
- Физическое представление обрабатываемой информации
- Представление данных в памяти компьютера
- Логическое и физическое представление данных
- Схема работы процессора с памятью
- Готовые работы на аналогичную тему
- Взаимодействие видов памяти
- Физическое представление данных
- Страницы работы
- Содержание работы
- Физические модели данных (внутренний уровень)
- 9.1. Структура памяти ЭВМ
- 9.2. Представление экземпляра логической записи
Физическое представление обрабатываемой информации
Читайте также:
| ||||||||||||||||||||||||||||||||||||
 |
Рис.1.1. Классификация ЭВМ по физическому представлению информации
АВМ – работают с информацией, представленной в аналоговой форме, т.е. в виде непрерывного ряда значений некоторой физической величины, например, электрического напряжения. Они просты и удобны в использовании, возможны высокие скорости вычислений, но низкая точность вычислений. Обычно используются для решения математических задач, например, дифференциальных уравнений.
 |
Рис. 1.2. Аналоговая форма представления информации в ЭВМ
ЦВМ — работают с информацией, представленной в дискретной, а точнее цифровой форме. Это наиболее универсальное средство обработки данных.
 |
Рис.1. 3. Цифровая форма представления информации в ЭВМ
ГВМ – работают с информацией, представленной и в цифровой, и в аналоговой форме, и совмещают преимущества АВМ и ЦВМ. ГВМ целесообразно использовать для решения задач управления сложными быстродействующими техническими комплексами.
В экономике, науке и технике преимущественно используются ЦВМ.
Дата добавления: 2015-01-29 ; просмотров: 51 ; Нарушение авторских прав
Источник
Представление данных в памяти компьютера
Вы будете перенаправлены на Автор24
Логическое и физическое представление данных
Работая с СУБД пользователь имеет дело с логическим представлением данных и может вообще не знать о том, как физически организовано представление данных в памяти ЭВМ. Однако, от способа физического размещения данных во многом зависит эффективность работы приложений, использующих базы данных.
Физическая организация данных зависит от типа используемой ЭВМ и конкретной СУБД. Разные СУБД используют разные методы размещения данных в памяти и средства доступа к ним. Поэтому при выборе СУБД на этапе проектирования важно знать и понимать особенности физического способа хранения данных. Главным критерием выбора является эффективность доступа к данным.
Если основными понятиями логической модели данных являются логическое поле, логическая запись и логический файл, то для физической модели есть аналогичные основные понятия — физическое поле, физическая запись, физический файл.
При некоторых способах организации доступа одно логическое поле может отображаться непосредственно в одно физическое поле, одна логическая запись в одну физическую запись, а один логический файл в один физический файл. Но в общем случае такого взаимнооднозначного соответствия нет.
Схема работы процессора с памятью
В ЭВМ существует два вида памяти — оперативная и внешняя. При этом процессор напрямую обращается только к оперативной памяти. Базы данных предназначены для постоянного хранения больших объемов информации, следовательно они хранятся во внешней памяти. Поэтому организация доступа к данным должна учитывать особенности обои видов памяти и их взаимодействия.
Основные свойства оперативной памяти:
- Минимальная адресуемая единица информации – 1 байт.
- Каждый байт имеет свой уникальный адрес, то есть память прямоадресуема.
- Для выбора данных процессор обращается непосредственно к последовательности байтов, содержащей нужные данные.
Готовые работы на аналогичную тему
Основные свойства внешней памяти:
- Минимальная адресуемая единица информации – физическая запись.
- Для обработки процессором физическая запись должна быть считана в оперативную память.
- Считывание может осуществляться только небольшими блоками, так как всю базу разместить в оперативной памяти невозможно.
Взаимодействие видов памяти
Последовательность логических полей определенной логической записи отображается на последовательность прямоадресуемых байтов в оперативной памяти. Прямая адресация позволяет процессору обращаться к нужному полю. Для такого представления необходимо, чтобы все записи имели фиксированную длину, тогда длина записи будет равна сумме длин ее полей. Если длина поля не фиксирована, то становится невозможным использование прямой адресации.
Проблема может возникнуть в ситуации, когда нужно хранить большой фрагмент текста, длина которого у разных записей может варьировать. В этом случае текст размещается во внешней памяти, а поле хранит ссылку на эту область памяти. Именно так организовано поле типа МЕМО в некоторых СУБД.
При одном обращении оперативной памяти к внешней памяти происходит либо чтение, либо записывание одной физической записи. Каждое обращение к внешней памяти занимает определенное время, которое существенно влияет на скорость работы всей системы. Поэтому, чтобы минимизировать количество обращений к внешней памяти, в некоторых СУБД физическую запись удлиняют за счет включения в нее нескольких логических записей.
Другим способом минимизации числа обращений является использование физических записей фиксированной длины, которые не зависят от длины логических записей. Такие физические записи называются страницами. Если оказывается, что в страницу укладывается нецелое количество логических записей, то последняя неполная запись отбрасывается, и страница остается заполнена не до конца. Именно такой метод используется в MS SQL SERVER.
Источник
Физическое представление данных
Страницы работы





Содержание работы
Тема 6 :Физическое представлене данных.
6.1 Общие положения
Современные СУБД обладают высоким быстродействием поиска информации. Базы данных, имеющие мощность (т.е. количество записей) до ≈ 10 6 дают скорость только ≈ 2 сек. за счет чего, это быстродействие реализуется .В настоящее время существует 2 пути:
1. Использование языка SQL – для реализации запросов
SQL является реляционным языком, использующим элементы реляционной алгебры и реляционного исчисления кортежей.
В реляционных системах запросов существует возможность выбора эффективной стратегии для вычисления реляционного выражения с помощью которого сформирован запрос.
Этот процесс – выбор эффективной стратегии вычислений выполняет оптимизатор. Он позволяет в отдельных случаях, сократить количество операций, которые необходимо произвести для организации поиска на 4 порядка т.е. в 10 000 раз. То есть мы имеем редкое увеличения скорости 10 4 раза., т.е. поиск старым оператором языка и SQL выиграл в 10 4 раза. Изучая обработку данных с помощью ЭВМ мы постепенно обращаемся к трем выделенным областям:
1. реальному миру;
Между этими тремя областями существуют определенные взаимосвязи. Тема рассматриваемая сегодня имеет отношение к 3 – й области – к области данных.
А область данных, как вы помните состоит из 3-х компонент:
3.1. Общая логическая структура данных (или данные в представлении администратора данных);
3.2. Данные в представлении программиста;
3.3.Представление данных в памяти ЭВМ.
Т.е. логическая структура данных и представление этой структуры в памяти ЭВМ это два важных, но различных между собой понятия.
Логические структуры данных это:
Что касается представления данных в памяти, то существует два метода :
Первый метод заключается в том, что каждому элементу данных указывается адрес памяти ЭВМ. Размещение данных (т.е. их запоминание) и их выборка осуществляется по известному адресу.
Второй метод заключается в том, что содержание ключа конкретной записи преобразуется определенным методом (существует несколько методов) в адрес памяти ЭВМ. В этом случае размещение данных и их выборка осуществляются по известному значению ключа, т.е. определяются по содержимым самих данных. Этот случай хорошо реализуется в ассоциативной памяти ЭВМ или с помощью специального программного обеспечения в обычной памяти ЭВМ.
Для первого и второго метода существует общая проблема – как эффективно отобразить логическую структуру данных на физическую структуру хранения.
Т.е. речь идет о нахождении адресной функции, которая позволяла бы быстро вычислять где хранятся необходимые данные.
6.2. 1 –й метод представления данных в памяти ЭВМ.
6.2.1. Последовательное распределение памяти.
Пусть у нас есть определенный тип записи с экземпляром записей У1, У2,…, Уп.
Будем считать, что запись, состоящая из элементов данных, хранится целиком и разделение на атрибуты или элементы данных происходит после выборки записи.
Такую структуру можно определить как линейное упорядочение записей, т.е. номера записей следуют один за другим или линейный список.
В такой структуре каждая запись идентифицирована своим порядковым номером. Обозначим через:
N – количество записей в списке
m- размер записей в байтах
β – адрес базы, указывающий на начало вектора данных в памяти
i – текущая запись в списке
α – адрес физической памяти.
В этом случае адрес каждой записи можно вычислить с помощью адресной функции, отображающий логический индекс, идентифицирующий адрес в структуре, в адрес физической памяти.
Источник
Физические модели данных (внутренний уровень)
Цель лекции: дать представление об основных типовых способах организации данных в памяти ЭВМ в СУБД с оценкой соответствующих моделей по времени доступа к данным в базе данных и по объему занимаемой памяти.
Как уже отмечалось, концептуальная схема, специфицированная к СУБД , автоматически отображается в структуру хранения программами СУБД . Внешний пользователь может ничего не знать о том, как его представление о данных физически организовано в памяти вычислительной системы. Тем не менее от физического размещения данных в памяти ЭВМ существенно зависит время решения прикладных задач. В связи с этим, даже на одном из начальных этапов проектирования базы данных – этапе выбора СУБД , желательно знать возможности физических структур хранения , представляемых конкретными СУБД , и оценивать временные характеристики проектируемой базы данных с учетом этих возможностей.
Способы физической организации данных в различных СУБД , как правило, различны и определяются типом используемой ЭВМ, инструментальными средствами разработки СУБД , а также критериями, которыми руководствуются разработчики СУБД при выборе методов размещения данных и способов доступа к этим данным. Заметим, что наиболее распространенным критерием служит время доступа к данным, однако в качестве критерия может выбираться, например, трудоемкость реализации соответствующих методов.
В настоящей лекции будут рассмотрены типовые физические модели организации данных в конкретных СУБД .
Физические модели данных служат для отображения моделей данных. Основными понятиями модели данных являются поле , логическая запись , логический файл . Слово » логический » введено, чтобы отличать понятия, относящиеся к логической модели данных , от понятий, относящихся к физической модели данных . Основными понятиями физической модели данных, используемыми для представления логической модели данных, являются поле, физическая запись , физический файл. В частности, логическая запись , состоящая из полей, может быть представлена в виде физической записи (из тех же полей), логический файл – в виде физического файла. Прежде чем конкретизировать понятия, относящиеся к физической модели данных , рассмотрим структуру памяти ЭВМ.
9.1. Структура памяти ЭВМ
Важнейшей особенностью памяти ЭВМ, в значительной степени определяющей методы организации данных и доступа к ним, является её неоднородность. Существуют два разных типа памяти – оперативная (ОП) и внешняя (ВП), причем процессор работает только с данными из оперативной памяти ( рис. 9.1.).

Как уже многократно отмечалось, базы данных создаются для работы с большими объемами данных, что обусловливает необходимость использования внешней памяти. Поэтому организация данных и доступа к ним должна учитывать как специфику каждого типа памяти, так и способы их взаимодействия.
Отметим основные свойства оперативной памяти:
- единицей памяти является байт;
- память прямоадресуема (каждый байт имеет адрес);
- процессор выбирает для обработки нужные данные, непосредственно адресуясь к последовательности байтов, содержащих эти данные.
Отметим основные свойства внешней памяти:
- минимальной адресуемой единицей является физическая запись ;
- для последующей обработки (например, работы с полями) запись должна быть считана в оперативную память;
- время чтения записи в ОП на несколько порядков выше времени обработки процессором записи из ОП;
- организация обмена осуществляется порциями, т.к. невозможно считать сразу всю базу данных.
9.2. Представление экземпляра логической записи
Логическая запись представляется в оперативной памяти следующим образом:
| Логическая запись | Последовательность байтов ОП | |||||||
|---|---|---|---|---|---|---|---|---|
| Поле 1 | Поле 2 | . | Поле N |  | B1 | B2 | . | BN |
| Тип поля | Bi – последовательность байтов ОП, используемая для хранения поля i | |||||||
| Характеристика поля | ||||||||
| Длина | ||||||||
Прямая адресация байтов позволяет процессору выбирать для обработки нужное поле .
Заметим, что указанное представление не делает различий для записей в сетевой, иерархической и реляционных моделях. В случае сетевой и иерархической моделей некоторые поля могут являться указателями, тогда последовательность байтов, используемая для хранения этих полей, содержит адрес начала последовательности байтов, соответствующей записи – члену отношения.
В большинстве современных СУБД используется формат записей фиксированной длины. В этом случае все записи имеют одинаковую длину, определяемую суммарной длиной полей, составляющих запись . В СУБД другие форматы записей (переменной длины, неопределенной длины) встречаются гораздо реже, поэтому в данной книге эти форматы не рассматриваются. Заметим, что поля записи, принимающие значения существенно разной длины в различных экземплярах записей, в предметной области встречаются достаточно часто. Примером может служить поле резюме в записи СОТРУДНИК. Резюме может составлять полстраницы текста, страницу и т.д. Возникает проблема – как эту информацию переменной длины представить в записи фиксированной длины. Возможным вариантом является установление размера соответствующего поля по максимальному значению. В этом случае у многих экземпляров записи указанное поле будет заполнено не полностью и, таким образом, память ЭВМ будет использоваться неэффективно. Более эффективный и часто используемый в СУБД прием организации таких записей состоит в следующем. Вместо поля (полей), принимающего значение существенно разной длины, в запись включается поле — указатель на область памяти, где будет размещаться значение исходного поля. Как правило, эта область является областью внешней памяти прямого доступа. В процессе ввода соответствующего значения в выделенной области занимается столько памяти, какова длина этого значения.
На рис. 9.2 представлен пример вышеуказанного представления экземпляров записей из N полей, причем поле N принимает значения соответственно разной длины у разных экземпляров записей .
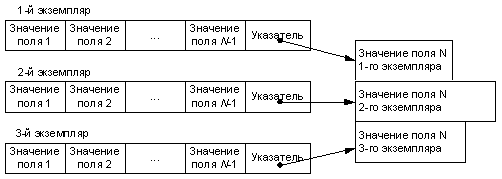
Конкретной реализацией такой схемы является поле типа МЕМО в СУБД (dBase III+, FoxPro, Access и т.д.).
Источник



