
- Основные структуры данных. Матчасть. Азы
- Что такое структура данных?
- Какие бывают?
- Основные структуры данных.
- Массивы
- Бывают
- Основные операции
- Вопросы
- Стеки
- Основные операции
- Вопросы
- Очереди
- Основные операции
- Вопросы
- Связанный список
- Бывают
- Основные операции
- Вопросы
- Графы
- Бывают
- Встречаются в таких формах как
- Общие алгоритмы обхода графа
- Вопросы
- Деревья
- Три способа обхода дерева
- Вопросы
- Trie ( префиксное деревое )
- Вопросы
- Хэш таблицы
- Вопросы
- Список ресурсов
- Вместо заключения
- Важнейшие структуры данных, которые вам следует знать к своему собеседованию по программированию
- Что такое структура данных?
- Зачем нужны структуры данных?
- Наиболее распространенные структуры данных
- Массивы
- Простейшие операции с массивами
- Вопросы по массивам, часто задаваемые на собеседованиях
- Стеки
- Вопросы о стеке, часто задаваемые на собеседованиях
- Очереди
- Простейшие операции с очередью
- Вопросы об очередях, часто задаваемые на собеседованиях
- Связный список
- Простейшие операции со связными списками:
- Вопросы о связных списках, часто задаваемые на собеседованиях:
- Графы
- Вопросы о графах, часто задаваемые на собеседованиях:
- Деревья
- Вопросы о деревьях, часто задаваемые на собеседованиях:
- Вопросы о борах, часто задаваемые на собеседованиях:
- Хеш-таблица
- Вопросы о хешировании, часто задаваемые на собеседованиях:
Основные структуры данных. Матчасть. Азы
Все чаще замечаю, что современным самоучкам очень не хватает матчасти. Все знают языки, но мало основы, такие как типы данных или алгоритмы. Немного про типы данных.
Еще в далеком 1976 швейцарский ученый Никлаус Вирт написал книгу Алгоритмы + структуры данных = программы.
40+ лет спустя это уравнение все еще верно. И если вы самоучка и надолго в программировании пробегитесь по статье, можно по диагонали. Можно код кофе.

В статье так же будут вопросы, которое вы можете услышать на интервью.
Что такое структура данных?
Структура данных — это контейнер, который хранит данные в определенном макете. Этот «макет» позволяет структуре данных быть эффективной в некоторых операциях и неэффективной в других.
Какие бывают?
Линейные, элементы образуют последовательность или линейный список, обход узлов линеен. Примеры: Массивы. Связанный список, стеки и очереди.
Нелинейные, если обход узлов нелинейный, а данные не последовательны. Пример: граф и деревья.
Основные структуры данных.
Массивы
Массив — это самая простая и широко используемая структура данных. Другие структуры данных, такие как стеки и очереди, являются производными от массивов.
Изображение простого массива размера 4, содержащего элементы (1, 2, 3 и 4).
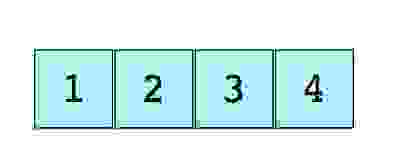
Каждому элементу данных присваивается положительное числовое значение (индекс), который соответствует позиции элемента в массиве. Большинство языков определяют начальный индекс массива как 0.
Бывают
Одномерные, как показано выше.
Многомерные, массивы внутри массивов.
Основные операции
Вопросы
Стеки
Стек — абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
Это не массивы. Это очередь. Придумал Алан Тюринг.
Примером стека может быть куча книг, расположенных в вертикальном порядке. Для того, чтобы получить книгу, которая где-то посередине, вам нужно будет удалить все книги, размещенные на ней. Так работает метод LIFO (Last In First Out). Функция «Отменить» в приложениях работает по LIFO.
Изображение стека, в три элемента (1, 2 и 3), где 3 находится наверху и будет удален первым.
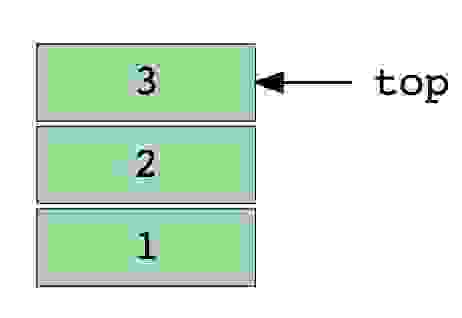
Основные операции
Вопросы
Очереди
Подобно стекам, очередь — хранит элемент последовательным образом. Существенное отличие от стека – использование FIFO (First in First Out) вместо LIFO.
Пример очереди – очередь людей. Последний занял последним и будешь, а первый первым ее и покинет.
Изображение очереди, в четыре элемента (1, 2, 3 и 4), где 1 находится наверху и будет удален первым

Основные операции
Вопросы
Связанный список
Связанный список – массив где каждый элемент является отдельным объектом и состоит из двух элементов – данных и ссылки на следующий узел.
Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком расположения элементов данных в памяти компьютера, а порядок обхода списка всегда явно задаётся его внутренними связями.
Бывают
Однонаправленный, каждый узел хранит адрес или ссылку на следующий узел в списке и последний узел имеет следующий адрес или ссылку как NULL.
Двунаправленный, две ссылки, связанные с каждым узлом, одним из опорных пунктов на следующий узел и один к предыдущему узлу.
Круговой, все узлы соединяются, образуя круг. В конце нет NULL. Циклический связанный список может быть одно-или двукратным циклическим связанным списком.
Самое частое, линейный однонаправленный список. Пример – файловая система.

Основные операции
Вопросы
Графы
Граф-это набор узлов (вершин), которые соединены друг с другом в виде сети ребрами (дугами).

Бывают
Ориентированный, ребра являются направленными, т.е. существует только одно доступное направление между двумя связными вершинами.
Неориентированные, к каждому из ребер можно осуществлять переход в обоих направлениях.
Смешанные
Встречаются в таких формах как
Общие алгоритмы обхода графа
Вопросы
Деревья
Дерево-это иерархическая структура данных, состоящая из узлов (вершин) и ребер (дуг). Деревья по сути связанные графы без циклов.
Древовидные структуры везде и всюду. Дерево скилов в играх знают все.
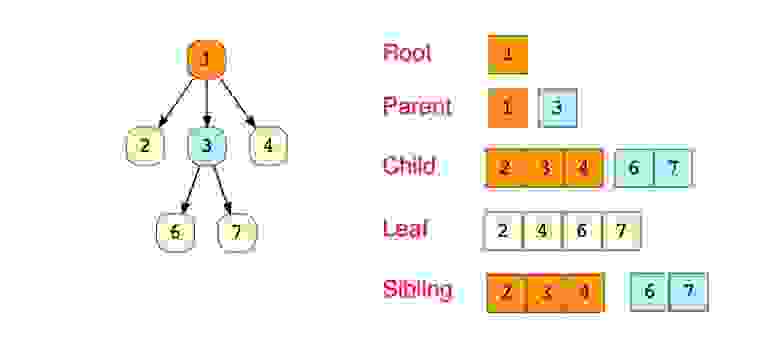
Типы деревьев
- N дерево
- Сбалансированное дерево
- Бинарное дерево
- Дерево Бинарного Поиска
- AVL дерево
- 2-3-4 деревья
Бинарное дерево самое распространенное.
«Бинарное дерево — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. » — Procs
Три способа обхода дерева
Вопросы
Trie ( префиксное деревое )
Разновидность дерева для строк, быстрый поиск. Словари. Т9.
Вот как такое дерево хранит слова «top», «thus» и «their».
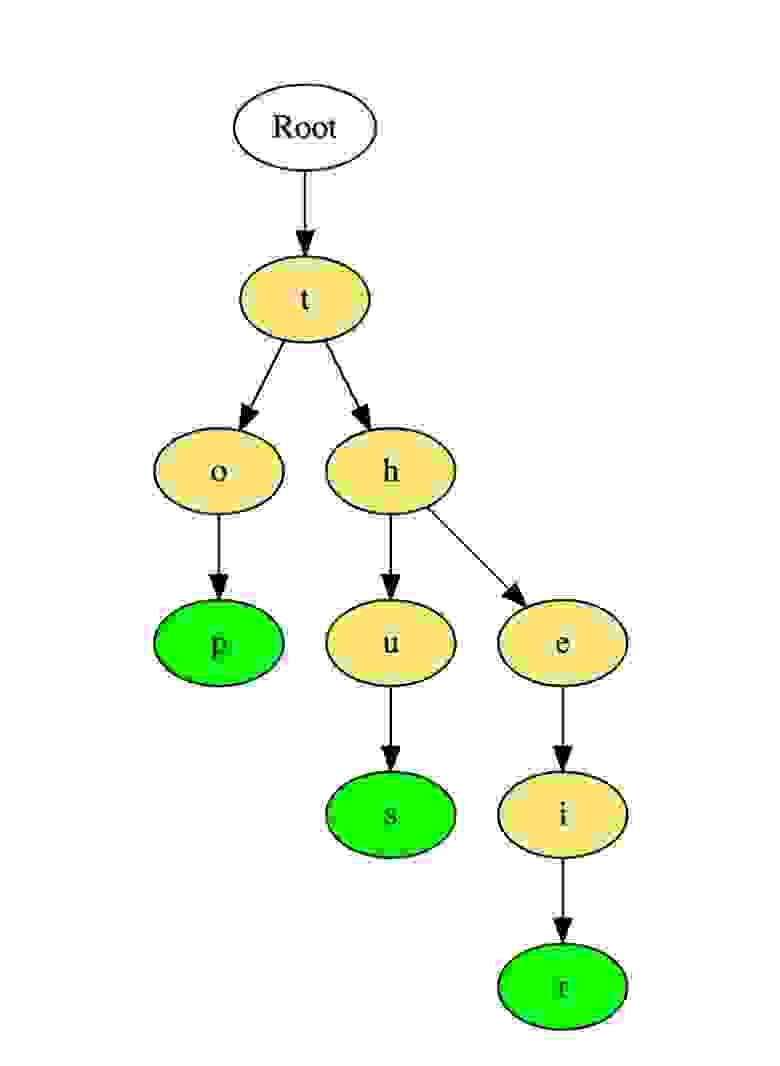
Слова хранятся сверху вниз, зеленые цветные узлы «p», «s» и «r» указывают на конец «top», «thus « и «their» соответственно.
Вопросы
Хэш таблицы
Хэширование — это процесс, используемый для уникальной идентификации объектов и хранения каждого объекта в заранее рассчитанном уникальном индексе (ключе).
Объект хранится в виде пары «ключ-значение», а коллекция таких элементов называется «словарем». Каждый объект можно найти с помощью этого ключа.
По сути это массив, в котором ключ представлен в виде хеш-функции.
Эффективность хеширования зависит от
- Функции хеширования
- Размера хэш-таблицы
- Метода борьбы с коллизиями
Пример сопоставления хеша в массиве. Индекс этого массива вычисляется через хэш-функцию. 
Вопросы
Список ресурсов
Вместо заключения
Матчасть так же интересна, как и сами языки. Возможно, кто-то увидит знакомые ему базовые структуры и заинтересуется.
Спасибо, что прочли. Надеюсь не зря потратили время =)
PS: Прошу извинить, как оказалось, перевод статьи уже был тут и очень недавно, я проглядел.
Если интересно, вот она, спасибо Hokum, буду внимательнее.
Источник
Важнейшие структуры данных, которые вам следует знать к своему собеседованию по программированию
Никлаус Вирт, швейцарский ученый-информатик, в 1976 году написал книгу под названием «Алгоритмы + Структуры данных = Программы».
Через 40 с лишним лет это тождество остается в силе. Вот почему соискатели, желающие стать программистами, должны продемонстрировать, что знают структуры данных и умеют их применять.
Практически во всех задачах от кандидата требуется глубокое понимание структур данных. При этом не столь важно, выпускник ли вы (закончили университет или курсы программирования), либо у вас за плечами десятки лет опыта.
Иногда в вопросах на интервью прямо упоминается та или иная структура данных, например, «дано двоичное дерево». В других случаях задача формулируется более завуалированно, например, «нужно отследить, сколько у нас книг от каждого автора».
Изучение структур данных — незаменимое дело, даже если вы просто стараетесь профессионально совершенствоваться на нынешней работе. Начнем с основ.
Переведено в Alconost

Что такое структура данных?
Если коротко, структура данных — это контейнер, информация в котором скомпонована характерным образом. Благодаря такой «компоновке», структура данных будет эффективна в одних операциях и неэффективна — в других. Наша цель — разобраться в структурах данных таким образом, чтобы вы могли выбрать из них наиболее подходящую для решения конкретной стоящей перед вами задачи.
Зачем нужны структуры данных?
Поскольку структуры данных используются для хранения информации в упорядоченном виде, а данные — самый важный феномен в информатике, истинная ценность структур данных очевидна.
Не важно, какую именно задачу вы решаете, так или иначе вам придется иметь дело с данными, будь то зарплата сотрудника, биржевые котировки, список продуктов для похода в магазин или обычный телефонный справочник.
В зависимости от конкретного сценария, данные нужно хранить в подходящем формате. У нас в распоряжении — ряд структур данных, обеспечивающих нас такими различными форматами.
Наиболее распространенные структуры данных
Сначала давайте перечислим наиболее распространенные структуры данных, а затем разберем каждую по очереди:
- Массивы
- Стеки
- Очереди
- Связные списки
- Деревья
- Графы
- Боры (в сущности, это тоже деревья, но их целесообразно рассмотреть отдельно).
- Хеш-таблицы
Массивы
Массив — это простейшая и наиболее распространенная структура данных. Другие структуры данных, например, стеки и очереди, производны от массивов.
Здесь показан простой массив размером 4, содержащий элементы (1, 2, 3 и 4).
Каждому элементу данных присваивается положительное числовое значение, именуемое индексом и соответствующее положению этого элемента в массиве. В большинстве языков программирования элементы в массиве нумеруются с 0.
Существуют массивы двух типов:
- Одномерные (такие, как показанный выше)
- Многомерные (массивы, в которые вложены другие массивы)
Простейшие операции с массивами
Вопросы по массивам, часто задаваемые на собеседованиях
Стеки
Всем известна знаменитая опция «Отмена», предусмотренная почти во всех приложениях. Задумывались когда-нибудь, как она работает? Смысл такой: в программе сохраняются предшествующие состояния вашей работы (количество сохраняемых состояний ограничено), причем, они располагаются в памяти в таком порядке: последний сохраненный элемент идет первым. Одними массивами такую задачу не решить. Именно здесь нам пригодится стек.
Стек можно сравнить с высокой стопкой книг. Если вам нужна какая-то книга, лежащая около центра стопки, вам сначала придется снять все книги, лежащие выше. Именно так работает принцип LIFO (Последним пришел — первым вышел).
Так выглядит стек, содержащий три элемента данных (1, 2 и 3), где 3 находится сверху — поэтому будет убран первым:
Простейшие операции со стеком:
- Push — Вставляет элемент в стек сверху
- Pop — Возвращает верхний элемент после того, как удалит его из стека
- isEmpty — Возвращает true, если стек пуст
- Top — Возвращает верхний элемент, не удаляя его из стека
Вопросы о стеке, часто задаваемые на собеседованиях
Очереди
Очередь, как и стек — это линейная структура данных, элементы в которой хранятся в последовательном порядке. Единственное существенное отличие между стеком и очередью заключается в том, что в очереди вместо LIFO действует принцип FIFO (Первым пришел — первым вышел).
Идеальный реалистичный пример очереди — это и есть очередь покупателей в билетную кассу. Новый покупатель становится в самый хвост очереди, а не в начало. Тот же, кто стоит в очереди первым, первым приобретет билет и первым ее покинет.
Вот изображение очереди с четырьмя элементами данных (1, 2, 3 и 4), где 1 идет первым и первым же покинет очередь:
Простейшие операции с очередью
Вопросы об очередях, часто задаваемые на собеседованиях
Связный список
Связный список — еще одна важная линейная структура данных, на первый взгляд напоминающая массив. Однако, связный список отличается от массива по выделению памяти, внутренней структуре и по тому, как в нем выполняются базовые операции вставки и удаления.
Связный список напоминает цепочку узлов, в каждом из которых содержится информация: например, данные и указатель на следующий узел в цепочке. Есть головной указатель, соответствующий первому элементу в связном списке, и, если список пуст, то он направлен просто на null (ничто).
При помощи связных списков реализуются файловые системы, хеш-таблицы и списки смежности.
Вот так можно наглядно изобразить внутреннюю структуру связного списка:
Существуют такие типы связных списков:
- Односвязный список (однонаправленный)
- Двусвязный список (двунаправленный)
Простейшие операции со связными списками:
Вопросы о связных списках, часто задаваемые на собеседованиях:
Графы
Граф — это множество узлов, соединенных друг с другом в виде сети. Узлы также называются вершинами. Пара (x,y) называется ребром, это означает, что вершина x соединена с вершиной y. Ребро может иметь вес/стоимость — показатель, характеризующий, насколько затратен переход от вершины x к вершине y.
- Неориентированный граф
- Ориентированный граф
В языке программирования графы могут быть двух видов:
- Матрица смежности
- Список смежности
Распространенные алгоритмы обхода графа:
Вопросы о графах, часто задаваемые на собеседованиях:
Деревья
Дерево — это иерархическая структура данных, состоящая из вершин (узлов) и ребер, которые их соединяют. Деревья подобны графам, однако, ключевое отличие дерева от графа таково: в дереве не бывает циклов.
Деревья широко используются в области искусственного интеллекта и в сложных алгоритмах, выступая в качестве эффективного хранилища информации при решении задач.
Вот схема простого дерева и базовая терминология, связанная с этой структурой данных:
Существуют деревья следующих типов:
- N-арное дерево
- Сбалансированное дерево
- Двоичное дерево
- Двоичное дерево поиска
- АВЛ-дерево
- Красно-черное дерево
- 2—3 дерево
Из вышеперечисленных деревьев чаще всего используются двоичное дерево и двоичное дерево поиска.
Вопросы о деревьях, часто задаваемые на собеседованиях:
Найдите высоту двоичного дерева
Найдите k-ное максимальное значение в двоичном дереве поиска
Найдите узлы, расположенные на расстоянии “k” от корня
Найдите предков заданного узла в двоичном дереве
Бор, также именуемый «префиксное дерево» — это древовидная структура данных, которая особенно эффективна при решении задач на строки. Она обеспечивает быстрое извлечение данных и чаще всего применяется для поиска слов в словаре, автозавершений в поисковике и даже для IP-маршрутизации.
Вот как три слова «top» (верх), «thus» (следовательно), and «their» (их) хранятся в бору:
Слова располагаются в направлении сверху вниз, и зеленые узлы «p», «s» и «r» завершают, соответственно, слова «top», «thus» и «their».
Вопросы о борах, часто задаваемые на собеседованиях:
Хеш-таблица
Хеширование — это процесс, применяемый для уникальной идентификации объектов и сохранения каждого объекта по заранее вычисленному индексу, именуемому его «ключом». Таким образом, объект хранится в виде «ключ-значение», а коллекция таких объектов называется «словарь». Каждый объект можно искать по его ключу. Существуют разные структуры данных, построенные по принципу хеширования, но чаще всего из таких структур применяется хеш-таблица.
Как правило, хеш-таблицы реализуются при помощи массивов.
Производительность хеширующей структуры данных зависит от следующих трех факторов:
- Хеш-функция
- Размер хеш-таблицы
- Метод обработки коллизий
Ниже показано, как хеш отображается на массив. Индекс этого массива вычисляется при помощи хеш-функции.
Вопросы о хешировании, часто задаваемые на собеседованиях:
- Найдите симметричные пары в массиве
- Отследите полную траекторию пути
- Найдите, является ли массив подмножеством другого массива
- Проверьте, являются ли массивы непересекающимися
Выше описаны восемь важнейших структур данных, которые определенно нужно знать, прежде чем идти на собеседование по программированию.
Удачи и интересного обучения! 🙂
Перевод статьи выполнен в Alconost.
Alconost занимается локализацией игр, приложений и сайтов на 68 языков. Переводчики-носители языка, лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджеры проектов 24/7, любые форматы строковых ресурсов.
Мы также делаем рекламные и обучающие видеоролики — для сайтов, продающие, имиджевые, рекламные, обучающие, тизеры, эксплейнеры, трейлеры для Google Play и App Store.
Источник



