
- Как оптимизировать SQL-запросы?
- Совет 1. Выберите правильный тип данных для столбца
- Совет 2: Табличные переменные и объединения
- Совет 3. Используйте условное предложение WHERE
- Совет 4: используйте SET NOCOUNT ON
- Совет 5: Избегайте ORDER BY, GROUP BY и DISTINCT
- Совет 6. Полностью уточняйте имена объектов базы данных
- Совет 7. Узнайте, как полностью защитить свой код
- Совет 8: используйте LAG и LEAD для последовательных строк
- Что изучать дальше
- Оптимизация сложных запросов MySQL
- Введение
- Покрывающий индекс — от толстых таблиц к индексам
- Оптимизация SQL запросов или розыск опасных преступников
- Вводные данные
- PMDSC – простая и понятная практика для любой скучной работы оптимизации SQL запросов
- Play it!
- Measure It!
- Draw it!
- Suppose it!
- Check it!
- Prison Break
Как оптимизировать SQL-запросы?

При оптимизации производительности разработчики и архитекторы часто упускают из виду настройку своих SQL-запросов. Понимание того, как работают базы данных, и написание более качественных SQL-запросов играет огромную роль в повышении производительности. Эффективные запросы SQL означают качественные масштабируемые приложения.
В этом руководстве мы рассмотрим 8 основных советов по SQL для оптимизации вашего SQL-сервера.
Совет 1. Выберите правильный тип данных для столбца
Каждый столбец таблицы в SQL имеет связанный тип данных. Вы можете выбирать из целых чисел, дат, переменных, логических значений, текста и т.д. При разработке важно выбрать правильный тип данных. Числа должны быть числового типа, даты должны быть датами и т.д. Это чрезвычайно важно для индексации.
Давайте посмотрим на пример ниже.
Вышеупомянутый запрос извлекает идентификатор и имя сотрудника с идентификатором 13412 . Что, если тип данных для employeeID — строка? Вы можете столкнуться с проблемами при использовании индексации, поскольку это займет много времени, когда это должно быть простое сканирование.
Совет 2: Табличные переменные и объединения
Когда у вас есть сложные запросы, такие как получение заказов для клиентов, вместе с их именами и датами заказа, вам нужно нечто большее, чем простой оператор выбора. В этом случае мы получаем данные из таблиц клиентов и заказов. Вот где вступают в силу объединения .
Давайте посмотрим на пример соединения:
Табличные переменные — это локальные переменные, которые временно хранят данные и обладают всеми свойствами локальных переменных. Не используйте табличные переменные в объединениях, как SQL видит их как одну строку. Несмотря на то, что они быстрые, табличные переменные плохо работают в соединениях.
Совет 3. Используйте условное предложение WHERE
Условные предложения WHERE используются для подмножества. Допустим, у вас есть такая ситуация:
С условным предложением WHERE это будет выглядеть так:
Совет 4: используйте SET NOCOUNT ON
При выполнении операций INSERT , SELECT , DELETE и UPDATE , используйте SET NOCOUNT ON . SQL всегда возвращает соответствующее количество строк для таких операций, поэтому, когда у вас есть сложные запросы с большим количеством соединений, это может повлиять на производительность.
С SET NOCOUNT ON SQL не будет подсчитывать затронутые строки и улучшить производительность.
В следующем примере мы предотвращаем отображение сообщения о количестве затронутых строк.
Совет 5: Избегайте ORDER BY, GROUP BY и DISTINCT
Использование ORDER BY , GROUP BY и DISTINCT только в случае необходимости. SQL создает рабочие таблицы и помещает туда данные. Затем он организует данные в рабочей таблице на основе запроса и затем возвращает результаты.
Совет 6. Полностью уточняйте имена объектов базы данных
Цель использования полностью определенных имен объектов базы данных — устранить двусмысленность. Полное имя объекта выглядит так:
Когда у вас есть доступ к нескольким базам данных, схемам и таблицам, становится важным указать, к чему вы хотите получить доступ. Вам не нужно этого делать, если вы не работаете с большими базами данных с несколькими пользователями и схемами, но это хорошая практика.
Поэтому вместо использования такого оператора:
Вам следует использовать:
Совет 7. Узнайте, как полностью защитить свой код
Базы данных хранят всевозможную информацию, что делает их основными целями атак. Распространенные атаки включают SQL-инъекции, когда пользователь вводит инструкцию SQL вместо имени пользователя и извлекает или изменяет вашу базу данных. Примеры SQL-инъекций:
Допустим, у вас есть это, вы textuserIDполучите ввод от пользователя. Вот как это может пойти не так:
Поскольку 1=1 всегда верно, он будет извлекать все данные из таблицы Users.
Вы можете защитить свою базу данных от SQL-инъекций, используя параметризованные операторы, проверки ввода, очистку ввода и т. Д. Как вы защищаете свою базу данных, зависит от СУБД. Вам нужно будет разобраться в своей СУБД и ее проблемах безопасности, чтобы вы могли писать безопасный код.
Совет 8: используйте LAG и LEAD для последовательных строк
Функция LAG позволяет запрашивать более одной строки в таблице, не вступая в таблицу к себе. Он возвращает значения из предыдущей строки таблицы.
Функция LEAD делает то же самое, но и для следующей строки.
Отказ от использования самостоятельных соединений повышает производительность, поскольку уменьшается количество операций чтения. Но, вы должны проверить, как LEAD и LAG влияют на производительность запросов.
Что изучать дальше
В этой статье мы рассмотрели несколько важных советов по SQL, но всегда есть чему поучиться. Вот несколько хороших следующих шагов:
- Оптимизация просмотров
- Вложенные запросы
- INSERT триггеры
- Внешние ключи
Источник
Оптимизация сложных запросов MySQL
Введение
MySQL — весьма противоречивый продукт. С одной стороны, он имеет несравненное преимущество в скорости перед другими базами данных на простейших операциях/запросах. С другой стороны, он имеет настолько неразвитый (если не сказать недоразвитый) оптимизатор, что на сложных запросах проигрывает вчистую.
Прежде всего хотелось бы ограничить круг рассматриваемых проблем оптимизации «широкими» и большими таблицами. Скажем до 10m записей и размером до 20Gb, с большим количеством изменяемых запросов к ним. Если в вашей в таблице много миллионов записей, каждая размером по 100 байт, и пять несложных возможных запросов к ней — это статья не для Вас. NB: Рассматривается движок MySQL innodb/percona — в дальнейшем просто MySQL.
Большинство запросов не являются очень сложными. Поэтому очень важно знать как построить индекс для использования нужным запросом и/или модифицировать запрос таким образом, чтобы он использовал уже имеющиеся индексы. Мы рассмотрим работу оптимизатора для выбора индекса обычных запросов (select_type=simple), без джойнов, подзапросов и объединений.
Отбросим простейшие случаи для очень небольших таблиц, для которых оптимизатор зачастую использует type=all (полный просмотр) вне зависимости от наличия индексов — к примеру, классификатор с 40-ка записями. MySQL имеет алгоритм использования нескольких индексов (index merge), но работает этот алгоритм не очень часто, и только без order by. Единственный разумный способ пытаться использовать index merge — случаи выборки по разным столбцам с OR.
Еще одно отступление: подразумевается что читатель уже знаком с explain. Часто сам запрос немного модифицируется оптимизатором, поэтому для того, чтобы понять, почему использовался или нет тот или иной индекс, следует вызвать а затем который и покажет измененный оптимизатором запрос.
Покрывающий индекс — от толстых таблиц к индексам
Итак задача: пусть у нас есть довольно простой запрос, который выполняется довольно часто, но для такого частого вызова относительно медленно. Рассмотрим стратегию приведения нашего запроса к using index, как к наиболее быстрому выбору.
Почему using index? Да, MySQL используют только B-tree индексы, но тем не менее MySQL старается по возможности держать индексы целиком в памяти (и при этом может даже добавить поверх них адаптивные хеш-индексы) — собственно все это и дает сказочный прирост производительности MySQL по отношению к другим базам данных. К тому же оптимизатор зачастую предпочтет использовать хоть и не лучший, но уже загруженный в память индекс, нежели более лучший, но на диске (для type=index/range). Отсюда несколько выводов:
- слишком тяжелые индексы — зло. Либо они не будут использоваться потому что они еще не в памяти, либо их не будут грузить в память потому что при этом вытеснятся другие индексы.
- если размер индекса сопоставим с размером таблицы, либо совокупность используемых индексов для разных частых запросов существенно превышает размер памяти сервера — существенной оптимизации не добиться.
- Нюанс — индексировать/сортировать по TEXT — обрекать себя на постоянный using filesort.
Один тонкий момент, про который иногда забываешь — MySQL создает только кластерные индексы. Кластерный — по сути указывающий не на абсолютное положение записи в таблице, а (условно) на запись первичного ключа, который в свою очередь позволяет извлечь саму искомую запись. Но MySQL, не мудрствуя лукаво, для того чтобы обойтись без второго лукапа, поступает просто — расширяя любой ключ на ширину первичного ключа. Таким образом если у вас в таблице primary key (ID), key (A,B,C), то в реальности у вас второй ключ не (A,B,C), а (A,B,C,ID). Отсюда мораль — толстый первичный ключ суть зло.
Следует указать на разницу в кешировании запросов в разных базах. Если PostgreSQL/Oracle кешируют планы запросов (как бы prepare for some timeout), то MySQL просто кеширует СТРОКУ запроса (включая значение параметров) и сохраняет результат запроса. То есть если последовательно селектировать несколько раз — то, если DDD не содержит изменяющихся функций, и таблица AAA не изменилась (в смысле используемой изоляции), результат будет взят прямо из кеша. Довольно спорное улучшение.
Таким образом, считаем, что мы не просто вызываем один и тот же запрос несколько раз. Параметры запроса меняются, данные таблицы меняются. Наилучший вариант — использование покрывающего индекса. Какой же индекс будет покрывающим?
- Во-первых, смотрим на клоз order by. Используемый индекс должен начинаться с тех же столбцов что упомянуты в order by, в той же или в полностью обратной сортировке. Если сортировка не прямая и не обратная — индекс не может быть использован. Здесь есть одно но… MySQL до сих пор не поддерживает индексов со смешанными сортировками. Индекс всегда asc. Так что если у вас есть order by A asc, B desc — распрощайтесь с using index.
- Столбцы, которые извлекаются, должны присутствовать в покрывающем индексе. Очень часто это невыполнимое условие в связи с бесконечным ростом индекса, что, как известно, зло. Поэтому существует способ обойти этот момент — использование self join‘а. То есть разделение запроса на выбор строк и извлечение данных. Во-первых, выбираем по заданному условию только столбцы первичного ключа (который всегда присутствует в кластером индексе), и во-вторых, полученный результат джойним к селекту всех требуемых столбцов, используя этот самый первичный ключ. Таким образом у нас будет чистый using index в первом селекте, и eq_ref (суть множественный const) для второго селекта. Итак, мы получаем что-то похожее на:
- Далее клоз where. Здесь в худшем случае мы можем перебрать весь индекс (type=index), но по возможности стоит стремиться использовать функции, не выводящие за рамки type=range (>, >=,
Источник
Оптимизация SQL запросов или розыск опасных преступников
Кейс компании Appbooster
Полагаю, практически каждый проект, использующий Ruby on Rails и Postgres в качестве основного вооружения на бэкенде находится в перманентной борьбе между скоростью разработки, читаемостью/поддерживаемостью кода и скоростью работы проекта в продакшене. Я расскажу о своем опыте балансирования между этими тремя китами в кейсе, где на входе страдали читаемость и скорость работы, а на выходе получилось сделать то, что до меня безуспешно пытались сделать несколько талантливых инженеров.

Полностью вся история займёт несколько частей. Это первая, где я расскажу о том что такое PMDSC для оптимизации SQL-запросов, поделюсь полезными инструментами измерения эффективности запросов в postgres и напомню об одной полезной старой шпаргалке, которая до сих пор актуальна.
Сейчас, спустя какое-то время, “задним умом” я понимаю, что на входе в этот кейс совершенно не ожидал что у меня всё получится. Поэтому этот пост будет полезен скорее для смелых и не самых опытных разработчиков, чем для супер-сеньоров видавших рельсы с голым SQL.
Вводные данные
Мы в Appbooster занимаемся продвижением мобильных приложений. Чтобы легко выдвигать и проверять гипотезы мы разрабатываем несколько своих приложений. Бэкенд большинства из них это Rails API и Postgresql.
Герой этой публикации разрабатывается с конца 2013 года – тогда только-только вышел rails 4.1.0.beta1. С тех пор проект вырос в полноценно нагруженное веб-приложение, которое крутится на нескольких серверах в Amazon EC2 c отдельным инстансом базы данных в Amazon RDS (db.t3.xlarge с 4 vCPU и 16 GB RAM). Пиковые нагрузки доходят до 25k RPM, средняя нагрузка днём 8-10k RPM.
С инстанса базы данных, точнее с её кредитного баланса и началась эта история.
Как работает инстанс Postgres типа “t” в Амазон RDS: если ваша база данных работает со средним потреблением процессорного времени ниже определенного значения, то у вас на счету накапливаются кредиты, которые инстанс может тратить на потребление процессора в часы высокой нагрузки – это позволяет не переплачивать за серверные мощности и справляться с высокой нагрузкой. Более подробно о том за что и сколько платят, используя AWS можно прочитать в статье нашего CTO.
Баланс кредитов в определенный момент исчерпался. Некоторое время этому не придавалось большого значения, потому как баланс кредитов можно пополнять за счет денег – нам это стоило около $20 в месяц, что не очень ощутимо для общих затрат на аренду вычислительных мощностей. В продуктовой разработке принято в первую очередь уделять внимание задачам сформулированным из бизнес требований. Повышенное потребление процессорной мощности сервером базы данных вписывается в технический долг и покрывается небольшими затратами на покупку баланса кредитов.
В один прекрасный день, я написал в ежедневном саммари о том, что очень устал тушить периодически возникающие в разных местах проекта “пожары”. Если так будет продолжаться, то бизнес задачам будет уделять время выгоревший разработчик. В тот же день я подошел к главному менеджеру проектов, объяснил расклад и попросил время на расследование причин периодических пожаров и ремонт. Получив добро, я начал собирать данные из разных систем мониторинга.
Мы используем Newrelic для отслеживания общего времени отклика за сутки. Картина выглядела так:
Желтым на графике выделена часть времени ответа, которую занимает Postgres. Как видно, иногда время ответа доходило до 1000 ms и большую часть времени именно база данных размышляла над ответом. Значит надо смотреть что происходит с SQL запросами.
PMDSC – простая и понятная практика для любой скучной работы оптимизации SQL запросов
Play it!
Measure it!
Draw it!
Suppose it!
Check it!
Play it!
Пожалуй, самая важная часть всей практики. Когда кто-то произносит фразу «Оптимизация SQL запросов» – это скорее вызывает приступ зевоты и скуку у абсолютного большинства людей. Когда ты произносишь «Детективное расследование и розыск опасных злодеев» – это сильнее вовлекает и настраивает тебя самого на нужный лад. Поэтому важно войти в игру. Мне понравилось играть в детектива. Я представлял себе что проблемы с базой данных либо опасные преступники, либо редкие болезни. А себя представлял в роли Шерлока Холмса, Лейтенанта Коломбо или Доктора Хауса. Выбирай героя на свой вкус и вперед!
Measure It!
Для анализа статистики запросов, я установил PgHero. Это очень удобный способ читать данные из расширения pg_stat_statements для Postgres. Заходим в /queries и смотрим на статистику всех запросов за последние сутки. Сортировка запросов по умолчанию по колонке Total Time – доля общего времени которое база данных обрабатывает запрос – ценный источник в поиске подозреваемых. Average Time – сколько в среднем запрос выполняется. Calls – сколько запросов было за выбранное время. PgHero считает медленными запросы, которые выполнялись более 100 раз за сутки и занимали в среднем более 20 миллисекунд. Список медленных запросов на первой странице, сразу после списка дублирующихся индексов.
Берём первый в списке и смотрим детали запроса, тут же можно посмотреть его explain analyze. Eсли planning time сильно меньше execution time, значит с этим запросом что-то не так и мы концентрируем внимание на этом подозреваемом.
В PgHero есть свой способ визуализации, но мне больше понравилось использовать explain.depesz.com копируя туда данные из explain analyze.
Один из подозреваемых запросов использует Index Scan. На визуализации видно что этот индекс не эффективен и является слабым местом – выделено красным. Отлично! Мы изучили следы подозреваемого и нашли важную улику! Правосудие неизбежно!
Draw it!
Нарисуем множество данных которые используются в проблемной части запроса. Будет полезно сравнить с тем какие данные покрывает индекс.
Немного контекста. Мы тестировали один из способов удержания аудитории в приложении – что-то вроде лотереи, в которой можно выиграть немного внутренней валюты. Делаешь ставку, загадываешь число от 0 до 100 и забираешь весь банк, если твое число оказалось ближе всех к тому что получил генератор случайных чисел. Мы назвали это “Арена”, а розыгрыши назвали “Битвами”.
В базе данных на момент расследования около пятисот тысяч записей о битвах. В проблемной части запроса мы ищем битвы в которых ставка не превышает баланс пользователя и статус битвы – жду игроков. Видим что пересечение множеств (выделено оранжевым) совсем маленькое количество записей.
Индекс, используемый в подозреваемой части запроса покрывает все созданные битвы по полю created_at. Запрос пробегает по 505330 записям из которых выбирает 40, а 505290 отсеивает. Выглядит очень расточительно.
Suppose it!
Выдвигаем гипотезу. Что поможет базе данных найти сорок записей из пятисот тысяч? Попробуем сделать индекс который покрывает поле ставка, только для битв со статусом “жду игроков” – паршиал индекс.
Паршиал индекс – существует только для тех записей, которые подходят под условие: поле статус равно “жду_игроков” и индексирует поле ставка – ровно то что в условии запроса. Очень выгодно использовать именно этот индекс: он занимает всего 40 килобайт и не покрывает те битвы которые уже сыграны и не нужны нам для получения выборки. Для сравнения – индекс index_arena_battles_on_created_at, который использовался подозреваемым занимает около 40 Мб, а таблица с битвами около 70 Мб. Этот индекс можно смело удалить, если его не используют другие запросы.
Check it!
Выкатываем миграцию с новым индексом в продакшен и наблюдаем за тем как изменился отклик эндпоинта с битвами.
На графике видно во сколько мы выкатили миграцию. Вечером 6 декабря время отклика уменьшилось примерно в 10 раз с
50ms. Подозреваемый в суде получил статус заключенного и теперь сидит в тюрьме. Отлично!
Prison Break
Спустя несколько дней мы поняли что рано радовались. Похоже, заключенный нашел сообщников, разработал и осуществил план побега.
Утром 11 декабря планировщик запросов postgres решил что использовать свежий паршиал индекс, ему больше не выгодно и стал снова использовать старый.
Мы снова на этапе Suppose it! Собираем дифференциальный диагноз, в духе доктора Хауса:
- Возможно, надо оптимизировать настройки postgres;
- может быть, минорно обновить postgres до новой версии (9.6.11 –> 9.6.15);
- а может быть, снова внимательно изучить какой SQL-запрос формирует Рельса?
Мы проверили все три гипотезы. Последняя привела нас на след сообщника.
Давай вместе пройдемся по этому SQL. Выбираем все поля битвы из таблицы битв статус которых равен “жду игроков” и ставка меньше или равна некоему числу. Пока все понятно. Следующее слагаемое условия выглядит жутко.
Мы ищем не существующий результат подзапроса. Достань первое поле из таблицы участий в битвах, где идентификатор битвы совпадает и профиль участника принадлежит нашему игроку. Попробую нарисовать множество описанное в подзапросе.
Сложно осмыслить, но в итоге этим подзапросом мы пробовали исключить те битвы в которых игрок уже участвует. Смотрим общий explain запроса и видим Planning time: 0.180 ms, Execution time: 12.119 ms. Мы нашли сообщника!
Настало время моей любимой шпаргалки, которая гуляет по интернетам с 2008 года. Вот она:
Да! Как только в запросе встречается что-то, что должно исключить какое-то количество записей на основе данных из другой таблицы, в памяти должен всплыть этот мем с бородой и кудрями.
На самом деле вот что нам нужно:
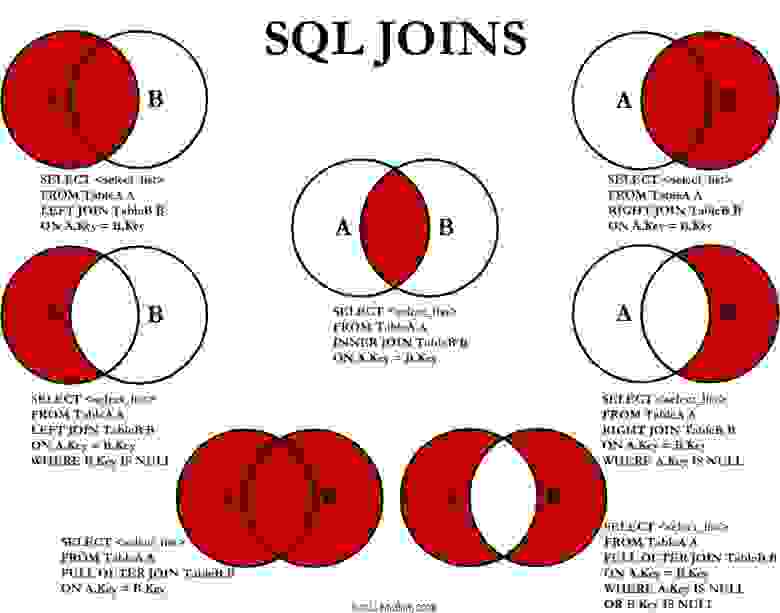
Сохрани себе эту картинку, а еще лучше распечатай и повесь в нескольких местах в офисе.
Переписываем подзапрос на LEFT JOIN WHERE B.key IS NULL, получаем:
Исправленный запрос бежит сразу по двум таблицам. Мы присоединили “слева” таблицу с записями участий в битвах пользователя и добавили условие что идентификатор участия не существует. Смотрим explain analyze полученного запроса: Planning time: 0.185 ms, Execution time: 0.337 ms. Отлично! Теперь планировщик запросов не будет сомневаться что ему стоит использовать паршиал индекс, а будет использовать самый быстрый вариант. Сбежавший заключенный и его сообщник приговорены на пожизненное заключение в заведении строгого режима. Сбежать им будет сложнее.
Источник



