
- Архитектура базы данных: понятие, определение, уровни
- Что это?
- Виды БД
- Централизованные базы данных
- Распределенные базы данных
- Типы БД по способу доступа к ним
- БД «файл-сервер»
- БД «клиент-сервер»
- Три уровня архитектуры БД
- Внешний уровень
- Концептуальный уровень
- Элементы концептуального уровня
- Внутренний уровень
- Элементы внутреннего уровня
- Архитектура хранилищ данных: традиционная и облачная
- Введение
- Традиционная архитектура хранилища данных
- Трехуровневая архитектура
- Kimball vs. Inmon
- Модели хранилищ данных
- Звезда vs. Снежинка
- ETL vs. ELT
- Организационная зрелость
- Новые архитектуры хранилищ данных
- Amazon Redshift
- Google BigQuery
- Panoply
- По ту сторону облачных хранилищ данных
Архитектура базы данных: понятие, определение, уровни
Как называется совокупность основных структурных, функциональных компонентов различных БД, СУБД (систем управления базами данных)? Этот комплекс в информационной науке принято называть архитектурой базы данных, СУБД. Предлагаем вам досконально разобрать это понятие, типы подобных комплексов, их трехуровневое разбиение.
Что это?
Архитектура базы данных — комплекс структурных компонентов БД, а также средств, обеспечивающих их взаимодействие как друг с другом, так и с конечным пользователем, системным персоналом.
Данное определение отражает одну из важнейших функций хранилищ информации — обеспечение возможности абстракции сведений БД. Она и формирует сложившийся в наши дни подход к архитектуре данных.
Отсюда возникает новый вопрос: в чем суть, предназначение абстракции данных? Предоставляемые системой, они (абстракции) будут основным средством поддержки независимости ведения хранилищ информации (другими словами, БД) разными группами конечных пользователей. По-иному это называется независимостью данных системы.
Виды БД
Архитектура систем управления базами данных будет различной в зависимости от разновидности последних. На сегодня выделяется два вида БД:
- централизованный;
- распределенный.
С особенностями каждой из разновидностей мы предлагаем читателю ознакомиться далее.
Централизованные базы данных
Главное отличие этих БД: они хранятся в памяти одной вычислительной системы. Но если база, в свою очередь, будет компонентом сетей ЭВМ, то становится возможным распределенный доступ к базам данных. То есть БД будет открытой для пользователей электронно-вычислительных машин, подключенных к данной сети. Подобное использование характерно для локальных систем ЭВМ, создаваемых на базе организаций, компаний.
Распределенные базы данных
Что важно знать об архитектуре распределенных баз данных? Такие БД состоят из нескольких частей, хранящихся в различных ЭВМ одной сети. Возможно, информация тут будет дублироваться, пересекаться. Что удобно, пользователю распределенной базы данных не нужно знать, каким образом элементы хранилища информации размещены в узлах подобной сети. Чаще всего он воспринимает этот комплекс сведений как единое целое.
Как осуществляется работа с подобной БД? С помощью системы управления распределенными базами данных (СУРБД). Ее системный справочник будет описывать информацию, содержащуюся в хранилище данных, основы ее размещения в сети. В свою очередь, сам справочник может быть декомпозирован, размещен в различных узлах общей сети.
Составные части распределенной БД размещаются на отдельных подключенных к ней ЭВМ. Ими управляют уже собственные (локальные) СУБД электронно-вычислительных устройств. Что важно отметить, подобные локальные системы управления хранилищами информации необязательно должны быть одинаковыми в различных узлах общей сети. Однако объединение таковых различных локальных баз данных в единую систему — весьма сложная научно-техническая задача. Для ее успешного решения потребовался целый комплекс экспериментальных мероприятий, теоретических разработок.
Типы БД по способу доступа к ним
Архитектура базы данных также будет различаться по способу доступа к находящейся в хранилище информации:
- Доступ локальный.
- Доступ удаленный (сетевой).
Последний тип доступа предполагает разделение архитектуры подобных систем еще на две вариации:
Снова предлагаем читателю разобраться с представленными разновидностями подробнее.
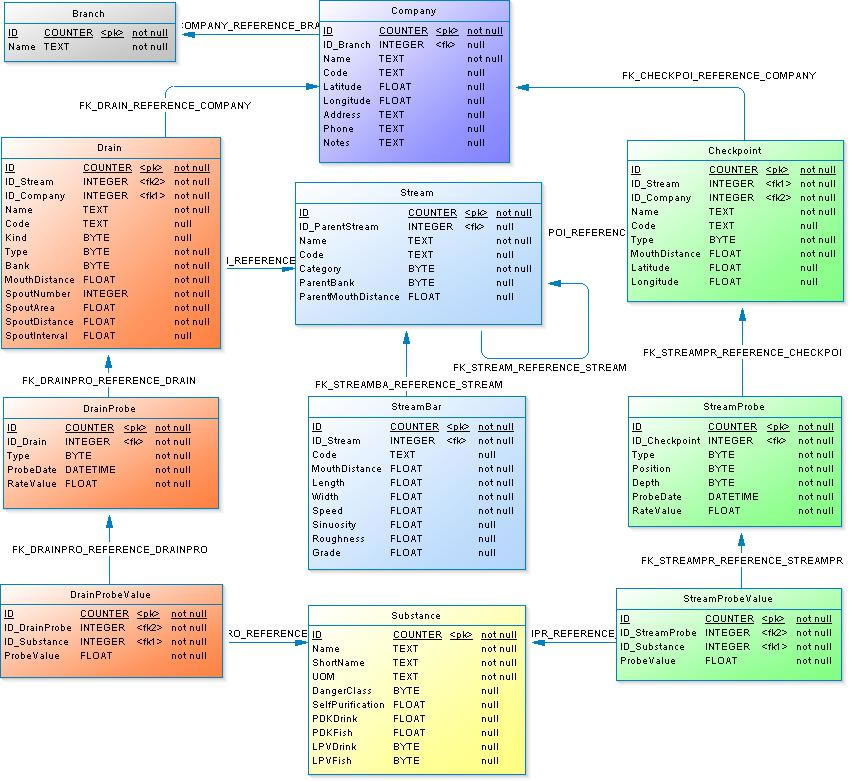
БД «файл-сервер»
Подобная архитектура комплексов баз данных предполагает выделение одного из устройств сети ЭВМ в качестве центрального. Оно будет считаться сервером файлов. На главной машине хранится совместно используемая централизованная база данных. Другие же устройства сети выступают рабочими станциями, которые поддерживают пользовательский доступ к основной БД.
В системе «файл-сервер» каждый пользователь имеет возможность запускать приложение, находящееся на главной машине. Притом на его устройстве будет открываться только копия данной программы.
По пользовательским запросам файлы центральной базы данных (находящейся на сервере) передаются на компьютеры — рабочие станции. Там и происходит обработка информации. У пользователей, работающих с общей БД, на компьютерах появляется локальная ее копия. Последняя периодически обновляется по мере наполнения основного хранилища на сервере свежей информацией.
Подобная архитектура систем БД более всего характерна для сетей, к которым подключено небольшое число пользователей. Для ее реализации типично использование персональных СУБД (к примеру, Paradox, DBase). Недостатком архитектуры является критически низкая производительность системы при одновременном доступе нескольких пользователей к одним и тем же данным.
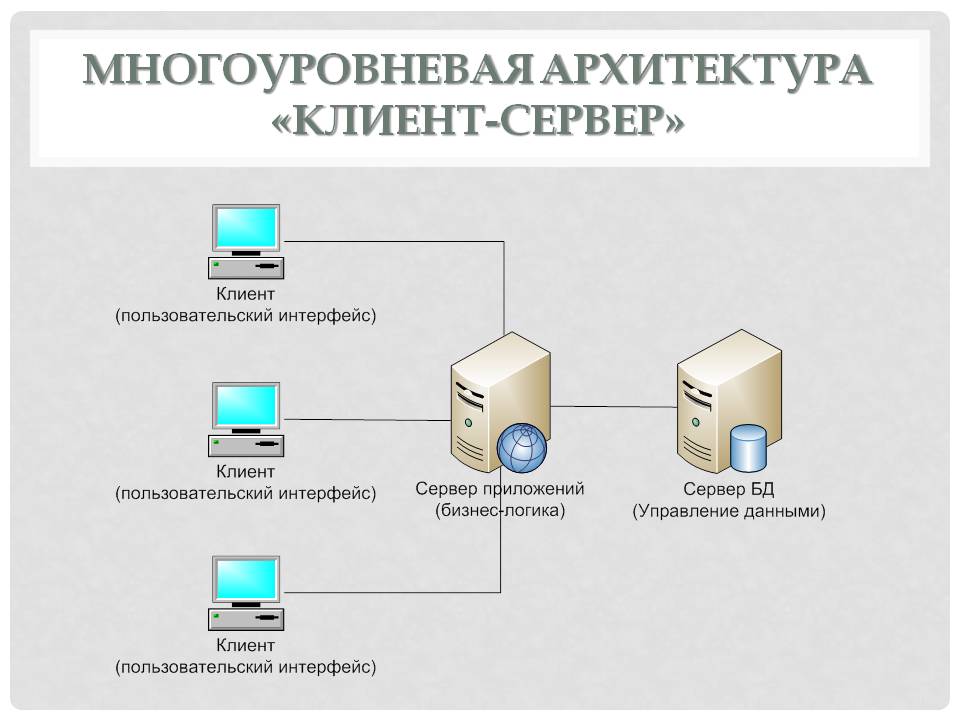
БД «клиент-сервер»
Здесь также предполагается наличие машины в сети, которая будет являться главной. Однако архитектура базы данных «клиент-сервер» имеет и собственную особенность. Главный компьютер не только хранит централизованную БД, но и обеспечивает основную часть обработки требуемых пользователю данных.
Технология разделяет систему на две части: серверную и клиентскую. Последняя будет обеспечивать интерактивный сервис, а серверная — разделение информации, управление данными, безопасность и администрирование.
Что предполагает архитектура клиент-серверных баз данных? Клиентское приложение здесь оформляет и отправляет запрос удаленному компьютеру-серверу, где расположено централизованное хранилище информации. Он (запрос) составлен на специальном языке SQL — стандарте доступа к серверу при использовании реляционных БД.
После получения запроса удаленный сервер перенаправляет его SQL-серверу. Так называется программа, ответственная за управление удаленной базой данных. Она обеспечивает выполнение запроса, предоставляет клиенту требуемые результаты по нему.
Таким образом, вся обработка запросов здесь будет проходить на удаленном сервере. Чтобы реализовать подобную архитектуру, необходимо задействовать многоуровневые СУБД. Второе их название — промышленные. Такие СУБД способны организовать масштабную инфосистему, состоящую из большого числа пользователей.
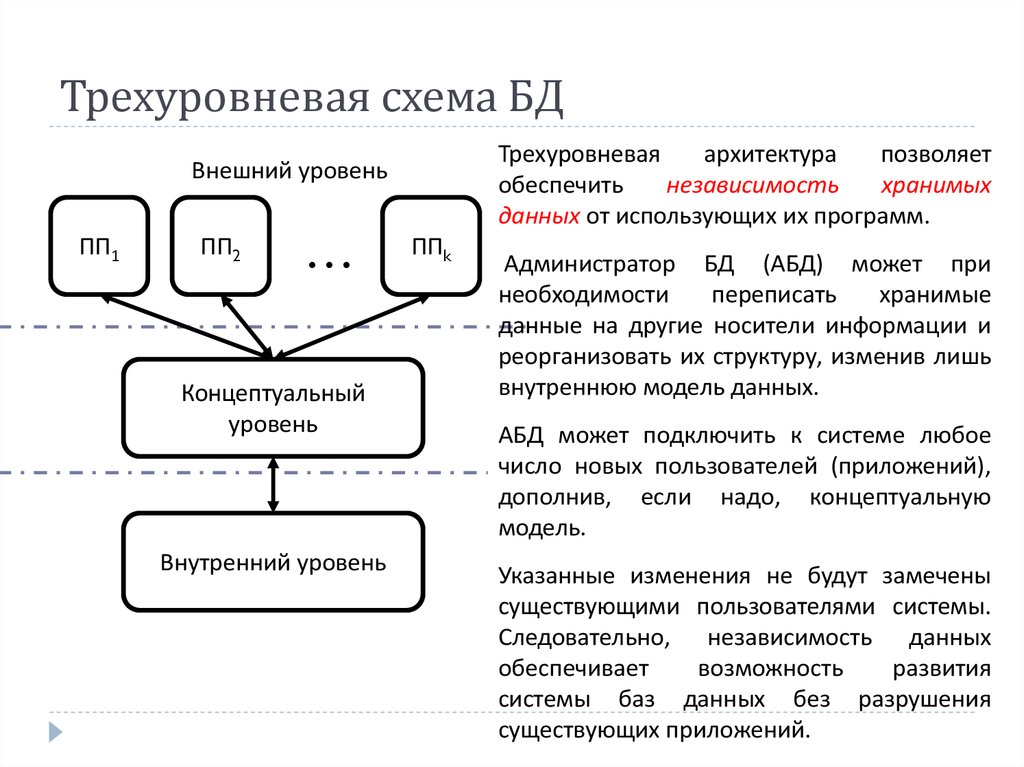
Три уровня архитектуры БД
Архитектура баз данных подразделяется на три основных уровня — три степени описания элементов БД:
- Внешний. На данном уровне информация воспринимается пользователями.
- Внутренний. На этом уровне информация воспринимается операционными системами, СУБД (системами управления базами данных).
- Концептуальный. Здесь осуществляется отображение внешнего уровня архитектуры системы баз данных на внутренний, обеспечение необходимой их независимости друг от друга.
Предлагаем читателю более подробно познакомиться с каждой из вышепредставленных степеней.
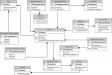
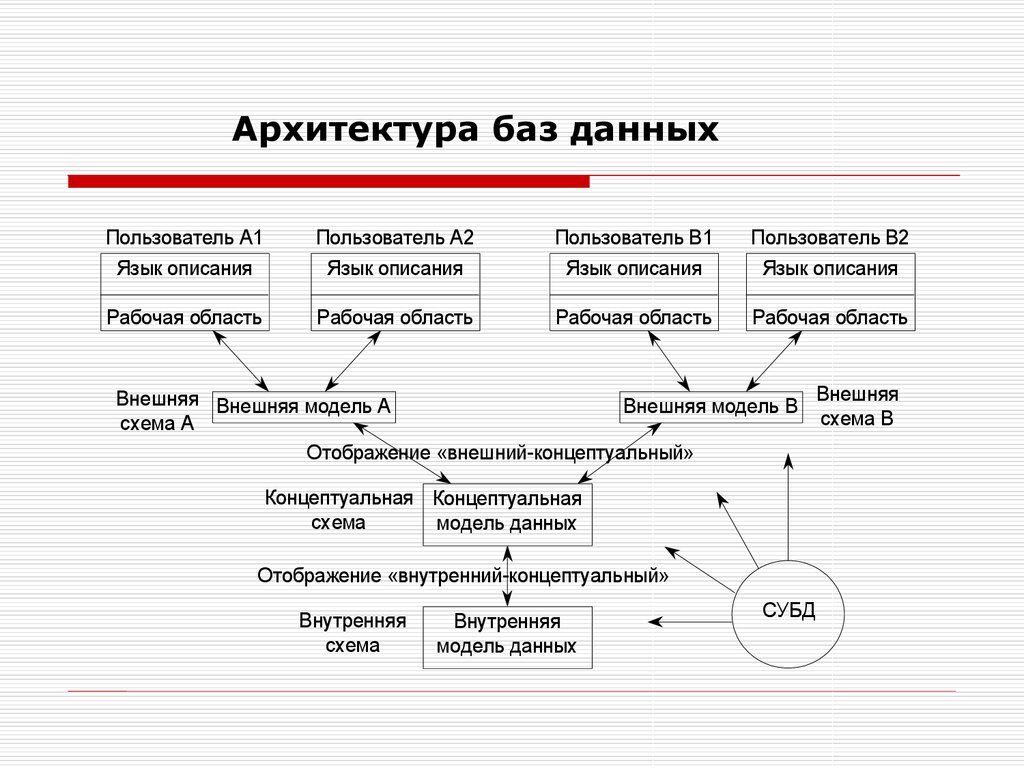
Внешний уровень
Внешний уровень архитектуры систем баз данных — это предоставление информации с позиции людей-пользователей.
Что из этого следует? Уровень описывает пользовательскую часть баз данных (относящихся к каждому пользователю). В свою очередь, она будет состоять из нескольких внешних представлений хранилищ информации, БД.
Что удобно, каждый пользователь здесь имеет дело с таким образом «реального мира», который более всего адаптирован под него. Внешнее представление будет содержать в себе только те сущности, связи и атрибуты, что интересны и полезны конкретному «юзеру».
Не стоит полагать, что ненужные для пользователя атрибуты, сущности и связи не существуют в базе данных. Они есть, но «юзер» чаще всего не подозревает об их существовании.
Если обратиться к терминологии ANSI/SPARC (Американского национального института стандартов), то представление каждого отдельного пользователя здесь будет называться внешним. В него будет входить содержимое БД — такое, каким его видит конкретный «юзер». Каждое такое внешнее представление определяется посредством внешней системы. Она же состоит из определения записи каждого типа, присутствующего во внешнем представлении.
Концептуальный уровень
Продолжаем разбирать архитектуру сервера, баз данных. Следующий ее уровень — концептуальный. Он включает в себя обобщающее представление о хранилище информации. Будет описывать, какие именно сведения хранятся в базе данных, а также каковы связи, их объединяющие.
С точки зрения администратора, хранилище содержит в себе логическую структуру БД. Данный уровень архитектуры базы данных — это фактически полное представление требований информации со стороны компании, предприятия, которое не будет зависеть от любых соображений относительно способа, методики ее (информации) хранения.
Элементы концептуального уровня
Перечислим компоненты, представленных на концептуальном уровне архитектуры:
- Совокупность сущностей, их атрибутов, связей между ними.
- Ограничения, что могут быть наложены на данные.
- Семантическая информация о сведениях в БД (связанная с их смыслом и значением).
- Информация по мерам обеспечения безопасности хранения данных, общей поддержки их целостности.
Концептуальный уровень призван поддерживать каждое из внешних представлений. Любая доступная пользователю информация из БД должна содержаться (или может быть вычислена) именно на данном уровне. Однако следует помнить, что информация о методах хранения данных в системе здесь не хранится.
Внутренний уровень
И последняя ступень трехуровневой архитектуры базы данных. Тут находится физическое представление в компьютере БД. Что это значит? Уровень предназначен для описания физической реализации базы данных. Кроме того, с его помощью достигается оптимальная производительность, обеспечивается экономное использование дискового пространства компьютерной системы.
Содержит в себе описание структур данных, организации конкретных файлов, которые используются для реализации хранения информации на дисковых пространствах, запоминающих устройствах. Здесь, на внутреннем уровне, СУБД взаимодействует с методами, способами доступа операционных систем, вспомогательным функционалом хранения и извлечения записей сведений. Цель всего перечисленного: размещать информацию на запоминающих устройствах, извлекать данные, создавать индексы и проч.
Ниже данного будет находиться физический уровень. Его контролирует уже операционная система, однако все же под контролем СУБД.
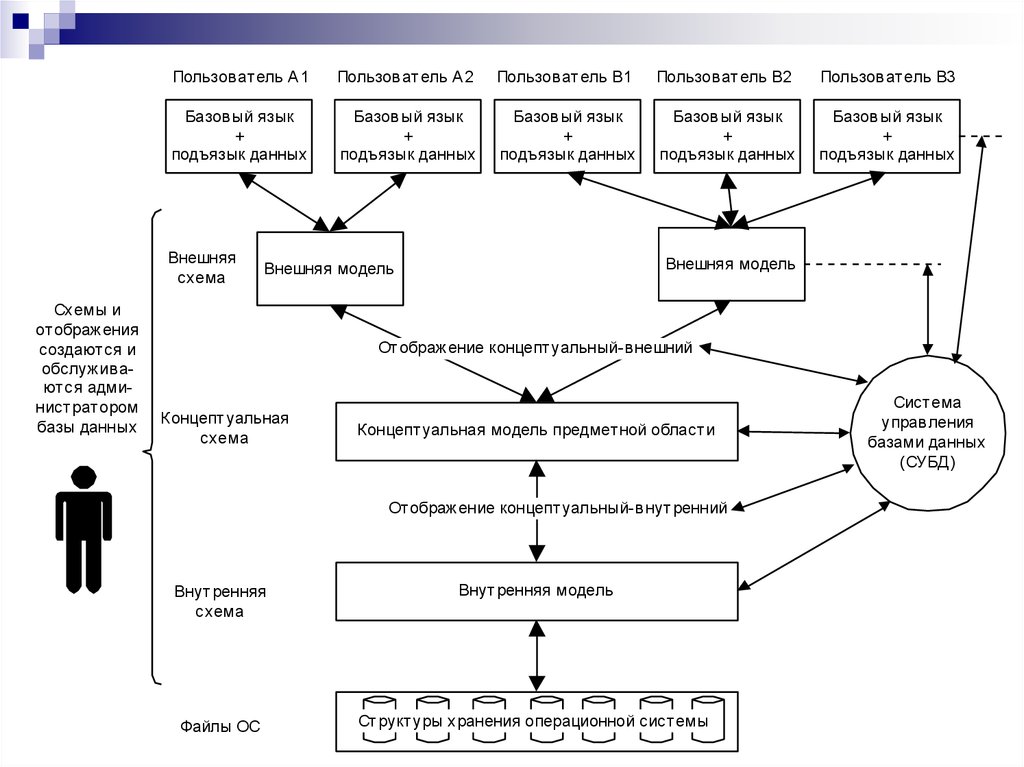
Элементы внутреннего уровня
Внутренний уровень архитектуры приложения, базы данных хранит в себе следующую информацию:
- О распределении дискового пространства для сохранения индексов и сведений.
- Подробное описание сохранения записи (где указываются реальные объемы сохраняемых данных).
- Информация о размещении записей.
- Сведения о сжатии данных, избранных методик их шифрования.
Вы познакомились с распространенными типами, видами архитектур систем баз данных. Также мы представили уровни архитектуры СУБД — внешний, внутренний и концептуальный, их характеристики и элементы.
Источник
Архитектура хранилищ данных: традиционная и облачная
Привет, Хабр! На тему архитектуры хранилищ данных написано немало, но так лаконично и емко как в статье, на которую я случайно натолкнулся, еще не встречал.
Предлагаю и вам познакомиться с данной статьей в моем переводе. Комментарии и дополнения только приветствуются!

Введение
Итак, архитектура хранилищ данных меняется. В этой статье рассмотрим сравнение традиционных корпоративных хранилищ данных и облачных решений с более низкой первоначальной стоимостью, улучшенной масштабируемостью и производительностью.
Хранилище данных – это система, в которой собраны данные из различных источников внутри компании и эти данные используются для поддержки принятия управленческих решений.
Компании все чаще переходят на облачные хранилища данных вместо традиционных локальных систем. Облачные хранилища данных имеют ряд отличий от традиционных хранилищ:
- Нет необходимости покупать физическое оборудование;
- Облачные хранилища данных быстрее и дешевле настроить и масштабировать;
- Облачные хранилища данных обычно могут выполнять сложные аналитические запросы гораздо быстрее, потому что они используют массовую параллельную обработку.
Традиционная архитектура хранилища данных
Следующие концепции освещают некоторые из устоявшихся идей и принципов проектирования, используемых для создания традиционных хранилищ данных.
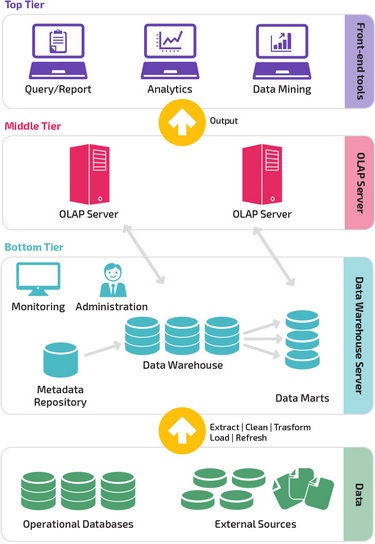
Трехуровневая архитектура
Довольно часто традиционная архитектура хранилища данных имеет трехуровневую структуру, состоящую из следующих уровней:
- Нижний уровень: этот уровень содержит сервер базы данных, используемый для извлечения данных из множества различных источников, например, из транзакционных баз данных, используемых для интерфейсных приложений.
- Средний уровень: средний уровень содержит сервер OLAP, который преобразует данные в структуру, лучше подходящую для анализа и сложных запросов. Сервер OLAP может работать двумя способами: либо в качестве расширенной системы управления реляционными базами данных, которая отображает операции над многомерными данными в стандартные реляционные операции (Relational OLAP), либо с использованием многомерной модели OLAP, которая непосредственно реализует многомерные данные и операции.
- Верхний уровень: верхний уровень — это уровень клиента. Этот уровень содержит инструменты, используемые для высокоуровневого анализа данных, создания отчетов и анализа данных.
Kimball vs. Inmon
Два пионера хранилищ данных: Билл Инмон и Ральф Кимбалл предлагают разные подходы к проектированию.
Подход Ральфа Кимбалла основывается на важности витрин данных, которые являются хранилищами данных, принадлежащих конкретным направлениям бизнеса. Хранилище данных — это просто сочетание различных витрин данных, которые облегчают отчетность и анализ. Проект хранилища данных по принципу Кимбалла использует подход «снизу вверх».
Подход Билла Инмона основывается на том, что хранилище данных является централизованным хранилищем всех корпоративных данных. При таком подходе организация сначала создает нормализованную модель хранилища данных. Затем создаются витрины размерных данных на основе модели хранилища. Это известно как нисходящий подход к хранилищу данных.
Модели хранилищ данных
В традиционной архитектуре существует три общих модели хранилищ данных: виртуальное хранилище, витрина данных и корпоративное хранилище данных:
- Виртуальное хранилище данных — это набор отдельных баз данных, которые можно использовать совместно, чтобы пользователь мог эффективно получать доступ ко всем данным, как если бы они хранились в одном хранилище данных;
- Модель витрины данных используется для отчетности и анализа конкретных бизнес-линий. В этой модели хранилища – агрегированные данные из ряда исходных систем, относящихся к конкретной бизнес-сфере, такой как продажи или финансы;
- Модель корпоративного хранилища данных предполагает хранение агрегированных данных, охватывающих всю организацию. Эта модель рассматривает хранилище данных как сердце информационной системы предприятия с интегрированными данными всех бизнес-единиц
Звезда vs. Снежинка
Схемы «звезда» и «снежинка» — это два способа структурировать хранилище данных.
Схема типа «звезда» имеет централизованное хранилище данных, которое хранится в таблице фактов. Схема разбивает таблицу фактов на ряд денормализованных таблиц измерений. Таблица фактов содержит агрегированные данные, которые будут использоваться для составления отчетов, а таблица измерений описывает хранимые данные.
Денормализованные проекты менее сложны, потому что данные сгруппированы. Таблица фактов использует только одну ссылку для присоединения к каждой таблице измерений. Более простая конструкция звездообразной схемы значительно упрощает написание сложных запросов.
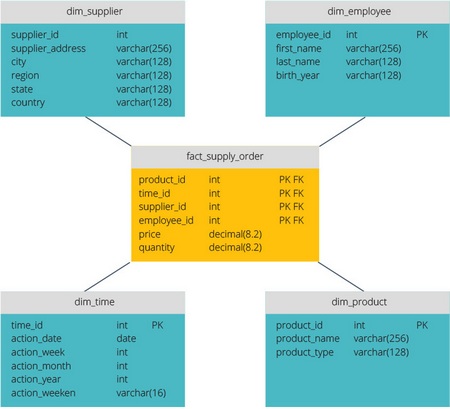
Схема типа «снежинка» отличается тем, что использует нормализованные данные. Нормализация означает эффективную организацию данных так, чтобы все зависимости данных были определены, и каждая таблица содержала минимум избыточности. Таким образом, отдельные таблицы измерений разветвляются на отдельные таблицы измерений.
Схема «снежинки» использует меньше дискового пространства и лучше сохраняет целостность данных. Основным недостатком является сложность запросов, необходимых для доступа к данным — каждый запрос должен пройти несколько соединений таблиц, чтобы получить соответствующие данные.

ETL vs. ELT
ETL и ELT — два разных способа загрузки данных в хранилище.
ETL (Extract, Transform, Load) сначала извлекают данные из пула источников данных. Данные хранятся во временной промежуточной базе данных. Затем выполняются операции преобразования, чтобы структурировать и преобразовать данные в подходящую форму для целевой системы хранилища данных. Затем структурированные данные загружаются в хранилище и готовы к анализу.
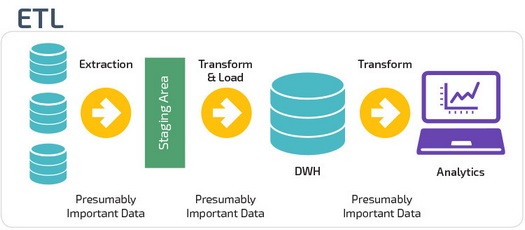
В случае ELT (Extract, Load, Transform) данные сразу же загружаются после извлечения из исходных пулов данных. Промежуточная база данных отсутствует, что означает, что данные немедленно загружаются в единый централизованный репозиторий.
Данные преобразуются в системе хранилища данных для использования с инструментами бизнес-аналитики и аналитики.

Организационная зрелость
Структура хранилища данных организации также зависит от его текущей ситуации и потребностей.
Базовая структура позволяет конечным пользователям хранилища напрямую получать доступ к сводным данным, полученным из исходных систем, создавать отчеты и анализировать эти данные. Эта структура полезна для случаев, когда источники данных происходят из одних и тех же типов систем баз данных.

Хранилище с промежуточной областью является следующим логическим шагом в организации с разнородными источниками данных с множеством различных типов и форматов данных. Промежуточная область преобразует данные в обобщенный структурированный формат, который проще запрашивать с помощью инструментов анализа и отчетности.
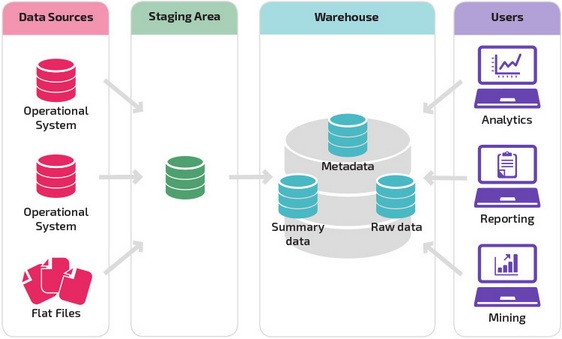
Одной из разновидностей промежуточной структуры является добавление витрин данных в хранилище данных. В витринах данных хранятся сводные данные по конкретной сфере деятельности, что делает эти данные легко доступными для конкретных форм анализа.
Например, добавление витрин данных может позволить финансовому аналитику легче выполнять подробные запросы к данным о продажах, прогнозировать поведение клиентов. Витрины данных облегчают анализ, адаптируя данные специально для удовлетворения потребностей конечного пользователя.

Новые архитектуры хранилищ данных
В последние годы хранилища данных переходят в облако. Новые облачные хранилища данных не придерживаются традиционной архитектуры и каждое из них предлагает свою уникальную архитектуру.
В этом разделе кратко описываются архитектуры, используемые двумя наиболее популярными облачными хранилищами: Amazon Redshift и Google BigQuery.
Amazon Redshift
Amazon Redshift — это облачное представление традиционного хранилища данных.
Redshift требует, чтобы вычислительные ресурсы были подготовлены и настроены в виде кластеров, которые содержат набор из одного или нескольких узлов. Каждый узел имеет свой собственный процессор, память и оперативную память. Leader Node компилирует запросы и передает их вычислительным узлам, которые выполняют запросы.
На каждом узле данные хранятся в блоках, называемых срезами. Redshift использует колоночное хранение, то есть каждый блок данных содержит значения из одного столбца в нескольких строках, а не из одной строки со значениями из нескольких столбцов.
Redshift использует архитектуру MPP (Massively Parallel Processing), разбивая большие наборы данных на куски, которые назначаются слайсам в каждом узле. Запросы выполняются быстрее, потому что вычислительные узлы обрабатывают запросы в каждом слайсе одновременно. Узел Leader Node объединяет результаты и возвращает их клиентскому приложению.
Клиентские приложения, такие как BI и аналитические инструменты, могут напрямую подключаться к Redshift с использованием драйверов PostgreSQL JDBC и ODBC с открытым исходным кодом. Таким образом, аналитики могут выполнять свои задачи непосредственно на данных Redshift.
Redshift может загружать только структурированные данные. Можно загружать данные в Redshift с использованием предварительно интегрированных систем, включая Amazon S3 и DynamoDB, путем передачи данных с любого локального хоста с подключением SSH или путем интеграции других источников данных с помощью API Redshift.
Google BigQuery
Архитектура BigQuery не требует сервера, а это означает, что Google динамически управляет распределением ресурсов компьютера. Поэтому все решения по управлению ресурсами скрыты от пользователя.
BigQuery позволяет клиентам загружать данные из Google Cloud Storage и других читаемых источников данных. Альтернативным вариантом является потоковая передача данных, что позволяет разработчикам добавлять данные в хранилище данных в режиме реального времени, строка за строкой, когда они становятся доступными.
BigQuery использует механизм выполнения запросов под названием Dremel, который может сканировать миллиарды строк данных всего за несколько секунд. Dremel использует массивно параллельные запросы для сканирования данных в базовой системе управления файлами Colossus. Colossus распределяет файлы на куски по 64 мегабайта среди множества вычислительных ресурсов, называемых узлами, которые сгруппированы в кластеры.
Dremel использует колоночную структуру данных, аналогичную Redshift. Древовидная архитектура отправляет запросы тысячам машин за считанные секунды.
Для выполнения запросов к данным используются простые команды SQL.
Panoply
Panoply обеспечивает комплексное управление данными как услуга. Его уникальная самооптимизирующаяся архитектура использует машинное обучение и обработку естественного языка (NLP) для моделирования и рационализации передачи данных от источника к анализу, сокращая время от данных до значения как можно ближе к нулю.
Интеллектуальная инфраструктура данных Panoply включает в себя следующие функции:
- Анализ запросов и данных — определение наилучшей конфигурации для каждого варианта использования, корректировка ее с течением времени и создание индексов, сортировочных ключей, дисковых ключей, типов данных, вакуумирование и разбиение.
- Идентификация запросов, которые не следуют передовым методам — например, те, которые включают вложенные циклы или неявное приведение — и переписывает их в эквивалентный запрос, требующий доли времени выполнения или ресурсов.
- Оптимизация конфигурации сервера с течением времени на основе шаблонов запросов и изучения того, какая настройка сервера работает лучше всего. Платформа плавно переключает типы серверов и измеряет итоговую производительность.
По ту сторону облачных хранилищ данных
Облачные хранилища данных — это большой шаг вперед по сравнению с традиционными подходами к архитектуре. Однако пользователи по-прежнему сталкиваются с рядом проблем при их настройке:
Источник



