
- Способы представления знаний для обработки на ЭВМ
- Представление знаний
- Содержание
- Графы знаний [ править ]
- История [ править ]
- Определение [ править ]
- Применение [ править ]
- Открытые проблемы [ править ]
- Онтология [ править ]
- Формализация [ править ]
- Философия [ править ]
- Общие компоненты онтологий [ править ]
- Построение при помощи методов машинного обучения [ править ]
- Векторные представления графов знаний [ править ]
- Обучение онтологий [ править ]
- Лингвистические методы [ править ]
- Предобработка текста [ править ]
- Извлечение термов и концептов [ править ]
- Нахождение связей [ править ]
- Статистические методы [ править ]
- Извлечение термов и концептов [ править ]
- Нахождение связей [ править ]
- Индуктивное логическое программирование [ править ]
- Оценка онтологии [ править ]
- Золотой стандарт [ править ]
- Экспертная оценка [ править ]
- Оценка, основанная на конкретной задаче [ править ]
- Оценка с использованием конкретных источников знаний [ править ]
- Особенности применения онтологии для конкретных задач [ править ]
- Cистема автоматической обработки текста [ править ]
- Обработка текста на русском языке [ править ]
Способы представления знаний для обработки на ЭВМ
Главной особенностью систем, основанных на знаниях, является наличие в них БЗ. Причем в отличие от БД, содержащих совокупность фактов о качественных и количественных характеристиках конкретных объектов, БЗ содержат концептуальные, понятийные знания о ПО, обычно выражаемые именно в терминах данной ПО. Чтобы использовать знания, хранящиеся в базе, система снабжается специальным механизмом вывода новых знаний на основании имеющихся в базе.
Определение термина «знание» включает большей частью философские элементы. Например, знание – это проверенный практикой результат познания действительности, верное ее отражение в сознании человека. Научное знание заключается в понимании действительности в ее прошлом, настоящем и будущем, в достоверном обобщении фактов, в том, что за случайным оно находит необходимое, закономерное, за единичным – общее, а на этой основе осуществляет предвидение. Научное знание может быть и эмпирическим, и теоретическим.
В простейших ситуациях знания рассматривают как констатацию фактов и их описание. В общепринятом смысле термин «знание» рассматривают противоположно незнанию, т.е. отсутствию проверенной информации о чем-либо.
В области систем искусственного интеллекта и инженерии знаний определение знаний увязывается с логическим выводом: знания – это информация, на основе которой реализуется процесс логического вывода (т.е. на основании этой информации можно делать различные заключения по имеющимся в системе данным с помощью логических выводов). Механизм логического вывода позволяет связывать воедино отдельные фрагменты знаний, а затем по этой последовательности связанных фрагментов делать заключение.
Кроме логического вывода в настоящее время в области искусственного интеллекта проводятся исследования по теории аргументации как теории обоснования новых знаний на основе имеющихся.
Сегодня в области систем обработки информации нет общепризнанного формального определения понятия «знания». Однако признается, что отличительные качественные особенности знаний обусловлены большими возможностями в направлении структурирования и взаимосвязанности составных единиц, их интерпретируемости, наличия метрики, функциональной целостности, активности.
Структурированность предполагает как возможность декомпозиции информационной единицы и синтеза, так и возможность синтеза более крупных структур.
Связанность характеризует возможность установки между информационными единицами самых разнообразных отношений, определяющих семантику и прагматику предметной области.
Интерпретируемость предусматривает использование имен информационных единиц, что позволяет системе знать, что хранится у нее в памяти.
Наличие метрик семантического пространства предполагает возможность оценки семантической близости информационных понятий.
Активность – понятие, отражающее принципиальное отличие знаний от данных. Считается, что элементы знаний – это организованные структуры информации, имеющие собственное смысловое содержание, структуру, связи и, обязательно, процедуры принятия решений.
Функциональная целостность знаний предполагает возможность выбора как самого результата, так и средств его получения и анализа.
Связи между понятиями, именами и другими функциональными конструкциями языка системы определяются отношениями.
Отношения классификации позволяют организовывать классы элементов в ПО, определять связи между классами, а также между классами и элементами. Количественные отношения позволяют определять меру для вводимых понятий, признаковые – приписывать понятиям различные признаки, отношения принадлежности связывают объекты по признаку отношения к рассматриваемой ситуации. Широко используются при организации знаний временные, пространственные, порядковые отношения.
Одно из важнейших свойств суждений – модальность. В нем выражается степень существенности того или иного признака для данного объекта ПО, указанного в суждении. Модальности как класс отношений играют важную роль при построении в БЗ аксиоматических предположений. Используют следующие отношения модальности: НЕОБХОДИМО, ЖЕЛАТЕЛЬНО, НЕВОЗМОЖНО, СОВЕРШЕННО НЕВОЗМОЖНО, ВОЗМОЖНО, ОБЯЗАТЕЛЬНО, НЕОБЯЗАТЕЛЬНО, НЕЖЕЛАТЕЛЬНО, СОВЕРШЕННО НЕОБХОДИМО. Существуют и другие группы отношений, имеющие важное значение для проектирования БЗ.
Различные языки представления знаний в разной степени отражают перечисленные выше особенности знаний.
К настоящему времени разработано несколько способов представления знаний, среди которых выделяют логическую модель, фреймовые и продукционные системы, семантические сети.
Семантические сети
Базовые структуры в семантических сетях могут быть представлены графом, множество вершин и дуг которого образуют сеть.
Создание семантических сетей (СЕМС) – это попытка обеспечить интегрированное представление данных, категорий (типов) данных, свойств категорий и операций над данными и категориями. Особенность семантической сети заключается в целостности системы, выполненной на ее основе, т.е. невозможности разделить БЗ и механизм вывода. При этом интерпретация СЕМС реализуется с помощью использующих эту сеть процедур.
В СЕМС нет четких различий между операциями над данными и операциями над схемой; она позволяет манипулировать как данными, так и знаниями о них.
Рассмотрим основные концепции, реализованные в СЕМС.
1. Концепция одновременного рассмотрения в модели как знака, так и типа.
Знак – это конкретное значение или конкретный экземпляр рассматриваемого объекта; тип – это класс подобных знаков.
Обобщение знаков в типы – элементарная форма абстрагирования, которое необходимо для лучшего понимания сложных объектов. Например, общее понятие Велосипед – абстракция множества представлений о конкретных велосипедах.
Абстракция может быть многоуровневой (абстракция одного уровня может рассматриваться как объект абстракции другого уровня и т.д.). Абстракция может использоваться для формирования нового типа из других типов.
2. Концепция иерархии типов. Ранее уже рассматривались основные операции абстрагирования: идентификация, обобщение и агрегация. Обобщение позволяет соотнести множество знаков или множество типов с одним общим типом. Различают обобщения:
знак–тип – его называют классификацией;
тип–тип, которое собственно и носит название обобщения.
Экземпляризация (порождение реализаций) – процесс, обратный процессу классификации. Специализация – процесс, обратный процессу обобщения. Например, представление конкретных служащих общим типом Служащий – это классификация. Представление типов Служащий и Учащийся общим типом Личность – это обобщение. Данные конкретного служащего – это экземпляр (реализация) типа Служащий, а тип Служащий – это специализация типа Личность.
С помощью операции агрегации объект конструируется из других базовых объектов. Агрегация также используется как на уровне знаков, так и на уровне типов. Например, тип Служащий может быть сконструирован из типов свойств Фамилия, Год рождения, Адрес. Такие свойства-типы являются дефиниционными, т.е. определяют, истолковывают понятие, и называются интенсиональными. Конкретная же реализация типа Служащий, относящийся, например, к «Пальчику Фоме Никифоровичу», конструируется из знаков «Пальчик Ф. Н.», «1988», «Новороссийск, ул. Свободы, д. 54». Такие свойства-знаки, являющиеся фактическими значениями, называются экстенсиональными. В семантических моделях различие между интенсиональными и экстенсиональными свойствами имеет важное значение.
Агрегация соотносится с понятием ЕСТЬ–ЧАСТЬ и выражает тот факт, что тип объекта есть агрегат других типов (например, Фамилия ЕСТЬ–ЧАСТЬ Служащий).
Обобщение соотносится с понятием ЕСТЬ–НЕК (есть некоторый) и выражает тот факт, что выполнено обобщение одним типом объекта другого типа объекта (например, Служащий ЕСТЬ–НЕК Личность).
3. Концепция роли. Обобщение позволяет построить сложную систему категорий, причем ее структура не обязательно древовидная, особенно если учитывается роль используемых понятий в моделируемой ситуации.
4. Концепция семантического расстояния. Эта концепция широко используется в словарных системах, где одно слово истолковывается посредством других, а они, в свою очередь, посредством третьих и т.д., и в этом случае используется мера семантической близости взаимосвязанных поня
тий. В качестве меры семантической близости взаимосвязанных понятий, представленных в модели вершинами, может, например, выступать число дуг на пути от одной вершины к другой.
5. Концепция разбиения. Суть этой концепции заключается в разработке механизмов ограничения доступа в сети. При формировании ответа системе должна быть доступна только та информация, которая релевантна решаемой задаче.
Базовым функциональным элементом семантической сети служит структура из двух компонентов: узлов и связывающих их дуг. Каждый узел представляет некоторое понятие, а дуга – отношение между парой понятий. Можно считать, что такое отношение представляет простой факт, например: «Иванов П. Н. работает в производственном отделе».
С позиций логики базовую структуру СЕМС можно рассматривать эквивалентом предиката с двумя аргументами. Эти два аргумента представлены узлами, а собственно предикат – направленной дугой, связывающей узлы:
Работает в (Иванов, Производственный отдел).
Однако возможности выражения семантики с использованием только базовых структур весьма ограничены. Дальнейшее повышение выразительности семантических моделей обеспечивается дифференциацией вершин и дуг по категориям.
Пример.Рассмотрим модель, в которой предусматриваются четыре категории вершин:
концепты (понятия) – элементы ПО (приложения), для которых строится представление;
события-действия, наблюдаемые в ПО;
характеристики (свойства)–вершины, соответствующие свойствам концепта;
значения-вершины, соотносящиеся с областями значений, которые могут принимать характеристики.
Дуги, соединяющие вершины–события и вершины-концепты, соответствуют ролям концептов в событиях:
дуга, указывающая вершину–концепт, которая играет роль агента в событии (исполнителя, либо инициатора действия, обычно в предложении естественного языка, выражаемого глаголом);
дуга, указывающая вершину–концепт, которая является объектом воздействия в событии.
Дуги, соединяющие вершины–концепты:
дуга, соответствующая представлению утверждения.
Дуги, соединяющие вершины–концепты и вершины-характеристики: дуга, соответствующая представлению связи концепта с характеристикой.
Дуги, соединяющие вершины–характеристики и вершины–значения: дуга, соответствующая представлению связи характеристики со значением. Построим по данной модели представление следующей ситуации: «Иванов, 1950 года рождения, работает программистом в вычислительном центре, расположенном в корпусе А». Представим вначале эту ситуацию в виде одной из возможных совокупностей простых бинарных фактов (утверждений):
1. Иванов работает программистом.
2. Иванов работает в вычислительном центре.
3. Иванов 1950 года рождения.
4. Вычислительный центр расположен в корпусе А.
Источник
Представление знаний
Представление знаний (англ. knowledge representation) — направление в исследованиях искусственного интеллекта, посвящённое представлению информации о мире в форме, которую было бы возможно использовать в компьютерных системах для решения сложных прикладных задач. Таковыми являются, например, диагностирование заболеваний или ведение диалога на естественном языке. Представление знаний включает в себя психологические исследования по решению задач человеком для построения формализмов, которые упростили бы работу со сложными системами. Примерами формализмов представления знаний являются семантические сети, архитектуры систем, правила и онтологии.
Содержание
Графы знаний [ править ]
История [ править ]
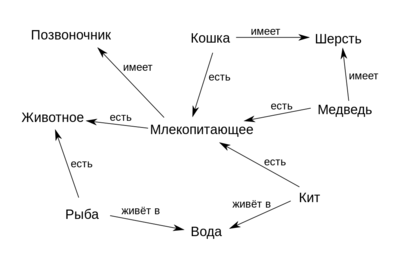
Семантические сети [1] (рис. 1) были разработаны в 1960 году из-за растущей необходимости в инструменте для представления знаний, который мог бы охватить широкий спектр сущностей: объекты реального мира, события, ситуации и отвлечённые концепты и отношения, — в конце концов будучи применённым в задаче поддержания диалога на естественном языке. Основной целью разработки семантических сетей было решение множества задач, например, представление планов, действий, времени, верований и намерений. При этом способ решения этих задач должен был быть достаточно обобщённым.
В 1980-х гг. Гронингенский университет и университет Твенте начали работу над совместным проектом, названным «Графы знаний», базируясь на устройстве семантических сетей с рёбрами, ограниченными наперёд заданным количеством отношений — для упрощения алгебры на графах. В последовавшие десятилетия граница между понятиями «Графов знаний» и «Семантических сетей» размывалась всё больше.
В 2012 году Google представили свою версию графа знаний [2] .
Определение [ править ]
Не существует формального определения графа знаний. Однако есть ряд требований, которых следует придерживаться при его построении [3] :
- Граф знаний определяется своей структурой (сущностями и связями между ними).
- Утверждения внутри графа знаний являются однозначными.
- Граф знаний использует конечный набор типов отношений.
- Все указанные сущности внутри графа знаний, включая типы и отношения, должны быть определены с использованием глобальных идентификаторов с однозначными обозначениями.
- Утверждения в графе знаний должны иметь явно указанные (лучше всего, проверенные) источники.
- Граф знаний может иметь оценки неопределённостей (вероятности, с которыми истинны те или иные утверждения [4] ).
Применение [ править ]
Вопросно-ответные системы. Самым распространённым применением графов знаний являются вопросно-ответные системы. Графы знаний располагают огромным количеством информации, доступ к которой проще всего получать посредством схемы вопрос-ответ.
Хранение информации исследований. Многие компании используют графы знаний для хранения результатов, полученных на разных стадиях исследований, которые могут быть использованы для построения понятных моделей, просчёта рисков, слежения за различными процессами и подобных задач.
Рекомендательные системы. Некоторые компании используют графы знаний как фундамент для своих рекомендательных систем. Здесь графы знаний позволяют находить связи между фильмами, телепрограммами, персоналиями и другими объектами. По выявленным связям можно пытаться предсказать индивидуальные предпочтения пользователя.
Управление цепочками поставок. Компании могут эффективно следить за перечнями различных составляющих, задействованного персонала, времени и других характеристик, что позволяет им передавать вещи более выгодно.
Открытые проблемы [ править ]
- Выявление лучших практик для построения графов знаний. Важной проблемой является создание единого набора эвристик и практик, которые можно было бы применить для построения графов знаний. Такой набор мог бы помочь разработчикам и исследователям в понимании и использовании графов знаний.
- Динамически изменяемые знания. Знания не статичны, они зависят от времени. Например, некоторое утверждение, которое было истинным в один момент времени, может перестать быть таковым в другой. Поэтому открытой проблемой является поддержка изменений в знаниях.
- Оценка корректности и полноты графа знаний. Не выработаны объективные критерии оценки графов знаний. Открытой проблемой является ответ на вопрос, какое качество более важно для графа знаний: корректность (непротиворечивость), полнота или другое.
Онтология [ править ]
Понятие онтологии существует как в информатике, так и в философии, однако эти понятия похожи.
| Определение: |
| Онтология (в информатике) — формализация знаний, включающая в себя представление, формальное именование и определение категорий, свойств и отношений между понятиями, данными и сущностями некоторой области знаний. |
Термин «онтология» применительно к графам знаний это, прежде всего, способ моделирования и формального представления схемы данных, обеспечивающий гораздо большие возможности, чем традиционные базы данных или объектно-ориентированный подход.
Согласно общепринятому определению в компьютерных науках, онтология — это способ формализации знаний, абстрактных или специфических, в какой-либо предметной области, реализованный на основе формального описания объектов, фактов и отношений между ними.
Формализация [ править ]
Для формализации используется концептуальная схема.
| Определение: |
| Концептуа́льная схе́ма [5] — семантическая сеть из взаимосвязанных по определенным правилам понятий и концепций. Обычно такая схема состоит из структуры данных, содержащей все релевантные классы объектов, их связи и правила (теоремы, ограничения), принятые в этой области. |
Философия [ править ]
Термин «онтология» в информатике является производным от соответствующего древнего философского понятия.
Общее с философским понятием:
- И то, и другое — попытка представить сущности, идеи и события со всеми их взаимозависимыми свойствами и отношениями в соответствии с системой категорий.
- В обеих областях существует значительная работа по проблемам онтологической инженерии [6] .
Отличия от философского понятия:
- Онтология в информатике должна иметь формат, который компьютер сможет легко обработать.
- Информационные онтологии создаются всегда с конкретными целями — решения конструкторских задач; они оцениваются больше с точки зрения применимости, чем полноты.
В каждой научной дисциплине или области знаний создают онтологии для организации данных в виде информации и знаний. С новыми онтологиями упрощается решение задач в этих областях. Однако при решении задач возникают определённые сложности, например, языковой барьер между исследователями разных стран. Эта сложность может быть нивелирована поддержкой контролируемых словарей [7] жаргона.
Общие компоненты онтологий [ править ]
| Название | Описание | Пример |
|---|---|---|
| Экземпляры (объекты) | Базовые или «наземные» объекты (индивиды). | Мария, 1, Солнце. |
| Классы (понятия) | Наборы, коллекции, концепции, классы в программировании, типы объектов или виды вещей. | Человек, Число, Звезда. |
| Атрибуты | Аспекты, свойства, признаки, характеристики или параметры, которые могут иметь объекты (и классы). | Возраст: 21, Чётность: нет, Спектральная классификация: жёлтый карлик. |
| Отношения | Способы, которыми классы и индивиды могут быть связаны друг с другом. | Люди являются Животными. |
| Правила | Высказывания в форме «Если . то . » (антецедент-консеквент), описывающие логические выводы, которые могут быть сделаны из утверждения в определенной форме. | Если [math]X[/math] смертен, то [math]X[/math] умрёт. |
| Аксиомы | Утверждения (включая правила) в логической форме, которые вместе составляют общую теорию, описываемую онтологией в её области применения. Это определение отличается от определения «аксиом» в формальной логике. В ней аксиомы включают только утверждения, утверждаемые как априорное знание. Здесь же «аксиомы» также включают в себя теорию, полученную из аксиоматических утверждений. | Человек смертен. Сократ — человек. |
| События | Изменение атрибутов или отношений. | [math]X[/math] умер ( [math]X[/math] больше не является живым). |
Онтологии обычно кодируются с помощью языков онтологий — специализированных формальных языков.
Примерами таковых являются OWL [8] , KIF [9] , Common Logic [10] , CycL [11] , DAML+OIL [12] .
Построение при помощи методов машинного обучения [ править ]
Векторные представления графов знаний [ править ]
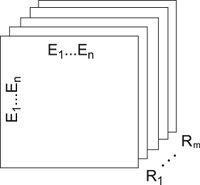
Векторные представления графов знаний (англ. Knowledge graph embeddings, KGE) являются малоразмерными представлениями объектов-узлов и связей между ними в графе знаний. Они обобщают информацию о семантике и локальной структуре вершин.
Существует множество различных моделей KGE, таких как TransE [13] , TransR [14] , RESCAL [15] , DistMult [16] , ComplEx [17] , и RotatE [18] .
Как пример для представления графовых данных может использоваться семантика Cреды описания ресурса (англ. Resource Description Framework, RDF) [19] где связи представляются триплетом «субъект — предикат — объект«. Для моделирования бинарных отношений на графе удобно использовать трехсторонний тензор [math]X[/math] , в котором две размерности образованы на основе связываемых объектов-узлов, а третья размерность содержит отношения между ними (рис. 2). Элемент тензора [math]x_
Обучение онтологий [ править ]
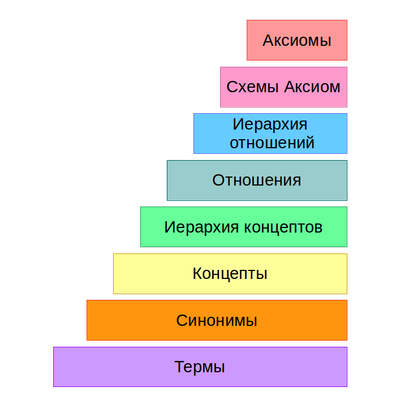
Процесс получения онтологий начинается с вынесения множества термов из текста и получения их синонимов. Далее они преобразуются во множество концептов. После чего выявляются связи между концептами, и в итоге формируются схемы аксиом и извлекаются аксиомы. Данный процесс называют слоеным пирогом обучения онтологии (рис. 3).
Алгоритмы, используемые в разных слоях при построении онтологии разбивают на 3 основные группы:
- лингвистические;
- статистические;
- логические.
Лингвистические методы [ править ]
Лингвистические методы основаны на различных особенностях языка и играют ключевую роль на начальных стадиях обучения. В основном их используют для предобработки текста, а также в извлечении термов, концептов и связей.
Предобработка текста [ править ]
На первой стадии текст предобрабатывается для уменьшения размерности и повышения точности обучаемой модели. Обычно для этого используют такие методы, как:
Извлечение термов и концептов [ править ]
Лингвистические техники также часто используют на этапе извлечения термов и концептов. Чтобы извлечь термы и концепты при помощи синтаксических структур слова помечают как части речи. Эта информация используется для извлечения синтаксических структур из предложений, таких как словосочетания и глагольные группы. Данные структуры анализируются на наличие различных слов и морфем для нахождения термов. К примеру словосочетание ‘acute appendicitis’ может быть извлечено в качестве кандидата на терм, так как является гипонимом к терму ‘appendicitis’. На китайских текстах данный метод достиг точности в [math]83.3\%[/math] [22] .
Распространёнными методами данного подхода являются:
- рамки валентностей (англ. Subcategorization Frames) [23] ;
- извлечение коренных слов (англ. Seed Words Extraction).
Нахождение связей [ править ]
С помощью анализа зависимостей можно находить связи между термами используя информацию, предоставленную в деревьях разбора. Таким образом, с помощью кратчайшего пути между двумя концептами в дереве разбора можно выявить связи между ними.
Также можно использовать регулярные выражения. Например, правило » [math]N[/math] , как например [math]N[/math] , [math]N[/math] , … , [math]N[/math] « (где [math]N[/math] — именная группа [24] ) может выявить такие образцы как «сезоны года, как например лето, осень, весна и зима». Данный подход полезен для выявления связей «является» к примеру (лето — сезон года).
Статистические методы [ править ]
Статистические методы основаны на статистике и не полагаются на семантику языка. Большинство статистических методов преимущественно используют вероятностные техники и в основном применяются после предобработки текста лингвистическими методами на ранних этапах обучения (извлечение термов, концептов и связей).
Извлечение термов и концептов [ править ]
На этом этапе используются следующие статистические методы:
- C/NC value [25] используют для извлечения многословных терминологий — групп термов, образующих концепты. Алгоритму на вход подаётся несколько многословных термов, для каждого из которых вычисляется оценка в форме C value и NC value. C value использует частоту встречаемости терма для его извлечения, что делает его эффективным для нахождения вложенных термов, а NC value по сути является модификацией C value, которая учитывает контекст.
- В процессе извлечения термов могут быть получены термы, не относящиеся к целевой области. Для фильтрации таких термов применяется метод сравнительного анализа (англ. Contrastive analysis) [26] . Он присуждает оценку для каждого терма, в зависимости от того, насколько он релевантен для целевой области, и насколько он нерелевантен в других областях.
- Латентно-семантический анализ (англ. Latent Semantic Analysis, LSA) используют для извлечения концептов. Этот метод основан на том, что термы, встречающиеся вместе, будут схожи по значению. LSA уменьшает размерность данных, сохраняя структуру подобия, после чего к оставшимся термам применяется мера сходства (например косинусное сходство[27] ) для поиска похожих слов.
- Кластеризация группирует множества объектов на подмножества (кластеры) таким образом, чтобы объекты из одного кластера были более похожи друг на друга, чем на объекты из других кластеров.
Нахождение связей [ править ]
Статистические методы также используют для выявления связей. Распространёнными техниками являются:
- Категоризация термов (англ. Term subsumption) находит связи между термами при помощи условной вероятности. Этот алгоритм ищет термы, являющиеся наиболее общими. Терм [math]t[/math] считается более общим, чем терм [math]x[/math] если [math]P(t \; | \; x) \gt P(x \; | \; t)[/math] , где [math]P(t \; | \; x)[/math] обозначает вероятность встречи терма [math]t[/math] при наличии терма [math]x[/math] .
- Анализ формальных понятий (англ. Formal Concept Analysis, FCA) [28] основан на том, что объекты могут иметь схожие атрибуты. Алгоритм на вход принимает матрицу связей объектов и атрибутов и находит в ней все естественные кластеры, что позволяет построить иерархию концептов и атрибутов.
- Иерархическая кластеризация группирует термы в кластеры для нахождения концептов и построения иерархий.
- Добыча ассоциативных правил (англ. Association rule mining, ARM) находит правила, предугадывающие совпадение элементов в различных базах данных, для чего обычно применяют алгоритмы Apriori [29] и FPG [30] . Тут правило подразумевает импликацию [math]X \to Y[/math] , где [math]X[/math] и [math]Y[/math] — непустые подмножества множества всех элементов, такие, что [math]X \cap Y = \varnothing[/math] .
Индуктивное логическое программирование [ править ]
На последней стадии построения онтологии используется индуктивное логическое программирование (англ. Inductive Logic Programming, ILP) [31] — раздел машинного обучения, который использует логическое программирование как форму представления примеров, фоновых знаний и гипотез. ILP необходимо для генерации аксиом по схемам аксиом (положительным и отрицательным примерам и фоновым знаниям).
Оценка онтологии [ править ]
Оценка качества получения онтологии является важной частью процесса обучения. Благодаря ей можно уточнить или перестроить модели, не удовлетворяющие требованиям. Так как обучение состоит из различных этапов, процесс оценки онтологий является достаточно сложной задачей. По этой причине предлагались многочисленные техники оценки, однако их все можно разбить на следующие группы:
Золотой стандарт [ править ]
Оценка с использованием золотого стандарта основана на наличии базовой онтологии. Золотой стандарт представляет собой пример идеальной онтологии в какой-то конкретной области. Сравнивая и оценивая обученную онтологию с золотым стандартом можно эффективно определить степень покрытия области знаний и консистентность. Золотым стандартом может быть как независимая онтология, так и статистическая модель, сформированная экспертами в данной области. Наличие золотого стандарта позволяет проводить регулярные и крупномасштабные оценки на различных этапах обучения. Однако получение золотого стандарта может оказаться проблемой, так как он должен быть смоделирован в условиях и с целью похожими на соответственно условия и цель обучаемой онтологии. Очень часто это приводит к выбору моделей, созданных человеком вручную.
Экспертная оценка [ править ]
Экспертная оценка основана на определении различных критериев. По каждому критерию выставляется числовая оценка, после чего считается взвешенная сумма оценок. Основным недостатком данного способа являются огромные затраты времени и усилий на ручную работу, однако данный метод устарел и крайне редко применяется в оценке современных онтологий.
Оценка, основанная на конкретной задаче [ править ]
Данная оценка применяется при построении онтологии для конкретных задач. Результаты, полученные в процессе решения задачи, определяют качество построенной онтологии, независимо от её структуры. Данная оценка позволяет выявить неустойчивые концепты и определить адаптивность конкретной онтологии, анализируя её эффективность в контексте различных задач.
К примеру, создаётся онтология для улучшения поиска документов. В таком случае можно проверить, получило ли приложение более релевантные документы после применения данной онтологии. Для этого можно применить традиционные методы оценки, такие как F мера.
Однако стоит отметить, что использование оценок, основанных на конкретных задачах, имеет несколько недостатков. К примеру:
- Онтология может являться лишь малой частью приложения, и её эффект на общий результат может быть незначительным.
- Онтология оценивается путём применения конкретным образом для конкретной задачи, а значит модель достаточно сложно обобщить.
Оценка с использованием конкретных источников знаний [ править ]
Эта оценка использует источники знаний конкретной области, чтобы определить степень покрытия этой области обучаемой онтологией. Главным преимуществом данной оценки является возможность сравнивать одну или несколько целевых онтологий с конкретными данными. Однако возникает проблема нахождения подходящего источника знаний (как и в оценке золотым стандартом).
Особенности применения онтологии для конкретных задач [ править ]
Cистема автоматической обработки текста [ править ]
Лингвистическая онтология является одним из ключевых элементов в системе обработки текста и ее построение необходимо для решения задачи.
Как описано выше — для построения современных онтологий всегда является актуальным извлечение термов и концептов, в данном случае семантически связанных слов из текста на естественном языке. Однако общим недостатком таких онтологий является отсутствие специализированных терминов, специфичных для данной предметной области. В следствие этого появляется проблема дополнения существующей онтологии, а именно семантической сети узлами и связями из внешних источников. И так как имеется множество публичных ресурсов для дополнения новых узлов и связей, то выделяют следующие задачи:
- Автоматизированный поиск новых узлов, связанных семантическими отношениями.
- Добавление новых узлов и связей в онтологию при обнаружении сущностей, признаки которых удовлетворяют заданным критериям.
Для решения данных задач существует множество способов анализа текстовой информации для извлечения из нее семантических отношений:
- Методы извлечения связей, основанные на шаблонах такие как «Top down» и «Bottom up» [32] .
- Группа методов, основанная на форматировании или на DOM [33] .
- Методы, основанные на машинном обучении. Одним из самых явных примеров реализации является word2vec, основанный на нейронных сетях.
Последняя группа методов является наиболее современной и показывает наилучшую точность, но не позволяет достичь приемлимой точности и полноты в общем случае, так как данные методы используются для конкретной предметной области. Таким образом поиск наиболее подходящих признаков для обучения нейронных сетей необходим для применения лингвистической онтологии в данной задаче.
Обработка текста на русском языке [ править ]
Чтобы применить онтологию для автоматической обработки текстов, необходимо понятиям онтологии сопоставить набор языковых выражений (слов и словосочетаний), которыми понятия могут выражаться в тексте. Для русского языка, как и для многих других языков, содержащие многозначные понятия, имеется ряд проблем.
Хоть понятие, лексическое значение относятся к категориям мышления, при этом между ними есть существенные различия. Значение включает в себя помимо понятийного содержания (сигнификативно-денотативного [34] [35] компонента значения), такие компоненты как оценочный, стилистический, сочетаемостный. Также значение включает лишь различительные черты объектов, иногда относительно поверхностные, а понятия охватывают их наиболее глубокие существенные свойства. Поэтому описать значения многих слов как совокупности общих и одновременно существенных признаков может быть очень трудно. В целом, считается, что значение и понятие совпадают лишь в сфере терминологии.
Многие понятия в русском языке сложно представить в виде формальной системы, пригодной для логического вывода, например, описать таксономические связи, по следующим причинам:
- Из-за их нечеткости, расплывчатости.
- Контекстной зависимости, когда реализация некоторых компонентов значения существенно зависит от контекста.
- Существования значительных рядов синонимов, отличающихся оттенками значений, что затрудняет разбиение таких рядов на совокупность взаимосвязанных понятийных единиц. Например, сколько понятий онтологии оптимально (и на основе каких принципов) сопоставить следующему ряду слов со значением ОШИБКА: ошибка, погрешность, недосмотр, просмотр, ляп, промах, оплошность, осечка, прокол, упущение, недочет, а также ослышка, описка, опечатка, оговорка. Таким словам обычно трудно найти точные слова-соответствия в других языках, то есть слова, имеющие такой же оттенок значения и такие же особенности употребления.
Несмотря на описанные проблемы, разработка моделей представления знаний о мире и о языке в рамках онтологий имеет смысл. Так например появился РуТез [36] — онтология для автоматической обработки текста на русском языке, которая представила свое решение [37] для данных проблем.
Источник



