
- Система управления базами данных SQLite. Изучаем язык запросов SQL и реляционные базы данных на примере библиотекой SQLite3. Курс для начинающих.
- Часть 3.2: Виды связей между таблицами в базе данных. Связи в реляционных базах данных. Отношения, кортежи, атрибуты
- Термины кортеж, атрибут и отношение в реляционных базах данных
- Виды и типы связей между таблицами в реляционных базах данных
- Реализация связи один ко многим в теории баз данных
- Связь многие ко многим
- Связь один к одному
- Системы управления базами данных¶
- Основные функции СУБД¶
- Классификации СУБД¶
- По модели данных¶
- Иерархические¶
- Сетевые¶
- Реляционные¶
- Объектно-ориентированные¶
- Объектно-реляционные¶
- По степени распределённости¶
- По способу доступа к БД¶
- Файл-серверные¶
- Клиент-серверные¶
- Встраиваемые¶
- Стратегии работы с внешней памятью¶
- СУБД: Способы организации
- Содержание
- Файл-серверные
- Клиент-серверные
- Встраиваемые
Система управления базами данных SQLite. Изучаем язык запросов SQL и реляционные базы данных на примере библиотекой SQLite3. Курс для начинающих.
Часть 3.2: Виды связей между таблицами в базе данных. Связи в реляционных базах данных. Отношения, кортежи, атрибуты
Здравствуйте, уважаемые посетители сайта ZametkiNaPolyah.ru. Продолжаем изучать базы данных и наше знакомство с библиотекой SQLite3. Продолжаем изучать теорию реляционных баз данных и в этой части мы познакомимся с видами и типами связей между таблицами в реляционных базах данных. Так же мы познакомимся с такими термина, как: кортеж, атрибут и отношения. Данная тема является базовой и ее понимание необходимо для работы с базами данных и для их проектирования.

Виды связей между таблицами в базе данных. Связи в реляционных базах данных. Отношения, кортежи, атрибуты.
Сразу скажу, что связей между таблицами в реляционной базе данных всего три. Поэтому их изучение, понимание и восприятие пройдет быстро, легко и безболезненно. Приступим к изучению.
Термины кортеж, атрибут и отношение в реляционных базах данных
В своей публикации я буду стараться объяснять теорию баз данных не с математической точки зрения, а на примерах. Грубо говоря, на пальцах. Во-первых, практические примеры позволяют легче усваивать материал. Во-вторых, с математической теорией проще разобраться, когда понимаешь суть происходящего.
Давайте разбираться с тем, что такое: отношение, кортеж, атрибут в реляционной базе данных.
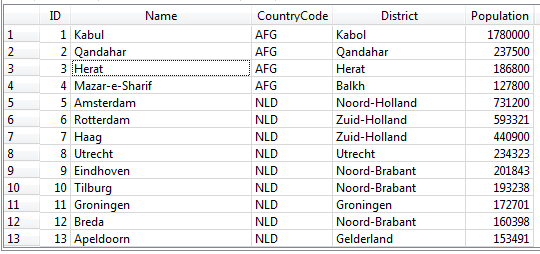
Таблица с данными из базы данных World
У нас есть простая таблица City из базы данных World, в которой есть строки и столбцы. Но термины: таблица, строка, столбец – это термины стандарта SQL.
Кстати: ни одна из существующих в мире СУБД не имеет полной поддержки того или иного стандарта SQL, но и ни один стандарт SQL полностью не реализует математику реляционных баз данных.
В терминологии реляционных баз данных: таблица – это отношение (принимается такое допущение), строка – это кортеж, а столбец – атрибут. Иногда вы можете услышать, как некоторые разработчики называют строки записями. Чтобы не было путаницы в дальнейшем предлагаю использовать термины SQL.
Если рассматривать таблицу, как объект (например книга), то столбец – это характеристики объекта, а строки содержат информацию об объекте.
Виды и типы связей между таблицами в реляционных базах данных
Давайте теперь рассмотрим то, как могут быть связаны таблицы в реляционных базах данных. Сразу скажу, что всего существует три вида связей между таблицами баз данных:
• связь один к одному;
• связь один ко многим;
• связь многие ко многим.
Рассмотрим, как такие связи между таблицами могут быть реализованы в реляционных базах данных.
Реализация связи один ко многим в теории баз данных
Связь один ко многим в реляционных базах данных реализуется тогда, когда объекту А может принадлежать или же соответствовать несколько объектов Б, но объекту Б может соответствовать только один объект А. Не совсем понятно, поэтому смотрим пример ниже.
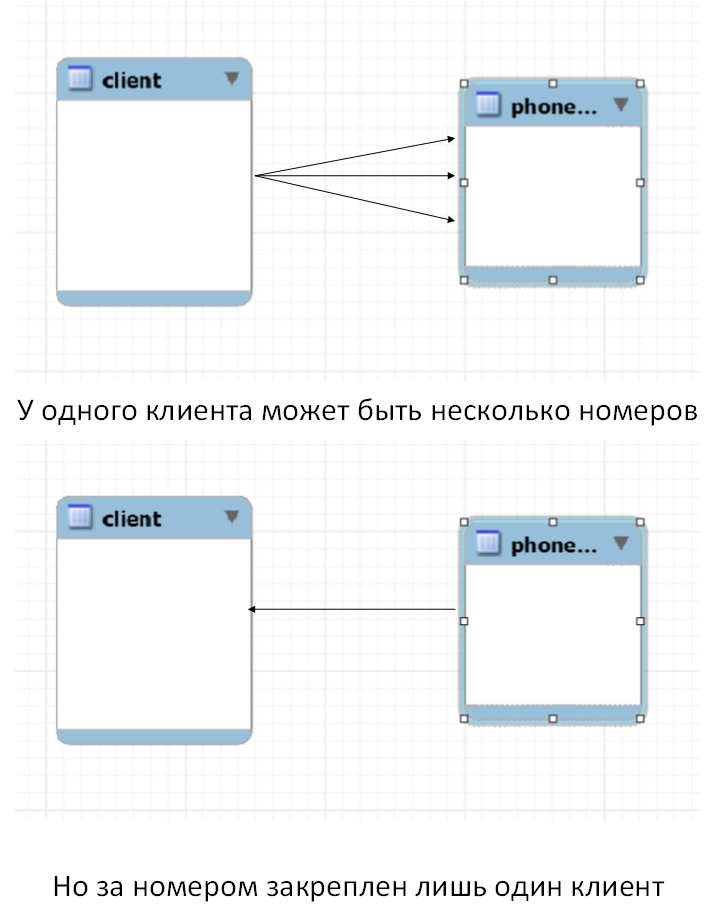
Реализация связи один ко многим в реляционных базах данных
У нас есть таблица, в которой содержатся данные о клиентах и у нас есть таблица, в которой хранятся их телефоны. Мы можем смело утверждать, что у одного клиента может быть несколько телефонов, но в тоже время мы можем быть уверены в том, что один конкретный номер может быть только у одного клиента. Это типичный пример связи один ко многим.
Связь многие ко многим
Связь многие ко многим реализуется в том случае, когда нескольким объектам из таблицы А может соответствовать несколько объектов из таблицы Б, и в тоже время нескольким объектам из таблицы Б соответствует несколько объектов из таблицы А. Рассмотрим простой пример.
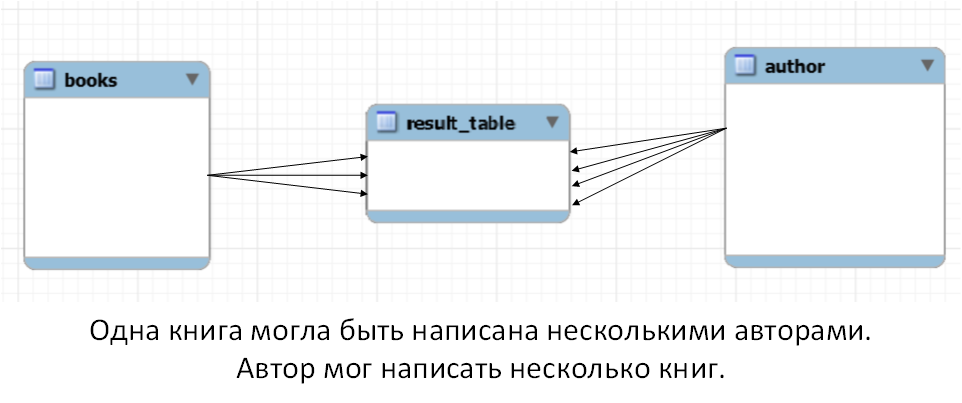
Пример связи многие ко многим
У нас есть таблица с книгами и есть таблица с авторами. Приведу два верных утверждения. Первое: одну книгу может написать несколько авторов. Второе: автор может написать несколько книг. Здесь мы наблюдаем типичную ситуацию, когда связь между таблицами многие ко многим. Такая связь (связь многие ко многим) реализуется путем добавления третьей таблицы.
Связь один к одному
Связь один к одному – самая редко встречаемая связь между таблицами. В 97 случаях из 100, если вы видите такую связь, вам необходимо объединить две таблицы в одну.
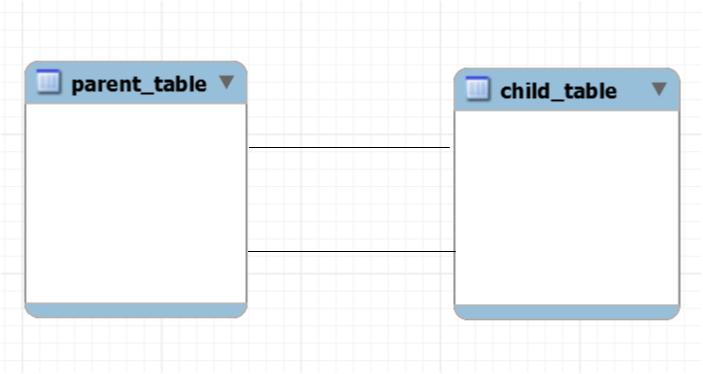
Пример связи один к одному
Таблицы будут связаны один к одному тогда, когда одному объекту таблицы А соответствует один объект таблицы Б, и одному объекту таблицы Б соответствует один объект таблицы А. Как я уже говорил: если вы видите, что связь один к одному – смело объединяйте таблицы в одну, за исключением тех случаев, когда происходит модернизация базы данных.
Например, у нас была таблица, в которой хранились данные о сотрудниках компании. Но произошли какие-то изменения в бизнес-процессе и появилась необходимость создать таблицы с теми же самыми сотрудниками, но не для всей компании, а разбив их по отделам. Таблицы отделов будут дочерними по отношению к таблице, в которой хранятся данные обо всех сотрудниках компании, и связаны такие таблицы будут связью один к одному.
Мы рассмотрели все виды связей между таблицами и то, как они реализуются в базах данных. В дальнейшем, когда мы начнем создавать свои базы данных, информация о видах связи между таблицами нам очень поможет.
Источник
Системы управления базами данных¶
Система управления базами данных (СУБД) — совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
Основные функции СУБД¶
- управление данными во внешней памяти (на дисках);
- управление данными в оперативной памяти с использованием дискового кэша;
- журнализация изменений, резервное копирование и восстановление базы данных после сбоев;
- поддержка языков БД (язык определения данных, язык манипулирования данными).
Обычно современная СУБД содержит следующие компоненты:
- ядро, которое отвечает за управление данными во внешней и оперативной памяти и журнализацию,
- процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода,
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД
- а также сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
Классификации СУБД¶
По модели данных¶
Иерархические¶
Используется представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами (в программировании применительно к структуре данных дерево устоялось название братья).
Иерархической базой данных является файловая система, состоящая из корневого каталога, в котором имеется иерархия подкаталогов и файлов.
Примеры: Caché, Google App Engine Datastore API.
Сетевые¶
Сетевые базы данных подобны иерархическим, за исключением того, что в них имеются указатели в обоих направлениях, которые соединяют родственную информацию.
Реляционные¶
Практически все разработчики современных приложений, предусматривающих связь с системами баз данных, ориентируются на реляционные СУБД. По оценке Gartner в 2013 году рынок реляционных СУБД составлял 26 млрд долларов с годовым приростом около 9%, а к 2018 году рынок реляционных СУБД достигнет 40 млрд долларов. В настоящее время абсолютными лидерами рынка СУБД являются компании Oracle, IBM и Microsoft, с общей совокупной долей рынка около 90%, поставляя такие системы как Oracle Database, IBM DB2 и Microsoft SQL Server.
Объектно-ориентированные¶
Управляют базами данных, в которых данные моделируются в виде объектов, их атрибутов, методов и классов.
Этот вид СУБД позволяет работать с объектами баз данных так же, как с объектами в программировании в объектно-ориентированных языках программирования. ООСУБД расширяет языки программирования, прозрачно вводя долговременные данные, управление параллелизмом, восстановление данных, ассоциированные запросы и другие возможности.
Объектно-реляционные¶
Этот тип СУБД позволяет через расширенные структуры баз данных и язык запросов использовать возможности объектно-ориентированного подхода: бъекты, классы и наследование.
Зачастую все те СУБД, которые называются реляционными, являются, по факту, объектно-реляционными.
В данном курсе мы будем, в первую очередь, гооврить об этом виде СУБД.
Примеры: PostgreSQL, DB2, Oracle, Microsoft SQL Server.
По степени распределённости¶
- Локальные СУБД (все части локальной СУБД размещаются на одном компьютере)
- Распределённые СУБД (части СУБД могут размещаться на двух и более компьютерах).
По способу доступа к БД¶
Файл-серверные¶
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. СУБД располагается на каждом клиентском компьютере (рабочей станции). Доступ СУБД к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на процессор файлового сервера. Недостатки: потенциально высокая загрузка локальной сети; затруднённость или невозможность централизованного управления; затруднённость или невозможность обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность. Применяются чаще всего в локальных приложениях, которые используют функции управления БД; в системах с низкой интенсивностью обработки данных и низкими пиковыми нагрузками на БД.
На данный момент файл-серверная технология считается устаревшей, а её использование в крупных информационных системах — недостатком.
Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.
Клиент-серверные¶
Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет доступ к БД непосредственно, в монопольном режиме. Все клиентские запросы на обработку данных обрабатываются клиент-серверной СУБД централизованно. Недостаток клиент-серверных СУБД состоит в повышенных требованиях к серверу. Достоинства: потенциально более низкая загрузка локальной сети; удобство централизованного управления; удобство обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность.
Примеры: Oracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQL, Caché, ЛИНТЕР.
Встраиваемые¶
Встраиваемая СУБД — СУБД, которая может поставляться как составная часть некоторого программного продукта, не требуя процедуры самостоятельной установки. Встраиваемая СУБД предназначена для локального хранения данных своего приложения и не рассчитана на коллективное использование в сети. Физически встраиваемая СУБД чаще всего реализована в виде подключаемой библиотеки. Доступ к данным со стороны приложения может происходить через SQL либо через специальные программные интерфейсы (API).
Примеры: OpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server Compact, ЛИНТЕР.
Стратегии работы с внешней памятью¶
СУБД с непосредственной записью — это СУБД, в которых все измененные блоки данных незамедлительно записываются во внешнюю память при поступлении сигнала подтверждения любой транзакции. Такая стратегия используется только при высокой эффективности внешней памяти.
СУБД с отложенной записью — это СУБД, в которых изменения аккумулируются в буферах внешней памяти до наступления любого из следующих событий:
- контрольной точки;
- конец пространства во внешней памяти, отведенное под журнал. СУБД выполняет контрольную точку и начинает писать журнал сначала, затирая предыдущую информацию;
- останов. СУБД ждёт, когда всё содержимое всех буферов внешней памяти будет перенесено во внешнюю память, после чего делает отметки, что останов базы данных выполнен корректно;
- при нехватке оперативной памяти для буферов внешней памяти.
Такая стратегия позволяет избежать частого обмена с внешней памятью и значительно увеличить эффективность работы СУБД.
Источник
СУБД: Способы организации
Системы управления базами данных классифицируются по способам организации. Различают три способа размещения СУБД.
Каталог СУБД-решений и проектов доступен на TAdviser.
Содержание
Файл-серверные
При работе с файл-серверной системой обработка всех данных происходит на рабочих местах, а сервер используется только как разделяемый накопитель. Каждый пользователь непосредственно использует информацию и вносит изменения в файлы данных и в индексные файлы. При больших объемах данных и работе во многопользовательском режиме существенно снижается быстродействие — ведь чем больше пользователей, тем выше требования к разделению данных. Кроме того, может возникнуть повреждение баз данных. Например, в момент записи в файл может возникнуть сбой сети или авария питания. В этом случае компьютер пользователя прерывает работу, база данных может оказаться поврежденной, а индексный файл — разрушенным. Переиндексация, которую необходимо провести после подобных сбоев, может длиться несколько часов. Перечисленные недостатки заставляют пользователей, работающих в сети, отказаться от файл-серверных СУБД.
Клиент-серверные
При использовании клиент-серверного способа организации вся работа с базой данных происходит на сервере и не зависит от сбоев на рабочих станциях. Все запросы на запись в файл перехватываются сервером. В файл изменения вносятся только после того, как сервер получит сообщение о том, что корректировка файла завершена. Это исключает повреждение индексных файлов и существенно повышает быстродействие системы.
Клиент-серверные СУБД также имеют ряд недостатков:
- высокие требования к пропускной способности коммуникационных каналов с сервером;
- слабая защита данных от взлома, в особенности от недобросовестных пользователей системы;
- высокая сложность администрирования и настройки рабочих мест пользователей системы;
- необходимость использовать на клиентских местах достаточно мощные компьютеры;
- сложность интеграции с унаследованными системами;
- сложность разработки системы из-за необходимости исполнять бизнес-логику и обеспечивать интерфейс с пользователем в одной программе.
Среди клиент-серверных СУБД наиболее распространены такие продукты, как IBM DB2, MS SQL Server, Oracle, MySQL.
Встраиваемые
Встраиваемая система управления базой данных — это система, которая может быть связана с клиентским приложением таким образом, чтобы приложение и СУБД работали в едином адресном пространстве. Вместе со встроенной базой данных приложение может быть развернуто как единая программа, которая функциональна, эффективна и автономна. Благодаря связыванию приложения с базой данных, прикладная система выигрывает от снижения общей сложности и уменьшения затрат на администрирование. Во многих случаях встраиваемая система управления базой данных — самый подходящий вариант для систем с ограниченными ресурсами. Однако, встраиваемые СУБД зачастую подходят лишь для решения задач узкой спецификации.
Встраиваевыми являются такие СУБД, как InterBase SMP, BerkeleyDB, OpenEdge.
Источник



