
- Немного о методах машинного обучения
- Обучение с частичным привлечением учителя
- Обучение с подкреплением
- Обучение с частичным привлечением учителя
- Содержание
- Определение [ править ]
- Основная идея [ править ]
- Постановка задачи обучения [ править ]
- Основные предположения, используемые SSL [ править ]
- Предположение плавности (Smoothness Assumption) [ править ]
- Предположение кластеризованности (Cluster Assumption) [ править ]
- Предположение избыточности (Manifold Assumption) [ править ]
- Подходы к решению задачи [ править ]
- Самообучение (Self Training) [ править ]
- Совместное обучение (Co-training) [ править ]
- Генеративные модели [ править ]
- Полуавтоматические опорные вектора (S3VM) [ править ]
- Алгоритмы на основе графов [ править ]
Немного о методах машинного обучения
Ранее мы уже рассматривали концепцию и некоторые особенности машинного обучения – с учителем и без. Сегодня речь пойдет о более частных случаях – методах обучения с частичным привлечением учителя (Semi-supervised learning) и обучения с подкреплением (Reinforcement learning). Собеседником DataReview и экспертом в данной области выступил Сергей Шельпук, директор направления Data Science в компании V.I.Tech, преподаватель курса Machine Learning в школе Lviv IT School (LITS).
Обучение с частичным привлечением учителя
Semi-supervised learning — это способ использовать неразмеченные (unlabeled) данные для того, чтобы повысить точность модели. Такое обучение предполагает использование для каждого прецедента как пар «ситуация-решение», так и просто набор ситуаций. Говоря простым языком, в данном случае сочетаются элементы машинного обучения обоих видов.
Сергей Шельпук:
Идея такая: если у нас есть какое-то небольшое количество размеченных данных и намного большее количество неразмеченных, мы можем сначала обучить модель на размеченной выборке (обучение с учителем), а потом использовать эту обученную модель, чтобы предсказать с ее помощью класс (или значение) для неразмеченных данных. Потом — снова обучаем модель с учителем, используя предсказанные значения для неразмеченных данных, как «правильный ответ». Потом — снова предсказываем значения для неразмеченных данных уже с новой моделью, и так по кругу.
Для чего же нужны такие «выкрутасы»? Понятно, что идеальная структура данных возможна только в теории; на практике же жизненно необходимо повышать точность модели – как раз для того, чтобы успешно работать с неидеальными данными. Применяя метод машинного обучения с частичным привлечением учителя, мы можем (по крайней мере, теоретически) повысить точность модели благодаря использованию так называемых неразмеченных (unlabeled) данных. Самый простой пример – фотографии в социальных сетях, когда пользователь не отмечает присутствующих на них людей или место съемок, то есть – не присваивает им теги (labels).
Для работы машинного обучения с частичным привлечением учителя необходимо, таким образом, две выборки – размеченная и неразмеченная, причем обе выборки должны содержать данные из одних и тех же классов.
Сергей Шельпук:
Недостатком этого метода является то, что наша неразмеченная выборка должна содержать только те же самые классы, что и размеченная. Иными словами, если в размеченной выборке у нас фотографии мотоциклов и машин, и мы знаем, на какой картинке что, то в неразмеченной тоже должны быть только мотоциклы и машины, только мы не знаем, что из них где.
В теории такая постановка задачи работает, однако в реальной жизни с данными «везет» значительно реже.
Сергей Шельпук:
Сейчас нам всем доступны огромные массивы неразмеченных данных (фотографии на Facebook, видео на YouTube, аудио на SoundCloud и т.д.), но среди них есть далеко не только те классы, которые нужны для нашей задачи. Потому машинное обучение с частичным привлечением учителя практически ничем не может помочь в плане использования таких массивов данных для улучшения наших моделей. Вместо него для этого мы используем методы глубокого обучения и обучения без учителя на основе сырых данных репрезентативных выборок (unsupervised feature learning).
Обучение с подкреплением
Reinforcement learning — способ обучать марковские процессы принятия решений (markov decision process) и решать задачи управления. Здесь вместо ответа на вопрос: «Какой это класс?» или «Какое это значение?» мы пытаемся ответить на вопрос: «Что нужно сделать, чтобы достичь желаемого результата?».
В ходе обучения с подкреплением система (агент) обучается, взаимодействуя с некоей средой. Откликом среды на принятые решения являются так называемые сигналы подкрепления – это позволяет назвать такую методологию частным случаем обучения с учителем, однако в роли последнего выступает среда или ее модель, при этом между ней и агентом существует обратная связь.
В общем-то, такая модель (как минимум, на первый взгляд) похожа на то, как работает человеческий мозг при принятии некоего решения. Это позволяет с успехом использовать методологию в самых разных областях знаний – от аэрокосмической сферы и до управления электрическими сетями и даже… лифтами – когда необходимо решить, на каком этаже должна стоять кабинка, чтобы люди потратили на ее ожидание как можно меньше времени.
Сергей Шельпук:
Одним из самых известных достижений этого вида машинного обучения был роботизированный вертолет, разработанный в Стэнфорде. В нашем стартапе QRhythm мы используем обучение с подкреплением для того, чтобы управлять облачной инфраструктурой, делать ее использование максимально надежным и максимально дешевым одновременно.
Перед машинным обучением всегда стояли высокие цели – как научные, так и практические. С точки зрения анализа данных, машинное обучение, прежде всего, призвано делать модели все более и более точными – и, к сожалению, идеального решения «на все случаи жизни» не существует.
Сегодня мы рассказали вам о двух методологиях, существование которых только подтверждает этот факт – впрочем, опыт подсказывает нам, что разнообразие в конечном итоге приводит к прогрессу; в случае машинного обучения в это можно – и нужно – верить.
Источник
Обучение с частичным привлечением учителя
Содержание
Определение [ править ]
| Определение: |
| Обучение с частичным привлечением учителя (англ. semi-supervised learning, SSL) — разновидность обучения с учителем, которое помимо размеченных данных для обучения также использует неразмеченные данные — обычно в сравнительно большем количестве, чем размеченные. |
Основная идея [ править ]
Обучение с частичным привлечением учителя занимает промежуточное положение между обучением с учителем и без учителя. Когда получение достаточного количества размеченных данных затруднено (например, когда при разметке данных привлекаются дорогостоящие устройства или квалифицированные лица), помимо размеченных данных можно также задействовать и неразмеченные данные для построения более эффективных моделей, по сравнению с моделями, построенными с полным участием учителя или без него вовсе.
Постановка задачи обучения [ править ]
- Множество данных $X = \
- Размеченные данные вида $(X_l, Y_l) = \<(x_<1:l>, y_<1:l>)\>$
- Множество неразмеченных данных $X_u = \
- Как правило, $l \ll n$
- Множество неразмеченных данных $X_
= \
- Найти решающую функцию $a: X → Y$, где при нахождении функции подразумевается применение как $(X_l, Y_l)$, так и $X_u$.
Основные предположения, используемые SSL [ править ]
Как и обучение с учителем, SSL также использует некоторые предположения на этапе распределения неразмеченных данных. Без них не представляется возможным обобщение алгоритма, решающего задачу лишь на одном конечном тестовом множестве данных, на потенциально бесконечное множество последующих тестовых наборов данных.
Предположение плавности (Smoothness Assumption) [ править ]
Smoothness Assumption — две точки $x_1$, $x_2$ в области высокой плотности, лежащие близко друг от друга, с большей вероятностью имеют одинаковые метки $y_1$, $y_2$.
Более того, исходя из транзитивности, если две точки связаны между собой точками из области высокой плотности (например, принадлежат одному кластеру), то они также, вероятно, размечены одинаково. С другой стороны, предположение даёт преимущество для разграничения в регионах с низкой плотностью, там где меньше близко разположенных точек, но больше вероятность принадлежности к разным классам.
Предположение кластеризованности (Cluster Assumption) [ править ]
Допустим, что данные каждого из класса образуют кластеры. Если использовать алгоритм кластеризации, используя размеченные данные для присвоения меток кластерам, тогда неразмеченные данные могут быть полезны в более точном нахождении границ этих кластеров.
Cluster Assumption — две точки $x_1$, $x_2$ из одного кластера с большей вероятностью имеют одинаковые метки $y_1$, $y_2$.
Предположение обосновывается на явном существовании классов: если существует плотный континуум объектов, маловероятно, что он будет разделён на разные классы. Следует отметить, что предположение не подразумевает формирования одного компактного кластера одним классом, но и не рассматривает два объекта разных классов в одном кластере.
Предположение избыточности (Manifold Assumption) [ править ]

Manifold Assumption — избыточность данных высокой размерности способствует понижению размерности.
Это предположение применимо, когда измерения данных избыточны, то есть генерируются определенным процессом, имеющим только несколько степеней свободы. Иначе говоря, вместо использования предположения, что данные могут представлять из себя любые объекты из многомерного пространства (например, множество из всех возможных изображений размером 1 мегапиксель, включая белый шум), легче представить эти данные в пространстве более низкой размерности, исключая разными способами конфигурации пикселей, которые не характерны для конкретных данных. В этом случае неразмеченные данные позволяют изучить генерирующий процесс и за счёт этого снизить размерность, что упрощает, например, привязку предположения плавности.
Рассмотрим задачу обнаружения признаков на примере перцепции. Множество двухмерных отображений трёхмерного объекта со всех возможных углов обзора имеет весьма высокую размерность, будучи представленным в виде массивов изображений в памяти вычислительной машины; чёрно-белые картинки размером 32×32 пикселя можно понимать как точки 1024-мерного пространства углов обзора (пространство входных данных). Более значимая для перцепции структура (пространство признаков), однако, может гораздо более низкую размерность: эти же изображения могут лежать в 2-мерном многообразии, параметризованном с помощью углов обзора (см. иллюстрацию).
Другим примером задач, когда естественные данные являются избыточными, является векторное представление слов и обработка естественного языка.
Подходы к решению задачи [ править ]
Самообучение (Self Training) [ править ]
1. Обучить $f$ с помощью $(X_l, Y_l)$
2. Спрогнозировать $x \in X_u$
3. Добавить $(x, f(x))$ к размеченным данным
4. Повторить
Алгоритм основан на предположении, что достоверные прогнозы, формируемые на шаге 2 — верны.
- Добавление нескольких наиболее достоверных $(x, f(x))$ к размеченным данным
- Добавление всех $(x, f(x))$ к размеченным данным
- Добавление всех $(x, f(x))$ к размеченным данным, взвешивание достоверности каждого $x$
- Наиболее простой метод semi-supervised обучения
- Метод может быть обёрткой для более сложных алгоритмов классификации
- Часто используется в прикладных задачах, таких как обработка естественного языка
- Негативное влияние ошибочных прогнозов усиливается с обучением. В таком случае существуют эвристические решения, например «удаление» метки с объекта, достоверность прогноза которого оказалась ниже определённого порога
- Трудно достичь сходимости алгоритма.
Однако, существуют частные случаи, когда самообучение эквивалентно работе EM-алгоритма, например его модификация под байесовский классификатор, использующий неразмеченные данные. Также у задач, использующих некоторые классы функций (например, линейные), существуют решения в виде сходящегося алгоритма.
Совместное обучение (Co-training) [ править ]
Совместное обучение является расширением самообучения, при котором несколько классификаторов прорабатывают разные (в идеале, непересекающиеся) множества признаков и генерируют размеченные примеры друг для друга.
Разделение признаков (feature split)
Метод совместного обучения предполагает, что каждый объект имеет два множества признаков $x = [x^<(1)>; x^<(2)>]$, разделение между которыми может быть как естественным, так и искусственным. Примером объекта с естественным разделением признаков может послужить веб-страница, содержащая текст и изображения. Два независимых классификатора обучаются по двум множествам признаков: первый анализирует текст, второй — изображения.
Предположения, используемые в совместном обучении
- Естественное разделение признаков $x = [x^<(1)>; x^<(2)>]$ существует
- $x^<(1)>$ и $x^<(2)>$ таковы, что по-отдельности могут обучить хороший классификатор
- множества $x^<(1)>$ и $x^<(2)>$ являются условно независимыми при фиксированном классе
1. Обучить два классификатора: $f^<(1)>$ с помощью $(X_l^<(1)>, Y_l)$, $f^<(2)>$ с помощью $(X_l^<(2)>, Y_l)$
2. Классифицировать множество $X_u$ с $f^<(1)>$ и $f^<(2)>$ независимо
3. Добавить $k$ наиболее достоверных прогнозов $(x, f^<(1)>(x))$ из $f^<(1)>$ к данным, размеченным с помощью $f^<(2)>$
4. Добавить $k$ наиболее достоверных прогнозов $(x, f^<(2)>(x))$ из $f^<(2)>$ к данным, размеченным с помощью $f^<(1)>$
5. Повторить
- Подходит почти ко всем известным классификаторам в качестве обёртки
- Не так сильна чувствительность к ошибочным прогнозам, по сравнению с self-training
- Естественное разделение признаков не всегда существует. В таком случае можно использовать fake feature split — случайное искуственное разделение
- Необхоимо искать эффективные модели, когда приходится использовать признаки из нескольких множеств
Генеративные модели [ править ]
Генеративные модели в полуавтоматическом обучении можно рассматривать как расширение обучения с учителем (классификация и информация о $p(x)$, или как расширение обучения без учителя (кластеризация и некоторые метки). Основное предположение генеративных моделей заключается в том, что распределения принимают форму $p(x|y, \theta)$, параметризованную вектором $\theta$.
- Интересующая величина: $p(X_l, Y_l, X_u|\theta) = \sum_
p(X_l, Y_l, X_u, Y_u|\theta)$ - Найти для $\theta$ оценку максимального правдоподобия, оценить апостериорный максимум или использовать теорему Байеса.
Пример генеративной модели
Параметры модели: $\theta = \big<\<>w_1, w_2, \mu_1, \mu_2, \sum_1, \sum_2\big<\>>$
$p(x, y|\theta) = p(y|\theta)p(x|y,\theta) = w_yN\big(x;\mu_y,\sum_y\big)$
Разберём пример двоичной классификации с использованием принципа максимального правдоподобия (MLE).
Размеченные данные имеют вид
$\log p(X_l, Y_l|\theta) = \sum\limits_^l \log p(y_i|\theta)p(x_i|y_i, \theta)$
Здесь в качестве оценки MLE для $\theta$ возьмём тривиальные величины: частота, выборочное среднее, выборочная ковариация.
Размеченные и неразмеченные данные:
$\log p(X_l, Y_l, X_u|\theta) = \sum\limits_^l \log p(y_i|\theta)p(x_i|y_i, \theta) + \sum\limits_^
Теперь, с появлением скрытых переменных, оценка MLE теряет тривиальность, однако для поиска локального оптимума можно использовать EM-алгоритм.
Достоинства генеративных моделей
- Гереативные модели очень эффективны, если составленная модель близка к правильной
- Трудно определить корректность модели
- Неразмеченные данные могут навредить при использовании неверной генеративной модели
Полуавтоматические опорные вектора (S3VM) [ править ]
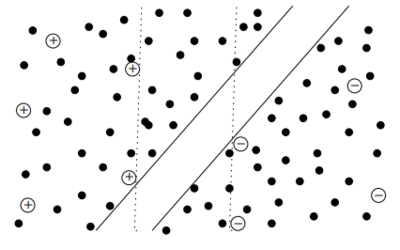
Полуавтоматические SVM (англ. Semi-supervised SVMs, S3VMs), они же трансдуктивные SVM (TSVMs) решают задачу максимизации зазора (margin) между неразмеченными данными.
- Перечислить все $2^u$ возможные способы разметки множества $X_u$
- Построить стандартную SVM для каждой разметки (и для $X_l$)
- Взять SVM с наибольшим зазором
- Два класса $y \in \<+1, -1\>$
- Размеченные данные $(X_l, Y_l)$
- Ядро $K$
- Гильбертово пространство функций $H_K$ (RKHS)
С помощью SVM найти функцию $f(x)=h(x)+b$, где $h \in H_K$ и классифицировать $x$ с помощью $sign(f(x))$
1. Входные данные: ядро $K$, веса $\lambda_1, \lambda_2, (X_l, Y_l), X_u$ 2. Решим задачу оптимизации для $f(x) = h(x) + b, h(x) \in H_K$
$
такую, что $\frac<1>
4. Классифицируем новый объект $x$ из тестового множества, используя $sign(f(x))$
- Применимо везде, где применимы классические SVM
- Трудности в оптимизации
- Алгоритм может сходиться к неправильной (плохой) целевой функции
- Менее мощный подход, по сравнению с алгоритмами на графах и генеративными моделями, т. е. потенциально менее эффективное обучение
Алгоритмы на основе графов [ править ]
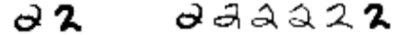
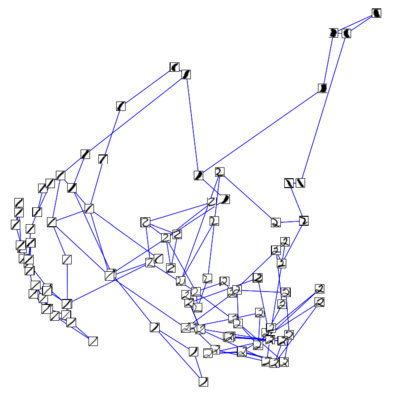
Данные можно представить в виде графа, построенного с использованием знаний в предметной области или на основе сходства объектов.
- Вершины $X_l \cup X_u$
- Рёбра, вычисленные исходя из признаков, например
- $k$ ближайших соседей
- Полный граф, веса рёбер которого убывают с расстоянием, $w = exp(-\|x_i — x_j\|^2/\sigma^2)$
Найти сходство по всем путям.
Регуляризация избыточности
1. Входные данные: ядро $K$, веса $\lambda_1, \lambda_2, (X_l, Y_l), X_u$
2. Построим граф сходств $W$ из вершин $X_l, X_u$, вычислим Лапласиан графа $\Delta$
3. Решим задачу оптимизации для $f(x) = h(x) + b, h(x) \in H_K$
$
4. Классифицируем новый объект $x$ из тестового множества, используя $sign(f(x))$
Графы, формирующиеся в процессе обучения, как правило, достаточно объёмны для графического отображения и человеческого восприятия. Для большей ясности рассмотрим множество данных, состоящее только из рукописных цифр «1» и «2». Критерием сходства объектов послужит евклидово расстояние, которое бывает особенно полезно при поиске локального сходства. Если такое расстояние между объектами достаточно мало, мы можем предположить, что объекты принадлежат одному классу. На основе расстояния можно построить KNN-граф (см. иллюстрацию), где объекты с малым евклидовым расстоянием будут соединены рёбрами. Чем больше имеется неразмеченных данных, схожих с размеченными (см. пример с цифрой «2»), тем больше соотвествующих рёбер, и, следовательно, более высокая точность классификации.
Достоинства алгоритмов на графах
- Ясный математический аппарат
- Высокая эффективность, когда граф соответствует задаче
- Можно использовать ориентированные графы
- Низкая эффективность при плохом построении графа
- Зависимость от структуры графа и весов рёбер
Источник



