
- Оптимальный префиксный код с длиной кодового слова не более L бит
- Содержание
- Пример [ править ]
- Сведение к задаче о рюкзаке [ править ]
- Восстановление ответа. [ править ]
- Пример работы алгоритма генерации оптимального префиксного кода с длиной кодового слова не более L бит [ править ]
- Пример восстановления ответа. [ править ]
- Пример 3.1.
- wiki.vspu.ru
- портал образовательных ресурсов
- Алфавитное неравномерное двоичное кодирование. Префиксный код. Код Хаффмана
Оптимальный префиксный код с длиной кодового слова не более L бит
| Определение: |
Оптимальный префиксный код с длиной кодового слова не более L бит — это код, обладающий следующими свойствами:
|
Здесь будет приведен алгоритм, решающий эту задачу за время [math] O(nL) [/math] , где [math]L[/math] — максимальная длина кодового слова, [math]n[/math] — размер алфавита, c помощью сведения задачи к задаче о рюкзаке.
Содержание
Пример [ править ]
Данный алгоритм бывает полезен, когда нам нужно ограничить максимальную длину кодового слова, а при использовании алгоритма Хаффмана самому редко встречающемуся символу соответствует слишком длинное кодовое слово. Например, пусть дан алфавит из [math]5[/math] символов [math]A=\
| Символ | Частота | Код |
|---|---|---|
| A | 1 | 1111 |
| B | 2 | 1110 |
| C | 4 | 110 |
| D | 8 | 10 |
| E | 16 | 0 |
Самое длинное кодовое слово здесь имеет длину [math]4[/math] . Пусть мы хотим, чтобы слова в нашем коде были не длиннее трех бит. Тогда алгоритм, который будет описан ниже, генерирует такой код:
| Символ | Частота | Код |
|---|---|---|
| A | 1 | 000 |
| B | 2 | 001 |
| C | 4 | 010 |
| D | 8 | 011 |
| E | 16 | 1 |
Важно заметить следующий факт: в худшем случае все кодовые слова будут иметь длину [math]L[/math] бит. Тогда мы можем закодировать [math] 2^L [/math] символов. Таким образом, нельзя получить описанный выше код, если [math] n \gt 2^L [/math] .
Сведение к задаче о рюкзаке [ править ]
Пусть [math]L[/math] — ограничение на длину кодового слова, а [math]P=\
- Для каждого символа создадим [math]L[/math] предметов ценностью [math]2^<-1>\dots2^<-L>[/math] , каждый из которых имеет вес [math]p_[/math] .
- С помощью задачи о рюкзаке выберем набор предметов суммарной ценностью [math]n — 1[/math] ( [math]n[/math] — размер алфавита) с минимальным суммарным весом.
- Посчитаем массив [math]H=\
\>[/math] , где [math]h_[/math] — количество предметов ценностью [math]p_[/math] , которые попали в наш набор.
При этом [math]h_[/math] — это длина кодового слова для [math]i[/math] -го символа. Зная длины кодовых слов, легко восстановить и сам код.
Из последнего утверждения и шага два легко заметить, что длина кодового слова, сгенерированного приведенным алгоритмом, действительно не превысит [math]L[/math] . Это так, потому что мы создаем ровно [math]L[/math] предметов веса [math]p_[/math] (частота символа). А значит, если в худшем случае мы возьмем все предметы данного веса, то их количество не превысит [math]L[/math] .
Убедимся также, что необходимую сумму ( [math]n — 1[/math] ) всегда можно набрать. Зафиксируем размер алфавита равным [math]n = 2^k[/math] . Теперь вспомним неравенство, которым связаны [math]n[/math] и [math]L[/math] : [math] n \leqslant 2^L [/math] . Возьмем минимально возможное значение [math]L[/math] такое, что [math]2^L = n[/math] . По условию у нас есть по [math]n[/math] монет номинала [math]2^<-i>[/math] , где [math]1 \leqslant i \leqslant L[/math] . Попробуем посчитать суммарную стоимость имеющихся монет:
Поскольку [math]n = 2^L[/math] :
[math]\frac<2^L> <2^1>+ \frac<2^L> <2^2>+ \dots + \frac<2^L><2^L>[/math] [math] = 2^
Таким образом, мы набрали необходимую сумму, используя все предметы. Но так как мы рассматривали граничный случай, при бОльших значениях [math]L[/math] данную сумму гарантированно можно набрать.
Оптимальность же кода следует из оптимальности решения задачи о рюкзаке. Действительно, частота символа — это вес предметов, соответствующих ему. Значит, чем чаще символ встречается в тексте, тем реже он будет попадать в наш рюкзак (будет выгоднее брать предметы аналогичной ценности, но меньшего веса, соответствующие более редким символам), а значит, его код будет короче. Таким образом, код, сгенерированный данным алгоритмом, будет оптимальным среди кодов с длиной кодового слова не более [math]L[/math] .
Восстановление ответа. [ править ]
Рассмотрим процедуру восстановления ответа по заданному алфавиту и известным длинам кодовых слов.
- Отсортируем все символы по возрастанию длины кодового слова, которое им соответствует, а при равенстве длин — в алфавитном порядке.
- Первому символу сопоставим код, состоящий из нулей, соответствующей длины.
- Каждому следующему символу сопоставим следующее двоичное число. При этом если его длина меньше необходимой, то допишем нули справа.
Заметим, что при генерации каждого следующего кодового слова, в качестве его префикса выступает последовательность, лексикографически большая, чем предыдущее кодовое слово (ведь мы берем следующее двоичное число), а значит ни для каких двух кодовых слов одно не может быть префиксом другого. Значит, код, сгенерированный таким образом является префиксным.
Пример работы алгоритма генерации оптимального префиксного кода с длиной кодового слова не более L бит [ править ]
Пусть [math]A=\
Сначала создадим необходимый набор предметов;
| Символ | Частота | Предметы |
|---|---|---|
| [math]A[/math] | [math]1[/math] | [math] (2^<-1>, 1), (2^<-2>, 1) [/math] |
| [math]B[/math] | [math]2[/math] | [math](2^<-1>, 2), (2^<-2>, 2)[/math] |
| [math]C[/math] | [math]3[/math] | [math] (2^<-1>, 3), (2^<-2>, 3)[/math] |
Решим задачу о рюкзаке для заданного набора и выберем предметы суммарной ценностью [math] n — 1 = 2 [/math] с минимальным суммарным весом. В нашем случае в оптимальный набор попадут следующие предметы:
Посчитаем массив [math] H [/math] :
Итак, мы получили длины кодовых слов для символов. Осталось восстановить ответ.
Пример восстановления ответа. [ править ]
Итак, у нас есть [math]A=\
Сопоставим первому символу код, состоящий из одного нуля:
Сопоставим следующему символу следующее двоичное число. Так как длина кода увеличилась на один, то припишем справа ноль:
[math] B = 10 [/math]
Сопоставим следующему символу следующее двоичное число.
Источник
Пример 3.1.
Пусть имеется следующая таблица префиксных кодов:

Требуется декодировать сообщение:
Декодирование производится циклическим повторением следующих действий:
(a) отрезать от текущего сообщения крайний левый символ, присоединить справа к рабочему кодовому слову;
(b) сравнить рабочее кодовое слово с кодовой таблицей; если совпадения нет, перейти к (а);
(c) декодировать рабочее кодовое слово, очистить его;
(d) проверить, имеются ли еще знаки в сообщении; если «да», перейти к (а).
Применение данного алгоритма дает:

Доведя процедуру до конца, получим сообщение: «мама мыла раму».
Таким образом, использование префиксного кодирования позволяет делать сообщение более коротким, поскольку нет необходимости передавать разделители знаков. Однако условие Фано не устанавливает способа формирования префиксного кода и, в частности, наилучшего из возможных. Мы рассмотрим две схемы построения префиксных кодов.
Префиксный код Шеннона-Фано
Данный вариант кодирования был предложен в 1948-1949 гг. независимо Р. Фано и К. Шенноном и по этой причине назван по их именам. Рассмотрим схему на следующем примере: пусть имеется первичный алфавит А, состоящий из шести знаков а1 . а6 с вероятностями появления в сообщении, соответственно, 0,3; 0,2; 0,2; 0,15; 0,1; 0,05. Расположим эти знаки в таблице в порядке убывания вероятностей (см. табл. 3.2). Разделим знаки на две группы таким образом, чтобы суммы вероятностей в каждой из них были бы приблизительно равными. В нашем примере в первую группу попадут a1 и а2 с суммой вероятностей 0,5 — им присвоим первый знак кода «0». Сумма вероятностей для остальных четырех знаков также 0,5; у них первый знак кода будет «1». Продолжим деление каждой из групп на подгруппы по этой же схеме, т.е. так, чтобы суммы вероятностей на каждом шаге в соседних подгруппах были бы возможно более близкими. В результате получаем:
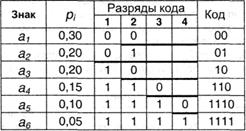
Из процедуры построения кодов легко видеть, что они удовлетворяют условию Фано и, следовательно, код является префиксным. Средняя длина кода равна:

I1 ( A ) = 2,390 бит. Подставляя указанные значения в (3.5), получаем избыточность кода Q(A,2) = 0,0249, т.е. около 2,5%. Однако, данный код нельзя считать оптимальным, поскольку вероятности появления 0 и 1 неодинаковы (0,35 и 0,65, соответственно). Применение изложенной схемы построения к русскому алфавиту дает избыточность кода 0,0147.
Префиксный код Хаффмана
Способ оптимального префиксного двоичного кодирования был предложен Д. Хаффманом. Построение кодов Хаффмана мы рассмотрим на том же примере. Создадим новый вспомогательный алфавит A1, объединив два знака с наименьшими вероятностями (а5 и а6) и заменив их одним знаком (например, а (1) ); вероятность нового знака будет равна сумме вероятностей тех, что в него вошли, т.е. 0,15; остальные знаки исходного алфавита включим в новый без изменений; общее число знаков в новом алфавите, очевидно, будет на 1 меньше, чем в исходном. Аналогичным образом продолжим создавать новые алфавиты, пока в последнем не останется два знака; ясно, что количество таких шагов будет равно N — 2, где N — число знаков исходного алфавита (в нашем случае N = 6, следовательно, необходимо построить 4 вспомогательных алфавита). В промежуточных алфавитах каждый раз будем переупорядочивать знаки по убыванию вероятностей. Всю процедуру построения представим в виде таблицы:

Теперь в обратном направлении проведем процедуру кодирования. Двум знакам последнего алфавита присвоим коды 0 и 1 (которому какой — роли не играет; условимся, что верхний знак будет иметь код 0, а нижний — 1). В нашем примере знак а1 (4) алфавита A (4) , имеющий вероятность 0,6, получит код 0, а a2 (4) с вероятностью 0,4 — код 1. В алфавите А (3) знак a1 (3) получает от a2 (4) его вероятность 0,4 и код (1); коды знаков a2 (3) и a3 (3) , происходящие от знака a1 (4) с вероятностью 0,6, будут уже двузначным: их первой цифрой станет код их «родителя» (т.е. 0), а вторая цифра — как условились — у верхнего 0, у нижнего — 1; таким образом, a2 (3) будет иметь код 00, а a3 (3) — код 01. Полностью процедура кодирования представлена в таблице, приведенной на с.70.
Из процедуры построения кодов вновь видно, что они удовлетворяют условию Фано и, следовательно, не требуют разделителя. Средняя длина кода, как и в предыдущем примере оказывается:
К(А,2) = 0,3 ∙ 2 + 0,2 ∙ 2 + 0,2 ∙ 2 +0,15 ∙ 3 + 0,1 ∙ 4 + 0,05 ∙ 4 = 2,45.

Избыточность снова оказывается равной Q(A, 2) = 0,0249, однако, вероятности 0 и 1 сблизились (0,47 и 0,53, соответственно). Более высокая эффективность кодов Хаффмана по сравнению с кодами Шеннона-Фано становится очевидной, если сравнить избыточности кодов для какого-либо естественного языка. Применение описанного метода для букв русского алфавита порождает коды, представленные в табл. 3.2. (для удобства сопоставления они приведены в формате табл. 3.1).
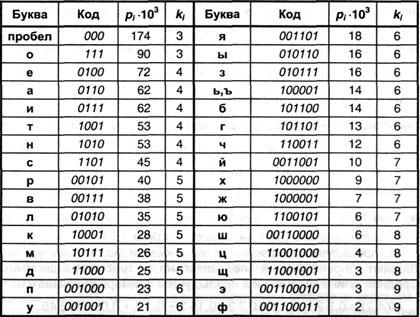
Средняя длина кода оказывается равной К(r,2) = 4,395; избыточность кода Q(r,2) = 0,0090, т.е. не превышает 1 %, что заметно меньше избыточности кода Шеннона-Фано (см. выше).
Код Хаффмана важен в теоретическом отношении, поскольку можно доказать, что он является самым экономичным из всех возможных, т.е. ни для какого метода алфавитного кодирования длина кода не может оказаться меньше, чем код Хаффмана (см. [49, с.209-211]).
Таким образом, можно заключить, что существует способ построения оптимального неравномерного алфавитного кода. Не следует думать, что он представляет число теоретический интерес. Метод Хаффмана и его модификация — метод адаптивного кодирования (динамическое кодирование Хаффмана) — нашли широчайшее применение в программах-архиваторах, программах резервного копирования файлов и дисков, в системах сжатия информации в модемах и факсах.
Источник
wiki.vspu.ru
портал образовательных ресурсов
Алфавитное неравномерное двоичное кодирование. Префиксный код. Код Хаффмана
Алфавитное неравномерное двоичное кодирование— кодирование при котором символы некоторого первичного алфавита кодируются комбинациями символов двоичного алфавита (т.е. 0 и 1), причем, длина кодов и, соответственно, длительность передачи отдельного кода, могут различаться.
Префиксный код в теории кодирования— код со словом переменной длины, имеющий такое свойство (выполнение условия Фано): если в код входит слово a, то для любой непустой строки b слова ab в коде не существует. Хотя префиксный код состоит из слов разной длины, эти слова можно записывать без разделительного символа.
Например, код, состоящий из слов 0, 10 и 11, является префиксным, и сообщение 01001101110 можно разбить на слова единственным образом:
0 10 0 11 0 11 10
Код, состоящий из слов 0, 10, 11 и 100, префиксным не является, и то же сообщение можно трактовать несколькими способами.
0 10 0 11 0 11 10
0 100 11 0 11 10
Префиксные коды широко используются в различных областях информационных технологий. На них основаны многие алгоритмы сжатия информации. Их используют различные протоколы. К префиксным кодам относятся такие распространённые вещи, как:
• Юникод,
• телефонные номера,
• Код Хаффмана,
• Код Фибоначчи и мн. другие.
Код Хаффмана
Идея, положенная в основу кодировании Хаффмана, основана на частоте появления символа в последовательности. Символ, который встречается в последовательности чаще всего, получает новый очень маленький код, а символ, который встречается реже всего, получает, наоборот, очень длинный код. Это нужно, так как мы хотим, чтобы, когда мы обработали весь ввод, самые частотные символы заняли меньше всего места (и меньше, чем они занимали в оригинале), а самые редкие — побольше (но так как они редкие, это не имеет значения). В данной статье я решил, что символ будет иметь длину 8 бит, то есть, будет соответствовать печатному знаку.
Я мог бы с той же простотой взять символ длиной в 16 бит (то есть, состоящий из двух печатных знаков), равно как и 10 бит, 20 и так далее. Размер символа выбирается, исходя из строки ввода, которую мы ожидаем встретить. Например, если бы я собрался кодировать сырые видеофайлы, я бы приравнял размер символа к размеру пикселя. Помните, что при уменьшении или увеличении размера символа меняется и размер кода для каждого символа, потому что чем больше размер, тем больше символов можно закодировать этим размером кода. Комбинаций нулей и единичек, подходящих для восьми бит, меньше, чем для шестнадцати. Поэтому вы должны подобрать размер символа, исходя из того по какому принципу данные повторяются в вашей последовательности.
Предположим, у нас есть строка «beep boop beer!», для которой, в её текущем виде, на каждый знак тратится по одному байту. Это означает, что вся строка целиком занимает 15*8 = 120 бит памяти. После кодирования строка займёт 40 бит.
Чтобы получить код для каждого символа строки «beep boop beer!»,на основе его частотности, нам надо построить бинарное дерево, такое, что каждый лист этого дерева будет содержать символ (печатный знак из строки). Дерево будет строиться от листьев к корню, в том смысле, что символы с меньшей частотой будут дальше от корня, чем символы с большей. Скоро вы увидите, для чего это нужно.
Чтобы построить дерево, мы воспользуемся слегка модифицированной очередью с приоритетами — первыми из неё будут извлекаться элементы с наименьшим приоритетом, а не наибольшим. Это нужно, чтобы строить дерево от листьев к корню.
Для начала посчитаем частоты всех символов: 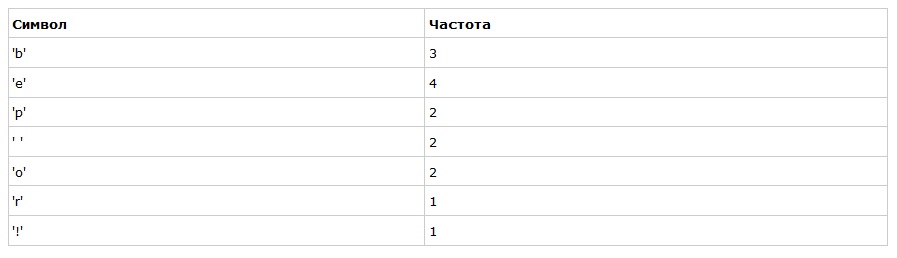
После вычисления частот мы создадим узлы бинарного дерева для каждого знака и добавим их в очередь, используя частоту в качестве приоритета:

Теперь мы достаём два первых элемента из очереди и связываем их, создавая новый узел дерева, в котором они оба будут потомками, а приоритет нового узла будет равен сумме их приоритетов. После этого мы добавим получившийся новый узел обратно в очередь.
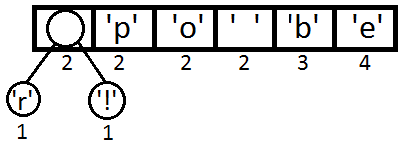
Повторим те же шаги и получим последовательно: 
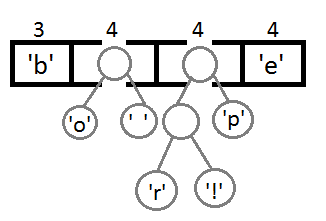
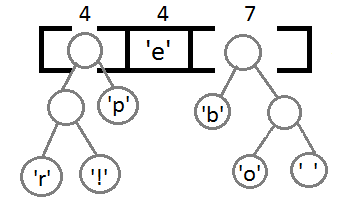
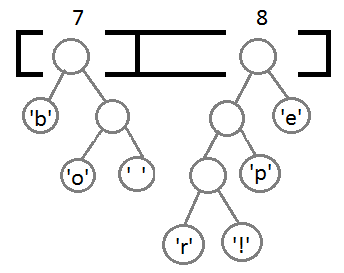
Ну и после того, как мы свяжем два последних элемента, получится итоговое дерево: 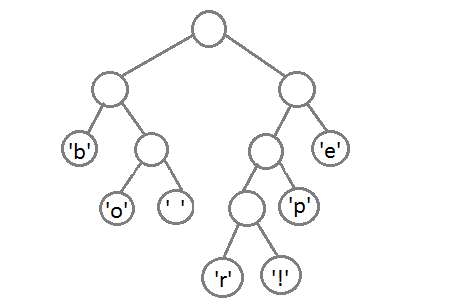
Теперь, чтобы получить код для каждого символа, надо просто пройтись по дереву, и для каждого перехода добавлять 0, если мы идём влево, и 1 — если направо:
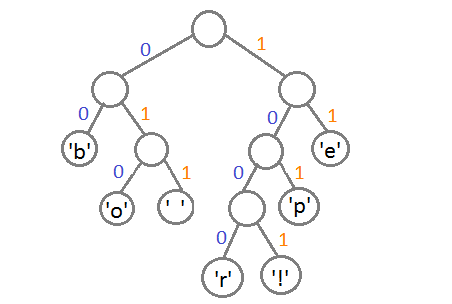
Если мы так сделаем, то получим следующие коды для символов:
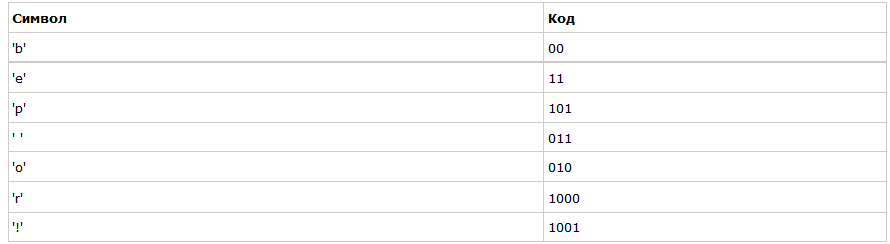
Чтобы расшифровать закодированную строку, нам надо, соответственно, просто идти по дереву, сворачивая в соответствующую каждому биту сторону до тех пор, пока мы не достигнем листа. Например, если есть строка «101 11 101 11» и наше дерево, то мы получим строку «pepe».
Важно иметь в виду, что каждый код не является префиксом для кода другого символа. В нашем примере, если 00 — это код для „b“, то 000 не может оказаться чьим-либо кодом, потому что иначе мы получим конфликт. Мы никогда не достигли бы этого символа в дереве, так как останавливались бы ещё на „b“.
Источник



