
- Массивы, обработка элементов массива
- Обработка элементов массива
- Видео по теме
- Демонстративно вертим массивы для новичков
- Что такое массив?
- Алгоритмы обработки массивов
- Заключение
- Методы массивов
- Добавление/удаление элементов
- splice
- slice
- concat
- Перебор: forEach
- Поиск в массиве
- indexOf/lastIndexOf и includes
- find и findIndex
- filter
- Преобразование массива
- sort(fn)
- reverse
- split и join
- reduce/reduceRight
- Array.isArray
- Большинство методов поддерживают «thisArg»
- Итого
- Задачи
- Переведите текст вида border-left-width в borderLeftWidth
Массивы, обработка элементов массива
Представьте себе такую задачу. Вам нужно хранить в памяти компьютера значения линейной функции  при
при  . Как это сделать? Мы умеем создавать отдельные переменные, но тогда здесь нам понадобится 100 переменных, с которыми надо будет еще как-то управляться. Но, к счастью, все можно сделать гораздо проще. Можно задать массив из 100 элементов и в каждый элемент массива записать значение функции при конкретном значении x.
. Как это сделать? Мы умеем создавать отдельные переменные, но тогда здесь нам понадобится 100 переменных, с которыми надо будет еще как-то управляться. Но, к счастью, все можно сделать гораздо проще. Можно задать массив из 100 элементов и в каждый элемент массива записать значение функции при конкретном значении x.
Итак, чтобы задать массив в языке Java используется такой синтаксис:
Например, в нашем случае следует выбрать вещественный тип данных для элементов массива. Имя массива обозначим как и функцию y:
и далее можем создать массив со 100 элементами с помощью оператора new:
Эти две строчки можно объединить в одну и записать все так:
Все, мы создали массив. Теперь, чтобы в его первый элемент записать первое значение функции, используется такой синтаксис:
Здесь k, b – переменные с какими-либо значениями, а x=0. Обратите внимание, первый элемент массива всегда имеет индекс, равный нулю. По аналогии, записывается значение во второй элемент массива:
и так далее. Давайте напишем целиком программу, которая заносит все 100 значений в массив и выводит их на экран.
Обратите внимание, если мы хотим прочитать значение из массива, то достаточно просто обратиться к нему по соответствующему индексу, например, так:
В результате переменная a будет равна 6-му значению элемента массива y. Поэтому, когда мы пишем
то осуществляется вывод элемента массива с индексом x. Вот так можно записывать и считывать значения из массива.
В языке Java можно сразу инициализировать массив конкретными значениями в момент его объявления, например, так:
В этом случае элементу powers[0] присваивается значение 1, powers[1] – 2, и т.д. Обратите внимание, что в этом случае нигде не должен указываться размер массива. Его размер определяется числом инициализируемых элементов.
Выведем этот массив в консоль:
Смотрите, здесь для определения числа элементов в массиве использовалось его свойство length. То есть, индекс последнего элемента в массиве всегда равен length-1. Например, вывести только последний элемент нашего массива можно так:
Для хранения некоторых видов информации, например, изображений удобно пользоваться двумерными массивами. Объявление двумерных массивов осуществляется следующим образом:
Какой индекс здесь считать строками, а какой – столбцами, решает сам программист, компьютер все равно будет обрабатывать элементы этого массива в соответствии с программой и что такое строки и столбцы ему неведомо.
Здесь также, первый элемент массива имеет индексы 0, то есть,
а далее, уже так:
и так далее. Давайте в качестве примера напишем программу, которая бы записывала в массив E размерностью 10×10 такие значения:

Также в Java можно создавать так называемые многомерные зубчатые массивы. Визуально такой двумерный массив можно представить вот в таком виде:

А задать его можно так:
Для обработки элементов такого массива можно записать такие циклы:
Смотрите, что здесь получается. Вот это свойство z.length возвращает первую размерность массива, то есть 5. Далее, мы берем i-ю строку (либо столбец в зависимости от интерпретации) и узнаем сколько элементов в этой строке. И внутри второго цикла записываем туда значение cnt, которое постоянно увеличивается на 1.
Затем, мы выводим полученный массив в консоль. Здесь также сначала перебираем первую его размерность. А вот этот цикл перебирает по порядку все элементы i-й строки и помещает их в переменную val. Обратите внимание на его синтаксис:
Вот так можно перебирать элементы любой коллекции, в данном случае строки массива. Вот так все это работает. По аналогии можно задавать массивы любой размерности.
Обработка элементов массива
Существует несколько стандартных алгоритмов обработки элементов массива:
- Удаление значения из массива по определенному индексу.
- Вставка значения в массив по определенному индексу.
- Сортировка элементов массива.
Начнем с первого – удаления элемента из массива. Создадим вот такой массив:
запишем туда значения с 1 по 9:
Теперь удалим элемент со значением 6. Для этого нужно проделать такую операцию:

Причем, сначала перемещаем 7-ку на место 6-ку, затем 8-ку и 9-ку, то есть, двигаемся от удаляемого элемента к концу массива. Программа будет выглядеть так:
Здесь мы начали движение с 5-го индекса (то есть 6-го элемента массива) и на первой итерации делаем операцию a[5]=a[6], то есть, 7-ку ставим на место 6-ки. На следующей итерации уже имеем a[6]=a[7] – перемещаем 8-ку и, затем, a[7]=a[8] – перемещаем 9-ку. Все, в итоге значение 6 было удалено из массива.
Теперь реализуем второй алгоритм и вставим значение 4, которого не хватает вот в таком массиве:
Здесь в конце записаны две 9, чтобы мы могли сдвинуть все элементы на 1 вправо и вставить элемент со значением 4. То есть, нам следует выполнить такую операцию над элементами массива:

Обратите внимание, что сдвиг осуществляется с конца массива. Если мы начнем это делать с 4-го, то просто затрем все остальные значения пятеркой. Итак, вот программа, которая вставляет 4-ку в этот массив:
Здесь счетчик i в цикле сначала равен 8 – это индекс последнего элемента нашего массива. Затем, делается операция a[i]=a[i-1], то есть, a[8]=a[7]. Таким образом, мы присваиваем 8-му элементу значение 7-го элемента. Это и есть смещение значения вправо. На следующей итерации i уменьшается на 1, то есть, равно 7 и операция повторяется: a[7]=a[6] и так далее, последний смещаемый элемент будет: a[4]=a[3]. После этого i будет равно 3, условие цикла становится ложным и он завершается. После смещения, мы присваиваем 4-му элементу массива значение 4 и выводим получившийся массив на экран.
Теперь рассмотрим довольно распространенный алгоритм сортировки элементов массива по методу всплывающего пузырька. Реализуем его на языке Java.
Здесь первый цикл показывает с какого элемента искать минимальный, то есть, это местоположение той вертикальной черты в методе всплывающего пузырька. Затем, задаем две вспомогательные переменные min – минимальное найденное значение, pos – индекс минимального элемента в массиве. Второй вложенный цикл перебирает все последующие элементы массива и сравнивает его с текущим минимальным и если будет найдено меньшее значение, то min становится равной ему и запоминается его позиция. Вот эти три строчки меняют местами текущее значение элемента с найденным минимальным, используя вспомогательную переменную t. И в конце программы выполняется вывод элементов массива на экран.
Запустим эту программу и посмотрим как она работает. Кстати, если мы теперь хотим выполнить сортировку по убыванию, то достаточно изменить вот этот знак на противоположный.
Видео по теме

#1 Установка пакетов и первый запуск программы

#2 Структура программы, переменные, константы, оператор присваивания

#3 Консольный ввод/вывод, импорт пакетов

#4 Арифметические операции

#5 Условные операторы if и switch

#6 Операторы циклов while, for, do while

#7 Массивы, обработка элементов массива

#8 (часть 1) Строки в Java, методы класса String

#8 (часть 2) Строки — классы StringBuffer и StringBuider

#9 Битовые операции И, ИЛИ, НЕ, XOR

#10 Методы, их перегрузка и рекурсия
© 2021 Частичное или полное копирование информации с данного сайта для распространения на других ресурсах, в том числе и бумажных, строго запрещено. Все тексты и изображения являются собственностью сайта
Источник
Демонстративно вертим массивы для новичков
Массив — структура, стоявшая у истоков программирования. Но, несмотря на то, что массивам уделяется внимание в каждом курсе уроков по любому языку программирования, от новичков все равно ускользает много важной информации, связанной с логикой взаимодействия с этой структурой.
Цель этого поста — собрать некоторую информацию о массивах, которой когда-то не хватало мне. Пост для новичков.
Что такое массив?
Массив — это структура однотипных данных, расположенная в памяти одним неразрывным блоком.
 Расположение одномерного массива в памяти
Расположение одномерного массива в памяти
Многомерные массивы хранятся точно также.
 Расположение двухмерного массива в памяти
Расположение двухмерного массива в памяти
Знание этого позволяет нам по-другому обращаться к элементам массива. Например, у нас есть двухмерный массив из 9 элементов 3х3. Так что есть, как минимум два способа вывести его правильно:
1-й вариант (Самый простой):
2-й вариант (Посложнее):
Формула для обращения к элементу 2-размерного массива, где width — ширина массива, col — нужный нам столбец, а row — нужная нам строчка:

Зная второй вариант, необязательно пользоваться им постоянно, но все же знать стоит. Например, он может быть полезен, когда нужно избавиться от лишних звездочек от указателей на указатели на указатели.
А вот так можно работать с трехмерным массивом
Этим способом можно обходить трехмерные объекты, например.
Формула доступа к элементам в трехмерном массиве, где height — высота массива, width — ширина массива, depth — глубина элемента(наше новое пространство), col — столбец элемента, а row — строка элемента:

Для получения доступа к элементам массива большей размерности по аналогии в формулу добавляем новые пространства.
Алгоритмы обработки массивов
Я не буду здесь писать про алгоритмы сортировки и алгоритмы поиска, так как найти код для почти любого из этих алгоритмов не составит труда.
Изображения — это целый комплекс из разных заголовков и информации о изображении, и самого изображения хранящемся в виде двухмерного массива.
Обработка изображений хорошо научит работать с двумерными массивами. Вот некоторые алгоритмы, которые пригодились мне для обработки изображений:
1) Зеркальное отражение.
Для того чтобы перевернуть изображение по горизонтали нужно всего лишь читать массив, в котором оно содержится сверху вниз и справа налево.
По такому же принципу выполняется переворот изображения по вертикали.
2) Поворот изображения на 90 градусов.
Для поворота изображения нужно повернуть сам двухмерный массив, а чтобы повернуть массив нужно транспонировать двухмерный массив, а затем зеркально отразить по горизонтали.
 Пошаговое выполнение алгоритма
Пошаговое выполнение алгоритма
Такой алгоритм появился, когда я нарисовал график координат c точками.
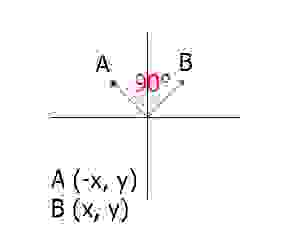 График, приведший к решению
График, приведший к решению
Хочу обратить ваше внимание, что здесь я применяю другой способ переворота изображения. Вместо выделения памяти под новый массив, здесь просто меняем местами первые и последние элементы.
Примечание: создать массив размерностью высоты и ширины реального изображения на стеке не выйдет. Только на куче с помощью оператора new.
Заключение
Этот небольшой пост не претендует на невероятные открытия мира информатики, но надеюсь успешно поможет немного вникнуть в устройство массивов падаванам мира IT.
Как я сказал в начале, здесь я собрал частичку того, чего не хватало мне при изучении программирования. Как бы эти вещи не казались бесполезными, все студенты университетов, изучающие информационные технологии проходят через это, и не напрасно — это помогает развивать логику и решать более сложные задачи, которые ждут далее. Приведенные выше примеры показывают некоторые важные способы взаимодействия с массивами.
Я надеюсь этот пост будет полезен, и если это будет так, то я напишу продолжение этой темы.
Источник
Методы массивов
Массивы предоставляют множество методов. Чтобы было проще, в этой главе они разбиты на группы.
Добавление/удаление элементов
Мы уже знаем методы, которые добавляют и удаляют элементы из начала или конца:
- arr.push(. items) – добавляет элементы в конец,
- arr.pop() – извлекает элемент из конца,
- arr.shift() – извлекает элемент из начала,
- arr.unshift(. items) – добавляет элементы в начало.
splice
Как удалить элемент из массива?
Так как массивы – это объекты, то можно попробовать delete :
Вроде бы, элемент и был удалён, но при проверке оказывается, что массив всё ещё имеет 3 элемента arr.length == 3 .
Это нормально, потому что всё, что делает delete obj.key – это удаляет значение с данным ключом key . Это нормально для объектов, но для массивов мы обычно хотим, чтобы оставшиеся элементы сдвинулись и заняли освободившееся место. Мы ждём, что массив станет короче.
Поэтому для этого нужно использовать специальные методы.
Метод arr.splice(str) – это универсальный «швейцарский нож» для работы с массивами. Умеет всё: добавлять, удалять и заменять элементы.
Он начинает с позиции index , удаляет deleteCount элементов и вставляет elem1, . elemN на их место. Возвращает массив из удалённых элементов.
Этот метод проще всего понять, рассмотрев примеры.
Начнём с удаления:
Легко, правда? Начиная с позиции 1 , он убрал 1 элемент.
В следующем примере мы удалим 3 элемента и заменим их двумя другими.
Здесь видно, что splice возвращает массив из удалённых элементов:
Метод splice также может вставлять элементы без удаления, для этого достаточно установить deleteCount в 0 :
В этом и в других методах массива допускается использование отрицательного индекса. Он позволяет начать отсчёт элементов с конца, как тут:
slice
Метод arr.slice намного проще, чем похожий на него arr.splice .
Он возвращает новый массив, в который копирует элементы, начиная с индекса start и до end (не включая end ). Оба индекса start и end могут быть отрицательными. В таком случае отсчёт будет осуществляться с конца массива.
Это похоже на строковый метод str.slice , но вместо подстрок возвращает подмассивы.
Можно вызвать slice и вообще без аргументов: arr.slice() создаёт копию массива arr . Это часто используют, чтобы создать копию массива для дальнейших преобразований, которые не должны менять исходный массив.
concat
Метод arr.concat создаёт новый массив, в который копирует данные из других массивов и дополнительные значения.
Он принимает любое количество аргументов, которые могут быть как массивами, так и простыми значениями.
В результате мы получаем новый массив, включающий в себя элементы из arr , а также arg1 , arg2 и так далее…
Если аргумент argN – массив, то все его элементы копируются. Иначе скопируется сам аргумент.
Обычно он просто копирует элементы из массивов. Другие объекты, даже если они выглядят как массивы, добавляются как есть:
…Но если объект имеет специальное свойство Symbol.isConcatSpreadable , то он обрабатывается concat как массив: вместо него добавляются его числовые свойства.
Для корректной обработки в объекте должны быть числовые свойства и length :
Перебор: forEach
Метод arr.forEach позволяет запускать функцию для каждого элемента массива.
Например, этот код выведет на экран каждый элемент массива:
А этот вдобавок расскажет и о своей позиции в массиве:
Результат функции (если она вообще что-то возвращает) отбрасывается и игнорируется.
Поиск в массиве
Далее рассмотрим методы, которые помогут найти что-нибудь в массиве.
indexOf/lastIndexOf и includes
Методы arr.indexOf, arr.lastIndexOf и arr.includes имеют одинаковый синтаксис и делают по сути то же самое, что и их строковые аналоги, но работают с элементами вместо символов:
- arr.indexOf(item, from) ищет item , начиная с индекса from , и возвращает индекс, на котором был найден искомый элемент, в противном случае -1 .
- arr.lastIndexOf(item, from) – то же самое, но ищет справа налево.
- arr.includes(item, from) – ищет item , начиная с индекса from , и возвращает true , если поиск успешен.
Обратите внимание, что методы используют строгое сравнение === . Таким образом, если мы ищем false , он находит именно false , а не ноль.
Если мы хотим проверить наличие элемента, и нет необходимости знать его точный индекс, тогда предпочтительным является arr.includes .
Кроме того, очень незначительным отличием includes является то, что он правильно обрабатывает NaN в отличие от indexOf/lastIndexOf :
find и findIndex
Представьте, что у нас есть массив объектов. Как нам найти объект с определённым условием?
Здесь пригодится метод arr.find.
Его синтаксис таков:
Функция вызывается по очереди для каждого элемента массива:
- item – очередной элемент.
- index – его индекс.
- array – сам массив.
Если функция возвращает true , поиск прерывается и возвращается item . Если ничего не найдено, возвращается undefined .
Например, у нас есть массив пользователей, каждый из которых имеет поля id и name . Попробуем найти того, кто с id == 1 :
В реальной жизни массивы объектов – обычное дело, поэтому метод find крайне полезен.
Обратите внимание, что в данном примере мы передаём find функцию item => item.id == 1 , с одним аргументом. Это типично, дополнительные аргументы этой функции используются редко.
Метод arr.findIndex – по сути, то же самое, но возвращает индекс, на котором был найден элемент, а не сам элемент, и -1 , если ничего не найдено.
filter
Метод find ищет один (первый попавшийся) элемент, на котором функция-колбэк вернёт true .
На тот случай, если найденных элементов может быть много, предусмотрен метод arr.filter(fn).
Синтаксис этого метода схож с find , но filter возвращает массив из всех подходящих элементов:
Преобразование массива
Перейдём к методам преобразования и упорядочения массива.
Метод arr.map является одним из наиболее полезных и часто используемых.
Он вызывает функцию для каждого элемента массива и возвращает массив результатов выполнения этой функции.
Например, здесь мы преобразуем каждый элемент в его длину:
sort(fn)
Вызов arr.sort() сортирует массив на месте, меняя в нём порядок элементов.
Он возвращает отсортированный массив, но обычно возвращаемое значение игнорируется, так как изменяется сам arr .
Не заметили ничего странного в этом примере?
Порядок стал 1, 15, 2 . Это неправильно! Но почему?
По умолчанию элементы сортируются как строки.
Буквально, элементы преобразуются в строки при сравнении. Для строк применяется лексикографический порядок, и действительно выходит, что «2» > «15» .
Чтобы использовать наш собственный порядок сортировки, нам нужно предоставить функцию в качестве аргумента arr.sort() .
Функция должна для пары значений возвращать:
Например, для сортировки чисел:
Теперь всё работает как надо.
Давайте возьмём паузу и подумаем, что же происходит. Упомянутый ранее массив arr может быть массивом чего угодно, верно? Он может содержать числа, строки, объекты или что-то ещё. У нас есть набор каких-то элементов. Чтобы отсортировать его, нам нужна функция, определяющая порядок, которая знает, как сравнивать его элементы. По умолчанию элементы сортируются как строки.
Метод arr.sort(fn) реализует общий алгоритм сортировки. Нам не нужно заботиться о том, как он работает внутри (в большинстве случаев это оптимизированная быстрая сортировка). Она проходится по массиву, сравнивает его элементы с помощью предоставленной функции и переупорядочивает их. Всё, что остаётся нам, это предоставить fn , которая делает это сравнение.
Кстати, если мы когда-нибудь захотим узнать, какие элементы сравниваются – ничто не мешает нам вывести их на экран:
В процессе работы алгоритм может сравнивать элемент с другими по нескольку раз, но он старается сделать как можно меньше сравнений.
На самом деле от функции сравнения требуется любое положительное число, чтобы сказать «больше», и отрицательное число, чтобы сказать «меньше».
Это позволяет писать более короткие функции:
Помните стрелочные функции? Можно использовать их здесь для того, чтобы сортировка выглядела более аккуратной:
Будет работать точно так же, как и более длинная версия выше.
reverse
Метод arr.reverse меняет порядок элементов в arr на обратный.
Он также возвращает массив arr с изменённым порядком элементов.
split и join
Ситуация из реальной жизни. Мы пишем приложение для обмена сообщениями, и посетитель вводит имена тех, кому его отправить, через запятую: Вася, Петя, Маша . Но нам-то гораздо удобнее работать с массивом имён, чем с одной строкой. Как его получить?
Метод str.split(delim) именно это и делает. Он разбивает строку на массив по заданному разделителю delim .
В примере ниже таким разделителем является строка из запятой и пробела.
У метода split есть необязательный второй числовой аргумент – ограничение на количество элементов в массиве. Если их больше, чем указано, то остаток массива будет отброшен. На практике это редко используется:
Вызов split(s) с пустым аргументом s разбил бы строку на массив букв:
Вызов arr.join(glue) делает в точности противоположное split . Он создаёт строку из элементов arr , вставляя glue между ними.
reduce/reduceRight
Если нам нужно перебрать массив – мы можем использовать forEach , for или for..of .
Если нам нужно перебрать массив и вернуть данные для каждого элемента – мы используем map .
Методы arr.reduce и arr.reduceRight похожи на методы выше, но они немного сложнее. Они используются для вычисления какого-нибудь единого значения на основе всего массива.
Функция применяется по очереди ко всем элементам массива и «переносит» свой результат на следующий вызов.
- previousValue – результат предыдущего вызова этой функции, равен initial при первом вызове (если передан initial ),
- item – очередной элемент массива,
- index – его индекс,
- array – сам массив.
При вызове функции результат её вызова на предыдущем элементе массива передаётся как первый аргумент.
Звучит сложновато, но всё становится проще, если думать о первом аргументе как «аккумулирующем» результат предыдущих вызовов функции. По окончании он становится результатом reduce .
Этот метод проще всего понять на примере.
Тут мы получим сумму всех элементов массива всего одной строкой:
Здесь мы использовали наиболее распространённый вариант reduce , который использует только 2 аргумента.
Давайте детальнее разберём, как он работает.
- При первом запуске sum равен initial (последний аргумент reduce ), то есть 0 , а current – первый элемент массива, равный 1 . Таким образом, результат функции равен 1 .
- При втором запуске sum = 1 , и к нему мы добавляем второй элемент массива ( 2 ).
- При третьем запуске sum = 3 , к которому мы добавляем следующий элемент, и так далее…
Поток вычислений получается такой:
В виде таблицы, где каждая строка –- вызов функции на очередном элементе массива:
| sum | current | result | |
|---|---|---|---|
| первый вызов | 0 | 1 | 1 |
| второй вызов | 1 | 2 | 3 |
| третий вызов | 3 | 3 | 6 |
| четвёртый вызов | 6 | 4 | 10 |
| пятый вызов | 10 | 5 | 15 |
Здесь отчётливо видно, как результат предыдущего вызова передаётся в первый аргумент следующего.
Мы также можем опустить начальное значение:
Результат – точно такой же! Это потому, что при отсутствии initial в качестве первого значения берётся первый элемент массива, а перебор стартует со второго.
Таблица вычислений будет такая же за вычетом первой строки.
Но такое использование требует крайней осторожности. Если массив пуст, то вызов reduce без начального значения выдаст ошибку.
Поэтому рекомендуется всегда указывать начальное значение.
Метод arr.reduceRight работает аналогично, но проходит по массиву справа налево.
Array.isArray
Массивы не образуют отдельный тип языка. Они основаны на объектах.
Поэтому typeof не может отличить простой объект от массива:
…Но массивы используются настолько часто, что для этого придумали специальный метод: Array.isArray(value). Он возвращает true , если value массив, и false , если нет.
Большинство методов поддерживают «thisArg»
Почти все методы массива, которые вызывают функции – такие как find , filter , map , за исключением метода sort , принимают необязательный параметр thisArg .
Этот параметр не объяснялся выше, так как очень редко используется, но для наиболее полного понимания темы мы обязаны его рассмотреть.
Вот полный синтаксис этих методов:
Значение параметра thisArg становится this для func .
Например, вот тут мы используем метод объекта army как фильтр, и thisArg передаёт ему контекст:
Если бы мы в примере выше использовали просто users.filter(army.canJoin) , то вызов army.canJoin был бы в режиме отдельной функции, с this=undefined . Это тут же привело бы к ошибке.
Вызов users.filter(army.canJoin, army) можно заменить на users.filter(user => army.canJoin(user)) , который делает то же самое. Последняя запись используется даже чаще, так как функция-стрелка более наглядна.
Итого
Шпаргалка по методам массива:
Для добавления/удаления элементов:
- push (. items) – добавляет элементы в конец,
- pop() – извлекает элемент с конца,
- shift() – извлекает элемент с начала,
- unshift(. items) – добавляет элементы в начало.
- splice(pos, deleteCount, . items) – начиная с индекса pos , удаляет deleteCount элементов и вставляет items .
- slice(start, end) – создаёт новый массив, копируя в него элементы с позиции start до end (не включая end ).
- concat(. items) – возвращает новый массив: копирует все члены текущего массива и добавляет к нему items . Если какой-то из items является массивом, тогда берутся его элементы.
Для поиска среди элементов:
- indexOf/lastIndexOf(item, pos) – ищет item , начиная с позиции pos , и возвращает его индекс или -1 , если ничего не найдено.
- includes(value) – возвращает true , если в массиве имеется элемент value , в противном случае false .
- find/filter(func) – фильтрует элементы через функцию и отдаёт первое/все значения, при прохождении которых через функцию возвращается true .
- findIndex похож на find , но возвращает индекс вместо значения.
Для перебора элементов:
- forEach(func) – вызывает func для каждого элемента. Ничего не возвращает.
Для преобразования массива:
- map(func) – создаёт новый массив из результатов вызова func для каждого элемента.
- sort(func) – сортирует массив «на месте», а потом возвращает его.
- reverse() – «на месте» меняет порядок следования элементов на противоположный и возвращает изменённый массив.
- split/join – преобразует строку в массив и обратно.
- reduce(func, initial) – вычисляет одно значение на основе всего массива, вызывая func для каждого элемента и передавая промежуточный результат между вызовами.
- Array.isArray(arr) проверяет, является ли arr массивом.
Обратите внимание, что методы sort , reverse и splice изменяют исходный массив.
Изученных нами методов достаточно в 99% случаев, но существуют и другие.
Функция fn вызывается для каждого элемента массива аналогично map . Если какие-либо/все результаты вызовов являются true , то метод возвращает true , иначе false .
arr.fill(value, start, end) – заполняет массив повторяющимися value , начиная с индекса start до end .
arr.copyWithin(target, start, end) – копирует свои элементы, начиная со start и заканчивая end , в собственную позицию target (перезаписывает существующие).
Полный список есть в справочнике MDN.
На первый взгляд может показаться, что существует очень много разных методов, которые довольно сложно запомнить. Но это гораздо проще, чем кажется.
Внимательно изучите шпаргалку, представленную выше, а затем, чтобы попрактиковаться, решите задачи, предложенные в данной главе. Так вы получите необходимый опыт в правильном использовании методов массива.
Всякий раз, когда вам будет необходимо что-то сделать с массивом, а вы не знаете, как это сделать – приходите сюда, смотрите на таблицу и ищите правильный метод. Примеры помогут вам всё сделать правильно, и вскоре вы быстро запомните методы без особых усилий.
Задачи
Переведите текст вида border-left-width в borderLeftWidth
Напишите функцию camelize(str) , которая преобразует строки вида «my-short-string» в «myShortString».
То есть дефисы удаляются, а все слова после них получают заглавную букву.
Источник



