
- Процесс анализа данных
- Определение проблемы
- Извлечение данных
- Подготовка данных
- Изучение данных/визуализация
- Предсказательная (предиктивная) модель
- Проверка модели
- Развертывание (деплой)
- Анализ данных — основы и терминология
- Алгоритмы и эвристики
- Задачи машинного обучения с учителем
- Выбор метрики и валидационная процедура
- Типичный цикл развития проекта
- Заключение
Процесс анализа данных
Анализ данных можно описать как процесс, состоящий из нескольких шагов, в которых сырые данные превращаются и обрабатываются с целью создать визуализации и сделать предсказания на основе математической модели.
Анализ данных — это всего лишь последовательность шагов, каждый из которых играет ключевую роль для последующих. Этот процесс похож на цепь последовательных, связанных между собой этапов:
- Определение проблемы;
- Извлечение данных;
- Подготовка данных — очистка данных;
- Подготовка данных — преобразование данных;
- Исследование и визуализация данных;
- Предсказательная модель;
- Проверка модели, тестирование;
- Развертывание — визуализация и интерпретация результатов;
- Развертывание — развертывание решения.
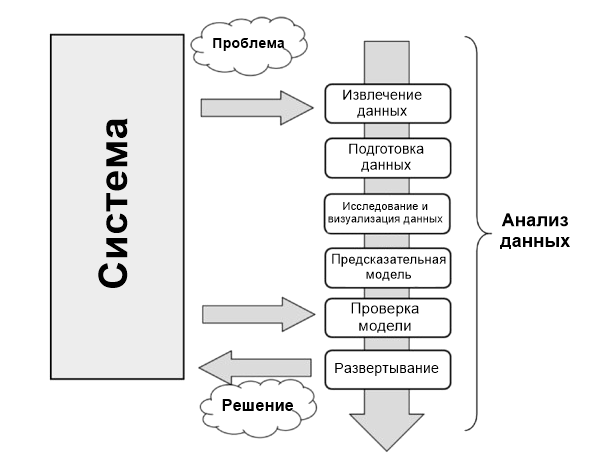 График показывает схематически все этапы анализа данных.
График показывает схематически все этапы анализа данных.
Определение проблемы
Процесс анализа данных начинается задолго до сбора сырых данных. Он начинается с проблемы, которую необходимо сперва определить, а затем и решить.
Определить ее можно только сосредоточившись на изучаемой системе: механизме, приложении или процессе в целом. Исследование может быть предназначено для лучшего понимания функционирования системы, но его лучше спроектировать так, чтобы понять принципы поведения и впоследствии делать предсказания или выбор (осознанный).
Процессы определения и документации результатов научной проблемы или бизнеса нужны для того, чтобы сосредоточить анализ на получении результатов.
На самом деле, всеобъемлющее и исчерпывающее исследование системы — это сложный процесс, и почти всегда нет достаточного количества информации, с которой можно начать. Поэтому определение проблемы и особенно планирование приводят к появлению руководящих принципов, которым необходимо следовать в течение всего проекта.
Когда проблема определена и задокументирована, можно двигаться к этапу планирования проекта анализа данных. Планирование необходимо для понимания того, какие профессионалы и ресурсы понадобятся для выполнения требований проекта максимально эффективно. Таким образом задача — рассмотреть те вопросы в области, которые касаются решения этой проблемы Необходимо найти специалистов с разными интересами и установить ПО, нужное для анализа данных.
Построение хорошей команды — один из ключевых факторов успешного анализа данных.
Также во время фазы планировки выбирается эффективная команда. Такие команды должны быть междисциплинарными, чтобы у них была возможность решать проблемы, рассматривая данные с разных точек зрения.
Извлечение данных
Когда проблема определена, первый шаг для проведения анализа — получение данных. Они должны быть выбраны с одной базовой целью — построение предсказательной модели. Поэтому выбор данных — также важный момент для успешного анализа.
Данные должны максимально отражать реальный мир — то, как система реагирует на него. Например, использовании больших наборов сырых данных, которые были собраны неграмотно, это привести либо к неудаче, либо к неопределенности.
Поэтому недостаточное внимание, уделенное выбору данных или выбор таких, которые не представляют систему, приведет к тому, что модели не будут соответствовать изучаемым системам.
Поиск и извлечение данных часто требует интуиции, границы которой лежат за пределами технических исследований и извлечения данных. Этот процесс также требует понимания природы и формы данных, предоставить которое может только опыт и знания практической области проблемы.
Вне зависимости от количества и качества необходимых данных важный вопрос — использование лучших источников данных.
Если средой изучения выступает лаборатория (техническая или научная), а сгенерированные данные экспериментальные, то источник данных легко определить. В этом случае речь идет исключительно о самих экспериментах.
Но при анализе данных невозможно воспроизводить системы, в которых данные собираются исключительно экспериментальным путем, во всех областях применения. Многие области требуют поиска данных в окружающем мире, часто полагаясь на внешние экспериментальные данные или даже на сбор их с помощью интервью и опросов.
В таких случаях поиск хорошего источника данных, способного предоставить все необходимые данные, — задача не из легких. Часто необходимо получать данные из нескольких источников данных для устранения недостатков, выявления расхождений и с целью сделать данные максимально общими.
Интернет — хорошее место для начала поиска данных. Но большую часть из них не так просто взять. Не все данные хранятся в виде файла или базы данных. Они могут содержаться в файле HTML или другом формате. Тут на помощь приходит техника парсинга. Он позволяет собирать данные с помощью поиска определенных HTML-тегов на страницах. При появлении таких совпадений специальный софт извлекает нужные данные. Когда поиск завершен, у вас есть список данных, которые необходимо проанализировать.
Подготовка данных
Из всех этапов анализа подготовка данных кажется наименее проблемным шагом, но на самом деле требует наибольшего количества ресурсов и времени для завершения. Данные часто собираются из разных источников, каждый из которых может предлагать их в собственном виде или формате. Их нужно подготовить для процесса анализа.
Подготовка данных включает такие процессы:
- получение,
- очистка,
- нормализация,
- превращение в оптимизированный набор данных.
Обычно это табличная форма, которая идеально подходит для этих методов, что были запланированы на этапе проектировки.
Многие проблемы могут возникнуть при появлении недействительных, двусмысленных или недостающих значений, повторении полей или данных, несоответствующих допустимому интервалу.
Изучение данных/визуализация
Изучение данных — это их анализ в графической или статистической репрезентации с целью поиска моделей или взаимосвязей. Визуализация — лучший инструмент для выделения подобных моделей.
За последние годы визуализация данных развилась так сильно, что стала независимой дисциплиной. Многочисленные технологии используются исключительно для отображения данных, а многие типы отображения работают так, чтобы получать только лучшую информацию из набора данных.
Исследование данных состоит из предварительного изучения, которое необходимо для понимания типа и значения собранной информации. Вместе с информацией, собранной при определении проблемы, такая категоризация определяет, какой метод анализа данных лучше всего подойдет для определения модели.
Эта фаза, в дополнение к изучению графиков, состоит из следующих шагов:
- Обобщение данных;
- Группировка данных;
- Исследование отношений между разными атрибутами;
- Определение моделей и тенденций;
- Построение моделей регрессионного анализа;
- Построение моделей классификации.
Как правило, анализ данных требует обобщения заявлений касательно изучаемых данных.
Обобщение — процесс, при котором количество данных для интерпретации уменьшается без потери важной информации.
Кластерный анализ — метод анализа данных, используемый для поиска групп, объединенных общими атрибутами (также называется группировкой).
Еще один важный этап анализа — идентификация отношений, тенденций и аномалий в данных. Для поиска такой информации часто нужно использовать инструменты и проводить дополнительные этапы анализа, но уже на визуализациях.
Другие методы поиска данных, такие как деревья решений и ассоциативные правила, автоматически извлекают важные факты или правила из данных. Эти подходы используются параллельно с визуализацией для поиска взаимоотношений данных.
Предсказательная (предиктивная) модель
Предсказательная аналитика — это процесс в анализе данных, который нужен для создания или поиска подходящей статистической модели для предсказания вероятности результата.
После изучения данных у вас есть вся необходимая информация для развития математической модели, которая кодирует отношения между данными. Эти модели полезны для понимания изучаемой системы и используются в двух направлениях.
Первое — предсказания о значениях данных, которые создает система. В этом случае речь идет о регрессионных моделях.
Второе — классификация новых продуктов. Это уже модели классификации или модели кластерного анализа. На самом деле, можно разделить модели в соответствии с типом результатов, к которым те приводят:
- Модели классификации: если полученный результат — качественная переменная.
- Регрессионные модели: если полученный результат числовой.
- Кластерные модели: если полученный результат описательный.
Простые методы генерации этих моделей включают такие техники:
- линейная регрессия,
- логистическая регрессия,
- классификация,
- дерево решений,
- метод k-ближайших соседей.
Но таких методов много, и у каждого есть свои характеристики, которые делают их подходящими для определенных типов данных и анализа. Каждый из них приводит к появлению определенной модели, а их выбор соответствует природе модели продукта.
Некоторые из методов будут предоставлять значения, относящиеся к реальной системе и их структурам. Они смогут объяснить некоторые характеристики изучаемой системы простым способом. Другие будут делать хорошие предсказания, но их структура будет оставаться «черным ящиком» с ограниченной способностью объяснить характеристики системы.
Проверка модели
Проверка (валидация) модели, то есть фаза тестирования, — это важный этап. Он позволяет проверить модель, построенную на основе начальных данных. Он важен, потому что позволяет узнать достоверность данных, созданных моделью, сравнив их с реальной системой. Но в этот раз вы берете за основу начальные данные, которые использовались для анализа.
Как правило, при использовании данных для построения модели вы будете воспринимать их как тренировочный набор данных (датасет), а для проверки — как валидационный набор данных.
Таким образом сравнивая данные, созданные моделью и созданные системой, вы сможете оценивать ошибки. С помощью разных наборов данных оценивать пределы достоверности созданной модели. Правильно предсказанные значения могут быть достоверны только в определенном диапазоне или иметь разные уровни соответствия в зависимости от диапазона учитываемых значений.
Этот процесс позволяет не только в числовом виде оценивать эффективность модели, но также сравнивать ее с другими. Есть несколько подобных техник; самая известная — перекрестная проверка (кросс-валидация). Она основана на разделении учебного набора на разные части. Каждая из них, в свою очередь, будет использоваться в качестве валидационного набора. Все остальные — как тренировочного. Так вы получите модель, которая постепенно совершенствуется.
Развертывание (деплой)
Это финальный шаг процесса анализа, задача которого — предоставить результаты, то есть выводы анализа. В процессе развертывания бизнес-среды анализ является выгодой, которую получит клиент, заказавший анализ. В технической или научной средах результат выдает конструкционные решения или научные публикации.
Развертывание — это процесс использования на практике результатов анализа данных.
Есть несколько способов развертывания результатов анализа данных или майнинга данных. Обычно развертывание состоит из написания отчета для руководства или клиента. Этот документ концептуально описывает полученные результаты. Он должен быть направлен руководству, которое будет принимать решения. Затем оно использует выводы на практике.
В документации от аналитика должны быть подробно рассмотрены следующие темы:
- Результаты анализа;
- Развертывание решения;
- Анализ рисков;
- Измерения влияния на бизнес.
Когда результаты проекта включают генерацию предсказательных моделей, они могут быть использованы в качестве отдельных приложений или встроены в ПО.
Источник
Анализ данных — основы и терминология
В этой статье я бы хотел обсудить базовые принципы построения практического проекта по (т. н. «интеллектуальному») анализу данных, а также зафиксировать необходимую терминологию, в том числе русскоязычную.
Анализ данных — это область математики и информатики, занимающаяся построением и исследованием наиболее общих математических методов и вычислительных алгоритмов извлечения знаний из экспериментальных (в широком смысле) данных; процесс исследования, фильтрации, преобразования и моделирования данных с целью извлечения полезной информации и принятия решений.
Говоря чуть более простым языком, я бы предложил понимать под анализом данных совокупность методов и приложений, связанных с алгоритмами обработки данных и не имеющих четко зафиксированного ответа на каждый входящий объект. Это будет отличать их от классических алгоритмов, например реализующих сортировку или словарь. От конкретной реализации классического алгоритма зависит время его выполнения и объем занимаемой памяти, но ожидаемый результат его применения строго зафиксирован. В противоположность этому мы ожидаем от нейросети, распознающей цифры, ответа 8 при входящей картинке, изображающей рукописную восьмерку, но не можем требовать этого результата. Более того, любая (в разумном смысле этого слова) нейросеть будет иногда ошибаться на тех или иных вариантах корректных входных данных. Будем называть такую постановку задачи и применяющиеся при ее решении методы и алгоритмы недетерминистическими (или нечеткими) в отличии от классических (детерминистических, четких).
Алгоритмы и эвристики
Описанную задачу распознавания цифр можно решать пытаясь самостоятельно подобрать функцию, реализующую соответствующее отображение. Получится, скорее всего, не очень быстро и не очень хорошо. С другой стороны, можно прибегнуть к методам машинного обучения, то есть воспользоваться вручную размеченной выборкой (или, в других случаях, теми или иными историческими данными) для автоматического подбора решающей функции. Таким образом, здесь и далее (обобщенным) алгоритмом машинного обучения я буду называть алгоритм, так или иначе на основе данных формирующий недетерминистический алгоритм, решающий ту или иную задачу. (Недетерминистичность полученного алгоритма нужна для того, чтобы под определение не подпадал справочник, использующий предварительно подгруженные данные или внешний API).
Таким образом, машинное обучение является наиболее распространенным и мощным (но, тем не менее, не единственным) методом анализа данных. К сожалению, алгоритмов машинного обучения, хорошо обрабатывающих данные более или менее произвольной природы люди пока не изобрели и поэтому специалисту приходится самостоятельно заниматься предобработкой данных для приведения их в пригодный для применения алгоритма вид. В большинстве случаев такая предобработка называется фичеселектом (англ. feature selection) или препроцессингом. Дело в том, что большинство алгоритмов машинного обучения принимают на вход наборы чисел фиксированной длины (для математиков — точки в  ). Однако сейчас также широко используются разнообразные алгоритмы на основе нейронных сетей, которые умеют принимать на вход не только наборы чисел, но и объекты, имеющие некоторые дополнительные, главным образом геометрические, свойства, такие как изображения (алгоритм учитывает не только значения пикселей, но и их взаимное расположение), аудио, видео и тексты. Тем не менее, некоторая предобработка как правило происходит и в этих случаях, так что можно считать, что для них фичеселект заменяется подбором удачного препроцессинга.
). Однако сейчас также широко используются разнообразные алгоритмы на основе нейронных сетей, которые умеют принимать на вход не только наборы чисел, но и объекты, имеющие некоторые дополнительные, главным образом геометрические, свойства, такие как изображения (алгоритм учитывает не только значения пикселей, но и их взаимное расположение), аудио, видео и тексты. Тем не менее, некоторая предобработка как правило происходит и в этих случаях, так что можно считать, что для них фичеселект заменяется подбором удачного препроцессинга.
Алгоритмом машинного обучения с учителем (в узком смысле этого слова) можно назвать алгоритм (для математиков — отображение), который берет на вход набор точек в (еще называются примерами или samples)  и меток (значений, которые мы пытаемся предсказать)
и меток (значений, которые мы пытаемся предсказать)  , а на выходе дает алгоритм (=функцию)
, а на выходе дает алгоритм (=функцию)  , уже сопоставляющий конкретное значение
, уже сопоставляющий конкретное значение  любому входу
любому входу  , принадлежащему пространству примеров. Например, в случае упомянутой выше нейросети, распознающей цифры, с помощью специальной процедуры на основе обучающей выборки устанавливаются значения, соответствующие связям между нейронами, и с их помощью на этапе применения вычисляется то или иное предсказание для каждого нового примера. Кстати, совокупность примеров и меток называется обучающей выборкой.
, принадлежащему пространству примеров. Например, в случае упомянутой выше нейросети, распознающей цифры, с помощью специальной процедуры на основе обучающей выборки устанавливаются значения, соответствующие связям между нейронами, и с их помощью на этапе применения вычисляется то или иное предсказание для каждого нового примера. Кстати, совокупность примеров и меток называется обучающей выборкой.
Список эффективных алгоритмов машинного обучения с учителем (в узком смысле) строго ограничен и почти не пополняется несмотря на активные исследования в этой области. Однако для правильного применения этих алгоритмов требуется опыт и подготовка. Вопросы эффективного сведения практической задачи к задаче анализа данных, подбора списка фичей или препроцессинга, модели и ее параметров, а также грамотного внедрения непросты и сами по себе, не говоря уже о работе над ними в совокупности.
Общая схема решения задачи анализа данных при использовании метода машинного обучения выглядит таким образом:
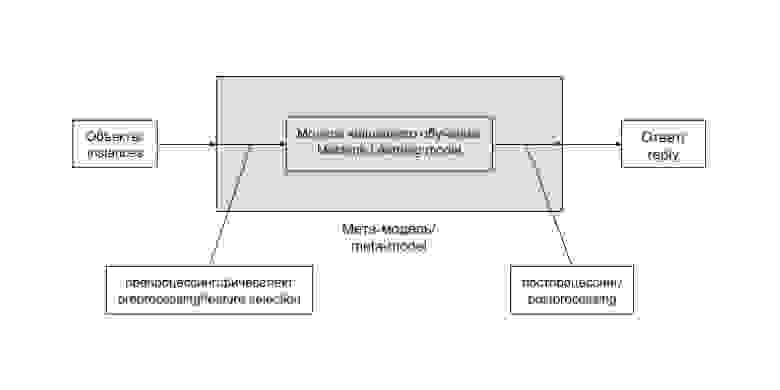
Цепочку «препроцессинг — модель машинного обучения — постпроцессинг» удобно выделять в единую сущность. Часто такая цепочка остается неизменной и лишь регулярно дообучается на новопоступивших данных. В некоторых случаях, особенно на ранних этапах развития проекта, ее содержимое заменяется более или менее сложной эвристикой, не зависящей напрямую от данных. Бывают и более хитрые случаи. Заведем для такой цепочки (и возможных ее вариантов) отдельный термин и будем называть мета-моделью (meta-model). В случае эвристики она редуцируется до следующей схемы:

Эвристика — это просто вручную подобранная функция, не использующая продвинутых методов, и, как правило, не дающая хорошего результата, но приемлемая в определенных случаях, например на ранних стадиях развития проекта.
Задачи машинного обучения с учителем
В зависимости от постановки, задачи машинного обучения делят на задачи классификации, регрессии и логистической регрессии.
Классификация — постановка задачи при которой требуется определить, какому классу из некоторого четко заданного списка относится входящий объект. Типичным и популярным примером является уже упоминавшееся выше распознавание цифр, в ней каждому изображению нужно сопоставить один из 10 классов, соответствующий изображенной цифре.
Регрессия — постановка задачи, при которой требуется предсказать некоторую количественную характеристику объекта, например цену или возраст.
Логистическая регрессия сочетает свойства перечисленных выше двух постановок задач. В ней задаются совершившиеся события на объектах, а требуется предсказать их вероятности на новых объектах. Типичным примером такой задачи является задача предсказания вероятности перехода пользователя по рекомендательной ссылке или рекламному объявлению.
Выбор метрики и валидационная процедура
Метрика качества предсказания (нечеткого) алгоритма — это способ оценить качество его работы, сравнить результат его применения с действительным ответом. Более математично — это функция, берущая на вход список предсказаний  и список случившихся ответов
и список случившихся ответов  , а возвращающая число соответствующее качеству предсказания. Например в случае задачи классификации самым простым и популярным вариантом является количество несовпадений
, а возвращающая число соответствующее качеству предсказания. Например в случае задачи классификации самым простым и популярным вариантом является количество несовпадений  , а в случае задачи регрессии — среднеквадратичное отклонение
, а в случае задачи регрессии — среднеквадратичное отклонение  . Однако в ряде случаев из практических соображений необходимо использовать менее стандартные метрики качества.
. Однако в ряде случаев из практических соображений необходимо использовать менее стандартные метрики качества.
Прежде чем внедрять алгоритм в работающий и взаимодействующий с реальными пользователями продукт (или передавать его заказчику), хорошо бы оценить, насколько хорошо этот алгоритм работает. Для этого используется следующий механизм, называемый валидационной процедурой. Имеющаяся в распоряжении размеченная выборка разделяется на две части — обучающую и валидационную. Обучение алгоритма происходит на обучающей выборке, а оценка его качества (или валидация) — на валидационной. В том случае, если мы пока не используем алгоритм машинного обучения, а подбираем эвристику, можно считать, что вся размеченная выборка, на которой мы оцениваем качество работы алгоритма является валидационной, а обучающая выборка пуста — состоит из 0 элементов.
Типичный цикл развития проекта
В самых общих чертах цикл развития проекта по анализу данных выглядит следующим образом.
- Изучение постановки задачи, возможных источников данных.
- Переформулировка на математическом языке, выбор метрик качества предсказания.
- Написание пайплайна для обучения и (хотя бы тестового) использования в реальном окружении.
- Написание решающей задачу эвристики или несложного алгоритма машинного обучения.
- По необходимости улучшение качества работы алгоритма, возможно уточнение метрик, привлечение дополнительных данных.
Заключение
На этом пока все, следующий раз мы обсудим какие конкретно алгоритмы применяются для решения задач классификации, регрессии и логистической регрессии, а о том, как сделать базовое исследование задачи и подготовить его результат для использования прикладным программистом уже можно почитать здесь.
Источник



