайный (случайный) отбор – индивидуальный отбор единиц, каждой из которых присвоен порядковый номер, с помощью жеребьевки или таблицы случайных чисел (Приложение 3). Генеральная совокупность предварительно не разделяется на какие-либо группы. Условием репрезентативности выборки служит принцип случайности (равная возможность каждой единицы попасть в выборку). Собственно-случайная выборка может осуществляться по схемам повторного и бесповторного обора (например, проведение тиражей денежно-вещевой лотереи).
Механический отбор – отбор из предварительно упорядоченной и разбитой на равные интервалы (группы) генеральной совокупности. Размер интервала равен обратной величине доли выборки. Например, при 5 % — ной выборке отбирается каждая 20-я единица (1/0,05), при 10 %-ной выборке — каждая 10-я единица (1/0,1) и т.д. В результате, генеральная совокупность как бы механически разбивается на равновеликие группы. Из каждой группы в выборку отбирается лишь одна единица. При этом отбор начинается не с первой единицы совокупности, а с середины первого интервала. Для обеспечения репрезентативности все единицы генеральной совокупности должны располагаться в определенном порядке. Механический отбор всегда бывает бесповторным. Он имеет преимущество перед случайным отбором, т.к. его легче организовать.
Типический отбор(расслоенный, стратифицированный) – неоднородная генеральная совокупность вначале разбивается на качественно однородные типические группы (не обязательно равные). Затем из каждой группы производится индивидуальный отбор случайным или механическим методом. Типическая выборка применяется при изучении сложных статистических совокупностей и дает более точные результаты по сравнению с другими методами отбора. В частности, случайная ошибка при типическом отборе меньше, чем при собственно-случайном и механическом отборе. Это объясняется тем, что имевшееся соотношение между группами единиц генеральной совокупности, сохраняется и в выборочной совокупности. Типический отбор бывает повторным и бесповторным.
Из каждой типической группы в выборочную совокупность можно отбирать определенное число единиц с помощью следующих разновидностей типического отбора:
1. пропорциональный типический отбор – число единиц выборки n пропорционально удельному весу каждой группы в генеральной совокупности: 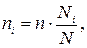
где:  — объем выборки из
— объем выборки из  — ой типической группы;
— ой типической группы;
 — объем — ой типической группы в генеральной совокупности.
— объем — ой типической группы в генеральной совокупности.
2. непропорциональный типический отбор — число единиц выборки непропорционально удельному весу каждой группы в генеральной совокупности:
 ,
,
где  — число выделенных типических групп.
— число выделенных типических групп.
3. отбор с учетом вариации признака -число единиц выборки пропорционально удельному весу в генеральной совокупности с учетом вариации признака по группам:
— для средней  , где
, где  — среднее квадратическое отклонение i – й группы;
— среднее квадратическое отклонение i – й группы;
— для доли 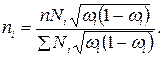
Серийный (гнездовой)отбор – это отбор, при котором в случайном порядке отбираются не отдельные единицы, а целые группы единиц (серии, гнезда), которые подвергаются сплошному наблюдению. Отбор отдельных серий осуществляется на основе случайного или механического метода. Серийный отбор применяется в том случае, если генеральная совокупность разбита на группы еще до начала выборочного наблюдения. На практике чаще применяется бесповторный отбор с равными сериями. Ошибка серийной выборки больше, чем при другом методе отбора. Но серийный отбор обладает организационными преимуществами, поэтому довольно часто применяется на практике. Серийную выборку применяют в двух случаях: 1) все серии имеют одинаковое количество единиц; 2) серии различны по объему. Серийный отбор обеспечивает экономию средств, если обследования распространяются на обширную территорию и гнездами являются территориальные единицы.
В рассмотренных выше методах осуществлялся одноступенчатый и многоступенчатый отбор единиц в выборочную совокупность.
При одноступенчатой выборке каждая отобранная единица сразу же подвергается изучению по заданному признаку (собственно-случайный и серийный отбор).
При многоступенчатой выборке применяется несколько стадий (ступеней) отбора. Производят отбор отдельных групп из генеральной совокупности, затем из групп выбираются отдельные единицы (механический отбор). При этом каждая стадия имеет свою единицу отбора. Число ступеней определяется числом типов единиц отбора. Например, на последней ступени единица отбора совпадает с единицей выборки. Ошибка всей выборки складывается из ошибок на отдельных ступенях отбора.
При построении многоступенчатой выборки используется комбинация разных методов отбора, поэтому такой метод отбора иногда называют комбинированной выборкой.
От многоступенчатого отбора следует отличать многофазный отбор. В отличие от многоступенчатого отбора, он предполагает сохранение одной и той же единицы отбора на всех этапах его проведения. При этом отобранные на каждой стадии единицы подвергаются обследованию по более широкой программе. Многофазная выборка используется для расширения программы обследования.
Особым видом выборочного наблюдения явления моментное наблюдение, т.е. выборочное наблюдение во времени. При этом все единицы изучаемой совокупности подлежат сплошному учету: объектами выборки служат отрезки времени. Поэтому понятия генеральной и выборочной совокупности относятся не к совокупности единиц, а ко времени наблюдения.
Ошибки выборки
Выборочное наблюдение носит несплошной характер, поэтому оно сопровождается ошибками (погрешностями).
Ошибки выборочного наблюдения возникают в двух случаях: 1. при сборе данных (ошибки регистрации); 2. в результате неполного учета единиц генеральной совокупности (ошибки репрезентативности).
Таким образом, любому выборочному наблюдению свойственна ошибка репрезентативности — расхождение между характеристиками выборочной и генеральной совокупности (рис 7.1).
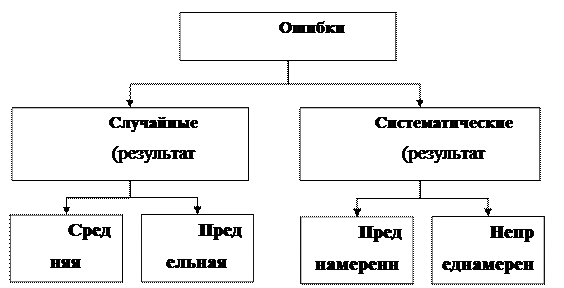
Рис 7.1. Виды ошибок репрезентативности
Ошибка репрезентативности возникает в результате того, что выборочная совокупность не полностью отражает закономерности, присущие генеральной совокупности. Величина случайной ошибки репрезентативности зависит:
1) от объема выборки;
2) от степени вариации признака в генеральной совокупности;
3) от метода отбора единиц и т.д.
По данным выборочной совокупности оценивают показатели (параметры) генеральной совокупности. Например, используют оценку 2-х параметров:
— генеральной средней величины изучаемого признака (для количественного признака);
— генеральной доли (для альтернативного признака).
Теоретическое обоснование появления случайных ошибок выборки объясняют предельные теоремы теории вероятностей. Так как случайная ошибка выборки возникает в результате случайных различий между границами выборочной и генеральной совокупностей, то при достаточно большом объеме выборки эта ошибка будет сколь угодно мала. Поэтому характеристики выборки могут достаточно хорошо представлять характеристики генеральной совокупности. Случайные ошибки могут быть доведены до незначительных размеров, что позволит определить их размеры и пределы с достаточной степенью точности на основании закона больших чисел.
Выборочное распределение средней величины будет приближаться к нормальному распределению по мере увеличения объема выборки  , независимо от характера распределения генеральной совокупности. С увеличением численности выборки величина выборочной средней
, независимо от характера распределения генеральной совокупности. С увеличением численности выборки величина выборочной средней 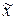 приближается к генеральной средней
приближается к генеральной средней  .
.
Одной из задач выборочного метода является определение ошибок выборки, т.е. возможных расхождений характеристик совокупностей:
1) между выборочной средней (  )и генеральной средней ( );
)и генеральной средней ( );
2) между выборочной долей единиц  , обладающих изучаемым признаком, и генеральной долей (р).
, обладающих изучаемым признаком, и генеральной долей (р).
Методы математической статистики позволяют измерить эти ошибки и указать границы их колеблемости. Величину ошибок можно оценить по формулам:
 ;
;  .
.
В статистике различают три вида ошибок выборки:
— средняя ошибка  ;
;
— предельная ошибка  ;
;
— относительная ошибка  .
.
Вид формулы средней ошибки выборки зависит от метода отбора. Рассмотрим порядок расчета ошибок выборки при собственно-случайном отборе.
Средняя ошибка выборки —характеризует среднюю величину возможных расхождений выборочных (средняя , доля  ) и генеральных характеристик (средняя , доля
) и генеральных характеристик (средняя , доля 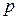 ) совокупности. Представляет собой среднее квадратическое отклонение возможных значений характеристик выборочной совокупности от характеристик генеральной совокупности.
) совокупности. Представляет собой среднее квадратическое отклонение возможных значений характеристик выборочной совокупности от характеристик генеральной совокупности.
Рассмотрим формулы средней ошибки выборки длясредней и долипри повторном и бесповторном отборе:
1. При повторном отборе:
1.1. Средняя ошибка выборочной средней  :
:

1.2. Средняя ошибка выборочной доли  :
:

2. При бесповторном отборе:
2.1. Средняя ошибка выборочной средней :

2.2. Средняя ошибка выборочной доли :
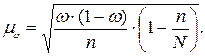
где  — дисперсия признака в генеральной совокупности;
— дисперсия признака в генеральной совокупности;
— объем выборки;
— выборочная доля единиц, обладающих изучаемым признаком;  дисперсия доли (альтернативного признака).
дисперсия доли (альтернативного признака).
Замечание. На практике величина дисперсии признака в генеральной совокупности  , как правило, неизвестна. Поэтому в формулы ошибки выборки подставляют дисперсию выборочной совокупности
, как правило, неизвестна. Поэтому в формулы ошибки выборки подставляют дисперсию выборочной совокупности  . Это возможно, поскольку между дисперсиями генеральной и выборочной совокупностей существует следующая взаимосвязь:
. Это возможно, поскольку между дисперсиями генеральной и выборочной совокупностей существует следующая взаимосвязь:
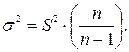
При большой численности выборочной совокупности сомножитель  стремится к единице, и выборочная дисперсия практически совпадает с генеральной , т.е.
стремится к единице, и выборочная дисперсия практически совпадает с генеральной , т.е.  .
.
Замечание. Поскольку при бесповторном отборе в ходе выборки объем генеральной совокупности  сокращается, то в формулу для расчета средней ошибки включают дополнительный множитель
сокращается, то в формулу для расчета средней ошибки включают дополнительный множитель 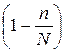 .
.
Средняя ошибка выборки при собственно-случайном повторном отборе зависит от:
— объема выборки (обратная зависимость);
— степени вариации признака (прямая зависимость).
Чем больше вариация признака, тем больше ошибка выборки. Для ее уменьшения необходимо увеличить объем выборочной совокупности.
Формулы расчета средних ошибок  для различных методов отбора приведены в табл. 7.2.
для различных методов отбора приведены в табл. 7.2.
Таблица 7.2
Формулы средних ошибок для различных методов отбора
| Метод отбора | Оцениваемый параметр | Вид отбора | |
| повторный | бесповторный | ||
| Собственно-случайный и механический | средняя | 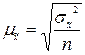 |  |
| доля |  |  | |
| Типический (пропорциональный) | средняя |  | 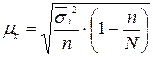 |
| доля | 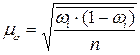 | 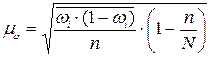 | |
| Серийный | средняя |  |  |
| доля |  |  | |
| Комбинированный: — типический и серийный — собственно-случайный и серийный | cредняя |  |  |
| cредняя |  |  |
Условные обозначения в таблице:
 — средняя из групповых дисперсий;
— средняя из групповых дисперсий;
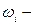 доля единиц i-й типической группы (серии) выборки, обладающих изучаемым признаком;
доля единиц i-й типической группы (серии) выборки, обладающих изучаемым признаком;
 — средняя из групповых дисперсий для доли.
— средняя из групповых дисперсий для доли.
М, m – количество равных серий соответственно в генеральной и выборочной совокупностях;
 — межгрупповая выборочная дисперсия,
— межгрупповая выборочная дисперсия,
где 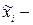 средняя в i-й серии;
средняя в i-й серии; 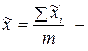 общая выборочная средняя;
общая выборочная средняя;
 — межгрупповая выборочная дисперсия доли, где
— межгрупповая выборочная дисперсия доли, где  — доля единиц, обладающих признаком в выборке. При равновеликих сериях
— доля единиц, обладающих признаком в выборке. При равновеликих сериях 

Следует иметь в виду, что в каждой конкретной выборке разность 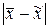 может быть меньше, больше или равна величине средней ошибки . Вероятность такой ошибки различна. Поэтому рассчитывают предельную ошибку выборки .
может быть меньше, больше или равна величине средней ошибки . Вероятность такой ошибки различна. Поэтому рассчитывают предельную ошибку выборки .
Предельная ошибка выборки — это максимально возможное расхождение характеристик выборочной (средняя , доля ) и генеральной совокупности (средняя , доля ), т.е. максимум ошибки при заданной вероятности ее появления.
Величина предельной ошибки определяется по формуле:

где  — коэффициент доверия, который определяется по таблице значений интеграла Лапласа при заданной доверительной вероятности
— коэффициент доверия, который определяется по таблице значений интеграла Лапласа при заданной доверительной вероятности  Он показывает, во сколько раз предельная ошибка выборки отличается от средней ошибки.
Он показывает, во сколько раз предельная ошибка выборки отличается от средней ошибки.
Соответственно, формулы предельной ошибки для средней и доли , имеют вид:


Значения интеграла Лапласа табулированы в зависимости от значений коэффициента (Приложение 2). Поэтому на практике пользуются готовыми таблицами значений. Приведем наиболее часто употребляемые уровни доверительной вероятности  и соответствующие им значения :
и соответствующие им значения :
| | 1,0 | 1,96 | 2,0 | 2,58 | 3,0 |
| | 0,683 | 0,950 | 0,954 | 0,990 | 0,997 |
Таким образом, предельная ошибка выборки отвечает на вопрос о точности выборки с определенной вероятностью, величина которой зависит от значения коэффициента доверия t.
Например, при t = 1 с вероятностью 0,683 можно утверждать, что расхождение между выборочными и генеральными характеристиками не превысит одной величины средней ошибки выборки, т.е. 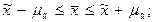
При t = 2 вероятность =0,954, значит, в среднем 954 выборки из 1000 дадут показатели выборки (средняя , доля ), которые будут отличаться от генеральных показателей (средняя , доля ) не более чем на величину двукратной средней ошибки выборки, т.е.  или
или 
Появление ошибки в три раза большей, чем средняя ошибка выборки, маловероятно (1-0,997=0,003), и считается практически невозможным событием.
Пределы, в которых с данной вероятностью будет находиться неизвестная величина изучаемого показателя генеральной совокупности, называют доверительным интервалом, а вероятность — доверительной вероятностью.
В качестве доверительной вероятности обычно принимают значения вероятностей Р и соответствующие им уровни значимости  (табл. 7.3)
(табл. 7.3)
Таблица 7.3
Соотношение между значениями доверительной вероятности 
и уровнями значимости 
| Вероятность | Уровень значимости |
| 0,90 | 0,10, или 10 % |
| 0,95 | 0,05, или 5 % |
| 0,99 | 0,01, или 1 % |
Например, 10 %-ный уровень значимости означает, что в 90 случаях из 100 характеристика генеральной совокупности, выявленная на основе выборки, будет лежать в пределах доверительного интервала. То есть, в 10 случаях из 100 существует риск совершить ошибку по выборочным данным при оценке генеральной совокупности.
Очевидно, что чем больше значение предельной ошибки , тем больше величина доверительного интервала, т.е. ниже точность оценки.
Формулы предельной ошибки позволяют определить:
§ доверительные интервалы, в которых будут находиться значения генеральных параметров:
— генеральная средняя: 
— генеральная доля: 
§ необходимую численность выборки , обеспечивающую с определенной вероятностью заданную точность наблюдения ( );
§ вероятность допуска той или иной заданный ошибки (определяется  и находится вероятность).
и находится вероятность).
Наряду с абсолютной величиной предельной ошибки выборки рассчитывают и относительную ошибку выборки  .Она определяетсякак процентное отношение предельной ошибки выборки к соответствующей характеристике выборочной совокупности (средняя , доля ):
.Она определяетсякак процентное отношение предельной ошибки выборки к соответствующей характеристике выборочной совокупности (средняя , доля ):
§ для средней  =
= 
§ для доли 
Выборка считается репрезентативной, если 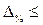 5 %.
5 %.
Пример.В порядке случайной бесповторной выборки было обследовано n = 160 турфирм из N = 1500, и получены следующие данные об их объеме продаж за отчетный период (табл. 7.4).
Источник



