
- Анализ неструктурированных данных и оптимизация их хранения
- HP Storage Optimizer: анализ данных с целью оптимизации их хранения
- HP Control Point: комплексный анализ для снижения бизнес-рисков, связанных с хранением данных
- Заключение
- Использование инструментов Data Science для обработки неструктурированных данных
Анализ неструктурированных данных и оптимизация их хранения
Тема анализа неструктурированных данных сама по себе не нова. Однако в последнее время в эпоху «больших данных» этот вопрос встаёт перед организациями гораздо острее. Многократный рост объёмов хранимых данных в последние годы, его постоянно увеличивающиеся темпы и нарастающее разнообразие хранимой и обрабатываемой информации существенно усложняют задачу управления корпоративными данными. С одной стороны, проблема имеет инфраструктурный характер. Так, по данным IDC, до 60% корпоративных хранилищ занимает информация, не приносящая организации никакой пользы (многочисленные копии одного и того же, разбросанные по разным участкам инфраструктуры хранения данных; информация, к которой никто не обращался несколько нет и уже вряд ли когда-нибудь обратится; прочий «корпоративный мусор»).

С другой стороны, неэффективное управление информацией ведёт к увеличению рисков для бизнеса: хранение персональных данных и прочей конфиденциальной информации на общедоступных информационных ресурсах, появление подозрительных пользовательских зашифрованных архивов, нарушения политик доступа к важной информации и т.д.
В этих обстоятельствах умение качественно анализировать корпоративную информацию и оперативно реагировать на любые несоответствия её хранения политикам и требованиям бизнеса является ключевым показателем зрелости информационной стратегии организации.
Теме аналитики файловых данных посвящён отдельный документ Gartner, вышедший в сентябре 2014 г. под названием «Market Guide for File Analysis Software». В данном документе приводятся следующие типовые сценарии использования аналитического ПО:
- Оптимизация хранения. Наиболее типичный сценарий. Целью внедрения файловой аналитики является снижение объёма хранимых данных, и, тем самым, повышение эффективности их хранения.
Выявление ненужных данных и избавление от них при миграции ИТ-инфраструктуры. Часто инициируются проектами по миграции данных в «облако». Проводится сканирование контента и по его результатам имеющие важность и ценность для бизнеса данные «переезжают» в «облако», а остальные удаляются.
Классификация. Целью таких проектов по анализу является группировка объектов по различным критериям для назначения на них общих политик, понимания ценности и потенциального риска, которые несёт хранимая информация.
Соблюдение нормативов и требований (compliance). Специалисты соответствующих подразделений могут разработать и внедрить политики доступа к важным данным и за счёт встроенной в аналитическое ПО классификации эффективно контролировать их соблюдение.
Управление уровнями доступа. За счёт получения информации об уровне и типе доступа пользователей к файлам и директориям возможно осуществлять информационный менеджмент с целью защиты персональных данных и иной конфиденциальной информации от несанкционированного доступа.
Принимая во внимание данный тренд, компания Hewlett-Packard выпустила на рынок два программных решения, предназначенных для расширенного анализа неструктурированной информации: HP Storage Optimizer и HP Control Point. Первое решение в основном предназначено для специалистов, отвечающих за хранение данных. Второе решение подойдёт не только специалистам ИТ-подразделений, но будет также интересно сотрудникам отделов информационной безопасности, Compliance-служб, а также руководству, определяющим стратегию хранения и использования информации в организации.
В данной статье будет сделан технический обзор обоих продуктов.
HP Storage Optimizer: анализ данных с целью оптимизации их хранения
HP Storage Optimizer объединяет в себе возможности по анализу метаданных объектов в репозиториях неструктурированной информации и назначению политик их иерархического хранения.

Архитектура HP Storage Optimizer
Источники анализируемой информации в терминологии HP Storage Optimizer называются репозиториями. В качестве репозиториев поддерживаются различные файловые системы, а также MS Exchange, MS SharePoint, Hadoop, Lotus Notes, Documentum и многие другие. Есть также возможность заказать разработку коннектора к репозиторию, который в настоящее время не поддерживается продуктом.
HP Storage Optimizer использует собственные соответствующие коннекторы для обращения к анализируемым репозиториям. Информация с коннекторов поступает в компонент под названием Connector Framework Server (обозначенный как «CFS» на картинке), который, в свою очередь, обогащает её дополнительными метаданными и направляет получившиеся данные на индексирование. Для повышения отказоустойчивости и балансировки нагрузки при взаимодействии приложения с коннекторами используется компонент Distributed Connector.
Метаданные индексируются «движком» HP Storage Optimizer Engine («SO Engine» на первой картинке) и помещаются в БД MS SQL. Для доступа к результатам анализа и назначения политик управления используется веб-приложение HP Storage Optimizer.
Для наглядного отображения информации, потенциально подлежащей оптимизации, в HP Storage Optimizer используются круговые диаграммы (ниже), показывающие дубликаты данных, редковостребованные и «ненужные» данные (ROT analysis: Redundant, Obsolete, Trivial). Критерии «редковостребованности» и «ненужности» можно гибко настроить, в том числе индивидуально для каждого репозитория. Кроме круговых диаграмм, доступны графики, иллюстрирующие разбивку данных по типам, времени и частоте добавления и др. Все элементы визуализации интерактивны, т.е. позволяют переходить в какую-либо категорию диаграммы (или столбец) и получать доступ к соответствующим данным.
Графический анализ данных в HP Storage Optimizer
Перечень метаданных, по которым может быть проведён анализ, необычайно широк и даёт возможность осуществлять высокоточные тематические выборки.
Пример работы с метаданными в HP Storage Optimizer
Хотелось бы заметить, что в состав продуктов HP Storage Optimizer и HP Control Point входит «движок» индексирования и визуализации, позволяющий просматривать более 400 различных форматов данных без установки на сервер соответствующих приложений для предпросмотра. Это значительно упрощает и ускоряет процесс анализа большого количества разноплановой информации.
После того как анализ данных проведён, администратору системы предоставляется возможность назначить политики удаления или перемещения данных. Политики на те или иные выборки данных возможно назначать как вручную, так и автоматически. Мощная ролевая модель управления, реализованная в HP Storage Optimizer и в HP Control Point, даёт возможность выдавать полномочия по работе с репозиториями, анализу данных в них, а также по назначению политик, максимально гибко.
HP Control Point: комплексный анализ для снижения бизнес-рисков, связанных с хранением данных
HP Control Point, по сути, представляет собой расширенную версию HP Storage Optimizer и предоставляет инструментарий не только для решения задач по оптимизации хранения, но и для внедрения политик хранения и управления жизненным циклом корпоративной информации.
Продукт позволяет проводить анализ информации не только по метаданным, но и по её содержимому. Кроме того, в нём реализованы дополнительные механизмы анализа данных и назначения политик по работе с ними.
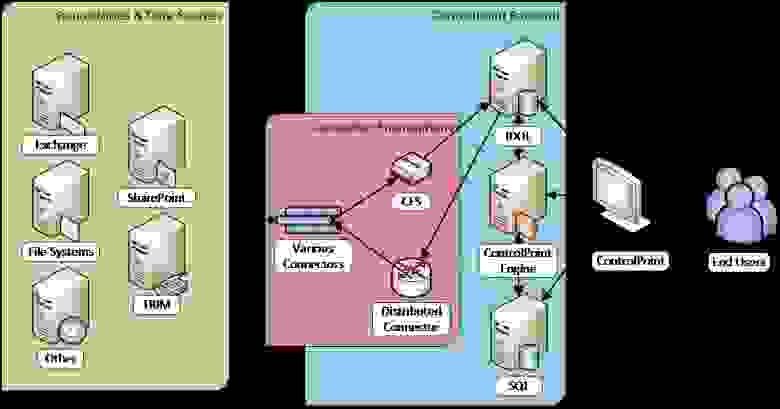
Архитектура HP Control Point
В отличие от HP Storage Optimizer, в HP Control Point широко используются возможности индексирования и смысловой категоризации информации «движка» HP IDOL (Intelligent Data Operating Layer): визуализация, категоризация, тэгирование и др. В его основе лежит возможность определять «смысл» набора анализируемой информации независимо от её формата, языка и т.д.
В частности, в HP Control Point дополнительно доступны два типа визуализации информации: кластерная карта и спектрограф. Кластерная карта представляет собой двухмерное изображение информационных «кластеров». Один кластер объединяет в себе информацию, имеющую схожий смысл. Таким образом, глядя на кластерную карту, можно быстро получить понимание основных смысловых групп этой информации. Кластерные карты интерактивны, т.е. позволяют с помощью кликов на те или иные кластеры получать доступ к информации, содержащейся в них.
Внешний вид кластерной карты в HP Control Point
Спектрограф представляет собой набор информационных кластеров, снятых в различные моменты времени и даёт возможность графически отследить, как менялся смысл информации в анализируемых репозиториях с течением времени.
Внешний вид спектрограммы в HP Control Point
Помимо расширенных возможностей визуализации информации, в HP Control Point доступна возможность категоризации анализируемой информации. Изначально информация категоризируется автоматически – средствами HP IDOL, выдавая пользователю системы массив данных, разбитый на смысловые части. Получив первичное разбиение, аналитик далее может сделать более выверенную категоризацию. Например, использовать какой-либо набор файлов, заведомо для аналитика релевантных той или иной категории, для «тренировки» категории на этот набор файлов, чтобы впоследствии получать более точные результаты категоризации. Для ещё более тонкой настройки можно использовать индивидуальные весовые коэффициенты файлов и даже фраз и отдельных слов внутри файлов, отражающие степень соответствия тех или иных единиц информации «тренируемой» категории. Такая детализация может использоваться, например, для создания подробных правил отнесения анализируемой информации к разряду конфиденциальной.
Что касается политик работы с анализируемой информацией, то в HP Control Point кроме копирования, переноса и удаления доступны также следующие опции:
– «Заморозка» объектов. Позволяет заблокировать доступ к отдельным объектам, не допуская их несанкционированное изменение или удаление.
– Создание рабочего процесса (workflow). Например, информирование или запрос утверждения уполномоченного сотрудника или владельца анализируемых объектов перед их переносом или удалением.
– Безопасный перенос в систему управления корпоративными записями HP Records Manager (например, в случае выявления несанкционированного присутствия конфиденциальных документов на общедоступном файловом сервере). При этом переносимые данные сопровождаются метаданными, которые будут использованы для дальнейшего управления документами в системе HP Records Manager с необходимыми настройками доступа, уровнями секретности и т.п.
Заключение
Как видно из текущего обзора, спектр применения HP Storage Optimizer и HP Control Point для решения задач анализа и управления корпоративными данными весьма широк. Кроме того, возможности анализа документов на разных языках (включая русский), а также масштабируемая архитектура компонентов обоих продуктов позволяет эффективно решать задачи по анализу всего объёма неструктурированных данных в организациях любого масштаба и сложности.
Автор статьи – Максим Луганский, технический консультант, Data Protection & Archiving, HP Big Data
Источник
Использование инструментов Data Science для обработки неструктурированных данных
Одной из главных проблем современной информации является разнообразие данных.
Давайте представим, что в вашей компании есть огромная база данных, хранящая сотни миллионов обращений сотрудников и клиентов, любой текст, написанный людьми на русском или любом другом языке. Эти обращения могут относиться к техническим процессам, к оказываемым услугам и к внутренним структурным процессам и т.д. Назовем это все бизнес-процессами. Итак, таким образом, у нас в руках огромный источник информации рефлекторного характера, отражающий состояние функционирования всех систем компании. Но данных настолько много, что человеческий мозг не сможет за короткий срок все это обработать и оценить. Что же делать?
На помощь приходит такая технология как NLP (анализ естественного языка), которая имеет возможность разобрать и упорядочить этот хаос слов и эмоций человека. Однажды, перед нами стояла задача обработать и структурировать более 10 млн. записей и выявить при помощи технологий Data Science отклонения в бизнес-процессах компании.
Наши данные хранятся в некоторой сервисной системе, поэтому сначала мы создали скрипт выгрузки данных. После того, как данные были выгружены из системы, мы их предварительно обработали инструментами NLTK (токенизация, лемматизация, удаление стоп-слов, фильтрация по ключевым словам).
При этом мы заранее обучили алгоритм логистической регрессии на выборке, размеченной вручную (задача классификации стандартного и нестандартного). После предварительной обработки на обученную модель подаётся TfidfVectorizer (матрица частот слов) исходного набора данных. Модель показывает записи, которые по её мнению являются необычными. После этого найденные необычные записи подаются на вход алгоритму машинного обучения LocalOutlierFactor, как показано на рисунке ниже.
LocalOutlierFactor (Локальный уровень выброса) является алгоритмом выявления аномальных точек данных путём измерения локального отклонения данной точки с учётом её соседних точек. Алгоритм выводит найденные отклонения бизнес-процессов.
После обучения мы внедряем эту модель в работу с новыми данными, и она снова определяет, что хорошо, а что плохо и выдает отчет, с которым работает человек, но этот отчет четко структурирован и легко читается, а обработка его человеком занимает считанные минуты.
Теперь давайте представим, что данные не хранятся в удобной базе и совсем не похожи на привычные таблицы, я говорю о первоисточниках, а именно о бумажных документах. Хорошо, когда этих документов пару папок и их можно прочитать довольно быстро и выяснить для себя все что нужно. А если их тысячи? Подумайте сколько времени у вас это займет, а кроме того ведь нужно сделать какие-то выводы по ним. В этот раз нам поможет такая технология как Computer Vision. Нашей задачей было выгрузить документы, которые хранятся в файловом хранилище и к ним нельзя через скрипты обратиться напрямую. В дальнейшем распознать текст со сканов документов, вычленить оттуда необходимую для анализа информацию и использовать её для некоторой аудиторской проверки.
На рисунке выше представлена схема работы использованных алгоритмов и решений. Смоделируем простой пример. Представим, что у нас есть сканы трудовых договор в pdf (например, как на рисунке ниже) и нам необходимо извлечь номер договора.
Чтобы конвертировать pdf в изображение используется библиотека pdf2img языка Python. Затем для распознавания текста с изображения используется библиотека pytesseract (оптическое распознавание символов), которая работает на основе рекуррентных нейронных сетей. Достаточно просто указать путь к изображению и вызвать метод image_to_string, указав при этом параметр языка, который будет распознаваться.
Из структуры договора видим, что после номера договора идёт перенос на новую строку. Будем это использовать для того, чтобы извлечь номер. Пример применения описанного алгоритма к изображению, представлен ниже.
Источник



