
- Мониторинг и анализ показателей деятельности предприятия
- Формирование структуры поставленных целей
- Варианты анализа целевых показателей — контроль исполнения целей
- Монитор целевых показателей
- Демонстрационный режим
- Организация системы мониторинга
- Как было раньше
- Как сейчас
- Правильный мониторинг
- Проектирование и вообще
- Метрики и оповещения (алерты)
- Бизнес-показатели
- Мониторинг мониторинга
- Основные инструменты
- Заключение
Мониторинг и анализ показателей деятельности предприятия
Для контроля и анализа целевых показателей деятельности предприятия можно использовать данные монитора целевых показателей.
Система целевых показателей — приборная панель управления для менеджеров предприятия всех уровней.
- своевременно выявлять проблемные участки на любом этапе управления предприятием;
- контролировать выполнение поставленных целей;
- анализировать эффективность ключевых процессов предприятия с помощью показателей;
- анализировать структуры целей;
- оценивать текущее состояние бизнеса;
- топ-менеджерам принимать оптимальные управленческие решения по ключевым процессам на основании данных по целевым показателям предприятия.
- простота использования;
- гибкая система настроек;
- предопределенный набор настроек;
- возможность создания и контроля собственных показателей;
- получение информации, как в сжатом виде, так и в более развернутом виде.
Формирование структуры поставленных целей
Каждое предприятие ставит перед собой цели, к которым оно будет двигаться для достижения успеха. Руководством и собственниками компании могут быть заданы различные цели.
- для каждой цели можно определить один целевой показатель;
- для каждой цели потенциально можно определить ответственного;
- в составе каждой цели можно выделить неограниченное количество подцелей, успешное выполнение которых обеспечит достижение вышестоящей цели.
Предусмотрена возможность группировки целей и целевых показателей по перспективам управления — категории целей.
Для достижения целевого показателя можно определить одну из стратегий (максимизация значения, минимизация значения, удержание в пределах допустимого диапазона).
При первоначальном заполнении информационной базы создаются 26 базовых целевых показателей, состав которых может быть самостоятельно расширен пользователями. Создание новых показателей оправданно для факторов, которые могут привести к существенным достижениям.
Варианты анализа целевых показателей — контроль исполнения целей
Каждый целевой показатель может быть проанализирован различными способами. Предусмотрено использование различных вариантов анализа целевых показателей. Состав показателей, алгоритм их формирования, форма представления могут гибко настраиваться.
Для каждого целевого показателя может быть указано неограниченное количество вариантов анализа.
При создании новой базы в качестве основного варианта анализа целевых показателей автоматически загружается поставляемая модель показателей.
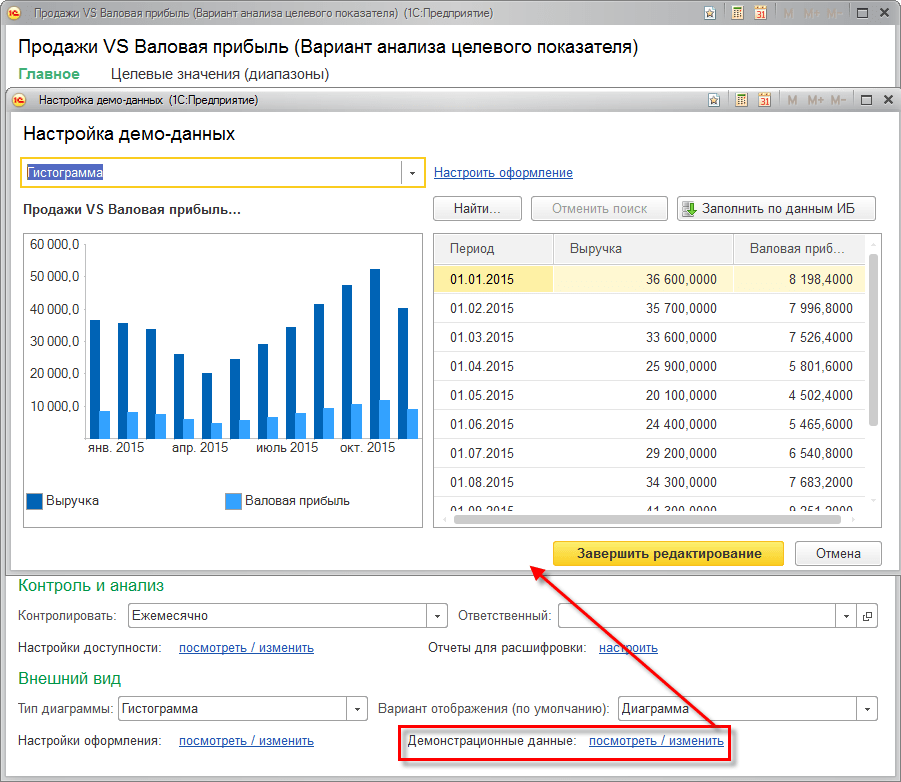
Для каждого варианта целевого показателя можно установить тип анализа (динамика изменения, сравнение с прошлым периодом и др.), вариант отображения данных (диаграмма, таблица и др.), тип диаграммы представления данных, метод расчета значения,
Использование вариантов анализа позволяет быстро настраивать план-фактный анализ для поддерживающих плановые значения показателей, проводить анализ структуры показателей в динамике, настраивать стандартный вариант отображения показателя в мониторе.
Для моделирования можно использовать не только демонстрационные данные, но и вводить произвольные данные в таблицу. При этом будет изменяться представление диаграммы.
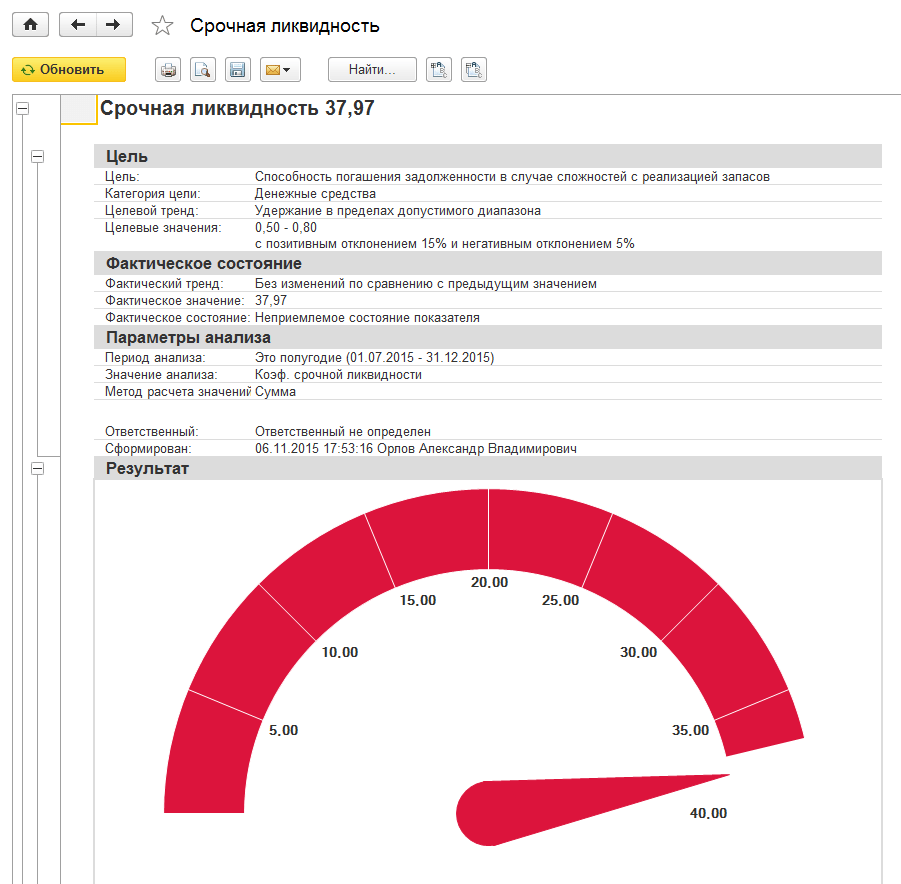
Монитор целевых показателей
Монитор целевых показателей — результат текущей деятельности предприятия.
Все целевые показатели предприятия отражаются в мониторе целевых показателей, данные которого представлены в виде отчета. Использование отчета по монитору позволяет проанализировать большое количество целевых показателей, представленных на одной странице.
Предоставление отчета возможно как в электронном, так и в бумажном виде.
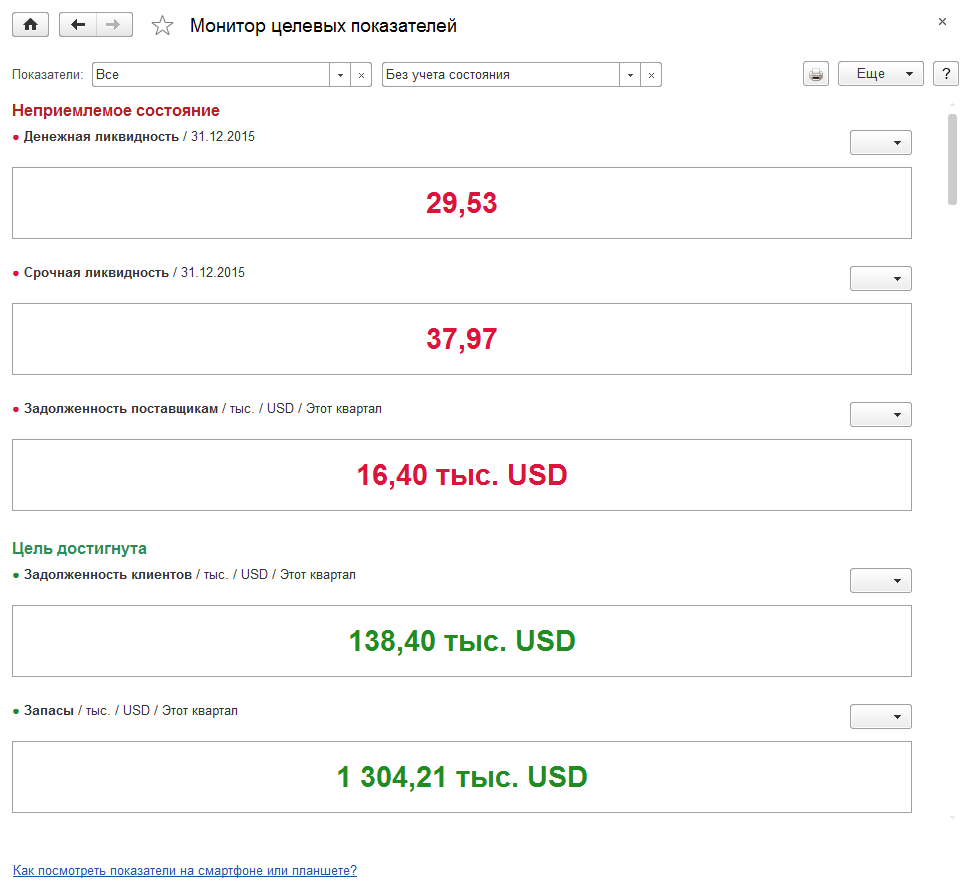
По каждому целевому показателю можно вывести детальный отчет для предоставления руководителю (информация об установленных целях, фактических значениях, ответственных, параметрах анализа и др.).
Обеспечивается возможность автоматической рассылки монитора целевых показателей предприятия руководителям, том — менеджерам.
Автоматическая рассылка ключевых показателей осуществляется в соответствии с настроенным расписанием. Использование такой возможности позволяет вовремя и быстро проинформировать топ-менеджера о данных целевых показателях предприятия. Например, можно задать расписание, согласно которому рассылка показателей предприятия будет осуществляться каждый день в 7.30 (один раз в день).
В качестве получателей целевых показателей могут выступать пользователи, организации, партнеры, контрагенты, физические лица, зарегистрированные в информационной базе.
Руководители могут получать информацию о состоянии дел на предприятии по электронной почте в виде рассылки дэш-бордов с ключевыми показателями эффективности.
Демонстрационный режим
Для наглядной демонстрации возможностей монитора целевых показателей без предварительного ввода данных можно использовать демонстрационный режим.
Источник
Организация системы мониторинга
Мониторинг — это главное, что есть у админа. Админы нужны для мониторинга, а мониторинг нужен для админов.

За последние несколько лет поменялась сама парадигма мониторинга. Новая эра уже наступила, и если сейчас вы мониторите инфраструктуру как набор серверов — вы не мониторите почти ничего. Потому что теперь «инфраструктура» — это многоуровневая архитектура, и для мониторинга каждого уровня есть свои инструменты.
Кроме проблем типа «упал сервер», «надо заменить винт в рейде», теперь надо понимать проблемы уровня приложения и уровня бизнеса: «взаимодействие с микросервисом таким-то замедлилось», «в очереди слишком мало сообщений для текущего времени», «время выполнения запросов к бд в приложении растет, запросы — такие-то».
У нас на поддержке около пяти тысяч серверов, в самых разных конфигурациях: от систем из трех серверов с кастомными докеровскими сетками, до больших проектов с сотнями серверов в Kubernetes. И за всем этим надо как-то следить, вовремя понимать, что что-то сломалось и быстро чинить. Для этого надо понять что такое мониторинг, как он строится в современных реалиях, как его проектировать и что он должен делать. Об этом и хотелось бы рассказать.
Как было раньше
Лет десять назад мониторинг был гораздо проще, чем сейчас. Впрочем, и приложения были попроще.
Мониторились, в основном, системные показатели: CPU, память, диски, сеть. Этого вполне хватало, потому что там крутилось одно приложение на php, и ничего больше не использовалось. Проблема в том, что по таким показателям обычно мало что можно сказать. Либо работает, либо нет. Что именно происходит с самим приложением, выше уровня системных показателей понять сложно.
Если проблема была на уровне приложения (не просто “сайт не работает”, а “сайт работает, но что-то не так”), то клиент сам писал или звонил, сообщал, что есть такая-то проблема, мы шли и разбирались, потому что сами мы такие проблемы заметить не могли.
Как сейчас
Сейчас совсем другие системы: с масштабированием, с автоскейлингом, микросервисы, докеры. Системы стали динамичными. Часто никто толком не знает, как именно все работает, на скольких серверах, как именно оно развернуто. Оно живет своей жизнью. Иногда даже неизвестно, что и где запущено (если это Kubernetes, например).
Усложнение самих систем, конечно, повлекло за собой большее количество возможных проблем. Появились метрики приложений, количество запущенных тредов у Java application, частота garbage collector pauses, количество событий в очереди. Очень важно, чтобы мониторинг также следил за масштабированием систем. Допустим, у вас Kubernetes HPA. Надо понимать, сколько запущено подов, и с каждого запущенного пода должны идти метрики в систему мониторинга приложения, в apm.
Все это нужно мониторить, потому что все это отражается на работе системы.
И сами проблемы стали менее очевидными.
Условно, проблемы можно поделить на две большие группы:
Проблемы первого рода – не работает основная, “пользовательская функциональность”.
Проблемы второго рода – что-то работает не так, как должно, и может куда-то не туда привести.
То есть теперь надо мониторить не только дискретное “работает/не работает”, а гораздо больше градаций. Что, в свою очередь, позволяет ловить проблему до того, как все рухнет.
Кроме того, теперь надо следить и за бизнес-показателями. Бизнес захотел иметь графики о деньгах, о том как часто идут заказы, сколько времени прошло с последнего заказа и так далее — это теперь тоже задача мониторинга.
Правильный мониторинг
Проектирование и вообще
Представление о том, что именно надо будет мониторить, должно быть заложено в момент разработки приложения и архитектуры, и речь даже не столько про серверную архитектуру, сколько про архитектуру приложения в целом.
Разработчики/архитекторы должны понимать какие части системы критичны для функционирования проекта и бизнеса, и заранее думать о том, что их работоспобность надо проверять.
Мониторинг должен быть удобным для админа, и давать представление о том, что происходит. Цель мониторинга – вовремя получить оповещение, по графикам быстро понять, что именно происходит и что именно нужно чинить.
Метрики и оповещения (алерты)
Алерты должны быть максимально понятными: админ, получив алерт, даже если он не знаком с системой, должен понять, о чем этот алерт, в какую документацию смотреть, или хотя бы кому позвонить. Должны быть четкие инструкции, что именно нужно делать, и как именно решать проблему.
Когда возникает проблема, очень хочется понять, из-за чего она возникла. Получая алерт о том, что у вас не работает приложение, вам очень хотелось бы знать, какие еще смежные системы ведут себя не так, какие еще есть отклонения от нормы. Должны быть понятные графики, собранные в дашборды, из которых сразу будет видно, где отклонение.
Для этого надо точно понимать, что нормально, а что не нормально. То есть должна быть достаточная историческая справка о состоянии системы. Задача заключается в том, чтобы покрыть алертами все возможные отклонения от нормы.
Когда админ получает алерт, он либо должен знать что с ним делать, либо кого спросить. Должна быть инструкция как именно нужно реагировать, и ее надо регулярно обновлять. Если у вас все работает через систему оркестрирования, то, наверное, у вас все хорошо, если все изменения происходят только через нее, в том числе и мониторинг. Система оркестрирования позволяет адекватно следить за актуальностью мониторинга.
Мониторинг должен расширяться после каждой аварии — если внезапно возникла какая-то проблема, которая проскочила мимо мониторинга, то, очевидно, надо замониторить эту ситуацию, чтобы в следующий раз проблема не была внезапной.
Бизнес-показатели
Полезно мониторить время с последней продажи, количество продаж за период. Если выложили релиз, то что изменилось: есть ли просадки по бизнес-показателям? На это отвечает, конечно, A/B тестирование, но графики тоже хотелось бы иметь. И надо мониторить действия конечного пользователя: писать скрипты на phantomjs, которые повторяют покупку, проходят по всем этапам основного бизнес-процесса.
Также вам, наверное, интересно знать, работает ли сервис логистики, или не свалился ли в очередной раз IpGeoBase. (Комментарий редактора: IpGeoBase — сервис, который использует большое число интернет-магазинов на 1С-Битрикс для определения местоположения пользователя. Чаще всего это делается непосредственно в коде загрузки страницы, и когда падает IpGeoBase — у нас перестают отвечать десятки сайтов. Кто-нибудь пожалуйста, скажите программистам, что это надо обрабатывать и делать таймаут, и кто-нибудь — пожалуйста попросите IpGeoBase не падать).
Нужно понимать, зависит ли просадка по бизнес-показателям от вашей системы, или от внешней.
Мониторинг мониторинга
Сам мониторинг тоже должен хоть как-то мониториться. Должен быть какой-то внешний кастомный скрипт, который будет проверять, что мониторинг работает нормально. Никому не хочется проснуться от звонка, потому что ваша система мониторинга упала вместе со всем дата-центром, и вам об этом никто не сказал.
Основные инструменты
В современных системах, которые масштабируются, у вас наверняка используется Prometheus, потому что аналогов в принципе нет. Для того, чтобы просматривать удобные графики от Prometheus нужна Grafana, потому что в Prometheus графики так себе. Нужен также какой-то APM. Либо это самописная система на Open Trace, jaeger и или что-то подобное. Но это редко кто делает. В основном используется либо New Relic, либо специфичные системы для стеков, типа Dripstat. Если у вас не одна система мониторинга, не один Zabbix, вам еще нужно понимать, как собирать эти метрики, и как раздавать алерты; кого оповещать, кого поднимать, в каком порядке, к кому какой алерт относится, и что с ним вообще делать.
Теперь по порядку.
Zabbix — не самая удобная система. Есть проблемы с кастомными метриками, особенно, если система масштабируется, и вам нужно определить роли. И хотя можно строить очень кастомные графики, алерты и дашборды, все это не очень неудобно и нединамично. Это статичная система мониторинга.
Prometheus — отличное решение для сборки огромного количества метрик. У него примерно те же возможности, что у Zabbix по кастомным алертам. Можно выводить графики и строить алерты по любым диким сочетаниям нескольких параметров. И это все очень здорово, но очень неудобно смотреть, поэтому к нему добавляется Grafana. Grafana очень красивая. Но сама по себе не очень помогает для мониторинга систем. Зато по ней удобно все читать. Лучше графиков, наверное, и нет.
ELK и Graylog — для сбора логов по событиям в приложении. Может быть полезно для разработчиков, но для подробной аналитики обычно не достаточно.
New Relic — APM, тоже полезный для разработчиков. Есть возможность понять, когда у вас в приложении прямо сейчас что-то идет не так. Понятно, какие из внешних сервисов не очень хорошо работают, или какая из баз медленно отвечает, либо какое системное взаимодействие просаживается.
Свой APM — если вы написали свою систему на Open Tracing, zipkin или jaeger, то, наверное, вы знаете, как именно это должно работать, и что именно, и в какой части кода идет не так. New Relic тоже позволяет это понять, но это не всегда удобно.
Заключение
О том какие показатели надо мониторить лучше думать в время проектирования системы, заранее подумать о том какие части системы критичны для ее работы и о том, как проверять их работу.
Алертов не должно быть слишком много, алерты должны быть актуальными. Должно быть сразу понятно, что сломалось и как это чинить.
Чтобы правильно замониторить бизнес-показатели, надо понять как устроены бизнес процессы, что нужно вашим аналитикам, хватает ли инструментов чтобы замерить нужные показатели, и как быстро можно узнать, если что-то пойдет не так.
В следующем посте мы расскажем как правильно спланировать мониторинг современной инфраструктуры, на всех уровнях: на уровнях системы, приложений и бизнеса.
Источник



