
Зачем и как хранить объекты на примере MinIO

Наша биг дата проанализировала Telegram-чаты, форумы и разговоры в кулуарах IT-мероприятий и пометила объектные хранилища как инструмент, который ещё не все осмеливаются использовать в своих проектах. Хочу поделиться с вами своим опытом в формате статьи-воркшопа. Если вы пока не знакомы с этой технологией и паттернами её применения, надеюсь, эта статья поможет вам начать использовать её в своих проектах.
Зачем вообще говорить о хранении объектов?
С недавних пор я работаю Golang-разработчиком в Ozon. У нас в компании есть крутая команда админов и релиз-инженеров, которая построила инфраструктуру и CI вокруг неё. Благодаря этому я даже не задумываюсь о том, какие инструменты использовать для хранения файлов и как это всё поддерживать.
Но до прихода в Ozon я сталкивался с довольно интересными кейсами, когда хранение разных данных (документов, изображений) было организовано не самым изящным образом. Мне попадались SFTP, Google Drive и даже монтирование PVC в контейнер!
Использование всех этих решений сопряжено с проблемами, в основном связанными с масштабированием. Это и привело меня к знакомству с объектными хранилищами, ведь с их помощью можно красиво и удобно решать целый ряд задач.
Объектное хранилище – это дополнительный слой абстракции над файловой системой и хостом, который позволяет работать с файлами (получать доступ, хранить) через API.
Объектное хранилище может помочь вам в кейсах, когда необходимо хранить файлы пользователей в ваших приложениях, складывать статику и предоставлять доступ к ней через Ingress или хранить кеши вашего CI.
Все материалы к статье (исходники, конфиги, скрипты) лежат вот в этой репе.
Что такое объектное хранилище
Хранить данные нашего приложения можно различными способами, от хранения данных просто на диске до блоба в нашей БД (если она это поддерживает, конечно). Но будет такое решение оптимальным? Часто есть нефункциональные требования, которые нам хотелось бы реализовать: масштабируемость, простота поддержки, гибкость. Тут уже хранением файлов в БД или на диске не обойтись. В этих случаях, например, масштабирование программных систем, в которых хранение данных построено на работе с файловой системой хоста, оказывается довольно проблематичной историей.
И на помощь приходят те самые объектные хранилища, о которых сегодня и пойдёт речь. Объектное хранилище – это способ хранить данные и гибко получать к ним доступ как к объектам (файлам). В данном контексте объект – это файл и набор метаданных о нём.
Стоит ещё упомянуть, что в объектных хранилищах нет такого понятия, как структура каталогов. Все объекты находятся в одном «каталоге» – bucket. Структурирование данных предлагается делать на уровне приложения. Но никто не мешает назвать объект, например, так: objectScope/firstObject.dat .
Основное преимущество хранения данных в объектах – это возможность абстрагирования системы от технических деталей. Нас уже не интересует, какая файловая (или тем более операционная) система хранит наши данные. Мы не привязываемся к данным какими-то конкретными способами их представления, которые нам обеспечивает платформа.
В этой статье мы не будем сравнивать типы объектных хранилищ, а обратим наше внимание на класс S3-совместимых стораджей, на примере MinIO. Выбор обусловлен тем, что MinIO имеет низкий порог входа (привет, Ceph), а ещё оно Kubernetes Native, что бы это ни значило.
На мой взгляд, MinIO – это самый доступный способ начать использовать технологию объектного хранения данных прямо сейчас: его просто развернуть, легко управлять и его невозможно забыть. На протяжении долгого времени MinIO может удовлетворять таким требованиям, как доступность, масштабируемость и гибкость.
Вообще S3-совместимых решений на рынке много. Всегда есть, из чего выбрать, будь то облачные сервисы или self-hosted-решения. В общем случае мы всегда можем перенести наше приложение с одной платформы на другую (да, у некоторых провайдеров есть определённого рода vendor lock-in, но это уже детали конкретных реализаций).
Disclaimer: под S3 я буду иметь в виду технологию (S3-совместимые объектные хранилища), а не конкретный коммерческий продукт. Цель статьи – показать на примерах, как можно использовать такие решения в своих приложениях.
Кейс 1: прокат самокатов
В рамках формата статьи-воркшопа знакомиться с S3 в общем и с MinIO в частности мы будем на практике.
На практике часто возникает вопрос хранения и доступа к контенту, который генерируется или обрабатывается вашим приложением. Правильно выбранный подход может обеспечить спокойный сон и отсутствие головной боли, когда придёт время переносить или масштабировать наше приложение.
Давайте перейдём к кейсу. Представим, что мы пишем сервис для проката самокатов и у нас есть user story, когда клиент фотографирует самокат до и после аренды. Хранить медиаматериалы мы будем в объектном хранилище.
Для начала развернём наше хранилище.
Самый быстрый способ развернуть MinIO – это наш любимчик Docker, само собой.
С недавнего времени Docker – не такая уж и бесплатная штука, поэтому в репе на всякий случай есть альтернативные манифесты для Podman.
Запускать «голый» контейнер из терминала – нынче моветон, поэтому начнём сразу с манифеста для docker-compose.
Сохраняем манифест и делаем $ docker-compose up в директории с манифестом.
Теперь мы можем управлять нашим хранилищем с помощью web-ui. Но это не самый удобный способ для автоматизации процессов (например, для создания пайплайнов в CI/CD), поэтому сверху ещё поставим CLI-утилиту:
$ go get github.com/minio/mc
И да, не забываем про export PATH=$PATH:$(go env GOPATH)/bin.
Cоздадим алиас в mc (залогинимся):
$ mc alias set minio http://localhost:9000 ozontech minio123
Теперь создадим bucket – раздел, в котором мы будем хранить данные нашего пользователя (не стоит ассоциировать его с папкой). Это скорее раздел, внутри которого мы будем хранить данные.
Назовем наш бакет “usersPhotos”:
$ mc mb minio/usersPhot
$ mc ls minio > [0B] usersPhotos
Теперь можно приступать к реализации на бэке. Писать будем на Golang. MinIO любезно нам предоставляет пакетик для работы со своим API.
Disclaimer: код ниже – лишь пример работы с объектным хранилищем; не стоит его рассматривать как набор best practices для использования в боевых проектах.
Начнём с подключения к хранилищу:
Теперь опишем ручку добавления медиа:
Нам надо как-то разделять фото до и после, поэтому мы добавим записи в базу данных:
Ну и сам метод обновления записи в БД:
Также мы могли бы напрямую через сервис вытаскивать и отдавать фото по запросу. Выглядело бы это примерно так:
Ну и само получение файла из хранилища:
Но мы можем и просто проксировать запрос напрямую в MinIO, так как у нас нет причин этого не делать (на практике такими причинами могут быть требования безопасности или препроцессинг файлов перед передачей пользователю). Делать это можно, обернув всё в nginx:
Получать ссылки на изображения мы будем через ручку rent_info:
И сам метод обогащения:
Упакуем всё в docker-compose.yaml:
Протестируем работу нашего приложения:
Изображение полученное при переходе по URL от ответа сервиса
Кейс 2: хранение и раздача фронта
Ещё одна довольно популярная задача, для решения которой можно использовать объектные хранилища, – хранение и раздача фронта. Объектные хранилища пригодятся нам тут, когда захотим повысить доступность нашего фронта или удобнее им управлять. Это актуально, например, если у нас несколько проектов и мы хотим упростить себе жизнь.
Небольшая предыстория. Однажды я встретил довольно интересную практику в компании, где в месяц релизили по несколько лендингов. В основном они были написаны на Vue.js, изредка прикручивался API на пару простеньких ручек. Но моё внимание больше привлекло то, как это всё деплоилось: там царствовали контейнеры с nginx, внутри которых лежала статика, а над всем этим стоял хостовый nginx, который выполнял роль маршрутизатора запросов. Как тебе такой cloud-native-подход, Илон? В качестве борьбы с этим монстром мной было предложено обмазаться кубами, статику держать внутри MinIO, создавая для каждого лендинга свой бакет, а с помощью Ingress уже всё это проксировать наружу. Но, как говорится, давайте не будем говорить о плохом, а лучше сделаем!
Представим, что перед нами стоит похожая задача и у нас уже есть Kubernetes. Давайте туда раскатаем MinIO Operator. Стоп, почему нельзя просто запустить MinIO в поде и пробросить туда порты? А потому, что MinIO-Operator любезно сделает это за нас, а заодно построит High Availability-хранилище. Для этого нам всего лишь надо три столовые ложки соды. воспользоваться официальной документацией.
Для простоты установки мы вооружимся смузи Krew, который всё сделает за нас:
$ kubectl krew update
$ kubectl krew install minio
$ kubectl minio init
Теперь надо создать tenant. Для этого перейдём в панель управления. Чтобы туда попасть, прокинем прокси:
$ kubectl minio proxy -n minio-operator
После прокидывания портов до нашего оператора мы получим в вывод терминала JWT-токен, с которым и залогинимся в нашей панели управления:
Интерфейс управления тенантами
Далее нажимаем на кнопку «Добавить тенант» и задаём ему имя и неймспейс:
Интерфейс настройки тенанта
После нажатия на кнопку «Создать» мы получим креденшиалы, которые стоит записать в какой-нибудь Vault:
Теперь для доступа к панели нашего кластера хранилищ, поднимем прокси к сервису minio-svc и его панели управления:
И вуаля! У нас есть высокодоступный отказоустойчивый кластер MinIO. Давайте прикрутим его к нашему GitLab CI и сделаем .gitlab_ci, чтобы в пару кликов деплоить фронт.
Вот так у нас будет выглядеть джоба для CI/CD на примере GitLab CI (целиком конфиг лежит в репе):
Для того чтобы отдавать статику, добавим Ingress-манифест:
А если вдруг потребуется доступ из других неймспейсов, то мы можем создать ресурс ExternalName:
Вместо вывода
Объектные хранилища – это класс инструментов, которые позволяют наделить систему высокодоступным хранилищем данных. Во времена cloud-native это незаменимый помощник в решении многих задач. Да, на практике могут случаться кейсы, в которых использование объектного хранения данных будет избыточным, но вряд ли это можно считать поводом совсем игнорировать этот инструментарий в других своих проектах.
Отдельно я бы посоветовал обратить внимание на S3-совместимые решения, если вы занимаетесь машинным обучением или BigData и у вас есть потребность в хранении большого количества медиаданных для их последующей обработки.
Рассмотренное в статье MinIO – это не единственный достойный инструмент, который позволяет работать с данной технологией. Существуют решения на основе Ceph и Riak CS и даже S3 от Amazon. У всех инструментов свои плюсы и минусы.
Желаю вам успехов в создании и масштабировании ваших приложений и надеюсь, что объектные хранилища вам будут в этом помогать!
Делитесь в комментариях о вашем опыте работы с объектными хранилищами и задавайте вопроы!
Источник
Физический дизайн структур хранения в СУБД Teradata
Что такое физический дизайн структур хранения
Основная цель, преследуемая в ходе разработки физической модели данных, — создание таких объектов для конкретной платформы/СУБД, которые позволят достигнуть максимальной производительности запросов/приложений, создающих основную нагрузку, сведя при этом дополнительные затраты, такие как необходимость поддерживать дополнительные индексы, выполнять материализацию производных данных и т. п., к минимуму.
Все реляционные СУБД построены на одних принципах, но каждой платформе присущи уникальные черты в виде наличия различных типов объектов и особенностей их реализации. По этой причине процесс физического моделирования является платформенно-зависимым, в отличие от логического моделирования, основная цель которого — достоверно описать данные и бизнес-процессы.
Хранение данных в СУБД Teradata
Говоря о физическом дизайне баз данных на платформе Teradata, помимо прочего, необходимо упомянуть, что это MPP (Massive Parallel Processing) платформа, в которой все данные распределяются по компонентам системы (AMP’ам) и обрабатываются ими при выполнении пользовательских запросов параллельно (см. нашу первую статью). Такая архитектура, а также равномерное распределение данных делают их обработку эффективной и в отсутствие дополнительных элементов обеспечения производительности. Эта возможность позволяет Teradata прекрасно справляться с Ad-Hoc запросами, не предусмотренными разработчиками физической модели.
Но для смешанной нагрузки, когда в системе одновременно выполняются и тактические (OLTP-подобные), и стратегические (OLAP, DSS, Data Mining) запросы, этого явно недостаточно. Особенно это относится к тактическим запросам, которые имеют достаточно высокие требования к времени отклика и пропускной способности. Основная техника физического дизайна для повышения производительности тактических запросов — создание индексов — путей доступа к данным, которые могут быть использованы запросами для быстрого поиска нужных строк таблицы без необходимости ее полного просмотра. Использование индексов позволяет радикально сократить количество операций ввода-вывода при выполнении запроса, что сокращает время отклика и, как следствие, повышает пропускную способность системы. Давайте посмотрим, как устроены индексы в Teradata, с учетом параллельной архитектуры.
Способы доступа к данным
СУБД Teradata поддерживает различные способы доступа к строкам таблиц:
Доступ по первичному индексу (о том, что такое первичный индекс, речь шла в нашей первой статье)
Это самый быстрый и наименее затратный способ доступа к данным в Teradata.
Напомним, что данные в СУБД Teradata распределяются с использованием результата хеширования значения колонки первичного индекса. Строки с одинаковыми значениями колонки первичного индекса ВСЕГДА попадают на один и тот же AMP. 
Алгоритм, применяемый для определения AMP’а, на котором должна быть размещена строка при ее вставке в таблицу, с тем же успехом используется и для поиска строки с известным значением колонки первичного индекса. 
Когда AMP, на котором находится искомая строка, определен, Teradata использует индексные структуры для поиска требуемого блока данных. Последовательно просматриваются:
- Master Index (всегда загружен в память AMP’а) для поиска цилиндра, содержащего нужный блок данных;
- Cylinder Index (почти всегда загружен в память AMP’а) для поиска нужного блока данных.
После того как требуемый блок данных найден, производится его чтение и далее — поиск строки с использованием массива указателей строк (Row Reference Array).
Данный алгоритм одинаково работает как для уникальных (Unique Primary Index — UPI), так и неуникальных (Non-unique Primary Index — NUPI) первичных индексов — с той лишь разницей, что при доступе по UPI всегда читается только один блок данных и возвращается не более одной строки, в то время как при доступе по NUPI эти значения зависят от степени неуникальности индекса.
Формат строки базовой таблицы 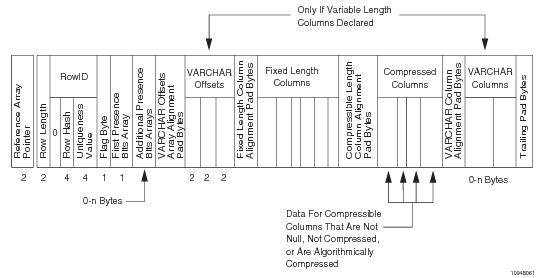
Особенность хранения данных в Teradata состоит в том, что на каждом AMP’е строки таблиц хранятся не в произвольном порядке, а отсортированы по хеш-значениям первичного индекса. Такой подход требует дополнительных усилий при вставке данных, поскольку новые строки нужно вставлять не в «конец таблицы», а так, чтобы сохранять сортировку по хешам. При этом мы получаем два преимущества:
- При соединении по колонке первичного индекса — возможность сразу применять эффективное соединение MERGE JOIN, поскольку строки уже упорядочены.
- Автоматическое индексирование колонки первичного индекса. Внутренние индексы файловой системы (мастер-индекс и цилиндр-индекс), указанные выше, содержат внутри себя диапазоны хеш-значений для тех данных, которые хранятся в блоках данных. За счет того, что строки упорядочены, эти диапазоны не пересекаются. Как следствие — создавая разметку дискового пространства на блоки данных, мы фактически получаем не только саму эту разметку, но и индексирование колонки первичного индекса — классический B-tree-индекс по хеш-значениям первичного индекса. Мы даже иногда говорим, что первичный индекс не занимает дискового пространства и не требует сопровождения, — имея в виду, что он является частью структуры «мастер-индекс» и «цилиндр-индекс» для хранения данных на дисковой системе AMP’ов.
Особенности данного алгоритма также определяют и присущие ему ограничения, а именно — доступ по первичному индексу возможен только при следующих условиях:
- использование в запросе условия «равно» для фильтрации по колонке первичного индекса;
- включение в условия поиска ВСЕХ колонок, составляющих первичный индекс.
Доступ по вторичному индексу
Вторичные индексы — альтернативные пути доступа к данным. Реализованы в виде индексных подтаблиц, позволяющих по значению колонки индексирования определить соответствующие ему идентификаторы строк базовой таблицы.
Реализация индексных подтаблиц уникального (Unique Secondary Index — USI) и неуникального (Non-unique Secondary Index — NUSI) вторичных индексов отличаются.
Формат строки индексной подтаблицы USI 
Строки индексной подтаблицы USI распределяются по AMP’ам с использованием результата хеширования колонки индексирования. С высокой вероятностью строка индексной таблицы будет находиться на другом по отношению к соответствующей строке базовой таблицы AMP’е. Каждой строке базовой таблицы соответствует строка индексной подтаблицы. Доступ к данным с использованием USI требует вовлечения двух AMP’ов (первый — для поиска строки в индексе, второй — для чтения строки базовой таблицы по ее идентификатору). Доступ к данным с использованием USI можно считать таким же эффективным, как и с использованием первичного индекса. Основное назначение USI — доступ к данным по значению индексной колонки. Точно так же, как и для первичного индекса, в выражении «WHERE» должны быть указаны ВСЕ колонки, составляющие индекс с условием «РАВНО».

Формат строки индексной подтаблицы NUSI

Строки индексной подтаблицы NUSI расположены локально (на тех же AMP’ах) по отношению к строкам базовой таблицы и по умолчанию логически отсортированы по hash-значению колонки вторичного индекса. Такое хранение означает, что строки с одним и тем же значением индексной колонки могут встречаться на любом из AMP’ов системы, а следовательно, в поиск требуемых строк в индексной подтаблице будут вовлечены все AMP’ы. Далее, для выбора строк из базовой таблицы будут задействованы только те AMP’ы, на которых отобраны строки индексной подтаблицы. Будет ли оптимизатор использовать NUSI для доступа к данным, зависит от селективности индекса. В качестве значения, при превышении которого оптимизатор выберет полный просмотр таблицы, можно ориентироваться на 1 % (если при выполнении запроса будет отобрано менее 1 % строк таблицы, индекс будет использован). Из этого следует правило: собирайте статистики по NUSI, без них оптимизатор выберет FTS.

Как и в случае с PI и USI, по умолчанию NUSI используется для доступа к строкам по значению (условие «РАВНО» на все колонки NUSI в выражении «WHERE»). Но помимо этого, NUSI может быть использован и для запросов с диапазонным доступом к строкам таблицы, для чего существует опция «ORDER BY VALUES», которая логически сортирует строки индексной подтаблицы по значению индексной колонки. Созданный таким образом индекс позволяет повысить производительность с условиями на индексную колонку, отличными от «РАВНО»: , >=,
Источник



