
Способы организации данных




![]()
![]()
Существует два способа организации данных на листе: таблица и список.
При организации данных в виде таблицы формируются строки и столбцы с записями, для которых в ячейку на пересечении строки и столбца помещаются данные. Например, на рис. 5.1 показана таблица уровня образования студентов Интернет-Университета по годам: года размещены в строках, а количество студентов соответствующего уровня образования – в столбцах.
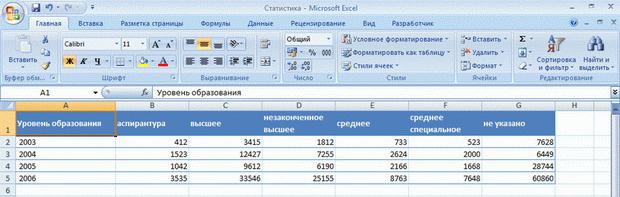
Рис. 5.1. Табличный способ организации данных
Таблицы могут иметь весьма сложную структуру с несколькими уровнями записей в строках и столбцах.
Табличный способ обеспечивает, как правило, более компактное размещение данных на листе. Для данных, организованных табличным способом, удобнее создавать диаграммы; в отдельных случаях удобнее производить вычисления. С другой стороны, данные, организованные в виде таблицы, сложнее обрабатывать: производить выборки, сортировки и т. п.
Другой способ организации данных – список. Список – набор строк листа, содержащий однородные данные; первая строка содержит заголовки столбцов, остальные строки содержат однотипные данные в каждом столбце.
В виде списка можно представлять как данные информационного характера (номера телефонов, адреса и т. п.), так и данные, подлежащие вычислениям.
Представление данных в виде списка обеспечивает большее удобство при сортировках, выборках, подведении итогов и т. п. С другой стороны, в этом случае затруднено построение диаграмм, снижается наглядность представления данных на листе.
Одни и те же данные можно представить как в виде таблицы, так и в виде списка. Например, в списке на рис. 5.2 представлены данные, организованные как таблица на рис. 5.1.
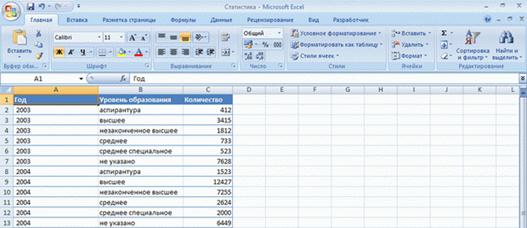
Рис. 5.2. Организация данных в виде списка
Нет каких-либо конкретных рекомендаций по использованию того или иного способа организации данных на листе. В каждом случае оптимальный способ выбирают исходя из решаемых задач.
Поскольку термин «таблица» является более традиционным, здесь и далее массив данных будет называться таблицей, кроме тех случаев, когда способ организации имеет принципиальное значение.
Источник
Способы организации данных
Возможны следующие способы организации данных:
1. Последовательный, т.е. доступ к данным в порядке их следования.
Различают последовательные данные со следующей длиной записи:
— фиксированной, т.е. все порции данных, считываемых или записываемых в файл, имеют одинаковую протяженность (поле, содержащее длину записи, может располагаться в управляющих структурах файла.);
— переменной, т.е. данные содержат поле с указанием длины текущей записи непосредственно перед самой записью(это несколько увеличивает протяженность файла: если длина дополнительного поля равна четырем байтам, то накладные расходы есть учетверенное число записей; требуется дополнительное время на считывание или генерацию поля длины записи);
— неопределенной, т.е. длина текущей записи задается в программе, в операторе или группе машинных команд, реализующих доступ к данным (данные не требуют пространственных накладных расходов).
2. Прямой способ обеспечивает произвольную последовательность доступа к записям файла. Это становится возможным в результате нумерации записей. Доступ к некоторой записи осуществляется по номеру.
Прямая организация предполагает одинаковую длину всех записей, поскольку иначе невозможно обеспечить пересчет номера записи в абсолютный адрес на внешнем устройстве. Чтобы поддерживать прямую запись в файл, приходится размечать требуемое пространство на диске при создании файла.
Файл, созданный как последовательный, в дальнейшем может рассматриваться как имеющий прямую организацию.
3. Индексно-последовательный способ пытается совместить достоинства последовательного и прямого доступов к данным:
— гибкость структуры записи, присущая последовательной организации;
— быстрый доступ к произвольной записи, как в прямой организации;
— возможна высокая скорость поиска информации, соответствующей заданному критерию (контекстный поиск);
— с каждой записью, помимо поля длины связывается поле индекса – числа или строки, однозначно идентифицирующего данные в записи.
Индекс может быть встроен в запись, т.е. быть ее частью, или располагаться отдельно от нее. Протяженность индекса есть управляемая величина, которая содержится в структурах описания файла. Индексы всех записей сводятся в отдельную таблицу, где упорядочиваются в соответствии с заданным критерием и связываются с абсолютными адресами хранения на диске. Одновременно хранятся адреса всех записей, связанные с их номерами.
Доступ к записи возможен в последовательном режиме, в индексно-последовательном, в прямом.
Для добавления новых записей требуется резервирование пространства под элементы индексной таблицы.
4. Библиотечный позволяет объединять в пределах одного файла несколько самостоятельных разделов, связанных друг с другом только областью применения.
В файле поддерживается каталог – таблица, в которой именам разделов ставятся в соответствие относительные адреса начала разделов и их протяженности. Для ускорения поиска имена разделов в каталоге упорядочиваются. Переменная длина раздела в библиотеке не позволяет реализовать модификацию непосредственно в файле и обычно требует перезаписи всего файла с внесением изменений в каталог.
Контрольные вопросы
1. Сформулируйте определение системы на основе категории «целостность».
2. Чем принципиально отличаются реляционные модели от сетевых и иерархических?
3. В чем различие процедурных и декларативных языков управления (манипулирования) данными?
4. Сформулируйте основные способы организации данных.
5. В чем суть нормализации отношений?
ТЕМА 5. ИНФОРМАЦИОННЫЕ МОДЕЛИ ПРИНЯТИЯ РЕШЕНИЙ
Источник
Конспект по дисциплине БД на тему «Модели организации данных в БД»

Модели организации данных в Базе данных
Системы автоматизации Базы данных манипулируют с конкретной моделью организации данных на машинном носителе. Модель данных определяется способом организации данных, ограничениями целостности и множеством операций, допустимых над объектами организации данных.
Модель данных – это абстрактное, самодостаточное, логическое определение объектов, операторов и прочих элементов, в совокупности составляющих абстрактную машину доступа к данным, с которой взаимодействует пользователь. Эти объекты позволяют моделировать структуру данных, а операторы – поведение данных.
При построении логической модели данных используются ниже перечисленные модели представления данных, поддерживаемые СУБД:
К ранним (дореляционным) СУБД относятся системы, основанные на инвертированных списках, иерархические и сетевые. Эти системы исторически предшествовали реляционным системам, внутренняя организация которых во многом основана на использовании методов ранних систем.
Иерархическая модель данных (рис. 1) близка по своей идее к иерархической (древовидной) структуре. Эта модель позволяет строить иерархию элементов БД, т.е. у каждого элемента может быть несколько “наследников” и существует один “родитель”. Для каждого уровня связи вводится интерпритация, зависящая от предметной области и описывающая взаимоотношения между “родителями” и “наследниками”.

Рис. 1. Графическое представление иерархической модели данных
На основе иерархической модели данных в конце 60-х – начале 70-х гг. ХХ в. были разработаны первые профессиональные СУБД: СУБД IMS (Information Management System) фирмы IBM, СУБД Tota, отечественные СУБД «ОКА», «ИНЭС».
Достоинства : возможность реализовать очень быстрый поиск, когда условия запроса соответствуют иерархии в схеме БД.
Недостатки: большая жесткость схемы. Если запрос не соответствует имеющейся иерархии, то его программирование и исполнение требуют значительных усилий. Другой недостаток- сложность внесения изменений.
Сетевая модель является развитием иерархической модели (рис. 2). Она основывается на понятиях элемента данных и связей, задающих логику взаимоотношений между данными. Связи от каждого элемента могут быть направлены на произвольное количество других элементов. Каждый элемент данных описывает некоторое понятие из предметной области и характеризуется некоторыми атрибутами.

Рис. 2. Графическое представление сетевой модели данных
Сетевая модель широко применялась в 70-е гг. ХХ в. в первых СУБД, использовавшихся крупными корпорациями для создания информационных систем: СУБД IDMS – Integrated Database Management System компании Cullinet Software Inc, СУБД IDS, предназначенная для использования на машинах основного класса фирмы IBM под управлением большинства операционных систем и отечественные СУБД «СЕТЬ», «БАНК», «СЕТОР». Архитектура системы IDMS основана на предложениях Data Base Task Group (DBTG) Комитета по языкам программирования Conference on Data Systems Languages (CODASYL), организации, ответственной за определение языка программирования Кобол.
Достоинства: высокая скорость поиска и возможность адекватно представлять многие задачи в самых различных предметных областях. Высокая скорость поиска основывается на классическом способе физической реализации сетевой модели — на основе списков.
Недостатки: жесткость, т.е. поиск данных и доступ к ним возможен только по тем связям, которые реально существуют в данной конкретной модели.
Для реляционной модели (рис. 3) выбрано представление данных на основе математического понятия отношения . Оно очень близко к понятию таблица . По-английски отношение — relation , отсюда и название “ реляционные СУБД”.
Реляционная модель БД – это набор информации, сгруппированной в одну или несколько таблиц. Таблица состоит из рядов и столбцов.

Рис. 2. Графическое представление реляционной модели данных
Каждый ряд (запись) в таблице описывает некий отдельный объект, поля содержат характеристики, значения неких признаков этих объектов. Записи в таблице объединяются по какому-то признаку. Связь между таблицами существует на логическом уровне и определяется предметной областью. Практически связь между таблицами устанавливается за счет логически связанных данных в разных таблицах.
Для работы с реляционными СУБД используется стандартизированный язык структурированных запросов SQL ( Structured Query Language ).
Четкий математический базис для работы с данными.
Высокая стандартизованность реляционных СУБД.
Нефункциональность языка запросов SQL . Это означает, что пользователь формулируете не то, КАК надо найти данные, а то, ЧТО необходимо найти.
Недостатки: атомарность, ограниченность, предопределенность набора возможных типов данных атрибутов. Это затрудняет использование реляционных моделей для некоторых современных приложений. Данная проблема решается расширением реляционных моделей в объектно-реляционные.
Постреляционная модель данных представляет собой расширенную реляционную модель, в которой отменено требование атомарности атрибутов. Поэтому постреляционную модель называют «не первой нормальной формой» или «многомерной базой данных». Она использует трехмерные структуры, позволяя хранить в полях таблицы другие таблицы. Тем самым расширяются возможности по описанию сложных объектов реального мира. В качестве языка запросов используется расширенный SQL, позволяющий извлекать сложные объекты из одной таблицы без операций соединения. Существует несколько коммерческих постреляционных СУБД, самыми известными из них являются системы Adabas, Pick и Universe.
Объектно-ориентированные модели данных. В настоящее время общепринятого определения объектно-ориентированной модели данных не существует, говорят о неком «объектном» подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации.
В объектно-ориентированном программировании отсутствуют общие средства манипулирования данными. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
автоматическое поддержание отношений наследования;
возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов, такие поля и методы используются только методами самого объекта;
создание процедур контроля целостности внутри объекта.
Появление объектно-ориентированных СУБД вызвано потребностями программистов, которым были необходимы средства для хранения объектов, не помещавшихся в оперативной памяти компьютера. Также важна была задача сохранения состояния объектов между повторными запусками прикладной программы. Поэтому большинство СУБД представляют собой библиотеку, процедуры управления данными которой включаются в прикладную программу.
Источник
Способ организации данных информатика
Ключевые слова
Концептуальная модель. Информационная модель. Модель данных. Функционально-ориентированный набор данных. Нормальная форма. Метод доступа. Ключевой атрибут. База данных. Система управления базой данных.
3.1. Модели и методы организации данных

Информационные модели
Информационная модель представляет собой формализованное описание на языке информатики части реального мира (предметной области), подлежащей изучению для организации управления и автоматизации социально-экономических процессов.
Информационная модель должна удовлетворять ряду требований: управление потоками событий; идентификация сообщений; обработка ошибок; возможность расширения; простота использования и управления (включая транспортабельность передачи сообщений); «мягкий» отказ; возможность расширения.
Информационный объект – это описание некоторой сущности (реального объекта, явления, процесса, события) в виде совокупности логически связанных информационных элементов (атрибут/реквизит, отношение).
Информационный объект имеет множество реализаций (экземпляров), каждый из которых представлен совокупностью конкретных значений атрибутов и идентифицируется значением ключевого атрибута (ключа). Остальные атрибуты являются описательными.
Информационная модель позволяет зафиксировать концептуальное устройство предметной области, иерархию понятий, свойств и структуру объектов.
Информационные объекты одного реквизитного состава и структуры образуют классы объектов, которым также присваивается уникальное имя («Студент», «Сессия», «Стипендия»).
Модель данных – это совокупность структурированных данных и операций их обработки.
Построение информационной модели базируется на описании документооборота и алгоритмов решения прикладных задач. Моделирование возможно, если создано формализованное описание, учитывающее основные закономерности процессов и действующие факторы.
Решение по конфигурации модели принимается с учетом объемных и временных характеристик потоков информации, рациональных маршрутов ее движения.
Локализация информации осуществляется с учетом:
- класса задач, решаемых с использованием этой информации;
- круга соответствующих пользователей;
- места хранения.
Концептуальная модель предметной области служит для описания ее объектов и отношений между ними:
Мк =
где А – множество объектов;
R – множество отношений между объектами.
Информационно-логическая (инфологическая) модель предметной области отражает предметную область в виде совокупности информационных объектов и их структурных связей.
Этапы построения информационной модели:
- идентификация пользователей и сопряженных организаций;
- идентификация областей принятия решений;
- определение области принятия решений;
- разработка описательной системы модели;
- разработка нормативной системы модели;
- разработка согласованной модели системы;
- построение и описание алгоритма принятия решений;
- определение информационных потребностей.
Технологию информационного моделирования можно представить следующим образом.
Первый шаг. Агрегированный структурный анализ:
- Назначение и цели организации.
- Операционная часть.
- Структурная конфигурация.
Второй шаг. Функциональный анализ:
- Основные функциональные стратегии, цели и показатели работы.
- Основные свойства, используемые для интеграции (планирование и контроль, инструменты связи, система принятия решений).
Третий шаг. Детализированный анализ организационных функций:
- Функциональные цели и показатели эффективности функционирования для поддерживаемых целей.
- Функциональные единицы и структуры.
- Функциональные системы.
Четвертый шаг. Анализ управленческих функций, поддерживаемых системой:
- Категории видов управленческой деятельности.
- Роли руководителей по основным видам деятельности: описать обязанности в пределах организационных функций или процессов; определить прямые обязанности.
- Показатели эффективности для управленческих функций.
- Идентифицировать действия, которые нужно поддерживать по каждому виду управленческой деятельности: определить цели и природу действий; определить природу проблем и природу процесса решения проблем; описать технику и ресурсы, необходимые для действий; описать влияние человеческих факторов на действия.
Пятый шаг.Определить характеристики для поддержки управленческих функций:
- информационные характеристики и содержание;
- вид необходимого преобразования информации;
- характеристики сообщений с точки зрения руководителей.
Уровни моделирования
Организационный уровень заключается в разработке организационных мероприятий и нормативных документов, обеспечивающих функционирование системы.
Информационная модель системы организационного уровня должна удовлетворять следующим требованиям:
- многократное использование любых наборов данных, содержащихся в динамической модели любого узла, всеми пользователями системы;
- однократный ввод оперативных данных;
- минимальная избыточность за счет развитой системы идентификации содержания информации и связей между узлами системы;
- физическая независимость данных, обеспечивающая возможность изменения способов физического хранения данных, а также замены внешних запоминающих устройств без значительной модификации программного обеспечения;
- логическая независимость данных, предусматривающая возможность добавления новых элементов данных и расширения общих логических структур информации без модификации программного обеспечения;
- простота использования модели, позволяющая применять языки запросов высокого уровня, которые обеспечивают возможность получения данных пользователями системы без необходимости разработки ими специальных программ;
- пользователи должны иметь возможность легкого получения информации о том, какие данные имеются в их рассмотрении, используя словари данных, определяющие элементы хранимой информации и методы ее получения, а также различные средства помощи;
- модель должна обеспечивать требуемую скорость удовлетворения запросов пользователей на запрашиваемые данные с помощью совершенных систем адресации, механизмов доступа и поиска данных;
- модель должна обеспечивать требуемый уровень контроля достоверности и целостности хранимой и используемой информации;
- модель должна обеспечивать требуемый уровень сохранности и защищенности данных от физического разрушения, несанкционированного доступа и использования, а также средства эффективного и своевременного восстановления работоспособности при сбоях и отказах;
- при подготовке и использовании информации должны применяться методы счетного и логического контроля, автоматического обнаружения и исправления ошибок.
Концептуальный уровень соответствует логическому аспекту представления об информации предметной области в интегрированном виде.
Функциональный уровень обеспечивает решение прикладных задач, требующих предварительного анализа информации.
Информационный уровень обеспечивает формирование информационных объектов (количественное и качественное описание), между которыми установлены связи, позволяющие осуществлять поиск и выбор требуемой информации в соответствии с реализуемыми функциями.
В основе моделирования лежит специфицирование (формализованное описание) предметной области. Специфицирование состоит в описании входной и выходной информации, планово-отчетных показателей, нормативно-справочной информации, оперативной информации, процедур, предназначенных для принятия решений руководителями всех уровней, словарей и каталогов пользователей.
Схема специфицирования предметной области:
- обозначение работы (код, наименование, идентификатор);
- проблемно или пооперационно организованная функция;
- обеспечивающая процедура.
При моделировании используется блочный принцип.
Функциональные блоки описывают функции в соответствии с этапами работы и подразделениями-исполнителями (функциональный граф).
Информационные блоки являются информационными описаниями выполняемых функций (информационный граф). Они состоят из функционально-ориентированных наборов данных, являющихся основой построения информационных баз.
Спецификация функционально-ориентированных наборов данных:
- обозначение функционально-ориентированных наборов данных;
- объемные характеристики (атрибуты, уровень, хранение, объемы);
- психологические характеристики (обработка, потребление, пользователь, режим работы, стоимость).
Между информационными блоками существуют логические связи, позволяющие осуществлять поиск и выбор требуемой информации в соответствии с реализуемыми функциями.
В прикладной системе можно выделить следующие уровни организации информации: модели процессов, документов, вычислений и данных, а также экземпляры хранимых записей.
Монитор управления обеспечивает интерфейс между моделями процессов и моделями документов. Модели процессов задаются с помощью функций и предикатов, что позволяет синхронизировать процедуры обработки информации, инициируемые пользователем.
Блок общения обеспечивает интерфейс между моделями документов, вычислений и данных. Модели документов имеют иерархическую структуру и содержат наряду с именами информационных областей (доменов) связи, существующие между ними для организации логического контроля и обработки вводимых и выводимых данных.
Блок управления вычислениями обеспечивает интерфейс между моделью вычислений и моделью данных. Модель вычислений задает информационные связи, существующие между процедурами обработки данных, позволяя автоматически генерировать управляющие программы для преобразования одних данных в другие.
Блок управления данными обеспечивает интерфейс между записями и моделью данных, которая представляет собой перечень имен документов с указанием функциональных связей между ними и позволяет организовать ввод, корректировку и поиск хранимых данных. Необходимый интерфейс между физическими записями и уровнем хранимых записей обеспечивается использованием методов доступа, которые позволяют представить структуры памяти в виде совокупности хранимых файлов.
Организация данных
Модель данных – это совокупность структурированных данных и операций их обработки.
Модели данных классифицируют по структурам.
- Простые списковые.
Содержат списки индексов для множества записей. Индекс включает ключ записи и соответствующий адрес (поэтому эти структуры еще называют адресными списками). - Цепные.
Каждая запись, кроме собственного адреса, содержит адрес следующей за ней записи (ссылку). Могут быть незамкнутыми и замкнутыми (кольцевыми). - Иерархические.
Объединяют наборы разнотипных записей, допускающих всевозможные сочетания между собой. Описываются с помощью служебных записей для вершин (имя, дуги) и для дуг (имя, источник, приемник, прочие дуги источника). Могут быть древовидными и сетевыми. - Реляционные.
Объединяют наборы однотипных записей, описываемых с помощью двумерных таблиц (строка-кортеж, столбец-домен).
Модели данных используют различные методы доступа:
- последовательный;
- прямой (индексный);
- индексно-последовательный.
Файл – это совокупность экземпляров записей одной структуры. Через файл осуществляется обращение к данным во внутреннем (машинном) представлении.
Объект характеризуется записью. Запись характеризуется полем (атрибут может иметь несколько полей). Поле характеризуется описанием (реквизитом). Поле, каждое значение которого однозначно определяет соответствующую запись, называется ключевым полем (первичный или простой ключ).
В правильно построенной реляционной базе данных в каждой таблице есть один или несколько столбцов, значения в которых во всех строках разные. Этот столбец называется первичным ключом таблицы.
Если запись однозначно определяется значениями нескольких полей, то используется составной ключ (или вторичный).
Первичный ключ для каждой строки таблицы является уникальным, поэтому в таблице с первичным ключом нет двух одинаковых строк.
Таблица, в которой все строки отличаются друг от друга, в математических терминах называется отношением. Именно этому термину реляционные базы данных и обязаны своим названием, поскольку в их основе лежат отношения (таблицы с отличающимися друг от друга строками).
Столбец одной таблицы, значения в котором совпадают со значениями столбца, являющегося первичным ключом другой таблицы, называется внешним ключом.
Внешние ключи выполняют роль поисковых или группировочных признаков.
Внешний ключ, как и первичный ключ, тоже может представлять собой комбинацию столбцов. На практике внешний ключ всегда будет составным (состоящим из нескольких столбцов), если он ссылается на составной первичный ключ в другой таблице. Очевидно, что количество столбцов и их типы данных в первичном и внешнем ключах совпадают.
Если таблица связана с несколькими другими таблицами, она может иметь несколько внешних ключей.

3.2. Системы информационных баз
Структура информационных баз
Информационное хранилище (или глобальная информационная база) содержит сведения о всей информации, доступной человечеству в масштабе земли.
Информационное хранилище включает отдельные информационные базы, которые формируют единое информационное пространство.
Информационная база – это, в широком смысле слова, совокупность сведений о конкретных объектах реального мира в какой-либо предметной области.
Информационная база может включать базы и банки данных, базы знаний.
Базы данных могут включать локальные записи (автономные, постраничные) и информационные таблицы.
По топологическому принципу базы данных делятся на локальные (централизованные) и распределенные (децентрализованные).
По архитектурному принципу база данных делится на четыре зоны:
- зона пользователя;
- функциональная (проблемная) зона;
- нормативно-справочная зона;
- технологическая зона.
В проблемной зоне базы данных хранится информация, необходимая для реализации закрепленных функций.
В справочной зоне базы данных хранится нормативно-справочная информация (словари, каталоги, справочники, сценарии связи).
В технологической зоне базы данных хранится информация, необходимая для проведения работ в пакетном режиме, подготовленная для передачи между зонами и во внешнее информационное пространство, а также информация, используемая службой администратора для управления информационной системой (регламентация, доступ, защита, передача).
Формализация отношений
Между информационными блоками существуют логические связи отношения, позволяющие осуществлять поиск и вывод требуемой информации в соответствии с реализуемыми функциями.
Различают следующие виды связей.
1 тип – «один к одному» (1:1)
Это модель функциональных зависимостей: 
2 тип – «один ко многим» (1:М)
Это модель порожденных зависимостей (односторонних): 


Формируется цепочка указателей: 
3 тип – «много ко многим» (М:М)
Это модель порожденных записей (двусторонних): 


Используется составной ключ – Ui+ki, j+lj:

4 тип – «условная»
Модель одиночной связи 

Используется для связи корневых объектов.
Формализацией отношений называется аппарат ограничений, позволяющий устранять дублирование, обеспечить непротиворечивость хранимых данных, уменьшить трудозатраты на ведение информационной базы.
Основные нормальные формы:
1НФ – существуют только функциональные зависимости;
2НФ – существуют функциональные зависимости неключевых атрибутов от составного ключа;
3НФ – неключевые атрибуты не имеют транзитивной связи с первичным ключом (первый атрибут связан с ключом, а второй атрибут связан с первым атрибутом).
При нормализации отношений происходит «расщепление» исходных информационных объектов. Часть атрибутов (полей) при этом удаляется из исходного объекта и включается в состав других (в том числе, вновь создаваемых) объектов.
Каноническая процедура проектирования информационной базы
Разработка информационной базы включает логическое проектирование, физическое проектирование и проектирование представления данных для приложений (информационное проектирование), рис. 3.1.
Каноническая процедура проектирования:
- разработка информационно-функционального графа;
- выделение ключей;
- удаление избыточных связей;
- выделение информационных групп (группа характеризуется ассоциированными элементами и имеет первичный ключ);
- привязка к используемому программному обеспечению (тип СУБД).

К уровню представления данных применяют следующие требования:
- структурная схема должна учитывать логические связи данных и быть стабильной;
- каждая запись должна иметь простую структуру;
- записи и их элементы должны быть поименованы (уникально);
- связи между записями должны быть классифицированы;
- первичные ключи каждой записи должны быть выделены (помечены);
- необходимо отразить связи вторичных ключей;
- некоторые записи могут иметь специальный ключ.
3.3. Реляционные базы данных
 Основные понятия.
Основные понятия.
Системы управления базами данных.
Применение информационных баз в учебном процессе.
Основные понятия
В зависимости от структуры данных различают иерархические, сетевые и реляционные базы данных.
Реляционной считается такая база данных, в которой все данные представлены в виде двумерных таблиц и все операции над базой сводятся к манипуляциям над таблицами. Название «реляционная» связано с тем фактом, что каждая запись в такой базе содержит информацию, относящуюся (related) только к одному конкретному объекту (экземпляру сущности). Кроме того, с данными двух сущностей можно работать как с единым целым, основанным на значениях связей (ключей) между сущностями.
- отношение (relation) – информация об объектах одного класса (экземплярах сущности): клиенты, заказы, сотрудники. В реляционной базе данных отношение хранится в виде таблицы;
- атрибут (attribute) – поименованное свойство сущности: адрес клиента, дата заказа, зарплата сотрудника;
- домен (domain) – допустимое множество всех возможных значений атрибута;
- связь (relationship) – способ, которым информация в одной таблице связана с информацией в другой таблице;
- объединение (join) – процесс объединения таблиц на основе совпадающих значений определенных атрибутов.
Итак, реляционная таблица состоит из строк (записей) и столбцов (полей) и имеет уникальное имя внутри базы.
Таблица отражает сущность (класс объектов) реального мира, а каждая ее строка – конкретный экземпляр этой сущности.
Централизованная база данных хранится в памяти одной вычислительной машины (к ней может осуществляться распределенный доступ).
Распределенная база данных состоит из нескольких, возможно пересекающихся или дублирующих друг друга частей, хранимых на различных компьютерах.
Различают базы данных с локальным доступом и сетевым доступом.
В сетевом доступе различают технологии файл-сервер, клиент-сервер.
Системы управления базами данных
Для компьютерной обработки баз данных используют специальное программное обеспечение – системы управления базами данных (СУБД).
Работа СУБД характеризуется следующими этапами:
- создание структуры (шаблона) базы;
- заполнение базы;
- просмотр и редактирование базы;
- сортировка информации;
- фильтрация информации;
- поиск информации и последующая выборка;
- модификация структуры базы ее записей;
- создание запросов, форм, отчетов.
Современные СУБД обеспечивают:
- набор средств для поддержки таблиц и отношений между связанными таблицами;
- развитый пользовательский интерфейс, который позволяет вводить и модифицировать информацию, выполнять поиск и представлять выводимую информацию в текстовом или графическом виде;
- средства программирования, с помощью которых можно создавать собственные приложения;
- средства обеспечения безопасности.
К основным функциям, выполняемым СУБД, относят:
- непосредственное управление данными во внешней памяти;
- управление буферами оперативной памяти;
- управление транзакциями;
- протоколирование;
- поддержка языков баз данных.
На сегодняшний день насчитывается порядка пятидесяти типов СУБД для IBM PC-совместимых компьютеров: семейство dBASE (RBASE, dBASE – фирма Borland, Ребус, Клиппер); семейство foxBASE (foxBASE, FoxPro, Visual FoxPro – фирма Microsoft); Paradox (ф. Borland); Access (ф. Microsoft).
- генерация исполнимых файлов;
- генерация меню, экранных форм, запросов, отчетов («Мастера», «Конструкторы»);
- генерация приложений.
Языковые средства: языки описания данных и языки манипулирования данными.
Пример 3.1. Язык описания данных: система информационного описания данных типа .
Пример 3.2. Языки манипулирования данными:
- XBASE–подобные языки (устаревший стандарт):
процедурная обработка; структурное программирование.
Занимают промежуточное положение между языками манипулирования данными и языками процессов. - QBE (Query by Example – образцовый язык запросов):
графический (схематичный) язык с минимальным набором простейших синтаксических конструкций: проекция (вертикальная выборка), селекция (горизонтальная выборка). - SQL (Structured Query Language – язык структурированных запросов):
международный стандарт языка запросов для архитектур файл-сервер и клиент-сервер.
SQL является инструментом, предназначенным для обработки и чтения данных, содержащихся в компьютерной базе данных. Как следует из названия, SQL является языком программирования, который применяется для организации взаимодействия пользователя с базой данных.
На самом деле SQL работает только с базами данных одного определенного типа, называемых реляционными (рис. 3.2)

В современные системы (например, Delphi) встраивают SQL-подобные процедуры, позволяющие работать с удаленными БД («прозрачное» подключение).
Операции алгебры отношений:
- ограничение (селекция) – горизонтальная выборка;
- проекция – вертикальная выборка;
- соединение – фильтрация;
- объединение – склеивание;
- пересечение.
- разность (вычитание);
- декартово (прямое) произведение;
- деление.
В современной реляционной БД выделяют ядро (Data Base Engine – процессор БД), компилятор (обычно для языка SQL), подсистему запросов (обработка транзакций), подсистему поддержки времени выполнения запроса и набор утилит, что обеспечивает работу в многопользовательских средах.
SQL — это неотъемлемая часть СУБД, инструмент, с помощью которого осуществляется связь пользователя с информационной базой (рис. 3.3).

SQL выполняет различные функции:
- Интерактивный язык запросов.
Пользователи вводят команды SQL в интерактивные программы, предназначенные для чтения данных и отображения их на экране. Это удобный способ выполнения специальных запросов. - Язык программирования баз данных.
Чтобы получить доступ к базе данных, программисты вставляют в свои программы команды SQL. Эта методика используется как в программах, написанных пользователями, так и в служебных программах баз данных (таких как генераторы отчетов и инструменты ввода данных). - Язык администрирования баз данных.
Администратор базы данных использует SQL для определения структуры базы данных и управления доступом к данным. - Язык создания приложений «клиент-сервер».
В программах для персональных компьютеров SQL используется для организации связи через локальную сеть с сервером базы данных, в которой хранятся совместно используемые данные. В большинстве новых приложений используется архитектура клиент-сервер, которая позволяет свести к минимуму сетевой трафик и повысить быстродействие как персональных компьютеров, так и серверов баз данных. - Язык распределенных баз данных.
В системах управления распределенными базами данных SQL помогает распределять данные среди нескольких взаимодействующих вычислительных систем. Программное обеспечение каждой системы с помощью SQL связывается с другими системами, посылая им запросы на доступ к данным. - Язык шлюзов базы данных.
В вычислительных сетях с различными СУБД SQL часто используется в шлюзовой программе, которая позволяет СУБД одного типа связываться с СУБД другого типа.
Таким образом, SQL превратился в полезный и мощный инструмент, обеспечивающий людям, программам и вычислительным системам доступ к информации, содержащейся в реляционных базах данных.
Применение информационных баз в учебном процессе
При автоматизации функций подразделений организационной системы с помощью индивидуальных и групповых автоматизированных рабочих мест следует исходить из необходимости временного сохранения обычных форм взаимодействия с другими подразделениями, которые еще не охвачены системой автоматизации. Групповое или индивидуальное автоматизированное рабочее место должно иметь необходимый минимальный резервный комплект внешних устройств и устройств компьютера.
Схема единого образовательного пространства вуза:
- информационная база (локальный и распределенный контент);
- средства диспетчеризации / навигации (интегрированные модули);
- средства управления (опорные модули);
- средства администрирования (организационные модули);
- средства коммуникации (программные и технические модули).
Из образовательного пространства вуза формируется (динамически) образовательное пространство студента и образовательное пространство педагога.
Можно выделить следующие уровни управленческой деятельности с использованием компьютера в системе народного образования:
1 — управление учением и развитием отдельного учащегося;
2 — управление учебным процессом в рамках одного учебного заведения;
3 — управление учебным процессом группы родственных учебных заведений;
4 — управление работой учебных заведений, объединенных по территориальному признаку;
5 — управление системой народного образования Федерации в целом.
Топология типовой компьютерной системы учебных заведений характеризуется следующим образом.
Глобальная сеть Министерства через главный коммутационный узел входит в Республиканскую систему и включает в себя множество региональных сетей.
Региональная сеть Территориального управления через коммуникационный узел соединяется с отраслевой сетью и включает в себя множество магистральных одноконтурных сетей.
Одноконтурная сеть учебного заведения через коммуникационный узел соединяется с двухконтурной магистральной сетью и включает в себя множество локальных сетей.
Локальная сеть подразделения учебного заведения (отдел, факультет) через местный коммутационный узел соединяется с распределенной сетью и включает в себя множество пользовательских и технологических псевдосетей.
Пользовательская псевдосеть через коммутационную шину входит в локальную сеть и включает в себя абонентские узлы (выносные терминальные устройства, сетевые пользовательские компьютеры и их ассоциации).
На региональном и локальном уровнях могут использоваться персональные компьютеры и терминальные устройства, не входящие в состав нижележащих сетей. Архитектура компьютерной организационной системы является многоуровневой и обеспечивает представление данных для каждого уровня в терминах связанной с ними модели данных.
Концептуальный уровень обеспечивает интегрированное представление о предметной области.
Внешний уровень поддерживает представление данных, требуемое конкретным пользователем.
Внутренний уровень отражает требуемую организацию данных в среде хранения.
Проектируемые интерфейсы для компьютерных организационных систем должны обладать следующими характеристиками:
- обеспечить приемлемое время реакции системы. Интерфейс не должен вносить ощущение нестабильности, непредсказуемости или медлительности, настолько мешающих работе пользователя, что его действия становятся малоэффективными;
- иметь семантику, соответствующую семантике выполняемой работы;
- иметь естественный синтаксис, очевидный для пользователя и соответствующий выполняемой работе. Должно сводиться к минимуму число вариантов формы выполнения одной и той же функции и не допускается использование различных вариантов для выполнения подобных функций;
- обеспечить избирательные уровни поддержки и помощи пользователям различной квалификации.
Абоненты компьютерной организационной системы должны иметь возможность использовать следующие функции сеансовых услуг по обработке и передаче данных:
- хранение сообщений для последующей доставки;
- упаковка данных с целью эффективной их передачи;
- разбиение длинных сообщений на пакеты для последующей доставки;
- преобразование символических, групповых, сокращенных или неявных адресов в реальные;
- функции управления, позволяющие вводить транспортируемые пакеты, проверять их правильность и исправлять перед передачей;
- функции, дающие возможность пользователю затребовать доставку и индикацию сообщения, которое было передано ему ранее:
- контрольно-ревизионные функции в отношении системы;
- диалоговые функции, упрощающие «вход» в систему;
- справочные функции, позволяющие одному абоненту узнать местоположение другого;
- функции преобразования, позволяющие взаимодействовать несовместимым компьютерам;
- функции, содействующие вводу передаваемых данных;
- функции, обеспечивающие защиту информации;
- функции, обеспечивающие общение с виртуальным терминалом.
Предписание по системной обработке информации включает следующие функции:
- системная организация информационной базы (генерация, активизация, реорганизация, реструктуризация);
- резервирование памяти (определение частоты и содержания сбрасываемых на резервный носитель массивов);
- ведение системного журнала о функционировании системы. Генерация стандартных отчетов;
- восстановление информационной базы (или ее части) к предшествующему состоянию. Исправление части базы (физических блоков) в случае, если они стали непригодны для использования;
- установка режима работы системы (одиночный, многопользовательский, пакетный, диалоговый);
- организация взаимодействия с программами проблемной обработки данных.
При работе с реляционными таблицами используются предписания по обработке данных, включающие операции алгебры отношений: ограничение, соединение, прямое произведение, проекция, пересечение, объединение, разность, деление.
Кроме того, приводится порядок использования вспомогательных процедур копирования, восстановления, защиты данных от разрушений и несанкционированного доступа, а также таблицы соответствия шаблонов входным документам, таблицы распределения информации по томам прямого доступа, параметры настройки программных средств для используемых режимов работы.
При работе с распределенными данными используется предписание по обработке запросов, включающее следующие типовые функции:
- проверка корректности запроса и приведение его в стандартную форму;
- передача запроса в нужный пункт распределенной информационной базы;
- интерпретирование запроса в терминах языка конкретного пункта системы;
- выполнение запроса путем включения в работу конкретного пункта системы и формирования ответных данных;
- представление пользователю ответа в специфицированной им форме.
Пример 3.3. Кадровый состав кафедры.
Информационная база характеризуется отношениями:
КАФЕДРА (Наименование, Подотчетность, Заведующий)
НИР (Номер_работы, Характер_работы)
СЛУЖАЩИЙ (Фамилия, Пол, Квалификация, Адрес)
ДЕТИ (Фамилия_сотрудника, Имя_ребенка, Пол, Возраст)
ТРУД (Фамилия_сотрудника, Дата_назначения, Должность)
ОКЛАД (Фамилия_сотрудника, Дата_назначения, Размер_оклада)
Отношения характеризуются следующими связями:
Источник



