
Способ измерения хранимого или передаваемого кода
Урок 5. Измерение информации. Количество информации как мера уменьшения неопределенности знаний. Алфавитный подход к определению количества информации
Измерение информации. Алфавитный подход
 |  | ||||
 |  | ||||


 В двоичном коде каждая двоичная цифра несет одну единицу информации, которая называется 1 бит.
В двоичном коде каждая двоичная цифра несет одну единицу информации, которая называется 1 бит.

 Более крупной, чем бит, единицей измерения информации является байт: 1 байт = 8 битов.
Более крупной, чем бит, единицей измерения информации является байт: 1 байт = 8 битов.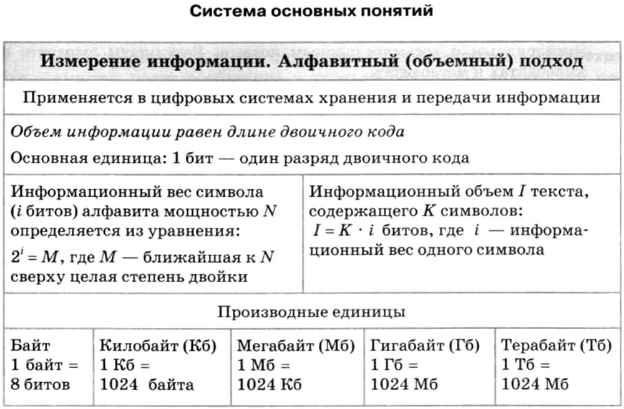
 |  |
|
| |
 |  |
|
Вопрос об измерении количества информации является очень важным как для науки, так и для практики. В самом деле, если информация является предметом нашей деятельности, мы ее храним, передаем, принимаем, обрабатываем. Поэтому важно договориться о способе ее измерения, позволяющем, например, ответить на вопросы: достаточно ли места на носителе, чтобы разместить нужную нам информацию, или сколько времени потребуется, чтобы передать ее по имеющемуся каналу связи. Величина, которая нас в этих ситуациях интересует, называется объемом информации. В таком случае говорят об алфавитном, или объемном, подходе к измерению информации. Алфавитный подход к измерению информации применяется в цифровых (компьютерных) системах хранения и передачи информации. В этих системах используется двоичный способ кодирования информации. При алфавитном подходе для определения количества информации имеет значение лишь размер (объем) хранимого и передаваемого кода. Алфавитный подход еще называют объемным подходом. Из курса информатики 7-9 классов вы знаете, что если с помощью i-разрядного двоичного кода можно закодировать алфавит, состоящий из N символов (где N — целая степень двойки), то эти величины связаны между собой по формуле: 2 i = N. Число N называется мощностью алфавита. Если, например, i = 2, то можно построить 4 двухразрядные комбинации из нулей и единиц, т. е. закодировать 4 символа. При i = 3 существует 8 трехразрядных комбинаций нулей и единиц (кодируется 8 символов): Английский алфавит содержит 26 букв. Для записи текста нужны еще как минимум шесть символов: пробел, точка, запятая, вопросительный знак, восклицательный знак, тире. В сумме получается расширенный алфавит мощностью в 32 символа. Поскольку 32 = 2 5 , все символы можно закодировать всевозможными пятиразрядными двоичными кодами от 00000 до 11111. Именно пятиразрядный код использовался в телеграфных аппаратах, появившихся еще в XIX веке. Телеграфный аппарат при вводе переводил английский текст в двоичный код, длина которого в 5 раз больше, чем длина исходного текста.
Длина двоичного кода, с помощью которого кодируется символ алфавита, называется информационным весом символа. В рассмотренном выше примере информационный вес символа расширенного английского алфавита оказался равным 5 битам. Информационный объем текста складывается из информационных весов всех составляющих текст символов. Например, английский текст из 1000 символов в телеграфном сообщении будет иметь информационный объем 5000 битов. Алфавит русского языка включает 33 буквы. Если к нему добавить еще пробел и пять знаков препинания, то получится набор из 39 символов. Для двоичного кодирования символов такого алфавита пятиразрядного кода уже недостаточно. Нужен как минимум 6-разрядный код. Поскольку 2 6 = 64, остается еще резерв для 25 символов (64 — 39 = 25). Его можно использовать для кодирования цифр, всевозможных скобок, знаков математических операций и других символов, встречающихся в русском тексте. Следовательно, информационный вес символа в расширенном русском алфавите будет равен 6 битам. А текст из 1000 символов будет иметь объем 6000 битов. Итак, если i — информационный вес символа алфавита, а К — количество символов в тексте, записанном с помощью этого алфавита, то информационный объем I текста выражается формулой: I = К x i (битов). Идея измерения количества информации в сообщении через длину двоичного кода этого сообщения принадлежит выдающемуся российскому математику Андрею Николаевичу Колмогорову. Согласно Колмогорову, количество информации, содержащееся в тексте, определяется минимально возможной длиной двоичного кода, необходимого для представления этого текста. Для определения информационного веса символа полезно знать ряд целых степеней двойки. Вот как он выглядит в диапазоне от 2 1 до 2 10 : Поскольку мощность N алфавита может не являться целой степенью двойки, информационный вес символа алфавита мощности N определяется следующим образом. Находится ближайшее к N значение во второй строке таблицы, не меньшее чем N. Соответствующее значение i в первой строке будет равно информационному весу символа. Пример. Определим информационный вес символа алфавита, включающего в себя все строчные и прописные русские буквы (66); цифры (10); знаки препинания, скобки, кавычки (10). Всего получается 86 символов. Поскольку 2 6 7 , информационный вес символов данного алфавита равен 7 битам. Это означает, что все 86 символов можно закодировать семиразрядными двоичными кодами. Для двоичного представления текстов в компьютере чаще всего применяется восьмиразрядный код. С помощью восьмиразрядного кода можно закодировать алфавит из 256 символов, поскольку 256 = 2 8 . В стандартную кодовую таблицу (например, используемую в ОС Windows таблицу ANSI) помещаются все необходимые символы: английские и русские буквы — прописные и строчные, цифры, знаки препинания, знаки арифметических операций, всевозможные скобки и пр.
Одна страница текста на листе формата А4 кегля 12 с одинарным интервалом между строками в компьютерном представлении будет иметь объем 4000 байтов, так как на ней помещается примерно 4000 знаков. Помимо бита и байта, для измерения информации используются и более крупные единицы: Объем той же страницы текста будет равен приблизительно 3,9 Кб. А книга из 500 таких страниц займет в памяти компьютера примерно 1,9 Мб.
Вопросы и задания 1. Есть ли связь между алфавитным подходом к измерению информации и содержанием информации? Следующая страница Источник |


 В двоичном коде каждая двоичная цифра несет одну единицу информации, которая называется 1 бит.
В двоичном коде каждая двоичная цифра несет одну единицу информации, которая называется 1 бит. 

 Более крупной, чем бит, единицей измерения информации является байт: 1 байт = 8 битов.
Более крупной, чем бит, единицей измерения информации является байт: 1 байт = 8 битов. 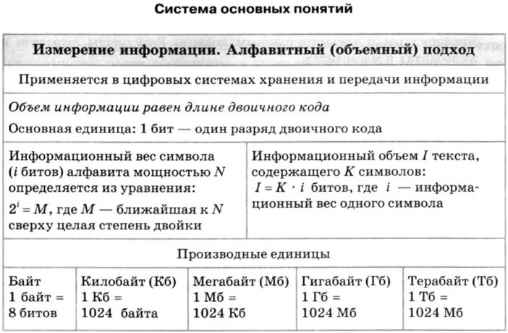
 Измерение информации. Содержательный подход
Измерение информации. Содержательный подход


