
- Размышления на тему ООП и состоянии объектов
- Проблема
- Предложенные решения
- RuntimeException
- Собственные попытки решения проблемы
- Реализация
- Вывод
- Является ли изменение состояния объекта проблемой?
- 1 ответ 1
- NEWOBJ.ru → Введение в ООП с примерами на C# →
- 2.3. Поля и методы: состояние и поведение
- § 15. Состояние и поведение. В настоящем разделе мы подробнее разберем особенности использования методов и полей классов. Начнем с определения [Буч 3]:
- § 16. Неизменяемость. Изменение программистом значений переменных (состояния объектов) в ходе выполнения программы выглядит вполне естественной практикой. Однако существует множество ситуаций, когда желательно так или иначе ограничивать эту возможность.
- § 17. Сохраняемость. Иногда требуется сохранить состояние объекта между запусками программы или при перемещении объекта между приложениями. Конечно, строго говоря, при восстановлении сохраненного состояния, мы в действительности создаем новый объект в памяти и присваиваем его полям значения, соответствующе тем, которые были у другого объекта. Однако удобно представлять этот процесс на более высоком уровне абстракции, как сохранение и восстановление.
- § 18. Свойства в C#. В заключение главы, коротко рассмотрим специальную синтаксическую разновидность методов в C# – свойства. В C# мы можем объявить метод, возвращающий значение заданного типа или принимающий один параметр заданного типа, используя следующий специальный синтаксис, позволяющий пользователям класса обращаться к этим методам, как к полям:
- Вопросы и задания
Размышления на тему ООП и состоянии объектов
Программный код пишется сверху вниз. В том же порядке читаются и выполняются инструкции. Это логично и все давно к этому привыкли. В некоторых случаях можно поменять порядок операций. Но иногда очерёдность вызовов функций важна, хотя синтаксически это неочевидно. Получается, что код выглядит рабочим, даже после перестановки вызовов, а результат оказывается неожиданным.
Однажды подобный код попался мне на глаза.
Проблема
Однажды, ковыряясь в чужом коде в совместном проекте, а обнаружил функцию наподобие:
Конечно сразу в глаза бросается не самый «элегантный» стиль: классы хранят данные (POJO), функции изменяют входящие объекты.
В целом вроде бы ничего. У нас есть объект, в котором не хватает данных, и есть сами данные, пришедшие из других источников (сервисов), которые мы теперь в этот объект и поместим, чтобы сделать его полноценным.
Но есть и некоторые нюансы.
- Мне не нравится, что ни одна функция не написана в стиле ФП и изменяет объект, переданный как аргумент.
- Но допустим, что это было сделано, чтобы сократить время обработки и количество создаваемых объектов.
- Только комментарий в коде говорит о том, что последовательность вызовов важна, и при встраивании нового Filler надо быть осторожным
- А ведь количество людей, работающих над проектом больше 1 и не все знают об этой хитрости. Особенно новые люди в команде (не обязательно на предприятии).
Последний пункт меня особенно насторожил. Ведь API построена так, что мы не знаем, что изменилось в объекте, после вызова данной функции. Например у нас до и после есть метод Product::getImages , который до вызова функции fill выдаст пустой список, а после список с картинками к нашему продукту.
С самими Filler дела обстоят ещё хуже. AvailabilityFiller никак не даёт понять, что ожидает, что информация о цене товара уже заложена в передаваемых объект.
И вот я задумался о том, как бы я мог оградить своих коллег от ошибочного использования функций.
Предложенные решения
Сперва, я решил обсудить данный случай со своими коллегами. К сожалению, все предложенные ими решения, не показались мне правильным подходом.
RuntimeException
Одним из предложенных вариантов был: а ты в AvailabilityFiller впиши в начале функции Objects.requireNonNull(product.getPrices) и тогда любой программист во время локальных тестов уже получит ошибку.
- но цены и правда может не быть, если сервис был недоступен или ещё какая ошибка, тогда товар должен получить статус «нет в наличии». Придётся приписывать всякие флаги или прочее, чтобы отличить «нет данных» от «даже не запрашивали».
- Если же бросить исключение в самом getPrices , тогда мы создадим те же проблемы, что и современная Java со списками
- Допустим в функцию передаётся List, предлагающий в своей API метод get… Я знаю, что не надо менять передаваемые объекты, а создавать новые. Но суть в том, что API нам такой метод предлагает, но в рантайме может вылететь ошибка, если это неизменяемый список, как например полученный из Collectors.toList()
- Если же бросить исключение в самом getPrices , тогда мы создадим те же проблемы, что и современная Java со списками
- если AvailabilityFiller будет кем-то использован в другом месте, то программист написавший вызов, не сразу поймёт, в чём проблема. Только после запуска и Дебага. Потом ему ещё придётся разбираться в коде, чтобы понять, откуда взять данные.
«А ты напиши тест, который будет ломаться, если поменять очерёдность вызовов». т.е. если все Filler будут возвращать «новый» продукт, получится что-то наподобие:
- не люблю тесты, которые настолько «White-Box»
- Ломается при каждом новом Filler
- Ломается при смене очередности независимых вызовов
- Опять таки не решает проблему переиспользования самого AvailabilityFiller
Собственные попытки решения проблемы
Думаю, что вы уже догадались, что я бы хотел решить проблему на уровне компиляции. Ну зачем мне, спрашивается, компилируемый язык со строгой типизацией, если я не могу предотвратить ошибку.
И я задумался, принадлежат ли объект без дополнительных данных и «расширенный» объект к одному и тому же классу?
Разве не будет правильным описать отдельными классами или интерфейсами различные возможные состояния объекта?
Таким образом моя идея состояла в следующем:
Т.е. задаваемый изначально продукт является инстансом класса отличного от возвращаемого, чем уже показаны изменения данных.
Filler ‘ы же в своих API точно указывают, какие данные им нужны и что они возвращают.
Таким образом можно предотвратить неправильную очередность вызовов.
Реализация
Как такое воплотить в реальность в Java? (Напомню, что наследование от нескольких классов в Java невозможно.)
Сложность добавляют независимые операции. Например, картинки могут быть добавлены и до и после добавления цен, а так же в самом конце функции.
Тогда могут быть
Как это всё описать?
Как уже заметно, всё сводится просто к огромнейшему количеству кода. И это при том, что в примере оставил только 3 вида входных данных. В реальном мире их может быть намого больше.
Получается, что затраты на написание и поддержку такого кода себя не оправдывают, хотя сама идея разделения состояния на отдельные классы мне показалась очень привлекательной.
Если посмотреть на другие языки, то где-то эту проблему решить проще, а где-то нет.
Например в Go можно прописать ссылку на расширяемый класс без «копирования» или «перегрузки» методов. Но речь не о Go
Ещё одно отступление
Пока писал эту статью, пришло в голову ещё одно возможное решение с Proxy , позвалающее прописывать только новые методы, но требующее иерархии интерфейсов. В общем страшное, сердитое и не подходящее. Если вдруг кому-то интересно:
Вывод
Что же получается? С одной стороны интересный подход, применяющий к «объекту» в разных состояниях отдельные классы и гарантирующий этим предотвращение ошибок, вызванных неправильной последовательностью вызовов методов, изменяющих этот объект.
С другой стороны, такой подход заставляет писать столько кода, что от него сразу хочется отказаться. Нагромождение интерфейсов и классов только мешает разобраться в проекте.
В другом своем проекте я всё же попробовал использовать такой подход. И сначала на уровне интерфейсов всё было просто отлично. Я написал функции:
Указав тем самым, что определённый шаг обработки данных требует дополнительной информации, которая не нужна ни в начале обратобки, ни в её конце.
Испльзуя mock ‘и, я сумел протестировать код. Но когда дело дошло до реализации и колличество данных и разных источников начало расти, я быстро сдался и переделал всё под «обычный» вид. Всё работает и никто не жалуется. Получается, что работоспособность и простота кода побеждают над «предотвращением» ошибок, а проследить за правильной последовательностью вызовов можно и вручную, пусть даже ошибка проявит себя только на этапе ручного тестирования.
Может, если бы я сделал шаг назад и посмотрел бы на код с другой стороны, у меня появились бы совсем другие решения. Но так вышло, что я заинтересовался именно этой прокомментированной сторокой.
Вот уже под конец статьи, задумавшись о том, что раз уж не красиво описывать setter’ы в интерфейсах, то можно представить сборку данных о продукте в виде Builder ‘а, который после добавления опрелённых данных возвращает другой интерфейс. Опять таки всё зависит от сложности логики построения объектов. Если вы работали с Spring Security, то вам знакомы такого рода решения.
Для моего примера выходит:
- Пишите чистые функции
- Пишите красивый и понятный код
- Помните, что краткость — сестра и что главное, чтобы код работал
- Не стесняйтесь ставить вещи под вопрос, искать иные пути и даже забрасывать альтернативные решения, если уж на то пошло
- Не молчите! Во время объяснения проблемы другим, рождаются лучшие решения (Rubber Duck Driven Developent)
Источник
Является ли изменение состояния объекта проблемой?
В следующем коде нарушается принцип инкапсуляции, потому что метод getHireDay() возвращает объект Date . Изменить его где-то в ином классе, вызвавшем метод getHireDay() , значит изменить состояние объекта Employee .
В следующем коде вроде как проблема снимается. Изменить состояние объекта Employee где-то в другом классе, вызвавшем метод getHireDay() , не удастся.
Вопрос. Является ли изменение состояния объекта проблемой, ведь объектов данного класса может быть сколько угодно? В каких случаях необходимо заботиться о состоянии объекта, точнее о неизменяемости его состояния?
1 ответ 1
Объекты всегда можно условно разделить на два типа:
- мутабельные (изменяемые)
- немутабельные(неизменяемые)
Что такое мутабельные объекты: это объекты, которые имеют состояние и имеют методы для изменения этого состояния. Т.е. привычные для нас Plain Old Java Objects с геттерами и сеттерами.
Немутабельные — это такие объекты, которые после их создания(вызова конструктора) не могут меняться.
Каждый из этих типов имеет свои преимущества и недостатки.
- Неизменяемые объекты — это хорошие ключи в Map и Set, поскольку они обычно не изменяются после создания.
- Немутабельность упрощает запись, использование и понимание кода (инвариант класса устанавливается один раз и затем неизменен)
- Неизменяемость упрощает параллелизацию вашей программы, поскольку конфликты между объектами отсутствуют.
- Внутреннее состояние вашей программы будет консистентным, даже если у вас возникли исключения.
- Ссылки на неизменные объекты могут кэшироваться, поскольку они не будут изменяться.
- Неизменяемые объекты являются потокобезопасными, поэтому у вас не будет проблем с синхронизацией.
Но за эти преимущества надо платить, поэтому придется тратить время на создание новых объектов, каждый раз, когда хотим изменить состояние, придется так же подумать о том, какой объект можно назвать немутабельным, потому что ваш объект к сожалению мутабельный. Т.е. нужно держать в голове правила для создания немутабельных объектов, а именно
- Сделать все поля приватными
- Не предоставлять геттеры/сеттеры и другие мутаторы
- Убедитесь, что методы нельзя переопределить, создав финальный класс (Strong Immutability) или сделав свои методы финальным (Weak Immutability)
- Если поле не является примитивным или немутабельным(как например Date), то сделайте полное клонирование этого объекта.
В общем, ответ на ваш вопрос: мутабельность сама по себе проблемой не является! Она активно используется в разработке, когда предметная область представлена анемичной моделью данных (только геттеры/сеттеры и в объектах нет методов поведения) и все с этим отлично живут. Но если вы хотите назвать объект иммутабельным, использовать его в качестве ключа в мапе использовать его в многопоточном окружении, то позаботьтесь о пунктах указанных выше.
Источник
 NEWOBJ.ru → Введение в ООП с примерами на C# →
NEWOBJ.ru → Введение в ООП с примерами на C# →
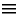 NEWOBJ.ru → Введение в ООП с примерами на C# →
NEWOBJ.ru → Введение в ООП с примерами на C# →2.3. Поля и методы: состояние и поведение
2.3. Поля и методы: состояние и поведение
§ 15. Состояние и поведение. В настоящем разделе мы подробнее разберем особенности использования методов и полей классов. Начнем с определения [Буч 3]:
Состояние объекта (state) – перечень полей объекта (обычно статический) и текущих значений каждого из этих полей (обычно динамический).
Мы оговариваем, что перечень полей обычно статический, то есть зафиксированный в определении класса, так как в некоторых языках перечень полей может быть изменен после создания объекта.
Мы оговариваем, что перечень текущих значений полей обычно динамический, то есть может меняться после создания объекта, так как во всех языках есть механизмы, позволяющие ограничить изменение полей после создания объекта. Мы обсудим некоторые из таких возможностей в следующем параграфе.
В настоящей книге мы используем термин поле ( field ), так как оно используется в C#. При этом в других языках программирования для обозначения полей класса могут применяться и другие термины: переменная-член ( member variable, member ), свойство ( property ). Отметим, что термин свойство, в свою очередь, имеет в C# специфическое значение и будет рассмотрен ниже в настоящей главе.
Приведем определение поведения объекта аналогичное определению состояния объекта [3].
Поведение объекта (behavior) — перечень (обычно статический) методов объекта и результатов их вызова (зависят от текущего состояния).
Мы оговариваем, что перечень методов, обычно статический, так как в некоторых языках программирования существуют механизмы, позволяющие изменять перечень методов класса или отдельного объекта при выполнении программы.
Мы оговариваем, что результаты вызова методов зависят от текущего состояния или, по-другому, определяются историей объекта (то есть историей изменения его состояния), так как один и тот же метод в общем случае может возвращать разные результаты в зависимости от состояния.
В предыдущих главах мы уже показывали, что методы имеют доступ ко всем полям объекта независимо от уровня видимости. При этом доступ выполняется через неявно передаваемую в метод переменную this , указывающую на объект, для которого был вызван метод. Если локальная переменная метода имеет такое же имя, как и некоторое поле класса, то эта локальная переменная скрывает ( hide ) поле класса. Мы уже рассматривали эту возможность ране в § 7.
Сокрытие переменных можно назвать разновидностью более общего понятия – перегрузки – использования в одной и той же области видимости одного и того же имени для обозначения разных элементов языка. Если «элемент языка» – метод, то мы имеем дело с перегрузкой методов.
Перегрузка метода (overloading) – определение в одной и той же области видимости нескольких методов с одинаковым именем, но различающихся количеством или типами параметров.
Компилятор, используя различие в параметрах, определяет на этапе компиляции, какой именно метод необходимо вызывать.
Мы используем термин метод, так как он используется в C#, но в других языках и, в целом, в объектно-ориентированном программировании как синонимы также используются термины функция (function) и функция-член (member function). Исторически термин функция возник в процедурном программировании и обозначал функцию, не связанную ни с каким классом. В объектно-ориентированных языках чтобы различать функции, не связанные ни с каким классом, и функции класса, последние стали называть другими терминами, например, функциями-членами в C++ и методами в C# и Java, оставив термин функция для функций, объявленных вне классов. При этом во многих объектно-ориентированных языках вовсе нет возможности объявить функцию вне какого-либо класса.
В заключение напомним, что при проектировании класса, как правило, следует избегать открытых полей – для изменения состояния объекта следует использовать методы 24 .
§ 16. Неизменяемость. Изменение программистом значений переменных (состояния объектов) в ходе выполнения программы выглядит вполне естественной практикой. Однако существует множество ситуаций, когда желательно так или иначе ограничивать эту возможность.
Во-первых, некоторые объекты представляют семантически неизменяемые данные, константы. Например, мы не хотели бы иметь возможность изменять переменные, в которых хранится число π, или число e, или коэффициенты перевода единиц измерения, или другие подобные значения. Семантически константами могут быть и более сложные объекты, например, точка-центр координат, объект-прямоугольник с размерами страниц стандартного формата. параметры работы приложения, не допускающие изменения после запуска. Очень часто локальные переменные не должны изменяться после инициализации согласно логике метода. Конечно, можно сказать, что раз эти объекты не должны меняться, то и не следует их менять. Например, в Python это единственная рекомендация для разработчика 25 . Однако во многих других современных языках программирования принята практика ограничений изменения семантически неизменяемых объектов на уровне языка.
Во-вторых, часто желательно ограничить возможность изменения состояния объекта только некоторыми фрагментами кода. В следующем примере будет ли изменено состояние объекта reportData внутри метода Create ?
Метод Create создает объект-отчет report , используя данные из объекта reportData . Разумно предположить, что метод Create использует данные reportData , но не изменяет их. Однако это не точно: код метода Create вполне может случайно или намеренно (в этом случае речь идет о неудачной архитектуре) изменить какие-то поля объекта reportData .
Приведем еще пример:
Здесь класс ReporDataProvider выполняет загрузку данных из базы данных с использованием переданного в конструкторе объекта-подключения db . Как и в предыдущем примере, разумно предположить, что объект reportDataProvider использует объект-подключение db , но не изменяет его. Однако (как и в предыдущем примере), это не точно. Особенно важна задача локализации фрагментов кода, изменяющих состояние объекта, в многопоточных приложениях. Так, если мы используем объект db для нескольких объектов-провайдеров, каждый из которых будет менять свойства подключения, то при параллельном запуске этих провайдеров отследить кто и что изменил значительно сложнее, чем при последовательном.
Дополнительным аргументов в пользу неизменяемости состояния объектов является потенциальное повышение производительности. Компилятор, зная, что значение тех или иных переменных не будет никогда меняться, может сгенерировать более оптимальный код.
Способы ограничивать изменение состояния объектов сильно отличаются в различных языках программирования. Рассмотрим коротко основные возможности C#: механизм констант ( const ) и механизм readonly -полей классов.
Локальные переменные методов и поля классов значимых типов могут быть помечены как константы ключевым словом const . Такие объекты невозможно изменить во время выполнения приложения. Рассмотрите следующий пример:
Значения констант должны быть определены на момент компиляции приложения, поэтому мы не можем их использовать со ссылочными переменными – экземплярами классов 26 :
Для ограничения изменения переменных ссылочного типа в C# используется механизм readonly -полей. Поля классов могут быть помечены как доступные только на чтение ключевым словом readonly (англ. «только чтение») . Это значит, что мы сможем присваивать значения этим полям только в конструкторе класса или непосредственно при инициализации поля. Рассмотрим следующий пример неизменяемого ( immutable ) класса:
Этот пример демонстрирует несколько важных особенностей.
Во-первых, в C# неизменяемость ( immutability ) – это свойство класса, а не объекта: или мы объявляем класс как неизменяемый и все его экземпляры будут неизменяемыми. Или мы объявляем класс как изменяемый и все его экземпляры будут также изменяемыми. У нас нет возможности сделать неизменяемым только некоторые экземпляры этого класса. Для сравнения, отметим, что в C++ такая возможность есть: мы можем отметить ключевым слово const переменную или даже параметр метода и это будет значить, что указанную переменная или параметр метода невозможно изменить, но другие, не отмеченные этим словом экземпляры будут изменяемыми, а объект-параметр будет изменяемым вне соответствующего метода.
Другая особенность, демонстрируемая примером с кругом – класс может быть не полностью неизменяемым. То есть часть полей может быть изменяемая, часть – нет. Полностью неизменяемый объект мы можем сделать только если все вложенные объекты (поля класса) также реализованы как неизменяемые. Так, в классе Circle недостаточно написать readonly Point , нужно чтобы и сам Point был неизменяемым, так как readonly для ссылочного типа обозначает лишь невозможность изменить его значение (ссылку), но не состояние объекта, на который он ссылается.
И последний момент, который мы разберем – особенность копирования неизменяемых объектов. В конструкторе для копирования объекта-центра мы используем копирование ссылки, так как уверены, что переданный объект уже не будет никогда изменен и вполне достаточно иметь всего один экземпляр объекта, на который будут ссылаться множество логически не связанных между собой переменных.
В заключение отметим, что, применяя имеющиеся возможности языка, как правило, лучше избыточно ограничить изменение переменных и позже снять это ограничение, чем случайно изменить переменную, которая с точки зрения других фрагментов кода, должна быть неизменяемой.
Несмотря на широкое использование в ежедневной практике, для объектно-ориентированного программирования неизменяемость – это всегда ограничение, так как исходно переменные в ООП изменяемые ( mutable ). Более того, в теории языков программирования введение неизменяемости для всех объектов – это определение функциональной парадигмы программирования [Мартин 11].
§ 17. Сохраняемость. Иногда требуется сохранить состояние объекта между запусками программы или при перемещении объекта между приложениями. Конечно, строго говоря, при восстановлении сохраненного состояния, мы в действительности создаем новый объект в памяти и присваиваем его полям значения, соответствующе тем, которые были у другого объекта. Однако удобно представлять этот процесс на более высоком уровне абстракции, как сохранение и восстановление.
Сохраняемость – способность объекта существовать во времени, переживая породивший его процесс, и (или) в пространстве, перемещаясь из своего первоначального адресного пространства. [Буч 3]
Для сохранения объекта в файл, передачи по сети или другому процессу, как правило, требуется привести значения полей объекта в формат, который будет понятен получателю и преобразовать их в непрерывную последовательность байт. Этот процесс называется сериализацией (от англ. serial – последовательный).
Сериализация (serialization) – преобразование состояния объекта в последовательность байт. Сериализация может быть двоичная, текстовая (JSON, XML) или какая-либо другая. Обратный процесс называется десериализацией.
На следующем рисунке предоставлен пример сериализации объекта в формат JSON.
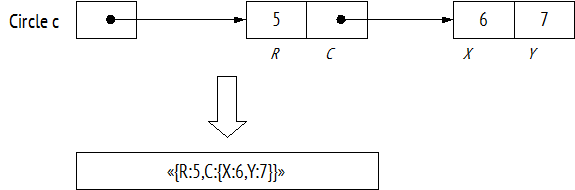
Особая тема – сохранение объектов в реляционную базу данных. Чаще всего используется следующий подход: объект соответствует строке таблицы, а поля – столбцам этой таблицы. Значения значимых полей хранятся непосредственно в ячейках строки таблицы, а ссылочные поля реализуются с помощью внешних ключей, связывающих строку таблицы объекта со строкой или строками таблицы другого объекта, на который указывает ссылочное поле 27 . На следующем рисунке приведен пример сохранения уже рассмотренного выше объекта Circle c в две таблицы реляционной базы данных:
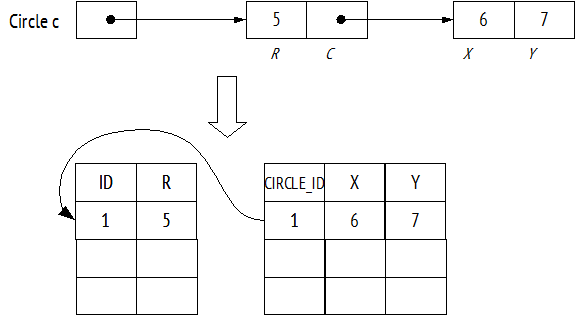
Очевидно, процесс сохранения и восстановления состояния объекта из базы достаточно трудоемкий для программиста, поэтому крайне привлекательна идея сохранения и загрузки состояния объекта в реляционную базу данных простым вызовом некоторых встроенных методов Save и Load . Библиотеки, упрощающие сохранение и загрузку состояния объектов или реализующие так или иначе эти методы Save и Load , называют ORM-библиотеками:
ORM (object-relational mapping) – «объектно-реляционное сопоставление» – механизм (реализуемый не языком программирования, а сторонними библиотеками), позволяющий сохранять или восстанавливать состояние объекта в приложении в реляционную базу данных.
Эти механизмы используются крайне широко и любое промышленное приложение использует ту или иную ORM, например, EntityFramework или Dapper .
Следует отметить, что полноценное «зеркалирование» базы данных в объекты памяти помимо трудоемкости, а точнее рутинности этого процесса, сопряжено с множеством концептуальных проблем, прежде всего, связанных с транзакциями. Чтобы преодолеть эти ограничения некоторые базы данных заявляются как объектные, а не реляционные, в том смысле, что при работе с ними мы не транслируем объектную модель программы в реляционную модель БД с помощью ORM, а напрямую сохраняем в БД в объектной модели. Хотя эти направления динамично развиваются, однако пока остаются нишевыми.
§ 18. Свойства в C#. В заключение главы, коротко рассмотрим специальную синтаксическую разновидность методов в C# – свойства. В C# мы можем объявить метод, возвращающий значение заданного типа или принимающий один параметр заданного типа, используя следующий специальный синтаксис, позволяющий пользователям класса обращаться к этим методам, как к полям:
Для свойства может объявлен только метод get , тогда мы создаем свойство доступное только на чтение, или, наоборот, только метод set , тогда мы создаем свойство, доступное только на запись (как правило, неудачное решение). Для методов get и set нет устоявшегося перевода на русский язык, по-английски их называют getter и setter .
Отметим еще раз, что свойства – специфическая возможность C# и представляет лишь синтаксическое упрощение для объявления и вызова определенных методов, а термин «свойство» вне языка C# часто используется для обозначения обычных полей класса.
Вопросы и задания
1. Дайте определение следующим терминам и сопоставьте русские термины с английскими: состояние объекта, поле, переменная-член, свойство, поведение объекта, метод, перегрузка метода, функция, функция-член, сокрытие локальных переменных неизменяемость, константа; state, field, member variable, property, behavior, method, overloading, member function, immutability.
2. Имеет ли открытый ( public ) метод класса доступ к закрытым ( private ) полям того же класса (1) того же объекта, для которого этот метод был вызван; (2) для другого объекта того же класса, который был передан как параметр этого метода?
3. В чем отличие между классом без состояния ( stateless ) и неизменяемым классом ( immutable )?
4. Почему нельзя перегрузить методы с одинаковыми параметрами, но отличающимися типами возвращаемых значений?
5. Изучите различия классов string и StringBuilder .
6. Назовите преимущества и недостатки использования неизменяемых типов данных.
7. Можно ли в C# объявить локальную переменную или параметр метода с ключевым словом readonly ?
8. Можно ли в конструкторе присваивать значения readonly -полю несколько раз?
9. Является ли массив неизменяемым типом данных в C#?
10. Повышают ли производительность приложений использование const и readonly в C#? Является ли производительность фактором, который необходимо учитывать, применяя механизмы языка программирования по ограничению изменения состояния объектов?
11. Объясните утверждение, что в C# неизменяемость – свойство классов, а не объектов.
12.* Познакомьтесь с подходом «event sourcing» (к сожалению, устоявшегося перевода этого термина нет), в рамках которого мы храним список транзакций, то есть событий об изменении состояния, но не храним само состояние.
13.* Приведите аргументы в пользу следующего тезиса: «Чем большей памятью мы располагаем и чем быстрее становятся наши компьютеры, тем меньше мы нуждаемся в изменяемых состояниях.» [11]
24. Или – в C# – свойства, см. § 18.
25. Системы статического анализа кода не в счет, так как это внешние по отношению к языку программирования инструменты.
26. Строго говоря, структуры C# (struct) также не могут быть константами, хотя и являются значимыми типами.
27. Нередко этот способ сохранения объектов в реляционную БД подвергают критике. Подробный анализ этого вопроса приведен, например, в [Дейт 4]. Однако по факту, именно описанная модель сегодня является самой распространенной.
Источник



