
- ElasticSearch — агрегация данных
- Aggregation module
- Простой пример
- Агрегация во всей красе или что-то посложнее
- Заключение
- Агрегирование данных
- Агрегирование данных
- Агрегаты в БД — зачем, как, а стоит ли?
- Динамический подсчет
- Несколько одновременных агрегатов
- EXPLAIN-оценка count(*)
- Триггер-аккумулятор
- Таблица агрегатов vs MVCC
- Дробление агрегатов
- Таблица изменений + worker
- Агрегация где-то рядом
- Временная агрегация в памяти процесса
- Поток изменений в событиях очереди
- В базе, но не в PostgreSQL
ElasticSearch — агрегация данных

В статье мы рассмотрим, как правильно реализовывать агрегацию данных, зачем это может понадобиться, и сдобрим это кучей рабочих примеров.
Для всех, кому интересно как сделать свои запросы в ES интереснее и посмотреть на обычной поиск с другой стороны, прошу под кат.
В предыдущей статье пользователи разделились поровну между статьёй по более простой теме и по более сложной, поэтому я выбрал не очень сложную тему, но довольно свежую, которая добавилась в ES относительно недавно(v1.0) и несёт довольно интересный функционал.
Aggregation module
Этот модуль пришел в ES на смену Facets, причем в настойчивой форме, Facets теперь считаются устаревшими и будут удалены в ближайшие релизы. Хотя агрегаты и были добавлены в v1.0.0RC1, а сейчас уже >1.2, я все же не рекомендую использовать Facets.
Зачем же понадобилось изменять рабочий инструмент?
Наверное, главной фишкой агрегатов является их вложенность. Приведу общий синтаксис запроса:
Как видно из структуры, агрегатов может быть сколь угодно много, и у каждого элемента может быть вложенный элемент без ограничений по глубине.
Используя вложенность, мы можем получить очень интересные статистические данные (пример в конце статьи).
Типы агрегатов
Типов агрегатов очень много, но все их можно объединить в 2 главных типа:
— Bucketing (Обобщение)
Для простоты понимания, это можно сравнить со всем знакомым инструментов «GROUP BY». Конечно, это довольно упрощенное сравнение, но принцип работы схож. Этот тип на основе фильтров обобщает документы, по какому-то определённому признаку, хороший пример это terms aggregation.
— Metric (Метрические)
Это агрегаты, которые высчитывают какие либо значение по определенному набору документов. Например sum aggregation
Думаю, для начало теории хватит, всем, кого интересует более фундаментальная информация по этому модулю, могут ознакомится с ней по этой ссылке.
Простой пример
Дамп наглым образом взят из этой прекрасной статьи
Давайте сгруппируем спортсменов по их виду спорта и узнаем сколько их в каждом спорте:
Тут мы используем агрегат «terms», который группирует документа по полю «sport».
«size» : 0 (0 заменяется на Integer.MAX_VALUE автоматически) говорит о том, что нам нужные все документы без исключения, в нашем случае не важна скорость, но надо учитывать, что более точный результат требует больше времени.
Отлично, бейсболистов больше всего.
Давайте отсортируем спортсменов по среднему значению их рейтинга, от большего к меньшему:
Тут отлично видно, что такое вложенный агрегат и как он может помочь нам выбрать документы максимально гибко.
Сначала мы указываем, что нужно сгруппировать спортсменов по имени, потом отсортировать по «rating_avg», который высчитывается в под агрегате «avg», по полю «rating». Заметьте, как элегантно ES работает с массивами ( «rating» : [10, 9] ) и с легкостью высчитывает среднее значение.
Еще одна прекрасная возможность агрегатов это использование «script» . Например:
Начиная с версии 1.2.0 выполнение скриптов по умолчанию отключено. Вы можете его включить, при условии что у пользователей нет прямого доступа к ES (Надеюсь, что это так, иначе советую вам немедленно закрыть этот доступ ради безопасности ваших данных).
Агрегация во всей красе или что-то посложнее
Давайте найдём всех спортсменов, которые находятся в радиусе 20 миль от точки «46.12,-68.55»
Сгруппируем их по виду спорта и выведем подробную статистику по рейтингу спортсменов в этом виде спорта.
Звучит неплохо, а вот и пример.
Заключение
Надеюсь, я смог донести общие возможности этого прекрасного модуля. Всем, кого это тема заинтересовала, я советую ознакомиться со всем списком фильтров по этой ссылке.
Рад любым полезным замечаниям и дополнениям по теме.
Так же можно прочитать мою предыдущую статью по ES — ElasticSearch и поиск наоборот. Percolate API
И принять участие в голосование внизу статьи.
Источник
Агрегирование данных
8.6. Агрегирование данных
На базе значений одной или нескольких группирующих переменных (переменных разбиения) можно объединить наблюдения в группы (агрегировать) и создать новый файл данных, содержащий по одному наблюдению для каждой группы разбиения. Для этого SPSS предоставляет большое количество функций агрегирования.
В сельскохозяйственном исследовании рассматривалось содержание свиней в двух различных типах свинарников. При этом в каждом из двух свинарников осуществлялся мониторинг поведения восьми свиней в течение двадцатидневного периода. На протяжении этого периода фиксировалась длительность определенных действий животных (то есть сколько времени свиньи рылись, ели, чесали голову и туловище). Данные хранятся в файле schwein.sav, содержащем следующие переменные:
Тип свинарника (1 или 2)
Порядковый номер свиньи (от 1 до 8)
Номер дня (от 1 до 20)
Длительность рытья (в секундах)
Длительность кормежки (в секундах)
Длительность чесания (в секундах)
Следует выяснить, значительно ли различается по длительности эти три действия в свинарниках обоих типов, для чего необходимо применить соответствующий статистический текст, например, тест Стьюдента (см. главу 13).
В каждой из двух выборок для каждого из трех действий имеется по 8 + 20=160 измерений. Однако выполнение статистического тест на основе этих данных будет не совсем корректно, так как они относятся к восьми особям, для каждой из которых было проведено по двадцать измерений.
Поэтому мы просуммируем длительности для каждой отдельной свиньи и для каждого отдельного действия. Затем полученные наборы сумм мы сравним при помощи теста Стьюдента. Это типичный пример агрегирования данных.
Загрузите файл schwein.sav.
Выберите в меню команды Data (Данные) Aggregate. (Агрегировать)
Откроется диалоговое окно Aggregate Data (Агрегировать данные).
В качестве переменных разбиения перенесите переменные stall и nr в поле Break Variable(s), а в качестве переменных агрегирования (Aggregate Variable(s)) выберите wuehlen, fressen и massage. Диалоговое окно приобретет вид, показанный на рис. 8.8.
Будут показаны три новые переменные wuehle_l, fresse_l и massag_l, имена которых состоят из первых шести букв имен соответствующих переменных агрегирования и комбинации символов _1. По умолчанию в качестве функции агрегирования принято среднее значение. Мы должны выбрать вместо него сумму.
Для этого щелкните на первой переменной, а затем на кнопке Funktion. (Функция). Откроется диалоговое окно Aggregate Data: Aggregate Function (Агрегировать данные: Функция агрегирования) (см. рис. 8.9).
Можно выбрать одну из шестнадцати функций агрегирования, имена которых не требуют особых пояснений.
Выберите пункт Sum of values (Сумма значений) и щелчком на кнопке Continue вернитесь в первое диалоговое окно.
Выполните те же действия для двух других переменных агрегирования. Агрегированные данные будут сохранены в новом файле.
Щелкните на кнопке File. и выберите для нового файла имя pigaggr.sav.
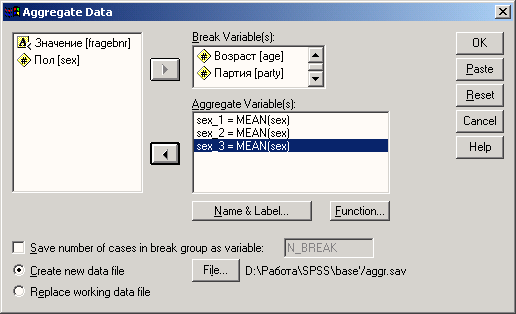
Рис. 8.8: Диалоговое окно Aggregate Data
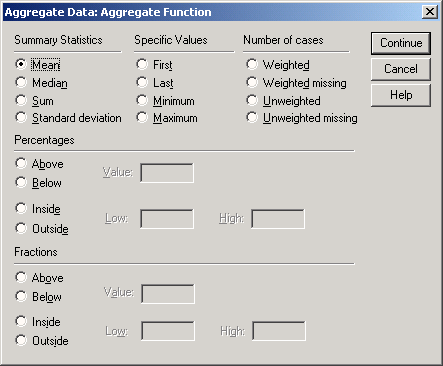
Рис. 8.9: Диалоговое окно Aggregate Data: Aggregate Function
После щелчка на кнопке Отбудет создан новый файл, содержащий 2 х 8=16 наблюдений и переменные stall, nr, wuehle_l, fresse_l и massag_l.
Загрузите этот файл и просмотрите его содержимое в редакторе данных.
Как описано в разделе 13.1, проведите тест Стьюдента для независимых выборок с группирующей переменной stall и тестируемыми переменными fresse_l, massag_l и wuehle_l. Вы получите следующий результат:
Group Statistics (Статистика группы)
Mean (Среднее значение)
Std. Deviation (Стандартное отклонение)
Std. Error Mean (Стандартная ошибка среднего значения)
Источник
Агрегирование данных




![]()
![]()
Агрегирование данных состоит в формировании промежуточных итогов, а также создании сводных и консолидированных таблиц.[14] )
Агрегирование данных выполняется в тех таблицах, в которых имеются поля с повторяющимися по смыслу значениями. Наиболее типичными задачами подобного типа являются задачи получения различного вида статистических итогов. Поясним подробнее назначение каждой из отмеченных процедур.
· Промежуточные итоги. Эта опция позволят сформировать промежуточные итоговые результаты определенного вида (сумма, среднее значение, максимум, минимум, количество значащих записей и т.д.) для выделенного ряда данных (группы записей). При формировании промежуточных итогов требуется предварительно произвести сортировку таблицы по полям группировки записей. К полученным промежуточным итогам можно также добавить новые итоги с сохранением предыдущих итогов.
· Сводные таблицы. Этот инструмент табличного процессора обеспечивает формирование сводной (агрегированной) информации и представление табличных данных в структурированном виде (в определенной внешней форме с упорядочением местоположения фрагментов), а также построение связанной со сводной таблицей сводной диаграммы. Распределение информации в сводной таблице можно задать, указывая какие поля и элементы должны в ней содержаться. Поле — это некоторая общая категория (поименованный столбец), а элемент— это отдельное значение, содержащееся внутри некоторой категории значений. Источником данных для сводной таблицы может быть электронная таблица, данные из внешних баз и т.д. Помимо «базовых» полей из источников данных, сводная таблица допускает формирование вычисляемых полей в области данных, а также вычисляемых элементов для полей группировки. Элементы полей группирования далее могут объединяться в группы, для которых можно указать тип итоговой функции.
Сводная таблица— это средство только для отображения информации и данные, расположенные в теле сводной таблицы, нельзя изменить. Чтобы малейшие изменения данных в источниках информации оперативно отражалисьв сводной таблице как в ее ячейках, напрямую связанных с источниками данных, так и ячейках, отображающих итоговые расчеты, необходимо установить автоматический режим обновления сводной таблицы.
· Консолидация данных. Это особый способ вычисления итогов для диапазона ячеек. Консолидируемые данные могут находится на одном и том же или нескольких листах рабочей книги, а также на листах нескольких разных рабочих книг. При консолидации доступны все типичные функции статистических итогов (сумма, среднее значение, максимум, минимум и т.п.). Результат консолидации записывается на лист рабочей книги, причем на одном и том же листе могут быть записаны несколько результатов консолидации с одними и теми же исходными диапазонами ячеек с данными, но с разными итоговыми функциями. Однако, если исходные диапазоны ячеек отличаются, результаты консолидации должны располагаться на разных листах. Различают следующие виды консолидации:
· Консолидация по расположению ячеек— состав и порядок следования консолидируемых данных во всех диапазонах постоянный, т.е. данных исходных областей находятся в одном и том же месте и размещены в одном и том же порядке. Этот способ используется для консолидации данных нескольких рабочих листов, созданных на основе одного шаблона.
· Консолидация по категориям — когда данные исходных областей не упорядочены, но имеют одни и те же заголовки столбцов и строк. Этот способ применяется при консолидации данных рабочих листов, имеющих разную структуру, но одинаковые заголовки.
· Консолидация с помощью трехмерных ссылок — исходные области располагаются на любом листе, в любой книге, на других открытых листах или книгах, а также зачастую на листах других табличных процессоров. Этот способ является наиболее предпочтительным, т.к. он снимает ограничения на расположение данных в исходных областях.
После создания консолидированной итоговой таблицы можно добавлять, удалять или изменять исходные области данных. Кроме этого, можно создать связи итоговой таблицы с исходными данными, с тем, чтобы данные области назначения итоговой таблицы автоматически обновлялись при изменении данных в исходных областях.
Источник
Агрегаты в БД — зачем, как, а стоит ли?
С течением жизни приложения в его БД накапливается все больше данных. Десктопное оно, SaaS или даже мобильное — неважно, в современном мире почти каждый что-то хранит «у себя».
Если это какая-то локальная утилита — не страшно, само ее существование у пользователя достаточно ограничено. Но если это что-то вроде нашего СБИС, который накапливает и помогает анализировать операции за все время существования бизнеса, то, по мере его роста, не только операций становится больше, но и понимания, какие именно сводные отчеты помогают в оперативном управлении.
Вот про то, как сделать такие отчеты быстрыми, какие бывают способы их реализации и встречаются «грабли» на этом пути, сегодня и поговорим.
Динамический подсчет
Самая простая реализация — просто берем и считаем count(*)/sum/min/max/. прямо по исходному набору данных. Чувствует себя достаточно неплохо, если количество агрегируемых записей не превышает нескольких сотен и будет эффективен за счет малой вычислительной нагрузки и нахождения в кэше всего, что хочется считать.

Несколько одновременных агрегатов
Первая оптимизация, которая может помочь в ускорении такого запроса — это вычисление сразу нескольких агрегатов за единственный проход данных.
EXPLAIN-оценка count(*)
Этот способ актуален для «длинных» отчетов, в которых очень хочется отобразить «пейджинг» — и обязательно с общим счетчиком «записей всего». И это — классический антипаттерн, поскольку из-за использования MVCC, PostgreSQL вынужден все равно вычитывать и считать отдельно все эти записи, а это медленно.
К счастью, для любителей странного есть «хак» для вероятностной оценки count() на основе вывода EXPLAIN .
Триггер-аккумулятор
Следующий вариант уже требует изменений в структуре БД — заводим отдельную от исходных данных таблицу, в которой будут жить агрегаты, а на таблицу(ы) с «первичкой» вешаем триггер.
В самом простом виде это может выглядеть примерно так:
Теперь нам достаточно прочитать всего лишь одну запись из таблицы агрегатов, чтобы получить значение нужного счетчика.
Таблица агрегатов vs MVCC
Но состояние такой записи достаточно часто меняется, поэтому из-за MVCC в этой таблице начинает постепенно накапливаться «мусор» (dead tuples), который уже ни один запрос как бы не может увидеть, но движок PostgreSQL все равно вынужден их фильтровать. Это может вызывать существенную деградацию производительности и неконтролируемый рост объема таблицы.
Чтобы такой мусор вычищался, а место переиспользовалось, в PostgreSQL существует процесс autovacuum’а. Но иногда скорость изменений данных превышает дефолтные настройки, тогда стоит базе «помочь»:
Эта настройка задает условия, при которых процесс очистки вообще возьмется за нашу таблицу. А с какой частотой он будет это делать, определяет параметр autovacuum_naptime , с помощью которого мы уменьшим интервал между сканированиями:
Будьте осторожны! В базах с большим количеством таблиц/секций, сама инициализация процесса autovacuum/autoanalyze и определение таблиц для обработки могут потреблять достаточно существенные ресурсы.
Дробление агрегатов
А что если изменения будут идти очень-очень часто и в несколько потоков? Такой триггер из-за блокировок при обновлении единственной «целевой» записи превратит нашу работу в «однопоточную»:
Достаточно очевидное решение — если упираемся в одну запись, давайте сделаем их несколько, а при выводе будем суммировать — все равно их будет существенно меньше, чем исходных данных.
Таким образом, наши шансы наткнуться на блокировку снижаются кратно, пропорционально количеству «долек».
Таблица изменений + worker
Но и такой вариант неидеален — «раздробленные» агрегаты не дают возможность «быстро и дешево», за единственный Index Scan , получить «рейтинговые» отчеты вроде тех, которые описаны в статье «SQL HowTo: рейтинг-за-интервал».
Поэтому давайте оставим все-таки единственную запись агрегата, а все «свежее» будем писать в таблицу изменений, и периодически (по событию или таймеру) будем «набегать» на эту таблицу, массово обрабатывать и удалять все изменения, и накатывать изменения на агрегаты.
Прелесть метода — в «однопоточности». То есть агрегат обновляется только одним этим нашим процессом, и блокировкам взяться неоткуда — достаточно обеспечить единственность активного worker’а. Этого легко добиться с помощью pg_try_advisory_lock .
С различными способами использования рекомендательных блокировок можно познакомиться в статье «Фантастические advisory locks, и где они обитают».
В качестве таблицы изменений, впрочем, может выступать и сама таблица исходных данных — лишь бы был способ (индекс/признак) быстро вычленить все необработанные записи.
При всех недостатках (+2 таблицы и реализация «вне БД»), метод позволяет в любой момент актуальные значения получить из БД — то есть транзакционная целостность при нас.
Примерно так у нас в СБИС живет счетчик остатков складской карточки, расчет себестоимости и сводные сальдо и обороты.
В этом случае обрабатывающий запрос может выглядеть как-то так:
При этом еще необработанные записи между итерациями worker’а доступны в diff-таблице, откуда мы их можем (если хотим, конечно) прочитать и добавить к сохраненному значению агрегата.
Фактически, мы получили длинную таблицу-очередь, что чревато проблемами из-за MVCC — значит, стоит брать ее обслуживание в свои руки и применять методики, описанные в «DBA: когда пасует VACUUM — чистим таблицу вручную».
Агрегация где-то рядом
Но считать (да и хранить) агрегаты внутри PostgreSQL — может не всегда оказаться эффективно. Поэтому, если требования проекта позволяют, можно посмотреть на альтернативные варианты.
Временная агрегация в памяти процесса
Если ваш процесс относится к долгоживущим, то нет необходимости сбрасывать в БД прямо уж каждое изменение, если вы готовы насколько-то отойти от полной непротиворечивости данных агрегата в каждый момент времени. Тогда можно вести счетчики в памяти процесса, а в БД отправлять по таймеру.
Поток изменений в событиях очереди
Микс из предыдущих двух вариантов. При изменении данных вы кидаете сообщение в очередь NOTIFY /PgQ/RabbitMQ/Kafka/. а на принимающей стороне worker получает эти события «пачками», и пушит в БД.
В базе, но не в PostgreSQL
PostgreSQL «честно» соблюдает ACID. Но ведь есть множество других БД, в которых с этим делом существенно проще: Redis, Tarantool, ClickHouse, . — выбирайте под свои задачи.
Примерно так у нас живет история загрузки (Redis) и статистика работы облака (ClickHouse).
Мини-серия «Агрегаты в БД»:
Источник



