
- Способ определения размера кластера
- Определение объёма кластера Elasticsearch и тестирование производительности в Rally
- Аппаратные ресурсы кластера Elasticsearch
- Хранилище
- Память
- Процессор
- Сайзинг кластера Elasticsearch по объёму хранения
- Пример расчёта малого кластера
- Пример расчета крупного кластера
- Тесты производительности
- Индексирование
- Поиск
- Как узнать размер кластера диска?
- Что такое кластер диска?
- Какой размер кластера поддерживает система?
Способ определения размера кластера
Как определить размер кластера?
Если вы хоть раз углублялись в изучение операционных систем, то непременно сталкивались со словом «кластер», которое означает вполне определённую величину, представляющую собой размер той или иной ячейки, где хранятся файлы. Данный размер прямо пропорционален памяти носителя.
Итак, если вы задались вопросом, узнать, каков же размер кластеров – ячеек на жёстком диске, то кроме ОС Windows и собственного терпения больше ничего не понадобиться.
Известно, что данная величина формируется вполне определённым образом . Её размер во время форматирования жёсткого диска, задаёт сама программа, имеющая одинаковые алгоритмы для каждой из задействованных утилит. К примеру, у носителя информации объёмом не более 1Гб, кластеры – до 1Кб, соответственно, у 4Гб носителя – 4Кб и так далее.
Но не всегда стоить верить данным сводных таблиц программы форматирования. В процессе конвертирования из файловых систем у кластера будет тот размер, который стандартен для файловой системы результирующей. К примеру, если происходит конвертирование жесткого диска с системы FAT32 в систему NTFS объём ячеек, хранящих информацию, имеет 512байт.
Вы можете определить размер кластера несколькими методами, при этом, не пользуясь дополнительным программным обеспечением. И таким методом можно назвать манипуляцию по проверке состояния процесса дефрагментации разделов – системного и пр. Для этого, открыв меню кнопки «Пуск» пройдитесь в «Панель управления». Откроется окошко, в котором двойным щелчком мышки откройте иконку «Администрирование».
Снова появится окошко, в котором будет ярлычок «Управление компьютером» и теперь откройте раздел «Хранение данных». Данный блок позволяет запустить процесс «Дефрагментация диска», что и нужно вам сделать.
Теперь активируйте кнопку «Анализ» и, спустя пару мгновений, начнётся сканирование выбранного вами раздела в жёстком диске в автоматическом режиме. Затем нажмите значок «Вывести отчет», который даст возможность подробно просмотреть информацию состояния вашего жёсткого диска в высветившемся окошке, где есть строчка «Размер кластера». В данном примере искомое значение – 4Кб, и, соответственно, системный раздел имеет объём около 12Гб.
Для сохранения найденной информации о разделе, нажмите значок «Сохранить как». Откроется окошко, где нужно будет выбрать каталог сохранения, теперь назовите сохраняемый вами файл и клавишей Enter подтвердите своё действие.
Источник
Определение объёма кластера Elasticsearch и тестирование производительности в Rally
В этой статье мы разберёмся с основными подходами к сайзингу Elasticsearch, покажем сравнения бенчмарков кластера при загрузке логов и метрик. А разница там заметная. Надеемся, вам это поможет с определением объёма кластера Elasticsearch и расшифровкой того самого «it depends».

В некотором роде, эта статья является продолжением нашей статьи о сайзинге на Хабре. Но здесь появились примеры из реальной жизни, поэтому если есть потребность в некоей преемственности, начните с той статьи, а уж потом возвращайтесь сюда. Под катом все подробности.
Материалы этой статьи основаны на публикации Benchmarking and sizing your Elasticsearch cluster for logs and metrics в блоге Elastic. Мы её немного доработали и выкинули примеры с облачным Elastic.
Аппаратные ресурсы кластера Elasticsearch
Производительность кластера Elasticsearch зависит в основном о того как вы его используете и что под ним работает (в смысле аппаратное обеспечение). Аппаратное обеспечение характеризуется следующим:
Хранилище
Вендор рекомендует использовать SSD везде где это только возможно. Но, очевидно, что возможно это не везде, поэтому к вашим услугам архитектура hot-warm-cold и Index Lifecycle Management (ILM).
Elasticsearch не требует избыточного хранилища (можно обойтись без RAID 1/5/10), сценарии хранения журналов или метрик обычно имеют по крайней мере одну реплику, что обеспечивает минимальную отказоустойчивость.
Память
Память на сервере делится на:
JVM Heap. Хранит метаданные о кластере, индексах, сегментах, сегментах и данных полей документов. В идеале стоит на это выделить 50% доступной оперативной памяти.
Кэш ОС. Elasticsearch будет использовать оставшуюся доступную память для кэширования данных, что заметно повысит производительность за счет предотвращения чтений с диска во время полнотекстового поиска, агрегирования значений документов и сортировки. И не забудьте отключить swap (файл подкачки), чтобы избежать сброса содержимого оперативной памяти на диск и последующее чтение с него (это медленно!).
Процессор
Узлы Elasticsearch имеют т.н. thread pools (пулы потоков) и thread queues (очереди потоков), которые используют доступные вычислительные ресурсы. Количество и производительность ядер CPU определяют среднюю скорость и пиковую пропускную способность операций с данными в Elasticsearch. Чаще всего это 8−16 ядер.
Производительность сети — пропускная способность (bandwidth), так и время задержки (latency) могут заметно влиять на связь между нодами Elasticsearch и взаимодействие между кластерами Elasticsearch. Обратите внимание, что по умолчанию проверка доступности нод выполняется каждую секунду и если в течении 30 секунд нода не пингуется, она помечается как недоступная и выключается из кластера.
Сайзинг кластера Elasticsearch по объёму хранения
Хранение логов и метрик обычно требует значительного дискового пространства, поэтому стоит использовать количество этих данных для первоначального определения размера нашего кластера Elasticsearch. Ниже несколько вопросов для понимания структуры данных, которыми нужно управлять в кластере:
- Сколько необработанных данных (ГБ) будем индексировать в день?
- Сколько дней будем хранить данные?
- Сколько дней в горячей зоне?
- Сколько дней в теплой зоне?
- Сколько реплик будет использоваться?
Сверху желательно накинуть 5% или 10% и чтобы в запасе всегда оставалось 15% свободного места от общего дискового объёма. Теперь попробуем это дело сосчитать.
Общий объем данных (ГБ) = Количество сырых данных в день (Гб) * Количество дней хранения * (Количество реплик + 1).
Общий объем хранилища (ГБ) = Общий объем данных (ГБ) * (1 + 0.15 запаса дискового пространства + 0.1 дополнительного резерва).
Общее количество нод данных = ОКРВВЕРХ (Общий объем данных (ГБ) / Объём памяти на ноду данных / Соотношение память: данные). В случае крупной инсталляции лучше держать в запасе ещё одну дополнительную ноду.
Elastic рекомендует следующие соотношения память: данные для различных типов нод: «горячие» → 1:30 (30 Гб дискового пространства на каждый гигабайт памяти), «тёплые» → 1:160, «холодные» → 1:500). ОКРВВЕРХ — окружение до ближайшего большего целого числа.
Пример расчёта малого кластера
1 ГБ данных, которые нужно хранить 9 месяцев.
Общий объем данных (ГБ) = 1 ГБ x (9 месяцев x 30 дней) x 2 = 540 ГБ
Общий объем хранилища (ГБ) = 540 ГБ x (1+0.15+0.1) = 675 ГБ
Общее количество нод данных = 675 ГБ / 8 ГБ ОЗУ / 30 = 3 ноды.
Пример расчета крупного кластера
Вы получаете 100 ГБ в день, будете хранить эти данные 30 дней в горячей зоне и 12 месяцев в теплой зоне. У вас есть 64 ГБ памяти на каждый узел, из которых 30 ГБ выделено для JVM Heap, а оставшаяся часть — для кэш-памяти ОС. Рекомендуемое соотношение память: данные для горячей зоны 1:30, для теплой — 1: 160.
Итого, если вы получаете 100 ГБ в день и должны хранить эти данные в течение 30 дней, получим:
Общий объем данных (ГБ) в горячей зоне = (100 ГБ x 30 дней * 2) = 6000 ГБ
Общий объем хранилища (ГБ) в горячей зоне = 6000 ГБ x (1 + 0,15 + 0,1) = 7500 ГБ
Общее количество нод данных в горячей зоне = ОКРВВЕРХ (7500/64/30) + 1 = 5 узлов
Общий объем данных (ГБ) в теплой зоне = (100 ГБ x 365 дней * 2) = 73 000 ГБ
Общий объем хранилища (ГБ) в теплой зоне = 73 000 ГБ x (1 + 0,15 + 0,1) = 91 250 ГБ
Общее количество узлов данных в теплой зоне = ОКРВВЕРХ (91 250/64/160) + 1 = 10 узлов
Таким образом, получили 5 узлов под горячую зону и 10 узлов плод теплую. Для холодной зоны аналогичные расчеты, но коэффициент память: данные уже будет 1:500.
Тесты производительности
Когда размер кластера определен, нужно подтвердить, что математика работает в реальных условиях.
Для этого теста используется тот же инструмент, который используют инженеры Elasticsearch — Rally. Он прост в развертывании и запуске и полностью настраивается, поэтому можно тестировать несколько сценариев (треков).
Чтобы упростить анализ результатов, тест делится на два раздела: индексирование и поисковые запросы. Для тестов будут использоваться данные из треков Metricbeat и логов веб-сервера.
Индексирование
Тестирование отвечает на следующие вопросы:
- Какова максимальная пропускная способность индексирования кластеров?
- Какой объем данных можно индексировать за день?
- Кластер больше или меньше подходящего размера?
Для этого теста используется кластер из 3 узлов со следующей конфигурацией для каждого узла:
Набор данных, используемый для теста, представляет собой данные Metricbeat со следующими характеристиками:
- 1 079 600 документов;
- Объем данных: 1,2 ГБ;
- Средний размер документа: 1,17 КБ.
Далее будет несколько тестов, чтобы определить оптимальный размер пакета и оптимальное количество потоков (threads).
Всё начинается с 1 клиента Rally для нахождения оптимального размера пакета. Первоначально, загружаются 100 документов, затем их количество увеличивается вдвое при последующих запусках. Результатом будет оптимальный размер пакета в размере 12 000 документов (это около 13,7 МБ). При дальнейшем росте размера пакета производительность начинает падать.
Затем, используя аналогичный метод, обнаруживается, что 16 — оптимальное количество клиентов, что позволяет достигать обработки 62 000 событий, индексируемых за секунду.
Итого, кластер без потери производительности может обрабатывать максимально 62 000 событий в секунду. Чтобы увеличить это количество, нужно будет добавить новый узел.
Ниже тот же самый тест с пакетом из 12 000 событий, но для сравнения приведены данные пропускной способность при наличии 1 ноды, 2 и 3 нод.
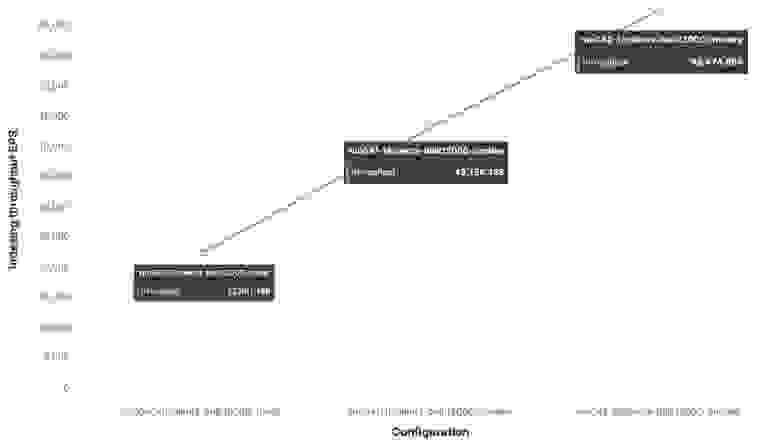
Для тестовой среды максимальная пропускная способность индексации составит:
- С 1 нодой и 1 шардом индексировалось 22 000 событий в секунду;
- С 2 нодами и 2 шардами индексировалось 43 000 событий в секунду;
- С 3 нодами и 3 шардами индексировалось 62 000 событий в секунду.
Любой дополнительный запрос на индексирование будет помещен в очередь, и когда она заполнится, нода ответит отклонением запроса на индексирование.
Обращаем внимание, что набор данных влияет на производительность кластера, поэтому важно выполнять треки Rally с вашими собственными данными.
Тест индексирования № 2
Для следующего шага будут использоваться треки с данными лога HTTP-сервера со следующей конфигурацией:
- 247 249 096 документов;
- Объем данных: 31,1 ГБ;
- Средний размер документа: 0,8 КБ.
Оптимальный размер пакета — 16 000 документов.
Оптимальное количество клиентов — 32.
Соответственно, максимальная пропускная способность индексирования в Elasticsearch — 220 000 событий в секунду.
Поиск
Пропускная способность поиска будет оцениваться при условии использования 20 клиентов и 1000 операций в секунду. Для поиска будет выполнено три теста.
Сравнивается время обслуживания (а точнее 90 процентиль) для набора запросов.
Набор данных из Metricbeat:
- Агрегированная гистограмма дат с автоматическим интервалом (auto-date-historgram);
- Агрегированная гистограмма дат с таймзоной с автоматическим интервалом (auto-date-histogram-with-tz);
- Агрегированная гистограмма дат (date-histogram);
- Агрегированная гистограмма дат с таймзоной (date-histogram-with-tz).
Можно заметить, что запрос auto-date-histogram-with-tz имеет наибольшее время обслуживания в кластере.
Набор данных из лога HTTP-сервера:
- Default;
- Term;
- Range;
- Hourly_agg;
- Desc_sort_timestamp;
- Asc_sort_timestamp.
Можно заметить, что запросы desc_sort_timestamp и desc_sort_timestamp имеют более длительное обслуживания.
Теперь разберемся с параллельными запросами. Посмотрим, как время обслуживания на 90 процентиле увеличится, если запросы будут выполняться параллельно.
Рассмотрим скорость индексирования и время обслуживания поисковых запросов при наличии параллельного индексирования.
Выполним задачу параллельного индексирования и поиска, чтобы увидеть скорость индексации и время обслуживания запросов.
Посмотрим, как время обслуживания запросов на 90 процентиле увеличилось при выполнении поиска параллельно с операциями индексации.
Итого имея 32 клиента для индексации и 20 пользователей для поиска:
- Пропускная способность индексации 173 000 событий в секунду, что меньше 220 000, полученных в предыдущих экспериментах;
- Пропускная способность поиска 1000 событий в секунду.
Rally — мощный инструмент для бенчмаркинга, но использовать его стоит только с теми данными, которые в дальнейшем будут также литься в продакшен.
Мы разработали обучающий курс по основам работы с Elastic Stack, который адаптируется под конкретные потребности заказчика. Подробная программа обучения по запросу.
Приглашаем зарегистрироваться на День Эластика в России и СНГ 2021, который пройдёт онлайн 3 марта с 10 до 13 часов.
Источник
Как узнать размер кластера диска?
Что такое кластер диска?
Какой размер кластера лучше выбрать при форматировании жесткого диска?. При форматировании флешки или жёсткого диска предлагает установить размер кластера.
Простой пример.
Вам нужно расфасовать крупу 128 кг. по мешочкам.
Если брать мешочки по 4 килограмма, тогда вам понадобится 32 мешочков. Если взять мешки по 64 кг, тогда вам нужно всего 2.
Получается, нам быстрее загрузить\выгрузить в машину 2 мешка по 64 кг, вместо 32 штук по 4 кг.
Также и с файлами. Диску быстрее будет прочитать крупный файл, разбитый на сектора по 64 Кбайт, чем, если бы он был разбит на сектора по 4 Кбайт.
Есть и другая сторона.
У вас имеются файлы по 30 Кбайт, тогда каждый из них будет занимать сектор по 64 Кбайта, из которых 34 Кбайта потратятся в холостую. Если же сектор будет по 4 Кбайта, тогда 4 Кбайте*8 = 32 Кбайт – 30 Кбайт фала = 2 Кбайта холостого места. 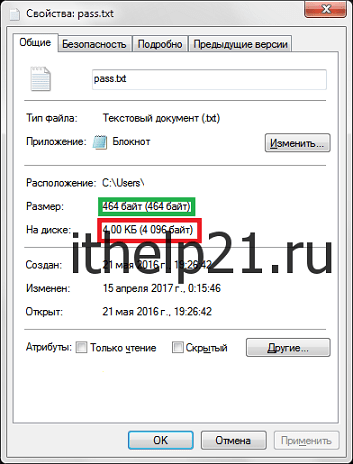
Какой размер кластера поддерживает система?
Прикинув оптимальный размера кластера посмотрим, какие размеры поддерживает операционная система на примере Windows 7:
1. В командной строке вводим команду:
2. Смотрим список томов:
3. Выбираем необходимый том:
4. Смотрим информацию по размеру кластера:
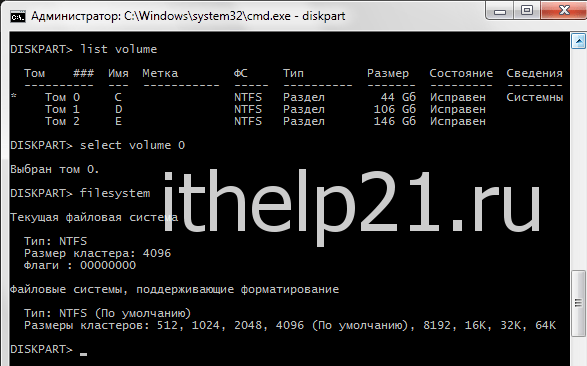
Как видно, у меня есть поддержка размеров кластеров от 512 до 64К.
Текущей размер – 4 Кбайт.
Источник



