
Страничный способ организации памяти




![]()
Сегментная, страничная и сегментно-страничная организация памяти
Сегментный способ организации памяти
Первым среди разрывных методов распределения памяти был сегментный. Естественным способом разбиения программы на части является разбиение её на логические элементы – т.н. сегменты. Каждый программный модуль может быть воспринят как отдельный сегмент.
Логически обращение к элементам программы в этом случае будет выглядеть как указание имени сегмента и смещения относительно начала этого сегмента. Физически имя (или порядковый номер) сегмента будет соответствовать некоторому адресу, с которого этот сегмент начинается при его размещении в памяти, и смещение должно прибавляться к этому базовому адресу.
Преобразование имени сегмента в его порядковый номер осуществляет система программирования. ОС размещает сегменты в память и для каждого сегмента получает информацию о его начале.
Каждый сегмент, помещаемый в память, имеет соответствующую информационную структуру, называемую дескриптором сегмента. Для любого исполняемого процесса ОС строит таблицу дескрипторов сегментов и с помощью бита присутствия отмечает для каждого сегмента его текущее местоположение. В дескрипторе сегмента, помимо указания его адреса, длины и бита присутствия, содержатся, как правило, данные о его типе (сегмент кода или данных), правах доступа (можно ли модифицировать, предоставлять другой задаче), отметка об обращениях к данному сегменту (как часто, давно или нет он использовался).
Достоинства сегментного метода:
· программу можно загружать не целиком, а по мере необходимости;
· некоторые программные модули могут быть разделяемыми – они являются сегментами, и к ним достаточно легко можно организовать доступ посредством помещения в дескрипторы сегментов указателей на такие разделяемые сегменты.
Недостатки сегментного метода:
· замедление доступа к требуемой ячейке памяти;
· потери памяти и процессорного времени на размещение и обработку дескрипторных таблиц;
· фрагментация памяти – в силу того, что размер сегмента может быть различным, после завершении работы одних сегментов и загрузки новых (очень маловероятно, что точно такого же размера) неизбежно возникновение свободных малых участков памяти.
В качестве примера операционной системы, применяющей сегментное преобразование памяти, можно назвать OS/2.
В основу страничного преобразования положено разбиение всей памяти на страницы. Страницы, в отличие от сегментов, имеют фиксированную длину, обычно являющуюся степенью числа 2, и не могут перекрываться. Страницы в физической памяти называются физическими страницами, а страницы в виртуальной памяти – виртуальными страницами. Адрес при страничной организации представляет собой упорядоченную пару, состоящую из номера страницы и смещения.
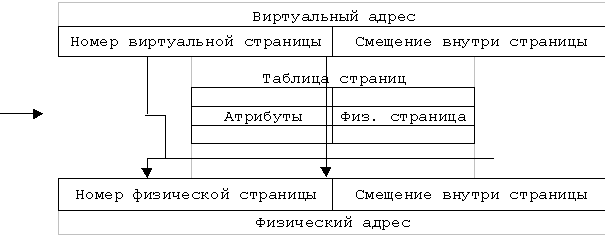
Страничное преобразование заключается в замене номера виртуальной страницы на номер физической. Каждой виртуальной странице ставится в соответствие физическая, т.е. страничное преобразование – это отображение физических страниц в виртуальные. Для этого отображения существует таблица дескрипторов страниц. Отличие от таблицы дескрипторов сегментов состоит в том, что здесь не требуется поле длины.
Поскольку размер страницы – величина фиксированная, то существует проблема его правильного выбора. Чем больше размер страницы, тем меньше будет размер структуры данных, обслуживающих преобразование адресов, но и тем больше будут потери, связанные с тем, что память можно выделять только постранично (возникает фрагментация). На некоторых архитектурах размер страниц задан аппаратно, например, на Intel – это 4 Кбайт, на DEC PDP-11 – 8 Кбайт, а на других архитектурах, таких, как Motorola 68030, размер страниц задается программно.
Важными характеристиками архитектуры процессора являются размеры физического и виртуального адресных пространств, определяющих соответственно ограничение на размер физической памяти и пределы, в которых может меняться виртуальный адрес. Размеры адресных пространств обычно определяются разрядностью архитектуры процессора. Самыми распространёнными сейчас являются 32-разрядные процессоры, позволяющие создавать виртуальные адресные пространства размером 2 32 байт (4 Гбайта).

Страничное преобразование представляет собой совокупность аппаратных и программных средств, обеспечивающих механизмы виртуальной памяти, свопинга и реализацию других алгоритмов управления памятью.
Основным достоинством страничного способа распределения памяти является минимально возможная фрагментация.
Недостатки страничного преобразования:
· как и при сегментном методе, потери памяти и процессорного времени на размещение и обработку дескрипторных таблиц;
· программы разбиваются на страницы случайно, без учёта логических взаимосвязей, имеющихся в коде, следовательно, межстраничные переходы осуществляются чаще, чем межсегментные. Вследствие этого труднее организовать разделение программных модулей между выполняющимися процессами.
Источник
Организация памяти
За последнюю неделю дважды объяснял людям как организована работа с памятью в х86, с целью чтобы не объяснять в третий раз написал эту статью.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
Как известно программист, когда пишет программы работает не с физическим адресом, а только с логическим. И то если он программирует на ассемблере. В том же Си ячейки памяти от программиста уже скрыты указателями, для его же удобства, но если грубо говорить указатель это другое представление логического адреса памяти, а в Java и указателей нет, совсем плохой язык. Однако грамотному программисту не помешают знания о том как организована память хотя бы на общем уровне. Меня вообще очень огорчают программисты, которые не знают как работает машина, обычно это программисты Java и прочие php-парни, с квалификацией ниже плинтуса.
Так ладно, хватит о печальном, переходим к делу.
Рассмотрим адресное пространство программного режима 32 битного процессора (для 64 бит все по аналогии)
Адресное пространство этого режима будет состоять из 2^32 ячеек памяти пронумерованных от 0 и до 2^32-1.
Программист работает с этой памятью, если ему нужно определить переменную, он просто говорит ячейка памяти с адресом таким-то будет содержать такой-то тип данных, при этом сам програмист может и не знать какой номер у этой ячейки он просто напишет что-то вроде:
int data = 10;
компьютер поймет это так: нужно взять какую-то ячейку с номером стопицот и поместить в нее цело число 10. При том про адрес ячейки 18894 вы и не узнаете, он от вас будет скрыт.
Все бы хорошо, но возникает вопрос, а как компьютер ищет эту ячейку памяти, ведь память у нас может быть разная:
3 уровень кэша
2 уровень кэша
1 уровень кэша
основная память
жесткий диск
Это все разные памяти, но компьютер легко находит в какой из них лежит наша переменная int data.
Этот вопрос решается операционной системой совместно с процессором.
Вся дальнейшая статья будет посвящена разбору этого метода.
Архитектура х86 поддерживает стек. 
Стек это непрерывная область оперативной памяти организованная по принципу стопки тарелок, вы не можете брать тарелки из середины стопки, можете только брать верхнюю и класть тарелку вы тоже можете только на верх стопки.
В процессоре для работы со стеком организованны специальные машинные коды, ассемблерные мнемоники которых выглядят так:
push operand
помещает операнд в стек
pop operand
изымает из вершины стека значение и помещает его в свой операнд
Стек в памяти растет сверху вниз, это значит что при добавлении значения в него адрес вершины стека уменьшается, а когда вы извлекаете из него, то адрес вершины стека увеличивается.
Теперь кратко рассмотрим что такое регистры.
Это ячейки памяти в самом процессоре. Это самый быстрый и самый дорогой тип памяти, когда процессор совершает какие-то операции со значением или с памятью, он берет эти значения непосредственно из регистров.
В процессоре есть несколько наборов логик, каждая из которых имеет свои машинные коды и свои наборы регистров.
Basic program registers (Основные программные регистры) Эти регистры используются всеми программами с их помощью выполняется обработка целочисленных данных.
Floating Point Unit registers (FPU) Эти регистры работают с данными представленными в формате с плавающей точкой.
Еще есть MMX и XMM registers эти регистры используются тогда, когда вам надо выполнить одну инструкцию над большим количеством операндов.
Рассмотрим подробнее основные программные регистры. К ним относятся восемь 32 битных регистров общего назначения: EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP
Для того чтобы поместить в регистр данные, или для того чтобы изъять из регистра в ячейку памяти данные используется команда mov:
mov eax, 10
загружает число 10 в регистр eax.
mov data, ebx
копирует число, содержащееся в регистре ebx в ячейку памяти data.
Регистр ESP содержит адрес вершины стека.
Кроме регистров общего назначения, к основным программным регистрам относят шесть 16битных сегментных регистров: CS, DS, SS, ES, FS, GS, EFLAGS, EIP
EFLAGS показывает биты, так называемые флаги, которые отражают состояние процессора или характеризуют ход выполнения предыдущих команд.
В регистре EIP содержится адрес следующей команды, которая будет выполнятся процессором.
Я не буду расписывать регистры FPU, так как они нам не понадобятся. Итак наше небольшое отступление про регистры и стек закончилось переходим обратно к организации памяти.
Как вы помните целью статьи является рассказ про преобразование логической памяти в физическую, на самом деле есть еще промежуточный этап и полная цепочка выглядит так:
Логический адрес —> Линейный (виртуальный)—> Физический
линейный адрес=Базовый адрес сегмента(на картинке это начало сегмента) + смещение
Сегмент кода
Сегмент данных
Сегмент стека
Используемый сегмент стека задается значением регистра SS.
Смещение внутри этого сегмента представлено регистром ESP, который указывает на вершину стека, как вы помните.
Сегменты в памяти могут друг друга перекрывать, мало того базовый адрес всех сегментов может совпадать например в нуле. Такой вырожденный случай называется линейным представлением памяти. В современных системах, память как правило так организована.
Теперь рассмотрим определение базовых адресов сегмента, я писал что они содержаться в регистрах SS, DS, CS, но это не совсем так, в них содержится некий 16 битный селектор, который указывает на некий дескриптор сегментов, в котором уже хранится необходимый адрес. 
Так выглядит селектор, в тринадцати его битах содержится индекс дескриптора в таблице дескрипторов. Не хитро посчитать будет что 2^13 = 8192 это максимальное количество дескрипторов в таблице.
Вообще дескрипторных таблиц бывает два вида GDT и LDT Первая называется глобальная таблица дескрипторов, она в системе всегда только одна, ее начальный адрес, точнее адрес ее нулевого дескриптора хранится в 48 битном системном регистре GDTR. И с момента старта системы не меняется и в свопе не принимает участия.
А вот значения дескрипторов могут меняться. Если в селекторе бит TI равен нулю, тогда процессор просто идет в GDT ищет по индексу нужный дескриптор с помощью которого осуществляет доступ к этому сегменту.
Пока все просто было, но если TI равен 1 тогда это означает что использоваться будет LDT. Таблиц этих много, но использоваться в данный момент будет та селектор которой загружен в системный регистр LDTR, который в отличии от GDTR может меняться.
Индекс селектора указывает на дескриптор, который указывает уже не на базовый адрес сегмента, а на память в котором хранится локальная таблица дескрипторов, точнее ее нулевой элемент. Ну а дальше все так же как и с GDT. Таким образом во время работы локальные таблицы могут создаваться и уничтожаться по мере необходимости. LDT не могут содержать дескрипторы на другие LDT.
Итак мы знаем как процессор добирается до дескриптора, а что содержится в этом дескрипторе посмотрим на картинке: 
Дескрипторы состоит из 8 байт.
Биты с 15-39 и 56-63 содержат линейный базовый адрес описываемым данным дескриптором сегмента. Напомню нашу формулу для нахождения линейного адреса:
линейный адрес = базовый адрес + смещение
[база; база+предел)
(база+предел; вершина]
Кстати интересно почему база и предел так рвано располагаются в дескрипторе. Дело в том что процессоры х86 развивались эволюционно и во времена 286х дескрипторы были по 8 бит всего, при этом старшие 2 байта были зарезервированы, ну а в последующих моделях процессоров с увеличением разрядности дескрипторы тоже выросли, но для сохранения обратной совместимости пришлось оставить структуру как есть.
Значение адреса «вершина» зависит от 54го D бита, если он равен 0, тогда вершина равна 0xFFF(64кб-1), если D бит равен 1, тогда вершина равна 0xFFFFFFFF (4Гб-1)
С 41-43 бит кодируется тип сегмента.
000 — сегмент данных, только считывание
001 — сегмент данных, считывание и запись
010 — сегмент стека, только считывание
011 — сегмент стека, считывание и запись
100 — сегмент кода, только выполнение
101- сегмент кода, считывание и выполнение
110 — подчиненный сегмент кода, только выполнение
111 — подчиненный сегмент кода, только выполнение и считывание
44 S бит если равен 1 тогда дескриптор описывает реальный сегмент оперативной памяти, иначе значение S бита равно 0.
Самым важным битом является 47-й P бит присутствия. Если бит равен 1 значит, что сегмент или локальная таблица дескрипторов загружена в оперативку, если этот бит равен 0, тогда это означает что данного сегмента в оперативке нет, он находится на жестком диске, случается прерывание, особый случай работы процессора запускается обработчик особого случая, который загружает нужный сегмент с жесткого диска в память, если P бит равен 0, тогда все поля дескриптора теряют смысл, и становятся свободными для сохранения в них служебной информации. После завершения работы обработчика, P бит устанавливается в значение 1, и производится повторное обращение к дескриптору, сегмент которого находится уже в памяти.
На этом заканчивается преобразование логического адреса в линейный, и я думаю на этом стоит прерваться. В следующий раз я расскажу вторую часть преобразования из линейного в физический.
А так же думаю стоит немного поговорить о передачи аргументов функции, и о размещении переменных в памяти, чтобы была какая-то связь с реальностью, потому размещение переменных в памяти это уже непосредственно, то с чем вам приходится сталкиваться в работе, а не просто какие-то теоретические измышления для системного программиста. Но без понимания, как устроена память невозможно понять как эти самые переменные хранятся в памяти.
В общем надеюсь было интересно и до новых встреч.
Источник



