
- HTTP авторизация
- Общий механизм HTTP авторизации
- Прокси-авторизация
- Доступ запрещён
- Аутентификация с помощью изображений
- Кодировка символов HTTP аутентификации
- WWW-Authenticate and Proxy-Authenticate headers
- Authorization and Proxy-Authorization headers
- Authentication schemes
- Basic authentication scheme
- Security of basic authentication
- Restricting access with Apache and basic authentication
- Restricting access with nginx and basic authentication
- Access using credentials in the URL
- Авторизация
- API-ключ
- Получение
- Использование
- Персональный токен
- Получение
- Использование
- HTTP Headers для «чайников»
- Что такое HTTP Headers?
- Пример
- Как увидеть HTTP Headers
- Структура запроса HTTP
- Методы запроса
- GET: получение документа
- POST: отправка данных на сервер
- HEAD: получение информации заголовка
- Структура ответа HTTP
- Коды статуса HTTP
- 200 OK
- 206 Partial Content
- 404 Not Found
- 401 Unauthorized
- 403 Forbidden
- 302 (or 307) Moved Temporarily & 301 Moved Permanently
- 500 Internal Server Error
- Complete List
- Заголовки HTTP в запросах HTTP
- User-Agent
- Accept-Language
- Accept-Encoding
- If-Modified-Since
- Cookie
- Referer
- Authorization
- Заголовки HTTP в ответах HTTP
- Cache-Control
- Content-Type
- Content-Disposition
- Content-Length
- Last-Modified
- Location
- Set-Cookie
- WWW-Authenticate
- Content-Encoding
- Заключение
HTTP авторизация
HTTP предоставляет набор инструментов для разграничения доступа к ресурсам и авторизацией. Самой распространённой схемой HTTP авторизации является «Basic» (базовая) авторизация. Данное руководство описывает основные возможности HTTP авторизации и показывает способы ограничения доступа к вашему серверу с её использованием.
Общий механизм HTTP авторизации
RFC 7235 определяет средства HTTP авторизации, которые может использовать сервер для запроса (en-US) у клиента аутентификационной информации. Сценарий запрос-ответ подразумевает, что вначале сервер отвечает клиенту со статусом 401 (Unauthorized) и предоставляет информацию о порядке авторизации через заголовок WWW-Authenticate (en-US), содержащий хотя бы один метод авторизации. Клиент, который хочет авторизоваться, может сделать это, включив в следующий запрос заголовок Authorization с требуемыми данными. Обычно, клиент отображает запрос пароля пользователю, и после получения ответа отправляет запрос с пользовательскими данными в заголовке Authorization .

В случае базовой авторизации как на иллюстрации выше, обмен должен вестись через HTTPS (TLS) соединение, чтобы обеспечить защищённость.
Прокси-авторизация
Этот же механизм запроса и ответа может быть использован для прокси-авторизации. В таком случае ответ посылает промежуточный прокси-сервер, который требует авторизации. Поскольку обе формы авторизации могут использоваться одновременно, для них используются разные заголовки и коды статуса ответа. В случае с прокси, статус-код запроса 407 (Proxy Authentication Required) и заголовок Proxy-Authenticate (en-US), который содержит хотя бы один запрос, относящийся к прокси-авторизации, а для передачи авторизационных данных прокси-серверу используется заголовок Proxy-Authorization (en-US).
Доступ запрещён
Если (прокси) сервер получает корректные учётные данные, но они не подходят для доступа к данному ресурсу, сервер должен отправить ответ со статус кодом 403 Forbidden . В отличии от статус кода 401 Unauthorized или 407 Proxy Authentication Required , аутентификация для этого пользователя не возможна.
Аутентификация с помощью изображений
Аутентификация с помощью изображений, загружаемых из разных источников, была до недавнего времени потенциальной дырой в безопасности. Начиная с Firefox 59, изображения, загружаемые из разных источников в текущий документ, больше не запускают диалог HTTP-аутентификации, предотвращая тем самым кражу пользовательских данных (если нарушители смогли встроить это изображение в страницу).
Кодировка символов HTTP аутентификации
Браузеры используют кодировку utf-8 для имени пользователя и пароля. Firefox использовал ISO-8859-1 , но она была заменена utf-8 с целью уравнения с другими браузерами, а также чтобы избежать потенциальных проблем (таких как баг 1419658).
WWW-Authenticate and Proxy-Authenticate headers
WWW-Authenticate (en-US) и Proxy-Authenticate (en-US) заголовки ответа которые определяют методы, что следует использовать для получения доступа к ресурсу. Они должны указывать, какую схему аутентификации использовать, чтобы клиент, желающий авторизоваться, знал, какие данные предоставить. Синтаксис для этих заголовков следующий:
Here, is the authentication scheme («Basic» is the most common scheme and introduced below). The realm is used to describe the protected area or to indicate the scope of protection. This could be a message like «Access to the staging site» or similar, so that the user knows to which space they are trying to get access to.
Authorization and Proxy-Authorization headers
The Authorization and Proxy-Authorization (en-US) request headers contain the credentials to authenticate a user agent with a (proxy) server. Here, the type is needed again followed by the credentials, which can be encoded or encrypted depending on which authentication scheme is used.
Authentication schemes
The general HTTP authentication framework is used by several authentication schemes. Schemes can differ in security strength and in their availability in client or server software.
The most common authentication scheme is the «Basic» authentication scheme which is introduced in more details below. IANA maintains a list of authentication schemes, but there are other schemes offered by host services, such as Amazon AWS. Common authentication schemes include:
- Basic (see RFC 7617, base64-encoded credentials. See below for more information.),
- Bearer (see RFC 6750, bearer tokens to access OAuth 2.0-protected resources),
- Digest (see RFC 7616, only md5 hashing is supported in Firefox, see баг 472823 for SHA encryption support),
- HOBA (see RFC 7486 (draft), HTTP Origin-Bound Authentication, digital-signature-based),
- Mutual (see draft-ietf-httpauth-mutual),
AWS4-HMAC-SHA256 (see AWS docs).
Basic authentication scheme
The «Basic» HTTP authentication scheme is defined in RFC 7617, which transmits credentials as user ID/password pairs, encoded using base64.
Security of basic authentication
As the user ID and password are passed over the network as clear text (it is base64 encoded, but base64 is a reversible encoding), the basic authentication scheme is not secure. HTTPS / TLS should be used in conjunction with basic authentication. Without these additional security enhancements, basic authentication should not be used to protect sensitive or valuable information.
Restricting access with Apache and basic authentication
To password-protect a directory on an Apache server, you will need a .htaccess and a .htpasswd file.
The .htaccess file typically looks like this:
The .htaccess file references a .htpasswd file in which each line contains of a username and a password separated by a colon («:»). You can not see the actual passwords as they are encrypted (md5 in this case). Note that you can name your .htpasswd file differently if you like, but keep in mind this file shouldn’t be accessible to anyone. (Apache is usually configured to prevent access to .ht* files).
Restricting access with nginx and basic authentication
For nginx, you will need to specify a location that you are going to protect and the auth_basic directive that provides the name to the password-protected area. The auth_basic_user_file directive then points to a .htpasswd file containing the encrypted user credentials, just like in the Apache example above.
Access using credentials in the URL
Many clients also let you avoid the login prompt by using an encoded URL containing the username and the password like this:
Источник
Авторизация
API Яндекс.Маркета для производителей доступен только авторизованным пользователям. Авторизация происходит с помощью и . API-ключ выдает Яндекс.Маркет, персональный токен — сервис Яндекс.OAuth.
API-ключ
API-ключ — это ключ авторизации, который разрешает доступ к данным конкретного производителя на Яндекс.Маркете.
Получение
Производитель получает API-ключ автоматически, вместе с доступом в Кабинет производителя. Ключ отображается на странице Настройки в блоке Контактные данные .
Использование
API-ключ необходимо указывать во всех запросах в HTTP-заголовке Authorization :
Пример запроса с HTTP-заголовком Authorization на языке PHP:
Персональный токен
Персональный токен ― это OAuth-токен, который позволяет идентифицировать каждого представителя производителя в Яндекс.Маркете. Для каждого представителя необходимо получить отдельный токен.
Получение
Получите персональный токен для каждого представителя:
Войдите в Кабинет производителя под своим логином на Яндексе.
Откройте страницу Настройки ― в блоке Контактные данные перейдите по ссылке Персональный токен . Откроется страница сервиса Яндекс.OAuth.
Ознакомьтесь с информацией и нажмите кнопку Разрешаю . На странице отобразится ваш персональный токен.
Использование
Персональный токен необходимо указывать в HTTP-заголовке X-User-Authorization ― при каждом запросе к API Яндекс.Маркета для производителей от имени этого представителя:
Источник
HTTP Headers для «чайников»
Russian (Pусский) translation by Yuri Yuriev (you can also view the original English article)
Являетесь вы программистом или нет, вы видели его повсюду в Интернете. На данный момент в адресной строке браузера отображается нечто, что начинается с «https: //». Даже ваш первый скрипт Hello World отправил HTTP-header без вашего понимания. В этой статье мы собираемся узнать об основах HTTP-заголовков и о том, как их можно использовать в наших веб-приложениях.
Что такое HTTP Headers?
HTTP значит «Hypertext Transfer Protocol» (Протокол передачи гипертекста). Всемирная паутина использует этот протокол. Он был создан в начале 1990-х годов. Почти всё, что вы видите в вашем браузере, передаётся на ваш компьютер через HTTP. Например, когда вы открыли страницу этой статьи, ваш браузер отправил более 40 HTTP-запросов и получил HTTP-ответы для каждого из них.
Заголовки HTTP являются основной частью этих HTTP-запросов и ответов, и они несут информацию о браузере клиента, запрошенной странице, сервере и многом другом.
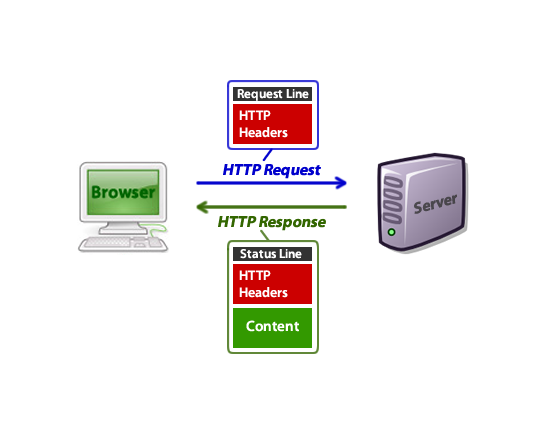

Пример
Когда вы вводите URL-адрес в адресной строке, ваш браузер отправляет HTTP-запрос, и он может выглядеть так:
Первая строка — это «Request Line», которая содержит некоторую базовую информацию по запросу. Остальные — HTTP заголовки.
После этого запроса ваш браузер получает ответ HTTP, который может выглядеть так:
Первая строка — это «Строка состояния», за которой следуют «HTTP-заголовки», до пустой строки. После этого начинается «содержимое» (в данном случае — HTML вывод).
Когда вы смотрите на исходный код веб-страницы в своём браузере, вы видите только часть HTML, а не заголовки HTTP, хотя они фактически были переданы вместе.
Эти HTTP-запросы также отправляются и принимаются для других вещей, таких как изображения, CSS-файлы, файлы JavaScript и т. д. Именно поэтому я сказал ранее, что ваш браузер отправил не менее 40 или более HTTP-запросов, поскольку вы загрузили только эту страницу статьи.
Теперь давайте рассмотрим структуру более подробно.
Как увидеть HTTP Headers
Для анализа HTTP-заголовков я использую следующие расширения Firefox:




- getallheaders() получает запросы headers. Вы можете использовать массив $_SERVER.
- headers_list() получает отзывы headers.
Далее в этой статье мы увидим примеры кода в PHP.
Структура запроса HTTP

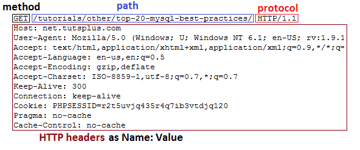
Первая строка HTTP-запроса называется линией запроса и состоит из трёх частей:
- «method» указывает, какой это запрос. Наиболее распространённые методы GET, POST и HEAD.
- «path» , как правило, является частью URL-адреса, который идёт после host (домена). Например, если запрос «https://net.tutsplus.com/tutorials/other/top-20-mysql-best-practices/» , часть path будет «/tutorials/other/top-20-mysql-best-practices/».
- Часть «protocol» содержит «HTTP» и версию, которая обычно 1.1 в современных браузерах.
Остальная часть запроса содержит HTTP headers как пары «Name: Value» в каждой строке. Они содержат различную информацию о HTTP-запросе и вашем браузере. Например, строка «User-Agent» предоставляет информацию о версии браузера и операционной системе, которую вы используете. «Accept-Encoding» сообщает серверу, может ли ваш браузер принимать сжатый output, например gzip.
Возможно, вы заметили, что данные cookie также передаются внутри HTTP-заголовка. И если бы ссылочный url, это было бы в header тоже.
Большинство этих заголовков являются необязательными. Этот HTTP-запрос мог быть таким же маленьким:
И вы всё равно получите правильный ответ от веб-сервера.
Методы запроса
Три наиболее часто используемых метода запроса: GET, POST и HEAD. Вы, вероятно, уже знакомы с первыми двумя, начиная с написания html-форм.
GET: получение документа
Это основной метод, используемый для извлечения html, изображений, JavaScript, CSS и т. д. С использованием этого метода запрошено большинство данных, загружаемых в ваш браузер.
Например, при загрузке статьи Nettuts +, самая первая строка HTTP-запроса выглядит так:
Как только html загрузится, браузер начнет отправлять GET-запрос изображений, который может выглядеть так:
Веб-формы можно настроить под метод GET. Вот пример.
Когда эта форма отправлена, HTTP-запрос начинается так:
Вы можете видеть, что каждый ввод формы был добавлен в строку запроса.
POST: отправка данных на сервер
Даже если вы можете отправлять данные на сервер с помощью GET и строки запроса, во многих случаях POST будет предпочтительнее. Отправка больших объёмов данных с помощью GET нецелесообразна и имеет ограничения.
Запросы POST чаще всего отправляются веб-формами. Давайте изменим предыдущий пример формы на метод POST.
Отправка этой формы создает HTTP-запрос следующим образом:
Здесь нужно отметить три важных момента:
- Путь в первой строке просто /foo.php, и больше нет строки запроса.
- Добавлены заголовки Content-Type и Content-Length, которые предоставляют информацию об отправляемых данных.
- Все данные теперь отправляются после заголовков, в том же формате, что и строка запроса.
Запросы POST метода также могут быть сделаны через AJAX, приложения, cURL и т. д. И все формы загрузки файлов необходимы для использования метода POST.
HEAD: получение информации заголовка
HEAD идентичен GET, за исключением того, что сервер не возвращает содержимое HTTP-ответа. Когда вы отправляете запрос HEAD, это означает, что вас интересуют только код ответа и HTTP headers, а не сам документ.
«Когда вы отправляете запрос HEAD, это означает, что вас интересуют только код ответа и HTTP headers, а не сам документ».
С помощью этого метода браузер может проверить, был ли документ изменён для целей caching. Он также может проверить, существует ли документ вообще.
Например, если у вас много ссылок на веб-сайте, вы можете периодически отправлять HEAD-запросы каждой из них, чтобы проверить наличие неработающих ссылок. Это будет намного быстрее, чем при использовании GET.
Структура ответа HTTP
После того, как браузер отправляет HTTP-запрос, сервер отвечает HTTP-ответом. Исключая контент, он выглядит так:


Первой порцией данных является протокол. Обычно это снова HTTP/1.x или HTTP/1.1 на современных серверах.
Следующая часть — это код состояния, за которым следует короткое сообщение. Код 200 означает, что наш запрос GET был успешным и сервер вернёт содержимое запрошенного документа сразу после headers.
Мы все видели «404» pages. Это число фактически приходит из части кода состояния HTTP-ответа. Если запрос GET будет создан для path, который сервер не может найти, он ответил бы 404, а не 200.
Остальная часть ответа содержит headers так же, как HTTP-запрос. Эти значения могут содержать информацию о софте сервера при последнем изменении страницы/файла, типе mime и прочее.
Опять же, большинство этих headers на самом деле являются необязательными.
Коды статуса HTTP
- 200 используются для успешных запросов.
- 300 для перенаправления.
- 400 используются, если возникла проблема с запросом.
- 500 используются, если возникла проблема с сервером.
200 OK
Как упоминалось ранее, этот код состояния отправляется в ответ на успешный запрос.
206 Partial Content
Если приложение запрашивает только диапазон запрошенного файла, возвращается код 206.
Это часто используется с менеджерами закачек, которые могут остановить и возобновить загрузку или разделить загрузку на части.
404 Not Found


Когда запрашиваемая страница или файл не найдена, сервер отправляет код ответа 404.
401 Unauthorized
Защищённые паролем веб-страницы отправляют этот код. Если вы не ввели логин правильно, вы можете увидеть следующее в вашем браузере.


Обратите внимание, что это относится только к страницам, защищённым паролем HTTP, которые вызывают запросы для входа следующим образом:


403 Forbidden
Если вам не разрешен доступ к странице, этот код может быть отправлен в ваш браузер. Это часто происходит, когда вы пытаетесь открыть URL-адрес для папки, в которой нет индексной страницы. Если параметры сервера не позволяют отображать содержимое папки, вы получите ошибку 403.
Например, на моем локальном сервере я создал папку изображений. Внутри этой папки я помещаю файл .htaccess с этой строкой: «Options -Indexes». Теперь, когда я пытаюсь открыть http://localhost/images/ — я вижу это:


Существуют другие способы блокировки доступа и 403 могут быть отправлены. Например, вы можете блокировать по IP-адресу с помощью некоторых директив htaccess.
302 (or 307) Moved Temporarily & 301 Moved Permanently
Эти два кода используются для перенаправления браузера. Например, когда вы используете службу сокращения URL, такую как bit.ly, именно так они перенаправляют людей, которые идут по ссылке.
302 и 301 обрабатываются браузером очень похоже, но они могут иметь различные значения для spiders поисковых систем. Например, если ваш сайт не готов для обслуживания, вы можете перенаправить его в другое место с помощью 302. Поисковая система продолжит проверку вашей страницы в будущем. Но если вы перенаправите с использованием 301, это сообщит spider, что ваш сайт переехал в это место навсегда. За более точной информацией: http://www.nettuts.com перейдите на https://net.tutsplus.com/ используя 301 код вместо 302.
500 Internal Server Error


Этот код обычно отображается при сбое веб-скрипта. Большинство скриптов CGI не выводят ошибки непосредственно в браузер, в отличие от PHP. Если есть фатальные ошибки, они просто отправят код статуса 500. И тогда программист должен искать в журналах ошибок сервера, чтобы найти сообщения об ошибках.
Complete List
Вы можете найти полный список кодов состояния HTTP с их пояснениями here.
Заголовки HTTP в запросах HTTP
Теперь мы рассмотрим некоторые из наиболее распространенных HTTP headers , найденных в HTTP requests.
Почти все эти заголовки можно найти в массиве $ _SERVER в PHP. Вы также можете использовать функцию getallheaders() для извлечения всех заголовков одновременно.
HTTP-запрос отправляется на определенные IP-адреса. Но так как большинство серверов способны размещать несколько сайтов под одним IP, они должны знать, какое доменное имя ищет браузер.
Это в основном имя host, включая домен и поддомен.
В PHP его можно найти, как $_SERVER[‘HTTP_HOST’] или $_SERVER[‘SERVER_NAME’].
User-Agent
Этот заголовок может содержать несколько частей информации, таких как:
- Имя и версия браузера.
- Название и версия операционной системы.
- Язык по умолчанию.
Именно так веб-сайты могут собирать определённую общую информацию о своих системах surfers. Например, они могут определить, использует ли surfer мобильный браузер и перенаправляет их на мобильную версию своего веб-сайта, который лучше работает с низким разрешением.
В PHP может быть выражен так: $_SERVER[‘HTTP_USER_AGENT’].
Accept-Language
Этот заголовок отображает настройки языка по умолчанию. Если сайт имеет разные языковые версии, он может перенаправить нового surfer на основе этих данных.
Он может содержать несколько языков, разделённых запятыми. Первый — это предпочтительный язык, и каждый из перечисленных языков может иметь значение «q», которое представляет собой оценку предпочтения пользователя для языка (min. 0 max. 1).
В PHP его можно найти так: $ _SERVER [«HTTP_ACCEPT_LANGUAGE»].
Accept-Encoding
Большинство современных браузеров поддерживают gzip и отправляют это в header. Затем веб-сервер может отправить выходной HTML-код в сжатом формате. Это позволяет уменьшить размер до 80% для экономии пропускной способности и времени.
В PHP его можно найти так: $ _SERVER [«HTTP_ACCEPT_ENCODING»]. Однако, когда вы используете функцию обратного вызова ob_gzhandler(), она будет проверять значение автоматически, поэтому вам это не нужно.
If-Modified-Since
Если веб-документ уже сохранен в кеше в браузере и вы посещаете его снова, ваш браузер может проверить, был ли документ обновлён, отправив следующее:
Если он не изменялся с этой даты, сервер отправляет код ответа «304 Not Modified», а содержимое — нет, и браузер загружает содержимое из cache.
В PHP его можно найти так: $ _SERVER [‘HTTP_IF_MODIFIED_SINCE’].
Существует также HTTP-заголовок Etag, который можно использовать для проверки текущего кэша. Мы поговорим об этом в ближайшее время.
Cookie
Как следует из названия, это отправляет файлы cookie, хранящиеся в вашем браузере для этого домена.
Это пары name=value, разделённые точками с запятой. Cookies могут также содержать id сеанса.
В PHP отдельные cookie-файлы могут быть доступны с помощью массива $ _COOKIE. Вы можете напрямую обращаться к переменным сеанса, используя массив $ _SESSION, и если вам нужен id сеанса, вы можете использовать функцию session_id () вместо cookie.
Referer
Как следует из названия, этот HTTP header содержит ссылочный url.
Например, если я зашел на домашнюю страницу Nettuts + и нажал ссылку на статью, этот header будет отправлен в мой браузер:
В PHP его можно найти как $ _SERVER [‘HTTP_REFERER’].
Возможно, вы заметили, что слово «referrer» написано с ошибкой, как «referer». К сожалению, он превратился в официальную спецификацию HTTP подобным образом и застрял.
Authorization
Когда веб-страница запрашивает авторизацию, браузер открывает окно входа в систему. Когда вы вводите имя пользователя и пароль в этом окне, браузер отправляет другой HTTP-запрос, но на этот раз он содержит этот header
Данные внутри header имеют кодировку base64. Например, base64_decode (‘bXl1c2VyOm15cGFzcw ==’) возвратит ‘myuser: mypass’
В PHP эти значения можно найти как $ _SERVER [‘PHP_AUTH_USER’] и $ _SERVER [‘PHP_AUTH_PW’].
Подробнее об этом будет, когда мы поговорим о заголовке WWW-Authenticate.
Заголовки HTTP в ответах HTTP
Теперь мы рассмотрим некоторые из наиболее распространенных HTTP headers, найденных в HTTP-ответах.
В PHP вы можете установить заголовки ответа, используя функцию header(). PHP уже отправляет определённые заголовки автоматически, для загрузки содержимого и настройки файлов cookie и прочее. Вы можете увидеть headers, которые отправляются или будут отправляться с помощью функции headers_list (). Вы можете проверить, были ли уже отправлены заголовки с помощью функции headers_sent().
Cache-Control
Определение из w3.org: «Поле заголовка Cache-Control используется для указания директив, которые ДОЛЖНЫ выполняться всеми механизмами кэширования по цепочке запросов/ответов». Эти «механизмы кэширования» включают шлюзы и прокси, которые может использовать ваш интернет-провайдер.
«public» означает, что ответ может быть кэширован кем угодно. «max-age» указывает, сколько секунд действителен кеш. Разрешение кэширования вашего сайта может снизить нагрузку на сервер и пропускную способность, а также увеличить время загрузки в браузере.
Кэширование также может быть предотвращено с помощью директивы «no-cache».
Подробности смотрите в w3.org.
Content-Type
Этот header указывает «mime-type» документа. Затем браузер определяет, как интерпретировать содержимое на основании этого. Например, страница html (или PHP-скрипт с выходом html) может возвращать это:
«text» — это тип, а «html» — подтип документа. Заголовок также может содержать больше информации, такой как charset.
Для gif-изображения это может быть отправлено.
Браузер может использовать внешнее приложение или расширение браузера на основе mime-type. Например, это приведет к загрузке Adobe Reader:
При загрузке напрямую Apache обычно может обнаружить mime-тип документа и отправить соответствующий header. Кроме того, большинство браузеров имеют некоторую степень отказоустойчивости и автоопределение типов mime, если заголовки указаны неверно или отсутствуют.
Вы можете найти список общих типов mime here.
В PHP вы можете использовать функцию finfo_file() для определения mime-типа файла.
Content-Disposition
Этот header указывает браузеру открыть окно загрузки файла, вместо того, чтобы пытаться проанализировать содержимое. Пример:
Это заставит браузер сделать это:


Обратите внимание, что соответствующий заголовок Content-Type также должен быть отправлен вместе с этим:
Content-Length
Когда контент будет передаваться браузеру, сервер может указать его размер (в байтах), используя этот header.
Это особенно полезно при загрузке файлов. Именно так браузер может определить ход загрузки.
Например, вот сценарий-макет, который я написал, имитирует медленную загрузку.


Теперь я собираюсь закомментировать заголовок Content-Length
Теперь результат такой:


Браузер может только сказать, сколько байтов было загружено, но он не знает общую сумму. И индикатор выполнения не показывает прогресс.
Это еще один header, который используется для кеширования. Это выглядит так:
Веб-сервер может отправлять этот header с каждым документом, который он обслуживает. Значение может быть основано на последней изменённой дате, размере файла или даже контрольной сумме файла. Браузер затем сохраняет это значение, так как он кэширует документ. В следующий раз, когда браузер запрашивает тот же файл, он отправляет это в HTTP-запросе:
Если значение Etag документа совпадает с этим, сервер будет отправлять код 304 вместо 200, и никакого содержимого. Браузер будет загружать содержимое из своего кеша.
Last-Modified
Как следует из названия, этот header указывает дату последнего изменения документа в формате GMT:
Это предлагает браузеру другой способ для cache документа. Браузер может отправить это в HTTP-запросе:
Мы уже говорили об этом ранее в разделе «If-Modified-Since».
Location
Этот заголовок используется для перенаправления. Если код ответа 301 или 302, сервер также должен отправить этот header. Например, когда вы перейдете на страницу http://www.nettuts.com, ваш браузер получит следующее:
В PHP вы можете перенаправить surfer так:
По умолчанию, это отправит 302 код ответа. Если вы хотите вместо 301 отправить:
Set-Cookie
Когда веб-сайт хочет установить или обновить файл cookie в вашем браузере, он будет использовать этот header.
Каждый файл cookie отправляется как отдельный header. Обратите внимание, что файлы cookie, установленные с помощью JavaScript, не проходят через HTTP headers.
В PHP вы можете установить cookie-файлы, используя функцию setcookie(), а PHP отправляет соответствующие HTTP headers.
Что приводит к отправке этого заголовка:
Если дата истечения срока действия не указана, cookie удаляется, когда окно браузера закрыто.
WWW-Authenticate
Сайт может отправить этот header для аутентификации пользователя через HTTP. Когда браузер увидит этот header, он откроет диалоговое окно входа в систему.
Что будет выглядеть так:
В руководстве PHP есть section, в котором приведены образцы кода, как это сделать в PHP.
Content-Encoding
Этот header обычно устанавливается, когда возвращаемое содержимое сжимается.
В PHP, если вы используете функцию обратного вызова ob_gzhandler(), она будет автоматически установлена.
Заключение
Спасибо за прочтение. Надеюсь, эта статья послужит хорошей отправной точкой для изучения HTTP Headers. Пожалуйста, оставьте свои комментарии и вопросы ниже, и я постараюсь дать как можно больше ответов.
Источник



