
- Архитектура хранилищ данных: традиционная и облачная
- Введение
- Традиционная архитектура хранилища данных
- Трехуровневая архитектура
- Kimball vs. Inmon
- Модели хранилищ данных
- Звезда vs. Снежинка
- ETL vs. ELT
- Организационная зрелость
- Новые архитектуры хранилищ данных
- Amazon Redshift
- Google BigQuery
- Panoply
- По ту сторону облачных хранилищ данных
- Хранение данных. Или что такое NAS, SAN и прочие умные сокращения простыми словами
- Зачем это все?
- Хранение данных
- Unified storage
- Гиперконвергентные системы
- Облака и эфемерные хранилища
- Заключение
Архитектура хранилищ данных: традиционная и облачная
Привет, Хабр! На тему архитектуры хранилищ данных написано немало, но так лаконично и емко как в статье, на которую я случайно натолкнулся, еще не встречал.
Предлагаю и вам познакомиться с данной статьей в моем переводе. Комментарии и дополнения только приветствуются!

Введение
Итак, архитектура хранилищ данных меняется. В этой статье рассмотрим сравнение традиционных корпоративных хранилищ данных и облачных решений с более низкой первоначальной стоимостью, улучшенной масштабируемостью и производительностью.
Хранилище данных – это система, в которой собраны данные из различных источников внутри компании и эти данные используются для поддержки принятия управленческих решений.
Компании все чаще переходят на облачные хранилища данных вместо традиционных локальных систем. Облачные хранилища данных имеют ряд отличий от традиционных хранилищ:
- Нет необходимости покупать физическое оборудование;
- Облачные хранилища данных быстрее и дешевле настроить и масштабировать;
- Облачные хранилища данных обычно могут выполнять сложные аналитические запросы гораздо быстрее, потому что они используют массовую параллельную обработку.
Традиционная архитектура хранилища данных
Следующие концепции освещают некоторые из устоявшихся идей и принципов проектирования, используемых для создания традиционных хранилищ данных.
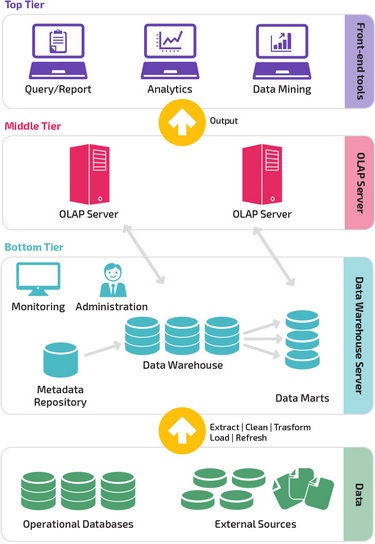
Трехуровневая архитектура
Довольно часто традиционная архитектура хранилища данных имеет трехуровневую структуру, состоящую из следующих уровней:
- Нижний уровень: этот уровень содержит сервер базы данных, используемый для извлечения данных из множества различных источников, например, из транзакционных баз данных, используемых для интерфейсных приложений.
- Средний уровень: средний уровень содержит сервер OLAP, который преобразует данные в структуру, лучше подходящую для анализа и сложных запросов. Сервер OLAP может работать двумя способами: либо в качестве расширенной системы управления реляционными базами данных, которая отображает операции над многомерными данными в стандартные реляционные операции (Relational OLAP), либо с использованием многомерной модели OLAP, которая непосредственно реализует многомерные данные и операции.
- Верхний уровень: верхний уровень — это уровень клиента. Этот уровень содержит инструменты, используемые для высокоуровневого анализа данных, создания отчетов и анализа данных.
Kimball vs. Inmon
Два пионера хранилищ данных: Билл Инмон и Ральф Кимбалл предлагают разные подходы к проектированию.
Подход Ральфа Кимбалла основывается на важности витрин данных, которые являются хранилищами данных, принадлежащих конкретным направлениям бизнеса. Хранилище данных — это просто сочетание различных витрин данных, которые облегчают отчетность и анализ. Проект хранилища данных по принципу Кимбалла использует подход «снизу вверх».
Подход Билла Инмона основывается на том, что хранилище данных является централизованным хранилищем всех корпоративных данных. При таком подходе организация сначала создает нормализованную модель хранилища данных. Затем создаются витрины размерных данных на основе модели хранилища. Это известно как нисходящий подход к хранилищу данных.
Модели хранилищ данных
В традиционной архитектуре существует три общих модели хранилищ данных: виртуальное хранилище, витрина данных и корпоративное хранилище данных:
- Виртуальное хранилище данных — это набор отдельных баз данных, которые можно использовать совместно, чтобы пользователь мог эффективно получать доступ ко всем данным, как если бы они хранились в одном хранилище данных;
- Модель витрины данных используется для отчетности и анализа конкретных бизнес-линий. В этой модели хранилища – агрегированные данные из ряда исходных систем, относящихся к конкретной бизнес-сфере, такой как продажи или финансы;
- Модель корпоративного хранилища данных предполагает хранение агрегированных данных, охватывающих всю организацию. Эта модель рассматривает хранилище данных как сердце информационной системы предприятия с интегрированными данными всех бизнес-единиц
Звезда vs. Снежинка
Схемы «звезда» и «снежинка» — это два способа структурировать хранилище данных.
Схема типа «звезда» имеет централизованное хранилище данных, которое хранится в таблице фактов. Схема разбивает таблицу фактов на ряд денормализованных таблиц измерений. Таблица фактов содержит агрегированные данные, которые будут использоваться для составления отчетов, а таблица измерений описывает хранимые данные.
Денормализованные проекты менее сложны, потому что данные сгруппированы. Таблица фактов использует только одну ссылку для присоединения к каждой таблице измерений. Более простая конструкция звездообразной схемы значительно упрощает написание сложных запросов.
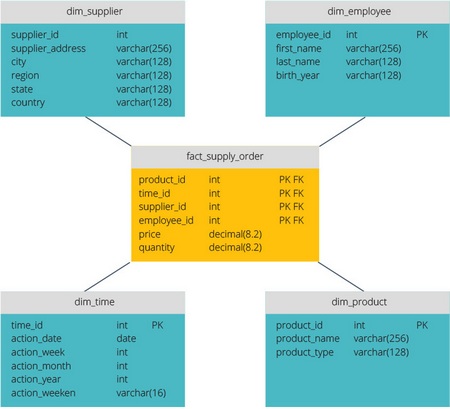
Схема типа «снежинка» отличается тем, что использует нормализованные данные. Нормализация означает эффективную организацию данных так, чтобы все зависимости данных были определены, и каждая таблица содержала минимум избыточности. Таким образом, отдельные таблицы измерений разветвляются на отдельные таблицы измерений.
Схема «снежинки» использует меньше дискового пространства и лучше сохраняет целостность данных. Основным недостатком является сложность запросов, необходимых для доступа к данным — каждый запрос должен пройти несколько соединений таблиц, чтобы получить соответствующие данные.

ETL vs. ELT
ETL и ELT — два разных способа загрузки данных в хранилище.
ETL (Extract, Transform, Load) сначала извлекают данные из пула источников данных. Данные хранятся во временной промежуточной базе данных. Затем выполняются операции преобразования, чтобы структурировать и преобразовать данные в подходящую форму для целевой системы хранилища данных. Затем структурированные данные загружаются в хранилище и готовы к анализу.
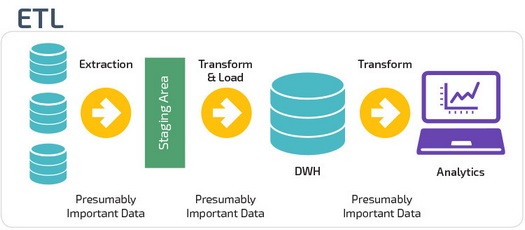
В случае ELT (Extract, Load, Transform) данные сразу же загружаются после извлечения из исходных пулов данных. Промежуточная база данных отсутствует, что означает, что данные немедленно загружаются в единый централизованный репозиторий.
Данные преобразуются в системе хранилища данных для использования с инструментами бизнес-аналитики и аналитики.

Организационная зрелость
Структура хранилища данных организации также зависит от его текущей ситуации и потребностей.
Базовая структура позволяет конечным пользователям хранилища напрямую получать доступ к сводным данным, полученным из исходных систем, создавать отчеты и анализировать эти данные. Эта структура полезна для случаев, когда источники данных происходят из одних и тех же типов систем баз данных.

Хранилище с промежуточной областью является следующим логическим шагом в организации с разнородными источниками данных с множеством различных типов и форматов данных. Промежуточная область преобразует данные в обобщенный структурированный формат, который проще запрашивать с помощью инструментов анализа и отчетности.
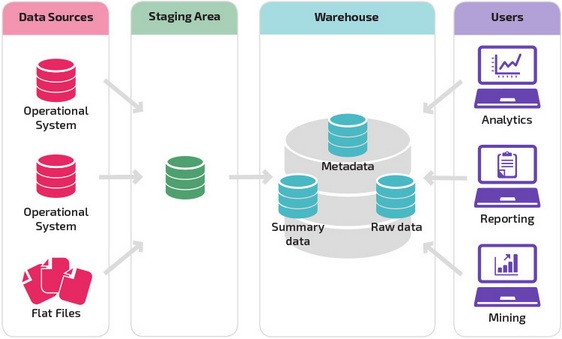
Одной из разновидностей промежуточной структуры является добавление витрин данных в хранилище данных. В витринах данных хранятся сводные данные по конкретной сфере деятельности, что делает эти данные легко доступными для конкретных форм анализа.
Например, добавление витрин данных может позволить финансовому аналитику легче выполнять подробные запросы к данным о продажах, прогнозировать поведение клиентов. Витрины данных облегчают анализ, адаптируя данные специально для удовлетворения потребностей конечного пользователя.

Новые архитектуры хранилищ данных
В последние годы хранилища данных переходят в облако. Новые облачные хранилища данных не придерживаются традиционной архитектуры и каждое из них предлагает свою уникальную архитектуру.
В этом разделе кратко описываются архитектуры, используемые двумя наиболее популярными облачными хранилищами: Amazon Redshift и Google BigQuery.
Amazon Redshift
Amazon Redshift — это облачное представление традиционного хранилища данных.
Redshift требует, чтобы вычислительные ресурсы были подготовлены и настроены в виде кластеров, которые содержат набор из одного или нескольких узлов. Каждый узел имеет свой собственный процессор, память и оперативную память. Leader Node компилирует запросы и передает их вычислительным узлам, которые выполняют запросы.
На каждом узле данные хранятся в блоках, называемых срезами. Redshift использует колоночное хранение, то есть каждый блок данных содержит значения из одного столбца в нескольких строках, а не из одной строки со значениями из нескольких столбцов.
Redshift использует архитектуру MPP (Massively Parallel Processing), разбивая большие наборы данных на куски, которые назначаются слайсам в каждом узле. Запросы выполняются быстрее, потому что вычислительные узлы обрабатывают запросы в каждом слайсе одновременно. Узел Leader Node объединяет результаты и возвращает их клиентскому приложению.
Клиентские приложения, такие как BI и аналитические инструменты, могут напрямую подключаться к Redshift с использованием драйверов PostgreSQL JDBC и ODBC с открытым исходным кодом. Таким образом, аналитики могут выполнять свои задачи непосредственно на данных Redshift.
Redshift может загружать только структурированные данные. Можно загружать данные в Redshift с использованием предварительно интегрированных систем, включая Amazon S3 и DynamoDB, путем передачи данных с любого локального хоста с подключением SSH или путем интеграции других источников данных с помощью API Redshift.
Google BigQuery
Архитектура BigQuery не требует сервера, а это означает, что Google динамически управляет распределением ресурсов компьютера. Поэтому все решения по управлению ресурсами скрыты от пользователя.
BigQuery позволяет клиентам загружать данные из Google Cloud Storage и других читаемых источников данных. Альтернативным вариантом является потоковая передача данных, что позволяет разработчикам добавлять данные в хранилище данных в режиме реального времени, строка за строкой, когда они становятся доступными.
BigQuery использует механизм выполнения запросов под названием Dremel, который может сканировать миллиарды строк данных всего за несколько секунд. Dremel использует массивно параллельные запросы для сканирования данных в базовой системе управления файлами Colossus. Colossus распределяет файлы на куски по 64 мегабайта среди множества вычислительных ресурсов, называемых узлами, которые сгруппированы в кластеры.
Dremel использует колоночную структуру данных, аналогичную Redshift. Древовидная архитектура отправляет запросы тысячам машин за считанные секунды.
Для выполнения запросов к данным используются простые команды SQL.
Panoply
Panoply обеспечивает комплексное управление данными как услуга. Его уникальная самооптимизирующаяся архитектура использует машинное обучение и обработку естественного языка (NLP) для моделирования и рационализации передачи данных от источника к анализу, сокращая время от данных до значения как можно ближе к нулю.
Интеллектуальная инфраструктура данных Panoply включает в себя следующие функции:
- Анализ запросов и данных — определение наилучшей конфигурации для каждого варианта использования, корректировка ее с течением времени и создание индексов, сортировочных ключей, дисковых ключей, типов данных, вакуумирование и разбиение.
- Идентификация запросов, которые не следуют передовым методам — например, те, которые включают вложенные циклы или неявное приведение — и переписывает их в эквивалентный запрос, требующий доли времени выполнения или ресурсов.
- Оптимизация конфигурации сервера с течением времени на основе шаблонов запросов и изучения того, какая настройка сервера работает лучше всего. Платформа плавно переключает типы серверов и измеряет итоговую производительность.
По ту сторону облачных хранилищ данных
Облачные хранилища данных — это большой шаг вперед по сравнению с традиционными подходами к архитектуре. Однако пользователи по-прежнему сталкиваются с рядом проблем при их настройке:
Источник
Хранение данных. Или что такое NAS, SAN и прочие умные сокращения простыми словами
TL;DR: Вводная статья с описанием разных вариантов хранения данных. Будут рассмотрены принципы, описаны преимущества и недостатки, а также предпочтительные варианты использования.

Зачем это все?
Хранение данных — одно из важнейших направлений развития компьютеров, возникшее после появления энергонезависимых запоминающих устройств. Системы хранения данных разных масштабов применяются повсеместно: в банках, магазинах, предприятиях. По мере роста требований к хранимым данным растет сложность хранилищ данных.
Надежно хранить данные в больших объемах, а также выдерживать отказы физических носителей — весьма интересная и сложная инженерная задача.
Хранение данных
Под хранением обычно понимают запись данных на некоторые накопители данных, с целью их (данных) дальнейшего использования. Опустим исторические варианты организации хранения, рассмотрим подробнее классификацию систем хранения по разным критериям. Я выбрал следующие критерии для классификации: по способу подключения, по типу используемых носителей, по форме хранения данных, по реализации.
По способу подключения есть следующие варианты:
- Внутреннее. Сюда относятся классическое подключение дисков в компьютерах, накопители данных устанавливаются непосредственно в том же корпусе, где и будут использоваться. Типовые шины для подключения — SATA, SAS, из устаревших — IDE, SCSI.
подключение дисков в сервере
- Внешнее. Подразумевается подключение накопителей с использованием некоторой внешней шины, например FC, SAS, IB, либо с использованием высокоскоростных сетевых карт.

дисковая полка, подключаемая по FC
По типу используемых накопителей возможно выделить:
- Дисковые. Предельно простой и вероятно наиболее распространенный вариант до сих пор, в качестве накопителей используются жесткие диски
- Ленточные. В качестве накопителей используются запоминающие устройства с носителем на магнитной ленте. Наиболее частое применение — организация резервного копирования.
- Flash. В качестве накопителей применяются твердотельные диски, они же SSD. Наиболее перспективный и быстрый способ организации хранилищ, по емкости SSD уже фактически сравнялись с жесткими дисками (местами и более емкие). Однако по стоимости хранения они все еще дороже.
- Гибридные. Совмещающие в одной системе как жесткие диски, так и SSD. Являются промежуточным вариантом, совмещающим достоинства и недостатки дисковых и flash хранилищ.
Если рассматривать форму хранения данных, то явно выделяются следующие:
- Файлы (именованные области данных). Наиболее популярный тип хранения данных — структура подразумевает хранение данных, одинаковое для пользователя и для накопителя.
- Блоки. Одинаковые по размеру области, при этом структура данных задается пользователем. Характерной особенностью является оптимизация скорости доступа за счет отсутствия слоя преобразования блоки-файлы, присутствующего в предыдущем способе.
- Объекты. Данные хранятся в плоской файловой структуре в виде объектов с метаданными.
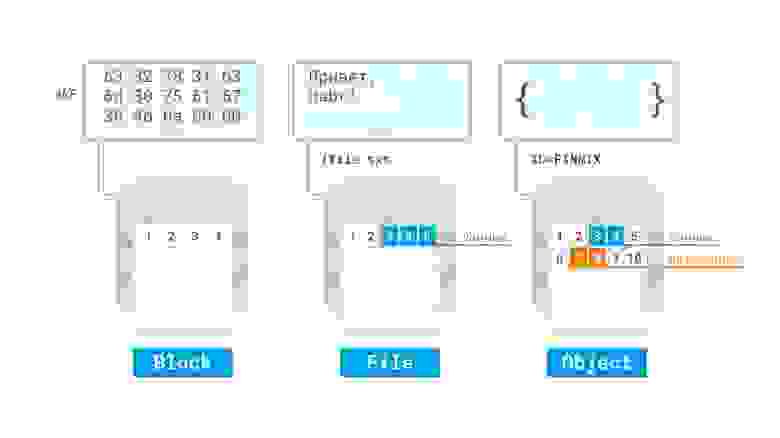
По реализации достаточно сложно провести четкие границы, однако можно отметить:
- аппаратные, например RAID и HBA контроллеры, специализированные СХД.

RAID контроллер от компании Fujitsu
- Программные. Например реализации RAID, включая файловые системы (например, BtrFS), специализированные сетевые файловые системы (NFS) и протоколы (iSCSI), а также SDS
пример организации LVM с шифрованием и избыточностью в виртуальной машине Linux в облаке Azure
Давайте рассмотрим более детально некоторые технологии, их достоинства и недостатки.
Direct Attached Storage — это исторически первый вариант подключения носителей, применяемый до сих пор. Накопитель, с точки зрения компьютера, в котором он установлен, используется монопольно, обращение с накопителем происходит поблочно, обеспечивая максимальную скорость обмена данными с накопителем с минимальными задержками. Также это наиболее дешевый вариант организации системы хранения данных, однако не лишенный своих недостатков. К примеру если нужно организовать хранение данных предприятия на нескольких серверах, то такой способ организации не позволяет совместное использование дисков разных серверов между собой, так что система хранения данных будет не оптимальной: некоторые сервера будут испытывать недостаток дискового пространства, другие же — не будут полностью его утилизировать:
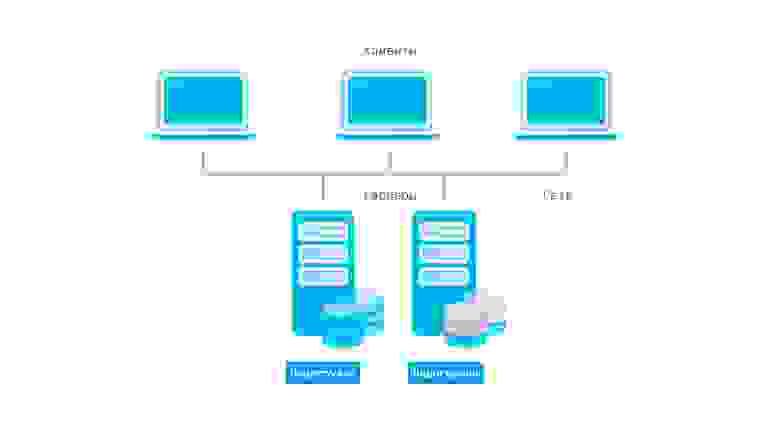
Конфигурации систем с единственным накопителем применяются чаще всего для нетребовательных нагрузок, обычно для домашнего применения. Для профессиональных целей, а также промышленного применения чаще всего используется несколько накопителей, объединенных в RAID-массив программно, либо с помощью аппаратной карты RAID для достижения отказоустойчивости и\или более высокой скорости работы, чем единичный накопитель. Также есть возможность организации кэширования наиболее часто используемых данных на более быстром, но менее емком твердотельном накопителе для достижения и большой емкости и большой скорости работы дисковой подсистемы компьютера.
Storage area network, она же сеть хранения данных, является технологией организации системы хранения данных с использованием выделенной сети, позволяя таким образом подключать диски к серверам с использованием специализированного оборудования. Так решается вопрос с утилизацией дискового пространства серверами, а также устраняются точки отказа, неизбежно присутствующие в системах хранения данных на основе DAS. Сеть хранения данных чаще всего использует технологию Fibre Channel, однако явной привязки к технологии передачи данных — нет. Накопители используются в блочном режиме, для общения с накопителями используются протоколы SCSI и NVMe, инкапсулируемые в кадры FC, либо в стандартные пакеты TCP, например в случае использования SAN на основе iSCSI.

Давайте разберем более детально устройство SAN, для этого логически разделим ее на две важных части, сервера с HBA и дисковые полки, как оконечные устройства, а также коммутаторы (в больших системах — маршрутизаторы) и кабели, как средства построения сети. HBA — специализированный контроллер, размещаемый в сервере, подключаемом к SAN. Через этот контроллер сервер будет «видеть» диски, размещаемые в дисковых полках. Сервера и дисковые полки не обязательно должны размещаться рядом, хотя для достижения высокой производительности и малых задержек это рекомендуется. Сервера и полки подключаются к коммутатору, который организует общую среду передачи данных. Коммутаторы могут также соединяться с собой с помощью межкоммутаторных соединений, совокупность всех коммутаторов и их соединений называется фабрикой. Есть разные варианты реализации фабрики, я не буду тут останавливаться подробно. Для отказоустойчивости рекомендуется подключать минимум две фабрики к каждому HBA в сервере (иногда ставят несколько HBA) и к каждой дисковой полке, чтобы коммутаторы не стали точкой отказа SAN.
Недостатками такой системы являются большая стоимость и сложность, поскольку для обеспечения отказоустойчивости требуется обеспечить несколько путей доступа (multipath) серверов к дисковым полкам, а значит, как минимум, задублировать фабрики. Также в силу физических ограничений (скорость света в общем и емкость передачи данных в информационной матрице коммутаторов в частности) хоть и существует возможность неограниченного подключения устройств между собой, на практике чаще всего есть ограничения по числу соединений (в том числе и между коммутаторами), числу дисковых полок и тому подобное.
Network attached storage, или сетевое файловое хранилище, представляет дисковые ресурсы в виде файлов (или объектов) с использованием сетевых протоколов, например NFS, SMB и прочих. Принципиально базируется на DAS, но ключевым отличием является предоставление общего файлового доступа. Так как работа ведется по сети — сама система хранения может быть сколько угодно далеко от потребителей (в разумных пределах разумеется), но это же является и недостатком в случае организации на предприятиях или в датацентрах, поскольку для работы утилизируется полоса пропускания основной сети — что, однако, может быть нивелировано с использованием выделенных сетевых карт для доступа к NAS. Также по сравнению с SAN упрощается работа клиентов, поскольку сервер NAS берет на себя все вопросы по общему доступу и т.п.
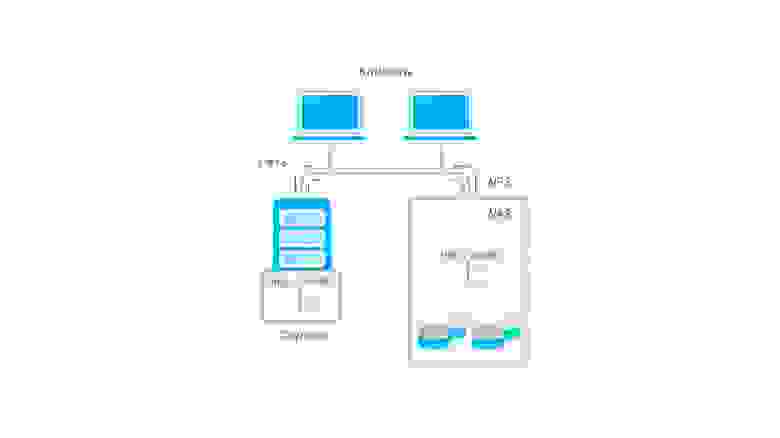
Unified storage
Универсальные системы, позволяющие совмещать в себе как функции NAS так и SAN. Чаще всего по реализации это SAN, в которой есть возможность активировать файловый доступ к дисковому пространству. Для этого устанавливаются дополнительные сетевые карты (или используются уже существующие, если SAN построена на их основе), после чего создается файловая система на некотором блочном устройстве — и уже она раздается по сети клиентам через некоторый файловый протокол, например NFS.
Software-defined storage — программно определяемое хранилище данных, основанное на DAS, при котором дисковые подсистемы нескольких серверов логически объединяются между собой в кластер, который дает своим клиентам доступ к общему дисковому пространству.
Наиболее яркими представителями являются GlusterFS и Ceph, но также подобные вещи можно сделать и традиционными средствами (например на основе LVM2, программной реализации iSCSI и NFS).
N.B. редактора: У вас есть возможность изучить технологию сетевого хранилища Ceph, чтобы использовать в своих проектах для повышения отказоустойчивости, на нашем практическим курсе по Ceph. В начале курса вы получите системные знания по базовым понятиям и терминам, а по окончании научитесь полноценно устанавливать, настраивать и управлять Ceph. Детали и полная программа курса здесь.
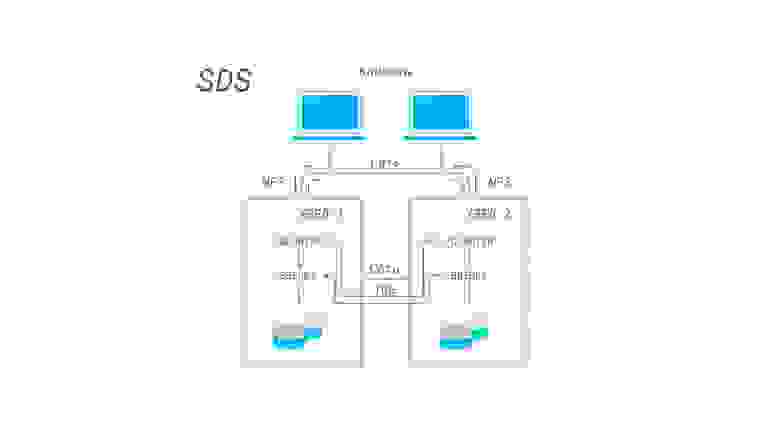
Пример SDS на основе GlusterFS
Из преимуществ SDS — можно построить отказоустойчивую производительную реплицируемую систему хранения данных с использованием обычного, возможно даже устаревшего оборудования. Если убрать зависимость от основной сети, то есть добавить выделенные сетевые карты для работы SDS, то получается решение с преимуществами больших SAN\NAS, но без присущих им недостатков. Я считаю, что за подобными системами — будущее, особенно с учетом того, что быстрая сетевая инфраструктура более универсальная (ее можно использовать и для других целей), а также дешевеет гораздо быстрее, чем специализированное оборудование для построения SAN. Недостатком можно назвать увеличение сложности по сравнению с обычным NAS, а также излишней перегруженностью (нужно больше оборудования) в условиях малых систем хранения данных.
Гиперконвергентные системы
Подавляющее большинство систем хранения данных используется для организации дисков виртуальных машин, при использовании SAN неизбежно происходит удорожание инфраструктуры. Но если объединить дисковые системы серверов с помощью SDS, а процессорные ресурсы и оперативную память с помощью гипервизоров отдавать виртуальным машинам, использующим дисковые ресурсы этой SDS — получится неплохо сэкономить. Такой подход с тесной интеграцией хранилища совместно с другими ресурсами называется гиперконвергентностью. Ключевой особенностью тут является способность почти бесконечного роста при нехватке ресурсов, поскольку если не хватает ресурсов, достаточно добавить еще один сервер с дисками к общей системе, чтобы нарастить ее. На практике обычно есть ограничения, но в целом наращивать получается гораздо проще, чем чистую SAN. Недостатком является обычно достаточно высокая стоимость подобных решений, но в целом совокупная стоимость владения обычно снижается.
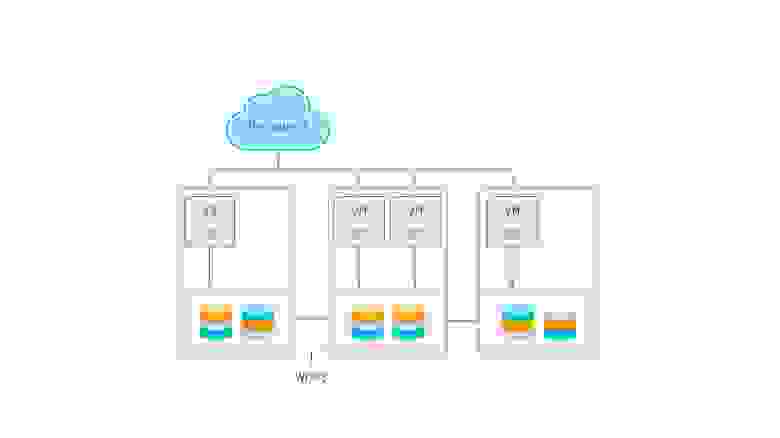
Облака и эфемерные хранилища
Логическим продолжением перехода на виртуализацию является запуск сервисов в облаках. В предельном случае сервисы разбиваются на функции, запускаемые по требованию (бессерверные вычисления, serverless). Важной особенностью тут является отсутствие состояния, то есть сервисы запускаются по требованию и потенциально могут быть запущены столько экземпляров приложения, сколько требуется для текущей нагрузки. Большинство поставщиков (GCP, Azure, Amazon и прочие) облачных решений предлагают также и доступ к хранилищам, включая файловые и блочные, а также объектные. Некоторые предлагают дополнительно облачные базы, так что приложение, рассчитанное на запуск в таком облаке, легко может работать с подобными системами хранения данных. Для того, чтобы все работало, достаточно оплатить вовремя эти услуги, для небольших приложений поставщики вообще предлагают бесплатное использование ресурсов в течение некоторого срока, либо вообще навсегда.

Из недостатков: могут заблокировать аккаунт, на котором все работает, что может привести к простоям в работе. Также могут быть проблемы со связностью и\или доступностью таких сервисов по сети, поскольку такие хранилища полностью зависят от корректной и правильной работы глобальной сети.
Заключение
Надеюсь, статья была полезной не только новичкам. Предлагаю обсудить в комментариях дополнительные возможности систем хранения данных, написать о своем опыте построения систем хранения данных.
Источник



