
- Способ оцифровки звуковой информации
- Оцифровка звука: как это работает
- Немного школьной физики
- Делим звук на отрезки
- Переводим в цифру
- Как теперь воспроизвести звук
- Что дальше
- Кодирование звуковой информации 🎤 Оцифровка звука
- Основные определения
- Представление и кодирование звуковой информации в компьютере
- Расчет объема аудио файла
- Форматы аудио
- Заключение
Способ оцифровки звуковой информации
2.2. Оцифровка звука
Оцифровка − процесс преобразования аналогового сигнала в цифровой.
Как известно, звуковая волна представляет собой сложную функцию зависимости амплитуды волны от времени. Так как же нам записать и сохранить в памяти компьютера такую функцию? Например, такие звуковые волны, как на рис. 2.3-2.4, невозможно описать с помощью аналитических функций, но при этом мы можем в каждый момент времени измерить значение амплитуды сигнала и записать в виде чисел, и таким образом запомнить эти числа. Однако значения амплитуды сигнала мы не можем записывать с бесконечной точностью, и поэтому вынуждены их округлять. Таким образом, оцифровка сигнала включает в себя два процесса − процесс дискретизации, когда мы измеряем величину сигнала на определённых дискретных промежутках, и квантования , когда эти значения ограничиваются определённым набором уровней (рис. 2.5).


Дискретизация и квантование могут выполняться в произвольном порядке. Эти процессы выполняются специальными устройствами, которые обобщенно называются аналого-цифровыми преобразователями (АЦП).

Рис. 2.5. Оцифровка
Процесс дискретизации − это процесс получения значений величин преобразуемого сигнала в определённые промежутки времени (рис. 2.5). Как видно из рис. 2.5-2.6, в процессе оцифровки часть информации теряется. Если частота дискретизации слишком мала, тогда в процессе оцифровки некоторые детали будут утрачены. Например, при дискретизации сигнала (рис. 2.6) с недостаточной частотой мы попросту пропустим пик между точками 2 и 3, а при восстановлении аналогового сигнала по полученным дискретным значениям сигнал будет сильно отличаться от оригинала. Так как же выбрать правильную частоту дискретизации в процессе оцифровки?

Рис. 2.6. Дискретизация с недостаточной частотой
Согласно теореме о дискретном представлении [10], если самая высокая частота из частот компонентов сигнала равна fh, то сигнал можно будет точно восстановить в том случае, если его дискретизация была выполнена с частотой, превышающей 2fh. Это граничное значение известно под названием частота Найквиста.
Доказательство теоремы можно очень просто проиллюстрировать. Предположим, имеется круглый диск со стрелкой, которая вращается по часовой стрелке со скоростью n оборотов в секунду. Предположим также, что это вращение оцифровывается с разной частотой дискретизации 4n, n, 4/3n, 2n раз в секунду.
Посмотрев ролики (рис. 2.7), можно увидеть, что при частоте дискретизации 4n, которая больше частоты Найквиста, диск вращается по часовой стрелке, как нам и надо. При дискретизации с частотой 4n/3 кажется, что стрелка вращается против часовой стрелки со скоростью n/3. А если выполнять дискретизацию движения нашего диска с частотой, равной 2n, то можно не определить, в какую сторону вращается стрелка, так как она будет находиться либо вверху, либо внизу.
Вывод: частота дискретизации должна превышать частоту Найквиста.
Рис. 2.7. Flash-ролик вращающейся стрелки, дискретизированной с разной частотой n (для просмотра и остановки щелкните на кнопку «пуск»)
Источник
Оцифровка звука: как это работает
Как переводят голос в бездушную цифру.
Начинаем рассказывать, как работают привычные технологии: компьютерный звук, видео, MP3, вещание и стриминги, всевозможные алгоритмы и всё подобное.
👍 У этой статьи нет никакой практической ценности, она просто для удовольствия. Иногда можно себя побаловать 🙂
Немного школьной физики
Звук — это колебания воздуха. Как волны на воде, только в воздухе. Воздух давит нам на уши, а в ушах есть чувствительные части, которые тонко чувствуют колебания воздуха. Эти колебания люди воспринимают как звук. В открытом космосе звуков нет, потому что там нет воздуха. И людей.
Частота. Чем быстрее колебания, тем тоньше воспринимаемый нами звук. Человек воспринимает колебания от 20 раз в секунду до примерно 20 тысяч раз в секунду. По-другому это называется частотой колебаний: герцами. То есть диапазон, который мы слышим — от 20 герц до 20 килогерц.
Для сравнения, собаки слышат от 40 герц до 60 килогерц, поэтому собачий свисток не воспринимается людьми, но очень хорошо слышен собакам. Собачий свисток как раз звучит в диапазоне 23–54 КГц.
Амплитуда. Чем сильнее колебания — тем громче, и наоборот. Можно представить, что это высота волн на поверхности пруда: может быть мелкая рябь (тихий звук), а могут быть большие мощные волны.
График. Если мы произнесём фразу «Привет, это журнал „Код“», то с точки зрения волн он будет выглядеть как-то так (очень примерно):
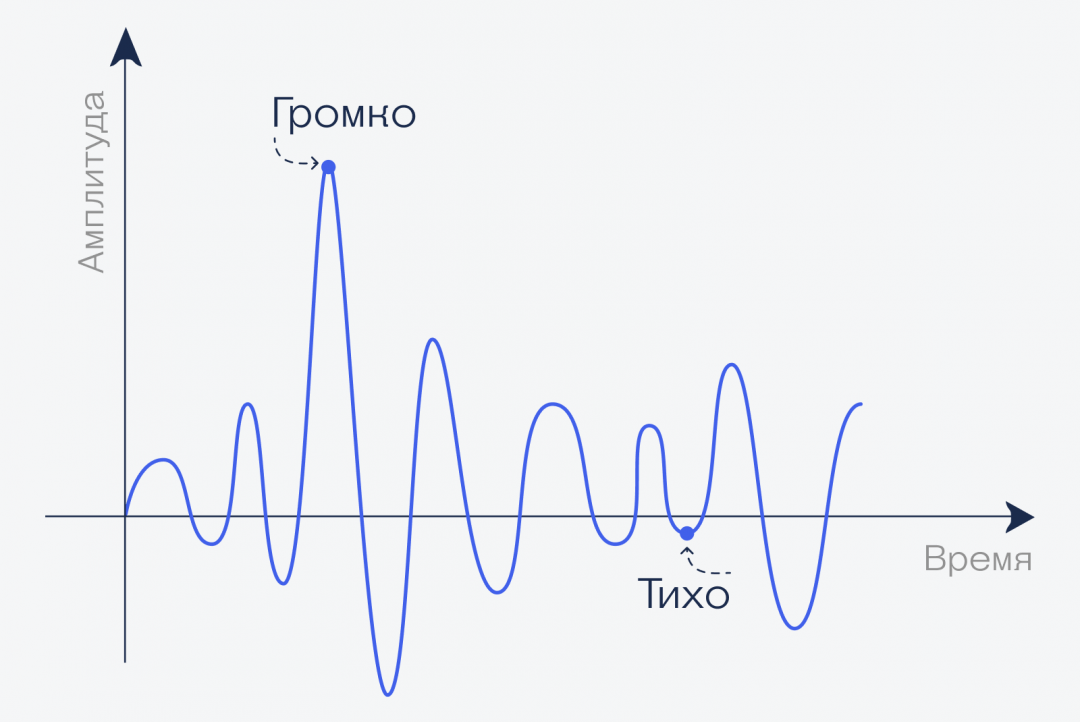
Делим звук на отрезки
Давайте увеличим наш график и посмотрим, что происходит, например, за одну секунду (опять же, очень примерно и упрощённо!):
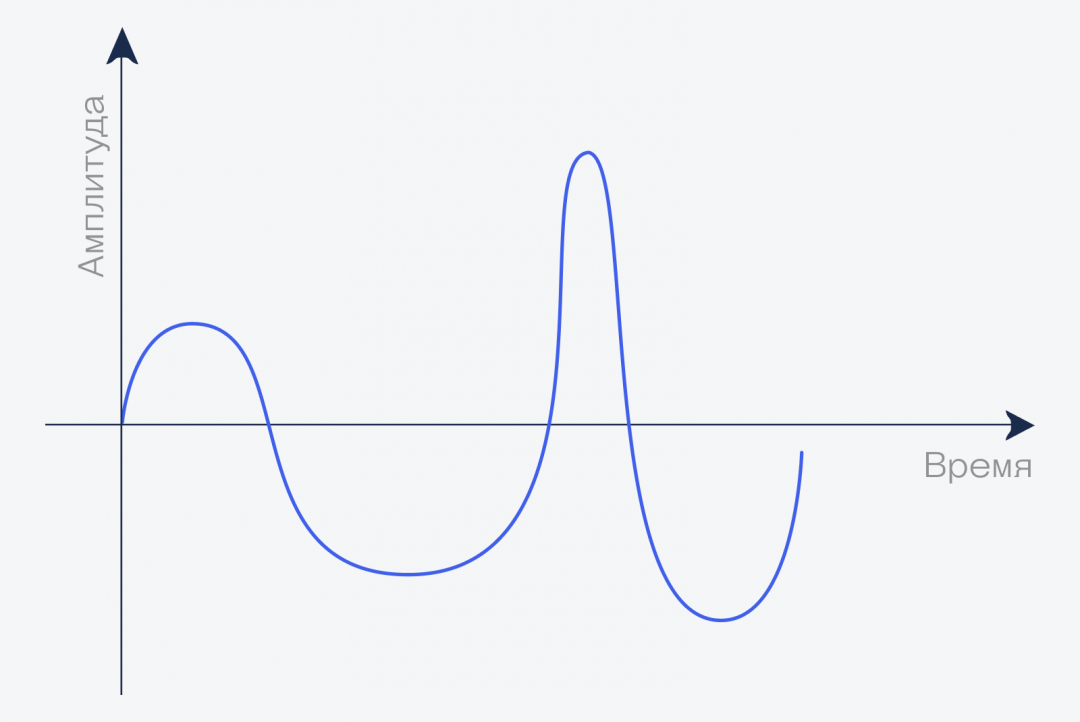 Упрощённо!
Упрощённо!
А теперь сделаем вот что: разделим секунду на 4 части, и для каждой найдём значение амплитуды:
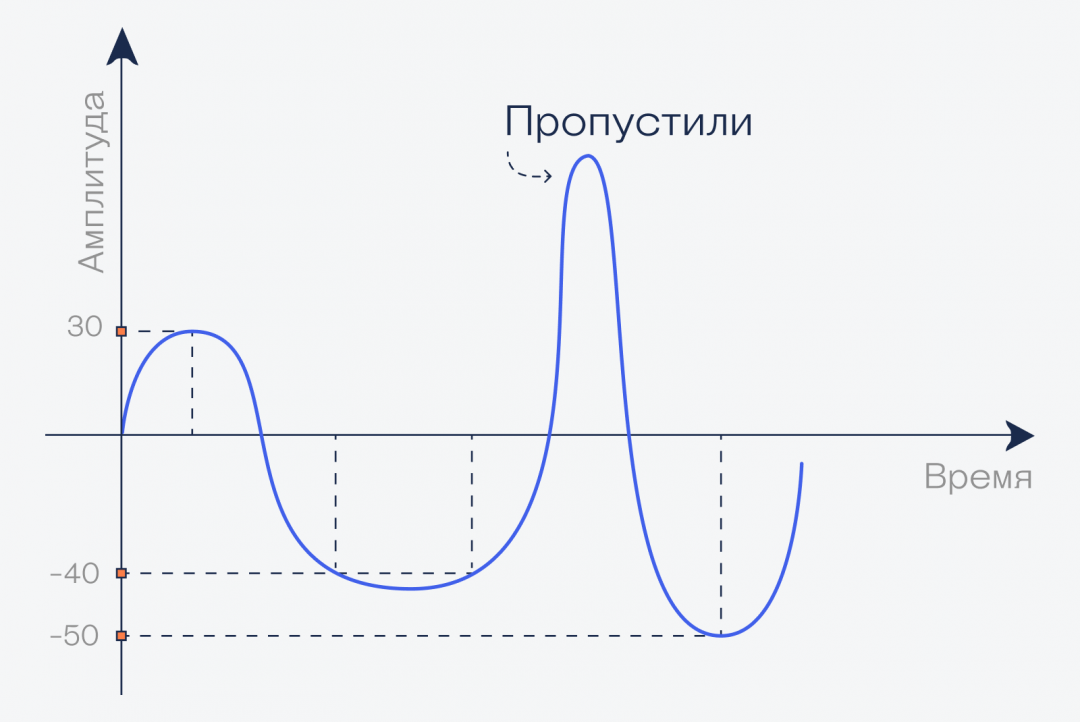 Мы за секунду четыре раза измерили состояние волны. Это называется дискретизацией
Мы за секунду четыре раза измерили состояние волны. Это называется дискретизацией
Мы измерили значение амплитуды в каждой из четырёх точек, получили, условно говоря, четыре числа: +30, −50, −50 и −60. Теоретически, если взять ток и подать эти четыре напряжения на динамик, у нас получится воспроизвести тот же звук. Но есть несколько проблем:
- Из-за того, что мы замерили волну только в четырёх местах, мы пропустили целое колебание. Оно было настолько быстрым, что уместилось между нашими ключевыми точками.
- Опять же, из-за больших отрезков мы получим очень грубый звук по сравнению с оригиналом. Это то же самое, как взять картину с тысячей разных оттенков и нарисовать её тремя цветами, не смешивая их.
Дискретизация с частотой 4 (сколько значений мы измеряем в секунду) — это слишком мало для звука. Чтобы получить более или менее разборчивую речь, нужно секунду делить на 8 тысяч отрезков, а для музыки обычно хватает 41 тысячи.
Увеличим частоту дискретизации: нарежем звук на более мелкие кусочки за ту же единицу времени:
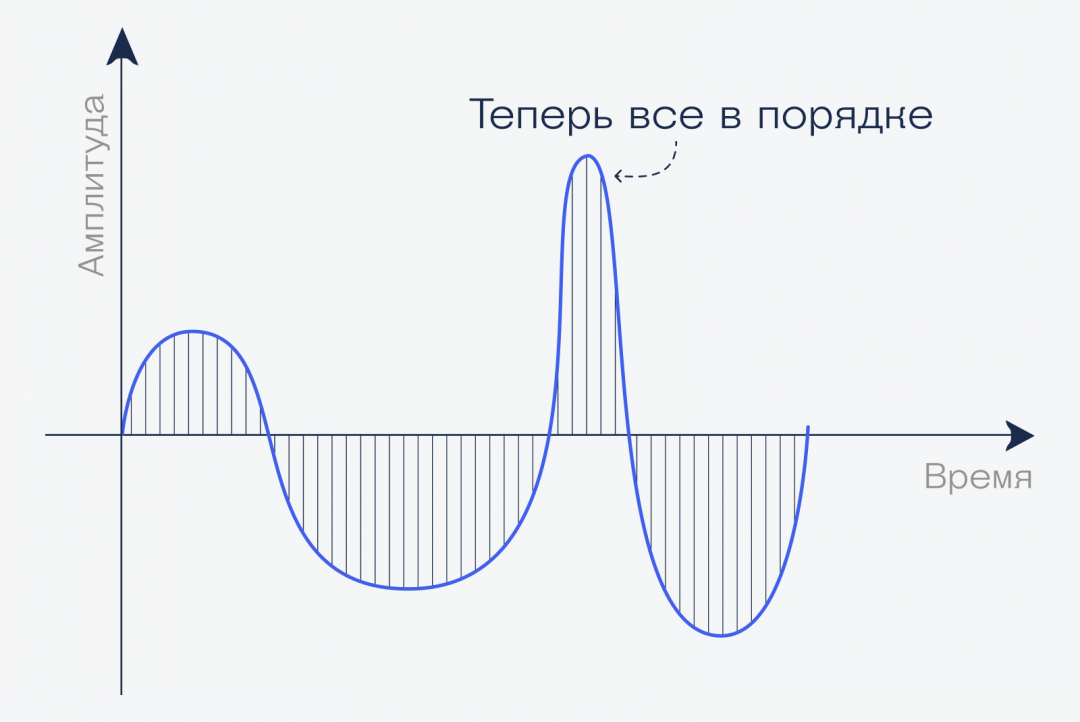 Теперь измерения будут намного точнее, а получившийся звук — естественнее
Теперь измерения будут намного точнее, а получившийся звук — естественнее
Переводим в цифру
После того как мы разбили звук на мелкие отрезки и измерили значение амплитуды для каждого из них, мы можем записать это в виде таблички:
| Время | Амплитуда |
| 0.01 сек. | 5 |
| 0.02 сек. | 7 |
| 0,03 сек | 10 |
| . | . |
| 1 сек | −21 |
Если мы весь звук разбиваем на одинаковые отрезки, то время можно не писать, потому что мы знаем, как оно меняется, достаточно записать в строчку только значения амплитуды:
Чтобы компьютер понимал эти числа, переведём эти числа в двоичную систему счисления. Для простоты будем считать, что одно число занимает ровно один байт памяти, но на самом деле чем больше байт выделяется на число, тем точнее будет измерение и качество звука. После перевода получим такое:
Последнее большое число получилось оттого, что нам нужно хранить и отрицательные значения, поэтому первая единица в байте означает, что это отрицательное число и его нужно считать немного иначе.
Вот эту последовательность компьютер уже может понять и воспроизвести в виде звука.
Как теперь воспроизвести звук
Чтобы что-то зазвучало, нужно сделать следующие шаги:
- Взять колонки или наушники — что угодно, что умеет «толкать воздух», то есть создавать акустические волны. В колонках за это отвечают динамики, к которым подключены специальные мягкие конусы, которые, собственно, и создают колебания воздуха. Та круглая ерунда в колонке — это и есть конус.
- Подать на эти колонки некий ток. От того, насколько мощный этот ток, конус будет двигаться по-разному.
- Чтобы получить этот меняющийся ток, нужен специальный чип под названием ЦАП — цифро-аналоговый преобразователь. Он получает на вход число, а на выходе дает ток. У всех ваших смартфонов и компьютеров есть такие ЦАПы.
- Процессор отправляет цифры из звукового файла в ЦАП.
- ЦАП получает числа и выдаёт меняющееся электричество по этим цифрам.
- Электричество попадает в колонку, передаётся на динамик.
- Динамик из-за электричества начинает двигать конус колонки.
- Конус начинает толкать воздух перед собой, создавая звуковые волны.
- Волны долетают до наших ушей, и мы воспринимаем их как звук.
Что дальше
У такого способа есть одна проблема: файл получается слишком большим, чтобы им было удобно пользоваться. Представьте: 44 тысячи чисел за одну секунду!
Чтобы уменьшить размер файла, придумали два решения: сжатие с потерями и без них. Каждое разберём отдельно, несмотря на то, что у них много общего.
Источник
Кодирование звуковой информации 🎤 Оцифровка звука
Одной из основных задач информатики является представление данных в виде удобном для хранения и передачи. Эти данные могут быть разного типа – звуковые, текстовые, графические и т.д. В этой статье мы расскажем про кодирование звуковой информации. Из этой статьи Вы узнаете основные принципы и определения. Также после прочтения сможете посчитать объем аудио файла. Читайте!
Основные определения
Для того чтобы разобраться в теме надо знать, что представляет собой звуковая информация (звук).
Звук – это непрерывная аналоговая волна, которая распространяется в окружающей среде. В роли среды может выступать воздух, жидкость, твердое тело, электричество и т.д.
Звук, как непрерывную волну, характеризуют две характеристики – частота и амплитуда.
От амплитуды зависит громкость аудио сигнала . Чем выше амплитуда, тем громкость больше.
Частота же характеризует тональность аудиоинформации . Чем больше частота, тем тональность выше. Человеческий слух улавливает волны от 20 Гц до 20 кГц. 1 Гц равен 1 колебанию аудио сигнала в секунду.
Представление и кодирование звуковой информации в компьютере
Для представления и кодирования звука используются специальное оборудование и программы. Рассмотрим весь процесс более подробно.
- Аудиоинформация, поступая из окружающей среды (например, по воздуху), преобразуется в электрический сигнал. Для этого используется такое устройство, как микрофон.
- После этого звук поступает на АЦП (аналого-цифровой преобразователь), где подвергается оцифровке.
- На последнем этапе информация (уже в двоичном виде) кодируется при помощи специальной программы – аудиокодека. На выходе получается файл в специальном формате (например, mp3), который можно хранить, воспроизводить и передавать.

Наибольший интерес представляет процесс оцифровки, также называемым аналого-цифровым преобразованием. В результате него аналоговый сигнал заменяется на цифровой.
Основной принцип аналогово-цифрового преобразования заключается в том, что через равные промежутки времени измеряется амплитуда волны. Также этот процесс называется дискретизация.
Дискретизация – это процесс в результате, которого непрерывная функция представляется в виде дискретной последовательности её значений. Схематично дискретизацию можно представить так:

Дискретизация характеризуется двумя такими величинами, как:
- Частота шага по времени;
- Шаг квантования.
Первая величина отображает, как часто берутся дискреты и измеряется в Герцах (количество измерений за одну секунду). Частота шага по времени находится по теореме Котельникова.
Шаг квантования характеризуется количеством уровней , до которых округляются величины амплитуды волны.
Количество уровней (ступенек) до которых округляются значения сигнала, зависит от аналого-цифрового преобразователя. На данный момент используются 16, 32 и 64 битные устройства.
Количество бит, затрачиваемое для номеров уровней, называется глубиной кодирования звуковой информации.
Глубина кодирования связано с количеством уровней по формуле:
Где i разрядность АЦП в битах.
Чем чаще берутся дискреты за единицу времени и больше глубина кодирования, тем выше качество звуковых данных на выходе и дороже АЦП.
Расчет объема аудио файла
«Вес» аудио файла зависит от качества оцифровки, чтобы его вычислить, необходимо использовать следующую формулу:
- N – длительность звучания в секундах;
- K – разрядность АЦП (глубина кодирования) в битах;
- F – частота взятия дискрет в герцах;
- Z – количество каналов ( 1- моно, 2 — стерео).
Пример: рассчитать объем аудио файла со следующими характеристиками – моно звучание, частота дискретизации 8 кГц, глубина — 8 бит (телефонная связь) и длительностью 60 секунд.
\[V = 60*1*8000*8=3840000 \ бит \]
Форматы аудио
Форматов для хранения аудио много, однако, все они делятся на две большие группы в зависимости от того, какой из методов сжатия используется – LOSELESS или LOSSY.
- LOSELESS – метод сжатия без потерь. Качество звуковой информации остается без изменений, однако за него приходится платить большим объемом компьютерной памяти. Используется для хранения музыки и других данных, где важно качество. Форматы, которые основаны на данном методе сжатия: FLAC, APE, TAC, ALAC и другие. На данный момент зарабатывают все большую популярность в связи с увеличением дискового пространства.
- LOSSY – сжатие с потерями. При таком методе файл сохраняются с искажениями относительно оригинала. В основном эти искажения не воспринимаются человеческим слухом, а также не замечаются при плохом аудио оборудовании. LOSSY позволяет существенно сэкономить дисковое пространство. На данный момент этот метод сжатия является доминирующим.
Форматы кодирования использующие алгоритмы LOSSY:
- MP3 (MPEG-1,2,2.5) – самый популярный аудио формат. Проигрывается на всех аудио и видео системах, по умолчанию поддерживается всеми операционными системами. Искажения заметны на высокоточной дорогостоящей аппаратуре.
- AAC – формат, который разрабатывался и позиционировался, как приемник mp3. Не получил широкого распространения. Преимущества перед mp3: большая гибкость кодирования, возможность использовать до 48 звуковых каналов.
- HE-AAC (High-Efficiency Advanced Audio Coding) – используется в цифровом радио и телевиденье.
Заключение
Вот Вы и узнали про кодирование звуковой информации в компьютере. Знаете, от чего зависит качество, что такое глубина кодирования, а также про основные форматы для хранения аудио. Можете использовать это сообщение для подготовки краткого конспекта. Также на нашем сайте вы можете почитать другие статьи, касающиеся информатике, например про множества или байты и биты.
Источник



