
Способ организации оперативной памяти
22. Способы организации оперативной памяти ЭВМ
Структура модуля памяти определяется способом организации ОП (способ адресации).
Существует 3 разновидности организации памяти:
1) адресная память
2) память со стековой организацией
3) ассоциативная организация ОП
С точки зрения функционального построения, любое ЗУ этого типа представляет собой некоторый массив элементов памяти. Структурные элементы памяти образуют ячейки памяти. Ширина ячеек – ширина выборки из памяти.
1) В адресной памяти, размещение и поиск информации в массиве запоминания, базируется на основе номера (адреса). Массив запоминания элементов содержит N n-разрядных слов, которые пронумерованы (0…N-1). Электронное обрамление включает в себя регистры для хранения адреса памяти, регистр информации (само слово), схемы адресной выборки (адресации), разрядные усилители для чтения и записи.
Массив запоминания (ЗМ) содержит N n-разрядных слов. Регистр адреса памяти (РАП) + схема адресной выборки + усилитель считывания + усилитель записи + регистр информации памяти (РИП) + схема управления – электронное обрамление. Цикл работы памяти инициируется сигналом обращения к памяти и операцией (ЗП/ЧТ). При инициировании обращения производится дешифрация адреса схемы адресной выборки. Если задана операция чтения, то активизируется усилитель считывания и информация через усилитель считывания предается в регистр информации памяти. Если память требует динамической регенерации, то после регистра информации памяти все поступает в регистр адреса памяти.
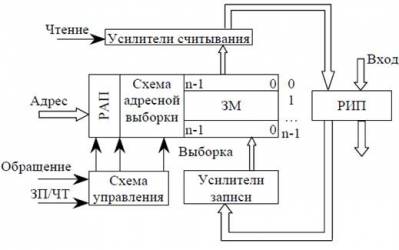
Если происходит чтение, то активизируется усилитель записи, который обеспечивает запись из регистра информации памяти в нужное место памяти.
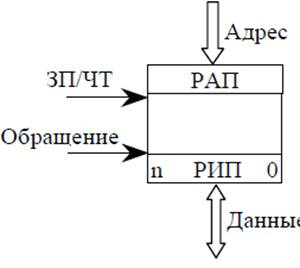
2) Стековая память является безадресной. Ячейки стековой памяти представляют собой
одномерный массив n-разрядных ячеек, в котором соседи связаны друг с другом.

Для операций с памятью доступна только 0 ячейка. Операция с памятью инициируется сигналом обращения.
Каждая операция записи, инициируемая сигналом обращения к памяти, приводит к тому, записанные данные помещаются в 0 ячейку памяти. При этом все ранние записи в памяти слова автоматически сдвигаются на 1 адрес ниже. Операция чтения, инициируемая сигналом обращения, приводит к тому, что на выходе памяти формируется значение слова, находящиеся в 0 ячейке памяти. При этом все имеющиеся слова сдвигаются на одно слово вверх. Счетчик стека нужен только для контроля заполнения и очищения стека. Техническая реализация стековой памяти оказывается сложнее адресной памяти. Стековая память используется достаточно широко (короткий стек из микропрограммирования). Чаще всего применяется не стековая память, а адресное поле, которое функционирует по принципу стека.
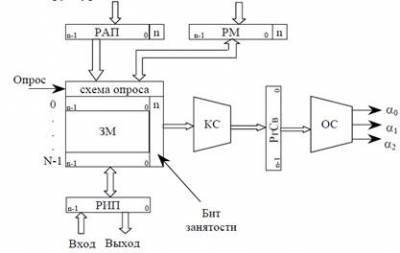
3) ассоциативная память. Исторически последняя. Является представителем многофункциональных запоминающих устройств (возможна обработка данных без процессора в памяти). Отличительная особенность: поиск любой информации в ЗМ производится не по адресу, а по ассоциативным признакам (признакам опроса). Поиск производится одновременно по всем ячейкам ЗМ.
Типовая структура ассоциативной памяти:
РАП — регистр ассоциативного опроса, РМ — регистр маски, РгСв — регистр связи. У каждой ячейки памяти существует бит занятости (1 — есть или 0 — нет слова). Опрос производится на основе двух признаков: признака ассоциативного опроса (в РАП) и маски, которая находится в РМ. Поиск производится по незамаскированным разрядам. Поиск начинается с сигнала опроса (производится опрос всего ЗМ). Результаты опроса фиксируются в РгСв через комбинационную схему (КС). Если некоторые биты замаскированы, они не участвуют в операции. По результатам опроса с помощью формирования считывания (ФС), формируется 3 сигнала.
С помощью них выполняются операции чтения и записи.
если α 0 — результат пустое множество;
если α 1 — слово считывается в РИП; если
если α 2 — процедура чтения может строиться по-разному:
1) считывается первый из элементов ЗМ, удовлетворяющий признаку запроса
2) считывание всех элементов, применяются методы множественного считывания
(последовательное чтение), результат множество слов.
Запись: опрос по полю занятости. Ищется свободная ячейка, если результат α 1 или α 2 — производится запись в первую свободную ячейку. Сложности возникают, когда результатом является α 0.
С точки зрения структуры, любая основная память компьютера может быть построена, как одноблочная, либо как многоблочная (сейчас одноблочная память практически не используется).
Многоблочную память строят из однотипных блоков.
1-й способ: Массив ячеек (плохой вариант)
· Можно делать память переменного объема
· Можно выиграть на времени дешифрации адреса
· Большие затраты на поиск свободного пространства при фрагментации
· Ненадежная (при физическом повреждении полностью выходит из строя)
· Дорогая при производстве (при больших объемах памяти)
2-й способ: Многоблочная
· Можно организовать параллельную работу блоков
· Надежная (при физическом повреждении блока другие блоки продолжают работать)
· Дешевле при производстве (при больших объемах памяти)
· Защита от несанкционированного выхода программы за выделенный блок.
· Затраты на дешифрацию адреса
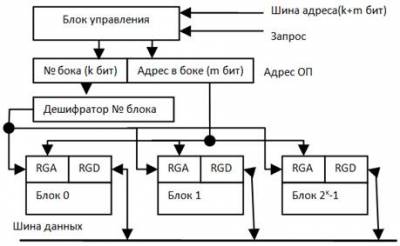
Помимо податливости к наращиванию емкости, блочное построение памяти обладает еще одним достоинством — позволяет сократить время доступа к информации . Это возможно благодаря потенциальному параллелизму, присущему блочной орг анизации.
Большей скорости доступа можно достичь за счет одновременного доступа ко многим банкам памяти. Одна из используемых для этого методик называется расслоением памяти. В ее основе лежит так называемое чередование адресов ( address interleaving ), заключающееся в изменении системы распределения адресов между банками памяти.
У каждого блока есть два регистра: RGA (регистр адреса, который хранит адрес в блоке) и RGD (регистр данных, который хранит либо результат чтения, либо данные для записи). Адрес ячейки запоминается в индивидуальном регистре адреса, и дальнейшие операции по доступу к ячейке в каждом блоке протекают независимо. При большом количестве блоков среднее время доступа к ОП сокращается почти в В раз (В — количество блоков), но при условии, что ячейки, к которым производится последовательное обращение относятся к разным блокам. Если же запросы к одному и тому же блоку следуют друг за другом, каждый следующий запрос должен ожидать завершения обслуживания предыдущего. Такая ситуация называется конфликтом по доступу. При частом возникновении конфликтов по доступу метод становится неэффективным.
Коэффициент расслоения – количество адресов, которое ОП может принять без задержки
Относительный коэффициент расслоения = коэффициент расслоения / количество блоков
Источник
Способ организации оперативной памяти
Необходимо отметить, что все распространенные операционные системы, если для работы нужно больше памяти, чем физически присутствует в компьютере, не прекращают работу, а сбрасывают неиспользуемое в данный момент содержимое памяти в дисковый файл (называемый свопом — swap) и затем по мере необходимости « перегоняют » данные между ОП и свопом. Это гораздо медленнее, чем доступ системы к самой ОП. Поэтому от количества оперативной памяти напрямую зависит скорость системы.
Команды, исполняемые ЭВМ при выполнении программы, равно как и числовые и символьные операнды, хранятся в памяти компьютера. Память состоит из миллионов ячеек, в каждой из которых содержится один бит информации (значения 0 или 1). Биты редко обрабатываются поодиночке, а, как правило, группами фиксированного размера. Для этого память организуется таким образом, что группы по n бит могут записываться и считывается за одну операцию. Группа n бит называется словом, а значение n — длиной слова. Схематически память компьютера можно представить в виде массива слов.
Обычно длина машинного слова компьютеров составляет от 16 до 64 бит. Если длина слова равна 32 битам, в одном слове может храниться 32- разрядное число в дополнительном коде или четыре символа ASCII, занимающих 8 бит каждый. Восемь идущих подряд битов являются байтом. Для представления машинной команды требуется одно или несколько слов.
Отдельные биты, как правило, не адресуются и чаще всего адреса назначаются байтам памяти. Память, в которой каждый байт имеет отдельный адрес, называется памятью с байтовой адресацией. Последовательные байты имеют адреса 0.1, 2 и так далее Таким образом, при использовании слов длиной 32 бита последовательные слова имеют адреса 1.4, 8, . и каждое слово состоит из 4 байт.
Прямой и обратный порядок байтов
Существует два способа адресации байтов в словах:
в прямом порядке. Прямым порядком байтов ( little-endian) называется система адресации, при которой байты адресуются справа налево, так что наименьший адрес имеет самый младший байт слова (расположенный с правого края);
в обратном порядке. Обратным порядком байтов ( big-endian) называется система адресации, при которой байты адресуются слева направо, так что самый старший байт слова (расположенный с левого края) имеет наименьший адрес.
В ПЭВМ на основе 80 x 86 используется прямой порядок, а в ПЭВМ на основе Motorola 68000 — обратный. В обеих этих системах адреса байтов 0.4, 8 и так далее, применяются в качестве адресов последовательных слов памяти в операциях чтения и записи слов.
Расположение слов в памяти
В случае 32- разрядных слов их естественные границы располагаются по адресам 0.4, 8 и так далее При этом считается, что слова выровнены по адресам в памяти. Если говорить в общем, слова считаются выровненными в памяти в том случае, если адрес начала каждого слова кратен количеству байтов в нем. По практическим причинам, связанным с манипулированием Двоично-кодированными адресами, количество байтов в слове обычно является степенью двойки. Поэтому, если длина слова равна 16 бит ( 2 байтам), выровненные слова начинаются по байтовым адресам 0.2, 4, . а если она равна 64 бит ( 23, то есть 8 байтам), то выровненные слова начинаются по байтовым адресам 0.8, 16, .
Не существует причины, по которой слова не могли бы начинаться с произвольных адресов. Такие слова называются не выровненными. Как правило, слова выравниваются по адресам памяти, но иногда этот принцип нарушается.
Обычно число занимает целое слово, поэтому для того чтобы обратиться к нему, нужно указать адрес слова, по которому оно хранится. Точно так же доступ к отдельно хранящемуся в памяти символу осуществляется по адресу содержащего его байта.
Для доступа к памяти необходимы имена или адреса, определяющие расположение данных в памяти. В качестве адресов традиционно используются числа из диапазона от 0 до 2k- 1 со значением к, достаточным для адресации всей памяти компьютера. Все 2k адресов составляют адресное пространство компьютера. Следовательно, память состоит из 2k адресуемых элементов. Например, использование 24- разрядных (как в процессоре 80286) адресов позволяет адресовать 224 (16 777 216) элементов памяти. Обычно это количество адресуемых элементов обозначается как 16 Мбайт ( 1 Мбайт = 220 = 1 048 576 байт, адресное пространство 8086 и 80186). Поскольку у процессоров 80386.80486 Pentium и их аналогов 32- разрядные адреса, им соответствует адресное пространство в 232 байт, или 4 Гбайт.
Адресное пространство ЭВМ графически может быть изображено прямоугольником, одна из сторон которого представляет разрядность адресуемой ячейки (слова) процессора, а другая сторона — весь диапазон доступных адресов для этого же процессора. Диапазон доступных адресов процессора определяется разрядностью шины адреса системной шины. При этом минимальный номер ячейки памяти (адрес) будет равен 0, а максимальный определяется из формулы M = 2n — 1.
Для шестнадцатиразрядной шины это будет 65 535 (64 К).
Иерархическая организация памяти
Компромиссом между производительностью и объемами памяти является решение использовать иерархию запоминающих устройств, то есть применять иерархическую модель памяти.
Применение иерархических систем памяти оправдывает себя вследствие двух важных факторов — принципа локальности обращений и низкого (экономически выгодного) соотношения стоимость/производительность. Принцип локальности обращений состоит в том, что большинство программ обычно не выполняют обращений ко всем своим командам и данным равновероятно, а в каждый момент времени оказывают предпочтение некоторой части своего адресного пространства.
Иерархия памяти обычно состоит из многих уровней, но в каждый момент времени взаимодействуют только два близлежащих уровня. Минимальная единица информации, которая может присутствовать либо отсутствовать в двухуровневой иерархии, называется блоком или строкой.
Успешное или не успешное обращение к более высокому уровню называют соответственно попаданием ( hit) или промахом ( miss). Попадание — есть обращение к объекту в памяти, который найден на более высоком уровне, в то время как промах означает, что он не найден на этом уровне.
Доля попаданий ( hit r а t е) — доля обращений к данным, найденным на более высоком уровне. Доля промахов ( miss rate) — это доля обращений к данным, которые не найдены на более высоком уровне.
Время обращения при попадании ( hit time) есть время обращения к более высокому уровню иерархии, которое включает в себя, в частности, и время, необходимое для определения того, является ли обращение попаданием или промахом.
Потери на промах ( miss ре n а lt у) есть время для замещения блока в более высоком уровне на блок из более низкого уровня плюс время для пересылки этого блока в требуемое устройство (обычно в процессор).
Потери на промах далее включают в себя два компонента:
время доступа ( access time) — время обращения к первому слову блока при промахе;
время пересылки ( transfer time) — дополнительное время для пересылки оставшихся слов блока. Время доступа связано с задержкой памяти более низкого уровня, а время пересылки — с полосой пропускания канала между устройствами памяти двух смежных уровней.
Кэш-память или cache memory — компонент иерархической памяти — представляет собой буферное ЗУ, работающее со скоростью, обеспечивающей функционирование ЦП без режимов ожидания.
Необходимость создания кэш-памяти возникла потому, что появились процессоры с высоким быстродействием. Между тем для выполнения сложных прикладных процессов нужна большая память. Использование же большой сверхскоростной памяти экономически невыгодно. Поэтому между ОП и процессором стали устанавливать меньшую по размерам высокоскоростную буферную память, или кэш-память. В дальнейшем она была разделена на два уровня — встроенная в процессор ( on-die) и внешняя ( on-motherboard).
Иерархия оперативной памяти
Стратегии управления иерархической памятью
При построении систем с иерархической памятью целью является получение максимальной производительности подсистемы памяти при ее минимальной стоимости. Эффективность той или иной системы кэш-памяти зависит от стратегии управления памятью. Стратегия управления памятью включает: метод отображения основной памяти в кэше; алгоритм взаимодействия между медленной основной и быстрой кэш-памятью; стратегии замещения информации в кэше.
Отображение памяти на кэш
Существует три основных способа размещения блоков (строк) основной памяти в кэше:
кэш-память с прямым отображением ( direct-mapped cache);
полностью ассоциативная кэш-память ( fully associative cache).
частично ассоциативная (или множественно ассоциативная, partial associative, set-associative cache) кэш-память;
Память с прямым отображением. В этом случае каждый блок основной памяти имеет только одно фиксированное место, на котором он может появиться в кэш-памяти. Все блоки основной памяти, имеющие одинаковые младшие разряды в своем адресе, попадают в один блок кэш-памяти. При таком подходе справедливо соотношение:
( Адрес блока кэш-памяти) = ( Адрес блока основной памяти) mod ( Число блоков в кэш-памяти).
Этот тип памяти наиболее прост, но и наименее эффективен, так как данные из разных областей памяти могут конфликтовать из-за единственной строки кэша, где они только и могут быть размещены.
Полностью ассоциативная памят
Может отображать содержимое любой области памяти в любую область кэша, но при этом крайне сложна в схемотехнике.
Является наиболее распространенным в данный момент среди процессорных архитектур. Характеризуется тем или иным количеством n « каналов » ( степенью ассоциативности, « п- way») и может отображать содержимое данной строки памяти на каждую из n своих строк. Этот вариант является разумным компромиссом между полностью ассоциативным и кэшем « прямого отображения ».
В современных процессорах, как правило, используется либо кэш-память с прямым отображением, либо двух- (четырех-) канальная множественно ассоциативная кэш-память. Например, в архитектурах К 7 и К 8 применяется 16- канальный частично-ассоциативный кэш L2.
Стратегия замещения информации в кэше определяет блок, подлежащий замещению при возникновении промаха. Простота при использовании кэша с прямым отображением заключается в том, что аппаратные решения здесь наиболее простые: легко реализуется сама аппаратура, легко происходит замещение данных. При замещении просто нечего выбирать — на попадание проверяется только один блок и только этот блок может быть замещен.
При полностью или частично ассоциативной организации кэш-памяти имеются несколько блоков, из которых надо выбрать кандидата в случае промаха. Как правило, для замещения блоков применяются две основные стратегии:
случайная ( Random) — блоки-кандидаты выбираются случайно (равномерное распределение). В некоторых системах используют псевдослучайный алгоритм замещения;
замещается тот блок, который не использовался дольше всех ( LRU — Least-Recently Used). В этом случае чтобы уменьшить вероятность удаления информации, которая скоро может потребоваться, все обращения к блокам фиксируются.
Достоинство случайного способа заключается в том, что его проще реализовать в аппаратуре. Когда количество блоков увеличивается, алгоритм LRU становится все более дорогим и часто только приближенным.
Алгоритмы обмена с кэш-памятью (свопинга)
включают следующие разновидности:
· алгоритм сквозной записи ( Write Through) или сквозного накопления ( Store Through);
· алгоритм простого свопинга ( Simple Swapping) или обратной записи ( Write Back);
· алгоритм свопинга с флагами ( Flag Swapping) или обратной записи в конфликтных ситуациях с флагами ( CUX);
· алгоритм регистрового свопинга с флагами ( FRS).

Алгоритм сквозной записи
Самый простой алгоритм свопинга. Каждый раз при появлении запроса на запись по некоторому адресу обновляется содержимое области по этому адресу как в быстрой, так и в основной памяти, даже если копия содержимого по этому адресу находится в быстром буфере. Такое постоянное обновление содержимого основной памяти, как и буфера, при каждом запросе на запись позволяет постоянно поддерживать информацию, находящуюся в основной памяти, в обновленном состоянии.
Поэтому, когда возникает запрос на запись по адресу, относящемуся к области, содержимое которой не находится в данный момент в быстром буфере, новая информация записывается просто на место блока, которое предполагается переслать в основную память (без необходимости пересылки этого слова в основную память), так как в основной памяти уже находится его достоверная копия.
Алгоритм простого свопинга
Обращения к основной памяти имеют место в тех случаях, когда в быстром буфере не обнаруживается нужное слово. Эта схема свопинга повышает производительность системы памяти, так как в ней обращения к основной памяти не происходят при каждом запросе на запись, что имеет место при использовании алгоритма сквозной записи. Однако в связи с тем, что содержимое основной памяти не поддерживается в постоянно обновленном состоянии, если необходимого слова в быстром буфере не обнаруживается, из буфера в основную память надо возвратить какое-либо устаревшее слово, чтобы освободить место для нового необходимого слова. Поэтому из буфера в основную память сначала пересылается какое-то слово, место которого занимает в буфере нужное слово. Таким образом, происходят две пересылки между быстрым буфером и основной памятью.
Алгоритм свопинга с флагами
Данный алгоритм является улучшением алгоритма простого свопинга. В алгоритме простого свопинга, когда в кэш-памяти не обнаруживается нужное слово, происходит два обращения к основной памяти — запись удаляемого значения из кэша и чтение нового значения в кэш. Если слово с того момента, как оно попало в буфер из основной памяти, не подвергалось изменениям, то есть по его адресу не производилась запись (оно использовалось только для чтения), то нет необходимости пересылать его обратно в основную память, потому что в ней и так имеется достоверная его копия; это обстоятельство позволяет в ряде случаев обойтись без обращений к основной памяти. Если, однако, слово подвергалось изменениям с тех пор, когда его копия была в последний раз записана обратно в основную память, то приходится перемещать его в основную память. Отслеживать изменения слова можно, пометив слово (блок) дополнительным флаг-битом. Изменяя значение флаг-бита при изменении слова, можно сформировать информацию о состоянии слова. Пересылать в основную память необходимо лишь те слова, флаги которых оказываются в установленном состоянии.
Алгоритм регистрового свопинга с флагами
Повышение эффективности алгоритма свопинга с флагами возможно за счет уменьшения эффективного времени цикла, что можно получить при введении регистра (регистров) временного хранения между кэш-памятью и основной памятью. Теперь, если данные должны быть переданы из быстрого буфера в основную память, они сначала пересылаются в регистр (регистры) временного хранения; новое слово сразу же пересылается в буфер из основной памяти, а уже потом слово, временно хранившееся в регистре, записывается в основную память. Действия в ЦП начинают опять выполняться, как только для этого возникает возможность. Алгоритм обеспечивает совмещение операций записи в основную память с обычными операциями над буфером, что обеспечивает еще большее повышение производительности.
Эксклюзивным называется кэш, в котором данные, хранящиеся в кэш-памяти первого уровня, не обязательно должны быть продублированы в кэшах нижележащих уровней. Инклюзивный кэш — когда любая информация, хранящаяся в кэшах высших уровней, дублируется в кэш-памяти.
Источник



