
Методы эффективного кодирования информации

Лабораторная работа №9. Методы эффективного кодирования информации
Изучить алгоритм Хаффмена для оптимального префиксного кодирования алфавита с минимальной избыточностью.
2. Теоретические сведения
Алгоритм Хаффмена (англ. Huffman) – алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью был разработан в 1952 году доктором Массачусетского технологического института Дэвидом Хаффменом. Он более практичен и никогда по степени сжатия не уступает методу Шеннона-Фэно, более того, он сжимает максимально плотно.
Этот метод кодирования состоит из двух основных этапов:
Построение оптимального кодового дерева.
Построение отображения код-символ на основе построенного дерева.
Алгоритм кодирования может быть представлен следующим образом:
Символы первичного алфавита m1 выписывают в порядке убывания вероятностей.
Последние n0 символов объединяют в новый символ, вероятность которого равна сумме этих символов, удаляют эти символы и вставляют новый символ в список остальных на соответствующее место (по вероятности). n0 вычисляется из системы:

где a – целое число,
m1 и m2 – мощность первичного и вторичного алфавита соответственно.
Последние m2 символов снова объединяют в один и вставляют его в соответствующей позиции, предварительно удалив символы, вошедшие в объединение.
Предыдущий шаг повторяют до тех пор, пока сумма всех m2 символов не станет равной 1.
Этот процесс можно представить как построение дерева, корень которого – символ с вероятностью 1, получившийся при объединении символов из последнего шага, его m2 потомков – символы из предыдущего шага и т.д.
Каждые m2 элементов, стоящих на одном уровне, нумеруются от 0 до m2-1 . Коды получаются из путей (от первого потомка корня и до листка). При декодировании можно использовать то же самое дерево, считывается по одной цифре и делается шаг по дереву, пока не достигается лист – тогда выводится символ, стоящий в листе и производится возврат в корень.
Для двоичного кода описанная методика значительно упрощается. В этом случае n0 = m2 = 2, а полученное в результате построения дерево называется двоичным.
Рассмотрим применение алгоритма Хаффмена для последовательности «aa bbb cccc ddddd» (таблица 12 , таблица 13).
Энтропия исходного сообщения равна:

Таблица 12 — Процедура оптимального двоичного кодирования

Таблица 13 — Результат кодирования по методу Хаффмена
Источник
Методы эффективного кодирования информации
Информационную избыточность можно ввести разными путями. Рассмотрим один из путей эффективного кодирования.
В ряде случаев буквы сообщений преобразуются в последовательности двоичных символов. Учитывая статистические свойства источника сообщения, можно минимизировать среднее число двоичных символов, требующихся для выражения одной буквы сообщения, что при отсутствии шума позволит уменьшить время передачи.
Такое эффективное кодирование базируется на основной теореме Шеннона для каналов без шума, в которой доказано, что сообщения, составленные из букв некоторого алфавита, можно закодировать так, что среднее число двоичных символов на букву будет сколь угодно близко к энтропии источника этих сообщений, но не меньше этой величины.
Теорема не указывает конкретного способа кодирования, но из нее следует, что при выборе каждого символа кодовой комбинации необходимо стараться, чтобы он нес максимальную информацию. Следовательно, каждый символ должен принимать значения 0 и 1 по возможности с равными вероятностями и каждый выбор должен быть независим от значений предыдущих символов.
При отсутствии статистической взаимосвязи между буквами конструктивные методы построения эффективных кодов были даны впервые К.Шенноном и Н. Фано. Их методики существенно не различаются, поэтому соответствующий код получил название кода Шеннона-Фано.
Код строится следующим образом: буквы алфавита сообщений выписываются в таблицу в порядке убывания вероятностей. Затем они разделяются на две группы так, чтобы суммы вероятностей в каждой из групп были по возможности одинаковы. Всем буквам верхней половины в качестве первого символа приписывается 1, а всем нижним — 0. Каждая из полученных групп, в свою очередь, разбивается на две подгруппы с одинаковыми суммарными вероятностями и т. д. Процесс повторяется до тех пор, пока в каждой подгруппе останется по одной букве.
Рассмотрим алфавит из восьми букв (табл. 3.4). Ясно, что при обычном (не учитывающем статистических характеристик) кодировании для представления каждой буквы требуется три символа.
Таблица 3.4 – Кодирование по методике Шеннона-Фано
Источник
Кодирование для чайников, ч.1
Не являясь специалистом в обозначенной области я, тем не менее, прочитал много специализированной литературы для знакомства с предметом и прорываясь через тернии к звёздам набил, на начальных этапах, немало шишек. При всём изобилии информации мне не удалось найти простые статьи о кодировании как таковом, вне рамок специальной литературы (так сказать без формул и с картинками).
Статья, в первой части, является ликбезом по кодированию как таковому с примерами манипуляций с битовыми кодами, а во второй я бы хотел затронуть простейшие способы кодирования изображений.
0. Начало
Поскольку я обращаюсь к новичкам в этом вопросе, то не посчитаю зазорным обратиться к Википедии. А там, для обозначения кодирования информации, у нас есть такое определение — процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
Чего мне не хватало в 70-80-е, так это в школе, пусть не на информатике, а, например, на уроках математики — базовой информации по кодированию. Дело в том, что кодированием информации каждый из нас занимается ежесекундно, постоянно и в целом — не концентрируясь на самом кодировании. То есть в быту мы это делаем постоянно. Так как это происходит?
Мимика, жесты, речь, сигналы разного уровня — табличка с надписью, знак на дороге, светофоры, и для современного мира — штрих- и бар-коды, URL, хэш-тэги.
Давайте рассмотрим некоторые более подробно.
1.1 Речь, мимика, жесты
Удивительно, но всё это — коды. С помощью них мы передаём информацию о своих действиях, ощущениях, эмоциях. Самое важное, чтобы коды были понятны всем. Например, родившись в густых лесах у Амазонки и не видя современного городского человека, можно столкнуться с проблемой непонимания кода — улыбка, как демонстрация зубов, будет воспринята как угроза, а не как выражение радости.
Следуя определению, что же происходит когда мы говорим? Мысль — как форма, удобная для непосредственного использования, преобразуется в речь — форму удобную для передачи. И, смотрите, так как у звука есть ограничение как на скорость, так и на дальность передачи, то, например, жест, в какой-то ситуации, может быть выбран для передачи той же информации, но на большее расстояние.
Но мы всё еще будем ограничены дальностью остроты нашего зрения, и тогда — человек начинает придумывать другие способы передачи и преобразования информации, например огонь или дым.
1.2 Чередующиеся сигналы
В примитивном виде кодирование чередующимися сигналами используется человечеством очень давно. В предыдущем разделе мы сказали про дым и огонь. Если между наблюдателем и источником огня ставить и убирать препятствие, то наблюдателю будет казаться, что он видит чередующиеся сигналы «включено/выключено». Меняя частоту таких включений мы можем выработать последовательность кодов, которая будет однозначно трактоваться принимающей стороной.
Наряду с сигнальными флажками на морских и речных судах, при появлении радио начали использовать код Морзе. И при всей кажущейся бинарности (представление кода двумя значениями), так как используются сигналы точка и тире, на самом деле это тернаный код, так как для разделения отдельных кодов-символов требуется пауза в передаче кода. То есть код Морзе кроме «точка-тире», что нам даёт букву «A» может звучать и так — «точка-пауза-тире» и тогда это уже две буквы «ET».

1.3 Контекст
Когда мы пользуемся компьютером, мы понимаем, что информация бывает разной — звук, видео, текст. Но в чем основные различия? И до того, как начать информацию кодировать, чтобы, например, передавать её по каналам связи, нужно понять, что из себя представляет информация в каждом конкретном случае, то есть обратить внимание на содержание. Звук — череда дискретных значений о звуковом сигнале, видео — череда кадров изображений, текст — череда символов текста. Если мы не будем учитывать контекст, а, например, будем использовать азбуку Морзе для передачи всех трёх видов информации, то если для текста такой способ может оказаться приемлемым, то для звука и видео время, затраченное на передачу например 1 секунды информации, может оказаться слишком долгим — час или даже пара недель.
2. Кодирование текста
От общего описания кодирования перейдём к практической части. Из условностей мы за константу примем то, что будем кодировать данные для персонального компьютера, где за единицу информации приняты — бит и байт. Бит, как атом информации, а байт — как условный блок размером в 8 бит.
Текст в компьютере является частью 256 символов, для каждого отводится один байт и в качестве кода могут быть использованы значения от 0 до 255. Так как данные в ПК представлены в двоичной системе счисления, то один байт (в значении ноль) равен записи 00000000, а 255 как 11111111. Чтение такого представления числа происходит справа налево, то есть один будет записано как 00000001.
Итак, символов английского алфавита 26 для верхнего и 26 для нижнего регистра, 10 цифр. Так же есть знаки препинания и другие символы, но для экспериментов мы будем использовать только прописные буквы (верхний регистр) и пробел.
Тестовая фраза «ЕХАЛ ГРЕКА ЧЕРЕЗ РЕКУ ВИДИТ ГРЕКА В РЕЧКЕ РАК СУНУЛ ГРЕКА РУКУ В РЕКУ РАК ЗА РУКУ ГРЕКУ ЦАП».
2.1 Блочное кодирование
Информация в ПК уже представлена в виде блоков по 8 бит, но мы, зная контекст, попробуем представить её в виде блоков меньшего размера. Для этого нам нужно собрать информацию о представленных символах и, на будущее, сразу подсчитаем частоту использования каждого символа:
Источник
Способы эффективного кодирования информации
Основы передачи дискретных сообщений
Тема 4. Эффективное (статическое) кодирование
Эффективное кодирование – это процедуры направленные на устранение избыточности.
Основная задача эффективного кодирования – обеспечить, в среднем, минимальное число двоичных элементов на передачу сообщения источника. В этом случае, при заданной скорости модуляции обеспечивается передача максимального числа сообщений, а значит максимальная скорости передачи информации.
Пусть имеется источник дискретных сообщений, алфавит которого 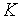 .
.
При кодировании сообщений данного источника двоичным, равномерным кодом, потребуется 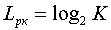 двоичных элементов на кодирование каждого сообщения.
двоичных элементов на кодирование каждого сообщения.
Если вероятности 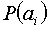 появления всех сообщений источника равны, то энтропия источника (или среднее количество информации в одном сообщении) максимальна и равна
появления всех сообщений источника равны, то энтропия источника (или среднее количество информации в одном сообщении) максимальна и равна 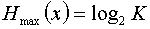 .
.
В данном случае каждое сообщение источника имеет информационную емкость 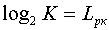 бит, и очевидно, что для его кодирования (перевозки) требуется двоичная комбинация не менее
бит, и очевидно, что для его кодирования (перевозки) требуется двоичная комбинация не менее 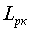 элементов. Каждый двоичный элемент, в этом случае, будет переносить 1 бит информации.
элементов. Каждый двоичный элемент, в этом случае, будет переносить 1 бит информации.
Если при том же объеме алфавита сообщения не равновероятны, то, как известно, энтропия источника будет меньше
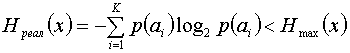 .
.
Если и в этом случае использовать для перевозки сообщения 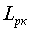 -разрядные кодовые комбинации, то на каждый двоичный элемент кодовой комбинации будет приходиться меньше чем 1 бит.
-разрядные кодовые комбинации, то на каждый двоичный элемент кодовой комбинации будет приходиться меньше чем 1 бит.
Появляется избыточность, которая может быть определена по следующей формуле
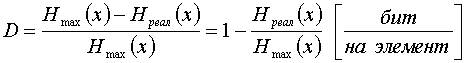 .
.
Среднее количество информации, приходящееся на один двоичный элемент комбинации при кодировании равномерным кодом
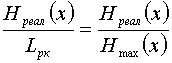 .
.
Для кодирования 32 букв русского алфавита, при условии равновероятности, нужна 5 разрядная кодовая комбинация. При учете ВСЕХ статистических связей реальная энтропия составляет около 1,5 бит на букву. Нетрудно показать, что избыточность в данном случае составит
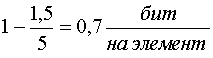 ,
,
Если средняя загрузка единичного элемента так мала, встает вопрос, нельзя ли уменьшить среднее количество элементов необходимых для переноса одного сообщения и как наиболее эффективно это сделать?
Для решения этой задачи используются неравномерные коды.
При этом, для передачи сообщения, содержащего большее количество информации, выбирают более длинную кодовую комбинацию, а для передачи сообщения с малым объемом информации используют короткие кодовые комбинации.
Учитывая, что объем информации, содержащейся в сообщении, определяется вероятностью появления
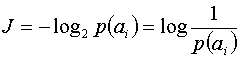 , можно перефразировать данное высказывание.
, можно перефразировать данное высказывание.
Для сообщения, имеющего высокую вероятность появления, выбирается более короткая комбинация и наоборот, редко встречающееся сообщение кодируется длинной комбинацией.
Т.о. на одно сообщение будет затрачено в среднем меньшее единичных элементов 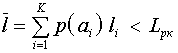 , чем при равномерном.
, чем при равномерном.
Если скорость телеграфирования постоянна, то на передачу одного сообщения будет затрачено в среднем меньше времени
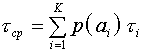
А значит, при той же скорости телеграфирования будет передаваться большее число сообщений в единицу времени, чем при равномерном кодировании, т.е. обеспечивается большая скорость передачи информации.
Каково же в среднем минимальное количество единичных элементов требуется для передачи сообщений данного источника?
Ответ на этот вопрос дал Шеннон.
Шеннон показал, что
1. Нельзя закодировать сообщение двоичным кодом так, что бы средняя длина кодового слова 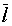 была численно меньше величины энтропии источника сообщений
была численно меньше величины энтропии источника сообщений 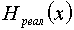 .
. 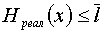 , где
, где 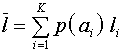 .
.
2. Существует способ кодирования, при котором средняя длина кодового слова немногим отличается от энтропии источника
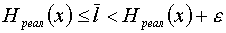
Остается выбрать подходящий способ кодирования.
Эффективность применения оптимальных неравномерных кодов может быть оценена:
Коэффициентом статистического сжатия, который характеризует уменьшение числа двоичных элементов на сообщение, при применении методов эффективного кодирования в сравнении с равномерным 
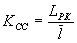 . Учитывая, что
. Учитывая, что 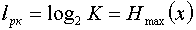 , можно записать
, можно записать 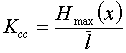 . Ксс лежит в пределах от 1 — при равномерном коде до
. Ксс лежит в пределах от 1 — при равномерном коде до 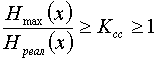 , при наилучшем способе кодирования.
, при наилучшем способе кодирования.
Коэффициент относительной эффективности
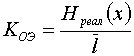 — позволяет сравнить эффективность применения различных методов эффективного кодирования.
— позволяет сравнить эффективность применения различных методов эффективного кодирования.
В неравномерных кодах возникает проблема разделения кодовых комбинаций. Решение данной проблемы обеспечивается применением префиксных кодов.
Префиксным называют код, для которого никакое более короткое слово не является началом другого более длинного слова кода. Префиксные коды всегда однозначно декодируемы.
Веедем понятие кодового дерева для множества кодовых слов.
Наглядное графическое изображение множества кодовых слов можно получить, установив соответствие между сообщениями и концевыми узлами двоичного дерева. Пример двоичного кодового дерева изображен на рисунке. 1.
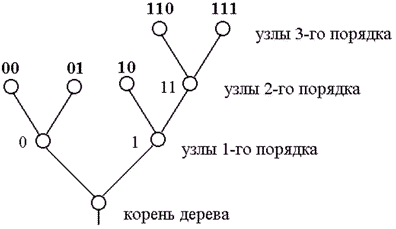
Рисунок 1. Пример двоичного кодового дерева
Две ветви, идущие от корня дерева к узлам первого порядка, соответствуют выбору между “0” и “1” в качестве первого символа кодового слова: левая ветвь соответствует “0”, а правая – “1”. Две ветви, идущие из узлов первого порядка, соответствуют второму символу кодовых слов, левая означает “0”, а правая – “1” и т. д. Ясно, что последовательность символов каждого кодового слова определяет необходимые правила продвижения от корня дерева до концевого узла, соответствующего рассматриваемому сообщению.
Формально кодовые слова могут быть приписаны также промежуточным узлам. Например, промежуточному узлу второго порядка на рис.1 можно приписать кодовое слово 11, которое соответствует первым двум символам кодовых слов, соответствующих концевым узлам, порождаемых этим узлом. Однако кодовые слова, соответствующие промежуточным узлам, не могут быть использованы для представления сообщений, так как в этом случае нарушается требование префиксности кода.
Требование, чтобы только концевые узлы сопоставлялись сообщениям, эквивалентно условию, чтобы ни одно из кодовых слов не совпало с началом (префиксом) более длинного кодового слова.
Любой код, кодовые слова которого соответствуют различным концевым вершинам некоторого двоичного кодового дерева, является префиксным, т. е. однозначно декодируемым.
Одним из часто используемых методов эффективного кодирования является так называемый код Хаффмена.
Пусть сообщения входного алфавита 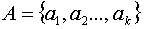 имеют соответственно вероятности их появления
имеют соответственно вероятности их появления 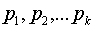 .
.
Тогда алгоритм кодирования Хаффмена состоит в следующем:
1. Сообщения располагаются в столбец в порядке убывания вероятности их появления.
2. Два самых маловероятных сообщения объединяем в одно сообщение 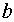 , которое имеет вероятность, равную сумме вероятностей сообщений
, которое имеет вероятность, равную сумме вероятностей сообщений 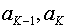 , т. е.
, т. е. 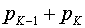 . В результате получим сообщения
. В результате получим сообщения 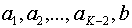 , вероятности которых
, вероятности которых 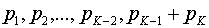 .
.
3. Повторяем шаги 1 и 2 до тех пор, пока не получим единственное сообщение, вероятность которого равна 1.
4. Проводя линии, объединяющие сообщения и образующие последовательные подмножества, получаем дерево, в котором отдельные сообщения являются концевыми узлами. Соответствующие им кодовые слова можно определить, приписывая правым ветвям объединения символ “1”, а левым — “0”. Впрочем, понятия “правые” и “левые” ветви в данном случае относительны.

На основании полученной таблицы можно построить кодовое дерево
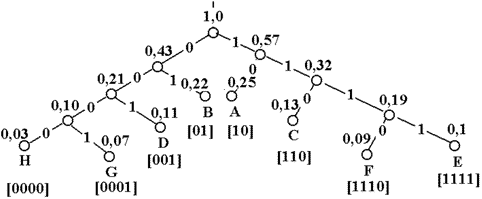
Так как в процессе кодирования сообщениям сопоставляются только концевые узлы, полученный код является префиксным и всегда однозначно декодируем.
При равномерных кодах одиночная ошибка в кодовой комбинации приводит к неправильному декодированию только этой комбинации. Одним из серьёзных недостатков префиксных кодов является появление трека ошибок, т.е. одиночная ошибка в кодовой комбинации, при определенных обстоятельствах, способна привести к неправильному декодированию не только данной, но и нескольких последующих кодовых комбинаций.
Пример на однозначность декодирования и трек ошибок
Пусть передавалась следующая последовательность
При возникновении ошибки в первом двоичном элементе, получим
0 0 0 1 1 1 0 0 0 1
Т.О. ошибка в одном разряде комбинации первого символа привела к неправильному декодированию двух символов. (Трек ошибок).
Источник



