
- Методы обработки результатов исследования
- Понятие и сущность, предназначение и специфика статистики. Методы и приёмы обработки результатов исследования, их описание, упорядочение, анализ, синтез, сравнение, интерпретации и обобщение. Характеристика и особенности качественных методов исследования.
- Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
- Подобные документы
- Способы обработки результатов диагностики
Методы обработки результатов исследования
Понятие и сущность, предназначение и специфика статистики. Методы и приёмы обработки результатов исследования, их описание, упорядочение, анализ, синтез, сравнение, интерпретации и обобщение. Характеристика и особенности качественных методов исследования.
| Рубрика | Экономика и экономическая теория |
| Вид | реферат |
| Язык | русский |
| Дата добавления | 30.04.2016 |
| Размер файла | 17,2 K |

Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Размещено на http://www.allbest.ru/
Методы обработки результатов исследования
1 Методы статистического описания
2 Методы и приёмы обработки результатов исследования: описание, упорядочение, анализ, синтез, сравнение, интерпретации, обобщение
3 Качественные методы
4 Количественный анализ
1. Методы статистического описания
Слово «статистика» происходит от латинского status — состояние дел.
Статистика — это отрасль знаний, в которой излагаются общие вопросы сбора, измерения и анализа массовых статистических (количестве-нных или качественных) данных; изучение количественной стороны массо-вых общественных явлений в числовой форме.
Статистические методы включают в себя и экспериментальное, и теоретическое начала. Статистика исходит прежде всего из опыта; недаром ее зачастую определяют как науку об общих способах обработки результатов эксперимента.
Статистические методы описания — методы анализа статистических данных. Выделяют методы прикладной статистики, которые могут приме-няться во всех областях научных исследований и любых отраслях народного хозяйства, и другие статистические методы, применимость которых ограни-чена той или иной сферой. Имеются в виду такие методы, как статистический приемочный контроль, статистическое регулирование технологических про-цессов, надёжность и испытания, планирование экспериментов.
Статистические методы анализа данных применяются практически во всех областях деятельности человека. Их используют всегда, когда необходимо получить и обосновать какие-либо суждения о группе (объектов или субъектов) с некоторой внутренней неоднородностью.
Целесообразно выделить три вида научной и прикладной деятельности в области статистических методов анализа данных:
а) разработка и исследование методов общего назначения, без учёта специфики области применения;
б) разработка и исследование статистических моделей реальных явлений и процессов в соответствии с потребностями той или иной области деятельности;
в) использование статистических методов и моделей для статистического анализа конкретных данных в решении прикладных задач, например, с целью проведения выборочных обследований.
Также существуют статистические группировки, которые разделяют совокупности тех или иных данных на группы однородные в каком-либо отношении. Существует три вида группировки: аналитическая, типологическая, структурная.
1 Аналитическая группировка — позволяет выявить связь между группировками.
2 Типологическая группировка — разделение исследуемой совокупности на однородные группы.
3 Структурная группировка — в которой происходит разделение однородной совокупности на группы, по определенному признаку.
2. Методы и приёмы обработки результатов исследования: описание, упорядочение, анализ, синтез, сравненные, интерпретация, обобщение
Описание — это результат наблюдения и эксперимента, состоящий в фиксировании данных с помощью определенных систем обозначений, принятых в науке. Описание как метод научного исследования производится как путем обычного языка, так и специальными средствами, составляющими язык науки (символы, знаки, матрицы, графики и т. д.). Важнейшими требованиями к научному описанию являются точность, логическая строгость и простота.
Упорядочение — процесс расположения элементов, фактов, записей, определённых результатов исследований по какому-либо определённому объединяющему их фатору.
Анализ — фактическое или мысленное расчленение целостного предмета на составные части (стороны, признаки, свойства, отношения или связи) с целью его всестороннего изучения. Анализ, разлагая предметы на части и изучая каждую из них, должен обязательно рассматривать их не сами по себе, а как части единого целого.
Синтез — фактическое или мысленное воссоединение целого из частей, элементов, сторон и связей, выделенных с помощью анализа. С помощью синтеза мы восстанавливаем предмет как конкретное целое во всем многообразии его проявлений. В естественных науках анализ и синтез применяются не только теоретически, но и практически. В социально-экономических и гуманитарных исследованиях предмет исследования подвергается лишь мысленному расчленению и воссоединению. Анализ и синтез как методы научного исследования выступают в органичном единстве.
Сравнение — сопоставление объектов с целью выявления признаков сходства или признаков различия между этими объектами. Известный афоризм гласит: «Все познается в сравнении».
Для того чтобы сравнение было объективным, оно должно отвечать следующим требованиям:
1 Сравнивать необходимо сопоставимые явления и предметы (например, нет смысла сравнивать человека с треугольником или животное с метеоритом и т. д.);
2 Сравнение должно осуществляться по наиболее важным и существенным признакам, так как сравнение по несущественным признакам может привести и заблуждению.
Интерпретация — совокупность значений (смыслов), придаваемых так или иначе элементам (выражениям, формулам, символам) какой-либо естественнонаучной или абстрактно-дедуктивной теории (в случаях же, когда «осмыслению» подвергаются сами элементы этой теории, то говорят также об интерпретации символов, формул и т. д.).
Обобщение — логический процесс перехода от единичного к общему, от менее общего к более общему знанию, при этом устанавливаются общие свойства и признаки исследуемых объектов. Получение обобщенного знания означает более глубокое отражение действительности, проникновение в ее сущность.
Качественные методы — в исследовательской практике, понятие качественных исследований трактуется достаточно широко и не всегда однозначно. Как правило, качественные методы понимаются как исследования, где данные получены путём наблюдения, интервью, анализа каких-либо документов (текстовых, визуальных — фото — и видео источников). Зачастую это свидетельства, собранные несколькими разными способами. статистический обработка качественный
Если в количественном исследовании на вопросы: как часто? как долго? мы получаем достаточно объективный ответ, фиксирующий количество, то в качественном исследовании на вопрос: как вам понравился фильм? мы получаем номинальный ответ, обозначающий качество отношения или, другими словами, субъективную ценность, значимость данного предмета для индивида в его собственных словах, исходя из его социального опыта (например, фильм скучный, интересный, любопытный и т. д.). Такие данные анализируются не математически, а путем аналитического раскрытия их субъективного смысла.
Качественное исследование проводится прежде всего для изучения индивидуального аспекта социальной практики — реального опыта жизни конкретных людей в конкретных обстоятельствах. Но через анализ индивидуального могут исследоваться и более широкие социальные проблемы, касающиеся социальных групп, движений или даже характера функционирования социальных институтов в конкретной социальной ситуации.
Из чего состоит качественное исследование?
Это прежде всего эмпирические неструктурированные свидетельства, полученные из разнообразных человеческих документов или «документов жизни», как их называют: текстовые записи интервью и наблюдений, личные и официальные документы, фотографии и т.д.
Вторым компонентом качественного исследования являются аналитические и интерпретативные процедуры, используемые для анализа. Они включают в себя разные техники, начиная от описания и комментирования до кодировки и категоризации.
Третьим компонентом является повествовательный отчет. Жанр и стиль такого отчета различается в зависимости от целей исследования и адресата, которому он предназначен: от широкой публики до научного доклада или дискуссии. По своему стилю обычно это живое описание с большим количеством цитат из устной или письменной речи исследуемых. По жанру — интерпретация, размышление, гипотезы или теоретизирование о данном феномене социальной жизни.
То есть качественное исследование как процесс изучения отдельной проблемы предполагает не только наличие особых (качественных) данных, но и специфические приемы их сбора, обработки и анализа. Поэтому в дальнейшем для обозначения качественного исследования используется более обобщенный термин — качественный метод, или качественные методы как совокупность разных тактик.
Каковы разновидности качественных методов?
По фокусу интереса или тактикам проведения исследования:
1 Изучение случая;
2 Этнографическое описание;
3 Восхождение к теории;
4 История жизни, история семьи, ист. исследование.
По форме аналитического представления конечных результатов:
1 Дословное описание полученных данных, когда информанты рассказывают о себе «своими голосами» без интерпретаций со стороны исследователя. Такая позиция позволяет избежать субъективизма в трактовке.
2 Стратегии редактирования и систематизирования (редактированного) полученных данных при коротком комментировании
3 Построение теории. Считают, что концептуальное представление о реальной практике и теоретические рассуждения о природе феномена являются наиболее ценным результатом качественного исследования.
Количественный анализ — позволяет получить выраженную количественно информацию по ограниченному кругу проблем, но от большого числа людей, что позволяет обрабатывать ее статистическими методами и распространять результаты на всех потребителей.
Необходимо различать два основных направления в использовании количественных методов в педагогике: первое — для обработки результатов наблюдений и экспериментов, второе — для моделирования, диагностики, прогнозирования, компьютеризации учебно-воспитательного процесса. Методы первой группы хорошо известны и достаточно широко применяются.
Статистический метод содержит следующие конкретные методики.
Регистрация — выявление определенного качества у явлений
данного класса и подсчет количества по наличию или отсутствию
Ранжирование — расположение собранных данных в определенной последовательности (убывания или нарастания зафиксированных показателей), определение места в этом ряду изучаемых
объектов (например, составление списка учеников в зависимости
от числа пропущенных занятий и т. п.).
Шкалирование — присвоение баллов или других цифровых
показателей исследуемым характеристикам. Этим достигается
Все более мощным преобразующим средством педагогических
исследований становится моделирование. Научная модель — это мысленно представленная или материально реализованная система, которая адекватно отображает предмет исследования и способна замещать его так, что изучение модели позволяет получить новую информацию об этом объекте. Моделирование — это метод создания и исследования моделей. Главное преимущество моделирования — целостность представления информации.
Моделирование успешно применяется для решения следующих важных задач:
— оптимизации структуры учебного процесса;
— улучшения планирования учебного процесса;
— управления познавательной деятельностью, учебно-воспитательным процессом;
— диагностики, прогнозирования, проектирования обучения.
Размещено на Allbest.ru
Подобные документы
Краткая история зарождения и развития статистики как науки. Предмет изучения и характеристика основных задач статистики. Статистические методы сбора и обработки данных для получения достоверных оценок и результатов. Источники статистических данных.
лекция [23,7 K], добавлен 13.02.2011
Индексы в статистике, их применение при анализе динамики, выполнении плановых заданий и территориальных сравнений, сравниваемый и базисный уровни. Формирование информационной базы статистического исследования, сводка и группировка результатов наблюдения.
контрольная работа [86,2 K], добавлен 19.10.2010
Понятие экономического анализа как науки, его сущность, предмет, общая характеристика методов и социально-экономическая эффективность. Основные группы эконометрических методов анализа и обработки данных. Факторный анализ экономических данных предприятия.
реферат [44,7 K], добавлен 04.03.2010
Понятие статистики как науки, предмет и методы ее изучения, основные цели и задачи. Категории статистики и ее показатели, способы представления результатов. Сущность и классификация относительных и средних величин. Понятие ряда динамики и его анализ.
реферат [192,6 K], добавлен 15.05.2009
Статистика как одна из древнейших отраслей знаний, возникшая на базе хозяйственного учета. Развитие статистики как науки. Определение предмета статистики. Статистическое наблюдение как этап статистического исследования. Методы и показатели статистики.
контрольная работа [38,9 K], добавлен 20.01.2010
Понятие и сущность цен и инфляции, их значение. Задачи статистики цен. Характеристика системы показателей статистики цен. Принципы и методы регистрации цен. Особенности методов расчета и анализа их индексов. Методы оценки уровня и динамики инфляции.
курсовая работа [70,9 K], добавлен 01.12.2010
Теоретические основы и базовые методы оценки бизнеса. Фундаментальные компоненты оценки рыночной стоимости ООО «Пермархбюро»: определение цены земельного участка, здания и предприятия затратным и доходным подходом, обобщение результатов исследования.
дипломная работа [214,3 K], добавлен 01.05.2011
Источник
Способы обработки результатов диагностики
Раздел 4. Представление и первичная обработка результатов исследования
Обработка данных психологических исследований – отдельный раздел экспериментальной психологии, тесно связанный с математической статистикой и логикой. Обработка данных направлена на решение следующих задач:
• упорядочивание полученного материала;
• обнаружение и ликвидация ошибок, недочетов, пробелов в сведениях;
• выявление скрытых от непосредственного восприятия тенденций, закономерностей и связей;
• обнаружение новых фактов, которые не ожидались и не были замечены в ходе эмпирического процесса;
• выяснение уровня достоверности, надежности и точности собранных данных и получение на их базе научно обоснованных результатов.
Различают количественную и качественную обработку данных. Количественная обработка – это работа с измеренными характеристиками изучаемого объекта, его «объективированными» свойствами. Качественная обработка представляет собой способ проникновения в сущность объекта путем выявления его неизмеряемых свойств.
Количественная обработка направлена в основном на формальное, внешнее изучение объекта, качественная – преимущественно на содержательное, внутреннее его изучение. В количественном исследовании доминирует аналитическая составляющая познания, что отражено и в названиях количественных методов обработки эмпирического материала: корреляционный анализ, факторный анализ и т. д. Реализуется количественная обработка с помощью математико-статистических методов.
В качественной обработке преобладают синтетические способы познания. Обобщение проводится на следующем этапе исследовательского процесса – интерпретационном. При качественной обработке данных главное заключается в соответствующем представлении сведений об изучаемом явлении, обеспечивающем дальнейшее его теоретическое изучение. Обычно результатом качественной обработки является интегрированное представление о множестве свойств объекта или множестве объектов в форме классификаций и типологий. Качественная обработка в значительной мере апеллирует к методам логики.
Противопоставление друг другу качественной и количественной обработки довольно условно. Количественный анализ без последующей качественной обработки бессмыслен, так как сам по себе не приводит к приращению знаний, а качественное изучение объекта без базовых количественных данных в научном познании невозможно. Без количественных данных научное познание – чисто умозрительная процедура.
Единство количественной и качественной обработки наглядно представлено во многих методах обработки данных: факторном и таксономическом анализе, шкалировании, классификации и др. Наиболее распространены такие приемы количественной обработки, как классификация, типологизация, систематизация, периодизация, казуистика.
Качественная обработка естественным образом выливается в описание и объяснение изучаемых явлений, что составляет уже следующий уровень их изучения, осуществляемый на стадии интерпретации результатов. Количественная же обработка полностью относится к этапу обработки данных.
Все методы количественной обработки принято подразделять на первичные и вторичные.
Первичная статистическая обработка нацелена на упорядочивание информации об объекте и предмете изучения. На этой стадии «сырые» сведения группируются по тем или иным критериям, заносятся в сводные таблицы. Первично обработанные данные, представленные в удобной форме, дают исследователю в первом приближении понятие о характере всей совокупности данных в целом: об их однородности – неоднородности, компактности – разбросанности, четкости – размытости и т. д. Эта информация хорошо считывается с наглядных форм представления данных и дает сведения об их распределении.
В ходе применения первичных методов статистической обработки получаются показатели, непосредственно связанные с производимыми в исследовании измерениями.
К основным методам первичной статистической обработки относятся: вычисление мер центральной тенденции и мер разброса (изменчивости) данных.
Первичный статистический анализ всей совокупности полученных в исследовании данных дает возможность охарактеризовать ее в предельно сжатом виде и ответить на два главных вопроса: 1) какое значение наиболее характерно для выборки; 2) велик ли разброс данных относительно этого характерного значения, т. е. какова «размытость» данных. Для решения первого вопроса вычисляются меры центральной тенденции, для решения второго – меры изменчивости (или разброса). Эти статистические показатели используются в отношении количественных данных, представленных в порядковой, интервальной или пропорциональной шкале.
Меры центральной тенденции – это величины, вокруг которых группируются остальные данные. Данные величины являются как бы обобщающими всю выборку показателями, что, во-первых, позволяет судить по ним обо всей выборке, а во-вторых, дает возможность сравнивать разные выборки, разные серии между собой. К мерам центральной тенденции в обработке результатов психологических исследований относятся: выборочное среднее, медиана, мода.
Выборочное среднее (М) – это результат деления суммы всех значений (X) на их количество (N).
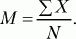
Медиана (Me) – это значение, выше и ниже которого количество отличающихся значений одинаково, т. е. это центральное значение в последовательном ряду данных. Медиана не обязательно должна совпадать с конкретным значением. Совпадение происходит в случае нечетного числа значений (ответов), несовпадение – при четном их числе. В последнем случае медиана вычисляется как среднее арифметическое двух центральных значений в упорядоченном ряду.
Мода (Мо) – это значение, наиболее часто встречающееся в выборке, т. е. значение с наибольшей частотой. Если все значения в группе встречаются одинаково часто, то считается, что моды нет. Если два соседних значения имеют одинаковую частоту и больше частоты любого другого значения, мода есть среднее этих двух значений. Если то же самое относится к двум несмежным значениям, то существует две моды, а группа оценок является бимодальной.
Обычно выборочное среднее применяется при стремлении к наибольшей точности в определении центральной тенденции. Медиана вычисляется в том случае, когда в серии есть «нетипичные» данные, резко влияющие на среднее. Мода используется в ситуациях, когда не нужна высокая точность, но важна быстрота определения меры центральной тенденции.
Вычисление всех трех показателей производится также для оценки распределения данных. При нормальном распределении значения выборочного среднего, медианы и моды одинаковы или очень близки.
Меры разброса (изменчивости) – это статистические показатели, характеризующие различия между отдельными значениями выборки. Они позволяют судить о степени однородности полученного множества, его компактности, а косвенно и о надежности полученных данных и вытекающих из них результатов. Наиболее используемые в психологических исследованиях показатели: среднее отклонение, дисперсия, стандартное отклонение.
Размах (Р) – это интервал между максимальным и минимальным значениями признака. Определяется легко и быстро, но чувствителен к случайностям, особенно при малом числе данных.
Среднее отклонение (МД) – это среднеарифметическое разницы (по абсолютной величине) между каждым значением в выборке и ее средним.
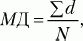
где d = |Х – М |, М – среднее выборки, X – конкретное значение, N – число значений.
Множество всех конкретных отклонений от среднего характеризует изменчивость данных, но если не взять их по абсолютной величине, то их сумма будет равна нулю и мы не получим информации об их изменчивости. Среднее отклонение показывает степень скученности данных вокруг выборочного среднего. Кстати, иногда при определении этой характеристики выборки вместо среднего (М) берут иные меры центральной тенденции – моду или медиану.
Дисперсия (D) характеризует отклонения от средней величины в данной выборке. Вычисление дисперсии позляет избежать нулевой суммы конкретных разниц (d = Х – М)не через их абсолютные величины, а через их возведение в квадрат:

где d = |Х – М|, М – среднее выборки, X – конкретное значение, N – число значений.
Стандартное отклонение (б). Из-за возведения в квадрат отдельных отклонений d при вычислении дисперсии полученная величина оказывается далекой от первоначальных отклонений и потому не дает о них наглядного представления. Чтобы этого избежать и получить характеристику, сопоставимую со средним отклонением, проделывают обратную математическую операцию – из дисперсии извлекают квадратный корень. Его положительное значение и принимается за меру изменчивости, именуемую среднеквадратическим, или стандартным, отклонением:

где d = |Х– М|, М – среднее выборки, X– конкретное значение, N – число значений.
МД, D и ? применимы для интервальных и пропорционных данных. Для порядковых данных в качестве меры изменчивости обычно берут полуквартильное отклонение (Q),именуемое еще полуквартильным коэффициентом. Вычисляется этот показатель следующим образом. Вся область распределения данных делится на четыре равные части. Если отсчитывать наблюдения начиная от минимальной величины на измерительной шкале, то первая четверть шкалы называется первым квартилем, а точка, отделяющая его от остальной части шкалы, обозначается символом Qv Вторые 25 % распределения – второй квартиль, а соответствующая точка на шкале – Q2. Между третьей и четвертой четвертями распределения расположена точка Q3. Полуквартильный коэффициент определяется как половина интервала между первым и третьим квартилями:
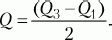
При симметричном распределении точка Q2 совпадет с медианой (а следовательно, и со средним), и тогда можно вычислить коэффициент Q для характеристики разброса данных относительно середины распределения. При несимметричном распределении этого недостаточно. Тогда дополнительно вычисляют коэффициенты для левого и правого участков:
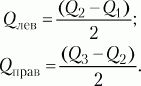
Вторичная статистическая обработка данных
К вторичным относят такие методы статистической обработки, с помощью которых на базе первичных данных выявляют скрытые в них статистические закономерности. Вторичные методы можно подразделить на способы оценки значимости различий и способы установления статистических взаимосвязей.
Способы оценки значимости различий. Для сравнения выборочных средних величин, принадлежащих к двум совокупностям данных, и для решения вопроса о том, отличаются ли средние значения статистически достоверно друг от друга, используют t-критерий Стьюдента. Его формула выглядит следующим образом:
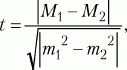
где М1, М2 – выборочные средние значения сравниваемых выборок, m1, m2 – интегрированные показатели отклонений частных значений из двух сравниваемых выборок, вычисляются по следующим формулам:
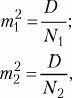
где D1, D2 – дисперсии первой и второй выборок, N1, N2 – число значений в первой и второй выборках.
После вычисления значения показателя t по таблице критических значений (см. Статистическое приложение 1), заданного числа степеней свободы (N1 + N2 – 2) и избранной вероятности допустимой ошибки (0,05, 0,01, 0,02, 001 и т.д.) находят табличное значение t. Если вычисленное значение t больше или равно табличному, делают вывод о том, что сравниваемые средние значения двух выборок статистически достоверно различаются с вероятностью допустимой ошибки, меньшей или равной избранной.
Если в процессе исследования встает задача сравнить неабсолютные средние величины, частотные распределения данных, то используется ?2критерий (см. Приложение 2). Его формула выглядит следующим образом:
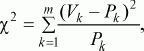
где Pk – частоты распределения в первом замере, Vk – частоты распределения во втором замере, m – общее число групп, на которые разделились результаты замеров.
После вычисления значения показателя ?2по таблице критических значений (см. Статистическое приложение 2), заданного числа степеней свободы (m – 1) и избранной вероятности допустимой ошибки (0,05, 0,0 ?2t больше или равно табличному) делают вывод о том, что сравниваемые распределения данных в двух выборках статистически достоверно различаются с вероятностью допустимой ошибки, меньшей или равной избранной.
Для сравнения дисперсий двух выборок используется F-критерий Фишера. Его формула выглядит следующим образом:
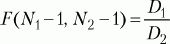
где D1, D2 – дисперсии первой и второй выборок, N1, N2 – число значений в первой и второй выборках.
После вычисления значения показателя F по таблице критических значений (см. Статистическое приложение 3), заданного числа степеней свободы (N1 – 1, N2 – 1) находится Fкр. Если вычисленное значение F больше или равно табличному, делают вывод о том, что различие дисперсий в двух выборках статистически достоверно.
Способы установления статистических взаимосвязей. Предыдущие показатели характеризуют совокупность данных по какому-либо одному признаку. Этот изменяющийся признак называют переменной величиной или просто переменной. Меры связи выявляют соотношения между двумя переменными или между двумя выборками. Эти связи, или корреляции, определяют через вычисление коэффициентов корреляции. Однако наличие корреляции не означает, что между переменными существует причинная (или функциональная) связь. Функциональная зависимость – это частный случай корреляции. Даже если связь причинна, корреляционные показатели не могут указать, какая из двух переменных является причиной, а какая – следствием. Кроме того, любая обнаруженная в психологических исследованиях связь, как правило, существует благодаря и другим переменным, а не только двум рассматриваемым. К тому же взаимосвязи психологических признаков столь сложны, что их обусловленность одной причиной вряд ли состоятельна, они детерминированы множеством причин.
По тесноте связи можно выделить следующие виды корреляции: полная, высокая, выраженная, частичная; отсутствие корреляции. Эти виды корреляций определяют в зависимости от значения коэффициента корреляции.
При полной корреляции его абсолютные значения равны или очень близки к 1. В этом случае устанавливается обязательная взаимозависимость между переменными. Здесь вероятна функциональная зависимость.
Высокая корреляция устанавливается при абсолютном значении коэффициента 0,8–0,9.Выраженная корреляция считается при абсолютном значении коэффициента 0,6–0,7.Частичная корреляция существует при абсолютном значении коэффициента 0,4–0,5.
Абсолютные значения коэффициента корреляции менее 0,4 свидетельствуют об очень слабой корреляционной связи и, как правило, в расчет не принимаются. Отсутствие корреляции констатируется при значении коэффициента 0.
Кроме того, в психологии при оценке тесноты связи используют так называемую «частную» классификацию корреляционных связей. Она ориентирована не на абсолютную величину коэффициентов корреляции, а на уровень значимости этой величины при определенном объеме выборки. Эта классификация применяется при статистической оценке гипотез. При данном подходе предполагается, что чем больше выборка, тем меньшее значение коэффициента корреляции может быть принято для признания достоверности связей, а для малых выборок даже абсолютно большое значение коэффициента может оказаться недостоверным.[86]
По направленности выделяют следующие виды корреляционных связей: положительная (прямая) и отрицательная (обратная). Положительная (прямая) корреляционная связь регистрируется при коэффициенте со знаком «плюс»: при увеличении значения одной переменной наблюдается увеличение другой. Отрицательная (обратная) корреляция имеет место при значении коэффициента со знаком «минус». Это означает обратную зависимость: увеличение значения одной переменной влечет за собой уменьшение другой.
По форме различают следующие виды корреляционных связей: прямолинейную и криволинейную. При прямолинейной связи равномерным изменениям одной переменной соответствуют равномерные изменения другой. Если говорить не только о корреляциях, но и о функциональных зависимостях, то такие формы зависимости называют пропорциональными. В психологии строго прямолинейные связи – явление редкое. Прикриволинейной связи равномерное изменение одного признака сочетается с неравномерным изменением другого. Эта ситуация для психологии типична.
Коэффициент линейной корреляции по К. Пирсону (r) вычисляется c помощью следующей формулы:
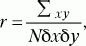
где х – отклонение отдельного значения X от среднего выборки (Мх), у – отклонение отдельного значения Y от среднего выборки (Му), Ьх – стандартное отклонение для X, ?y– стандартное отклонение для Y, N – число пар значений Xи Y.
Оценка значимости коэффициента корреляции проводится по таблице (см. Статистическое приложение 4).
При сравнении порядковых данных применяется коэффициент ранговой корреляции по Ч. Спирмену (R):
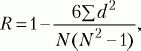
где d – разность рангов (порядковых мест) двух величин, N – число сравниваемых пар величин двух переменных (X и Y).
Оценка значимости коэффициента корреляции проводится по таблице (см. Статистическое приложение 5).
Внедрение в научные исследования автоматизированных средств обработки данных позволяет быстро и точно определять любые количественные характеристики любых массивов данных. Разработаны различные программы для компьютеров, по которым можно проводить соответствующий статистический анализ практически любых выборок. Из массы статистических приемов в психологии наибольшее распространение получили следующие: 1) комплексное вычисление статистик; 2) корреляционный анализ; 3) дисперсионный анализ; 4) регрессионный анализ; 5) факторный анализ; 6) таксономический (кластерный) анализ; 7) шкалирование. Познакомиться с характеристиками этих методов можно в специальной литературе («Статистические методы в педагогике и психологии» Стенли Дж., Гласа Дж. (М., 1976), «Математическая психология» Г.В. Суходольского (СПб., 1997), «Математические методы психологического исследования» А.Д. Наследова (СПб., 2005) и др.).
Источник



