
- Модели организации баз данных
- Сетевая модель базы данных
- Операции над данными в сетевой модели БД
- Ограничения целостности
- Достоинства и недостатки ранних СУБД
- Объектно-ориентированные СУБД
- Структура
- Целостность данных
- Средства манипулирования данными
- Подведем теперь некоторые итоги
- Объектно-реляционные СУБД
- Краткие итоги
- Сетевые БД
- Урок 28. Информатика и ИКТ 11 класс (к учебнику Н. Д. Угриновича)
- В данный момент вы не можете посмотреть или раздать видеоурок ученикам
- Получите невероятные возможности
- Конспект урока «Сетевые БД»
Модели организации баз данных
Сетевая модель базы данных
На разработку этого стандарта большое влияние оказал американский ученый Ч.Бахман. Основные принципы сетевой модели данных были разработаны в середине 60-х годов, эталонный вариант сетевой модели данных описан в отчетах рабочей группы по языкам баз данных ( COnference on DAta SYstem Languages) CODASYL (1971 г.).
Сетевая модель данных определяется в тех же терминах, что и иерархическая. Она состоит из множества записей, которые могут быть владельцами или членами групповых отношений. Связь между записью-владельцем и записью-членом также имеет вид 1:N.
Основное различие этих моделей состоит в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Согласно этой модели каждое групповое отношение именуется и проводится различие между его типом и экземпляром. Тип группового отношения задается его именем и определяет свойства общие для всех экземпляров данного типа. Экземпляр группового отношения представляется записью-владельцем и множеством (возможно пустым) подчиненных записей. При этом имеется следующее ограничение: экземпляр записи не может быть членом двух экземпляров групповых отношений одного типа (т.е. сотрудник из примера в п..1, например, не может работать в двух отделах).
Иерархическая структура рис. 4.2 преобразовывается в сетевую модель, следующим образом (см. рис. 4.3):
- деревья (a) и (b), показанные на рис. 4.2, заменяются одной сетевой структурой, в которой запись СОТРУДНИК входит в два групповых отношения;
- для отображения типа M:N вводится запись СОТРУДНИК_КОНТРАКТ, которая не имеет полей и служит только для связи записей КОНТРАКТ и СОТРУДНИК, (см. рис. 4.3). Отметим, что в этой записи может храниться и полезная информация, например, доля данного сотрудника в общем вознаграждении по данному контракту.

Каждый экземпляр группового отношения характеризуется следующими признаками:
Способ упорядочения подчиненных записей:
- произвольный,
- хронологический /очередь/,
- обратный хронологический /стек/,
- сортированный.
Если запись объявлена подчиненной в нескольких групповых отношениях, то в каждом из них может быть назначен свой способ упорядочивания.
Режим включения подчиненных записей:
- автоматический — невозможно занести в БД запись без того, чтобы она была сразу же закреплена за неким владельцем;
- ручной — позволяет запомнить в БД подчиненную запись и не включать ее немедленно в экземпляр группового отношения. Эта операция позже инициируется пользователем.
Принято выделять три класса членства подчиненных записей в групповых отношениях:
- Фиксированное. Подчиненная запись жестко связана с записью владельцем и ее можно исключить из группового отношения только удалив. При удалении записи -владельца все подчиненные записи автоматически тоже удаляются. В рассмотренном выше примере фиксированное членство предполагает групповое отношение «ЗАКЛЮЧАЕТ» между записями «КОНТРАКТ» и «ЗАКАЗЧИК», поскольку контракт не может существовать без заказчика.
- Обязательное. Допускается переключение подчиненной записи на другого владельца, но невозможно ее существование без владельца. Для удаления записи-владельца необходимо, чтобы она не имела подчиненных записей с обязательным членством. Таким отношением связаны записи «СОТРУДНИК» и «ОТДЕЛ». Если отдел расформировывается, все его сотрудники должны быть либо переведены в другие отделы, либо уволены.
- Необязательное. Можно исключить запись из группового отношения, но сохранить ее в базе данных не прикрепляя к другому владельцу. При удалении записи -владельца ее подчиненные записи — необязательные члены сохраняются в базе, не участвуя более в групповом отношении такого типа. Примером такого группового отношения может служить «ВЫПОЛНЯЕТ» между «СОТРУДНИКИ» и «КОНТРАКТ», поскольку в организации могут существовать работники, чья деятельность не связана с выполнением каких-либо договорных обязательств перед заказчиками.
Операции над данными в сетевой модели БД
| Добавить | — внести запись в БД и, в зависимости от режима включения, либо включить ее в групповое отношение, где она объявлена подчиненной, либо не включать ни в какое групповое отношение. |
| Включить в групповое отношение | — связать существующую подчиненную запись с записью-владельцем. |
| Переключить | — связать существующую подчиненную запись с другой записью-владельцем в том же групповом отношении. |
| Обновить | — изменить значение элементов предварительно извлеченной записи. |
| Извлечь | — извлечь записи последовательно по значению ключа, а также используя групповые отношения — от владельца можно перейти к записям — членам, а от подчиненной записи к владельцу набора. |
| Удалить | — убрать из БД запись. Если эта запись является владельцем группового отношения, то анализируется класс членства подчиненных записей. Обязательные члены должны быть предварительно исключены из группового отношения, фиксированные удалены вместе с владельцем, необязательные останутся в БД. |
| Исключить из группового отношения | — разорвать связь между записью-владельцем и записью-членом. |
Ограничения целостности
Как и в иерархической модели обеспечивается только поддержание целостности по ссылкам (владелец отношения — член отношения).
Достоинства и недостатки ранних СУБД
Достоинства ранних СУБД:
- развитые средства управления данными во внешней памяти на низком уровне;
- возможность построения вручную эффективных прикладных систем;
- возможность экономии памяти за счет разделения подобъектов (в сетевых системах)
Недостатки ранних СУБД:
- сложность использования;
- высокий уровень требований к знаниям о физической организации БД;
- зависимость прикладных систем от физической организации БД;
- перегруженность логики прикладных систем деталями организации доступа к БД.
Как иерархическая, так и сетевая модель данных предполагает наличие высококвалифицированных программистов. И даже в таких случаях реализация пользовательских запросов часто затягивается на длительный срок.
Объектно-ориентированные СУБД
Появление объектно-ориентированных СУБД вызвано потребностями программистов на ОО-языках, которым были необходимы средства для хранения объектов, не помещавшихся в оперативной памяти компьютера. Также важна была задача сохранения состояния объектов между повторными запусками прикладной программы. Поэтому, большинство ООСУБД представляют собой библиотеку, процедуры управления данными которой включаются в прикладную программу. Примеры реализации ООСУБД как выделеного сервера базы данных крайне редки.
Сразу же необходимо заметить, что общепринятого определения » объектно-ориентированной модели данных » не существует. Сейчас можно говорить лишь о неком «объектном» подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации.
Мы знаем, что любая модель данных должна включать три аспекта: структурный, целостный и манипуляционный. Посмотрим, как они реализуются на основе объектно-ориентированная парадигмы программирования .
Структура
Структура объектной модели описывается с помощью трех ключевых понятий:
| инкапсуляция | — каждый объект обладает некоторым внутренним состоянием (хранит внутри себя запись данных), а также набором методов — процедур, с помощью которых (и только таким образом) можно получить доступ к данным, определяющим внутреннее состояние объекта, или изменить их. Таким образом, объекты можно рассматривать как самостоятельные сущности, отделенные от внешнего мира; |
| наследование | — подразумевает возможность создавать из классов объектов новые классы объекты, которые наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность. Наследование может быть простым (один предок) и множественным (несколько предков); |
| полиморфизм | — различные объекты могут по разному реагировать на одинаковые внешние события в зависимости от того, как реализованы их методы. |
Целостность данных
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
- автоматическое поддержание отношений наследования возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов; такие поля и методы используются только методами самого объекта создание процедур контроля целостности внутри объекта
Средства манипулирования данными
К сожалению, в объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
Подведем теперь некоторые итоги
В объектно-ориентированных базах данных, в отличие от реляционных, хранятся не записи, а объекты. ОО-подход представляет более совершенные средства для отображения реального мира, чем реляционная модель, естественное представление данных. В реляционной модели все отношения принадлежат одному уровню, именно это осложняет преобразование иерархических связей модели «сущность-связь» в реляционную модель. ОО — модель можно рассматривать послойно, на разных уровнях абстракции. Имеется возможность определения новых типов данных и операций с ними.
В то же время, ОО — модели присущ и ряд недостатков:
- отсутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных языках, проблема их оптимизации возлагается на программиста;
- вместо чисто декларативных ограничений целостности (типа явного объявления первичных и внешних ключей реляционных таблиц с помощью ключевых слов PRIMARY KEY и REFERENCES) или полудекларативных триггеров для обеспечения внутренней целостности приходится писать процедурный код.
Очевидно, что оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя способами — расширение ОО-языков в сторону управления данными (стандарт ODMG), либо добавление объектных свойств в реляционные СУБД (SQL-3, а также так называемые объектно-реляционных СУБД).
Объектно-реляционные СУБД
Разница между объектно-реляционными и объектными СУБД : первые являют собой надстройку над реляционной схемой, вторые же изначально объектно-ориентированы. Главная особенность и отличие объектно-реляционных, как и объектных, СУБД от реляционных заключается в том, что О(Р) СУБД интегрированы с Объектно-Ориентированным (OO) языком программирования, внутренним или внешним как C++, Java . Характерные свойства OРСУБД — 1) комплексные данные, 2) наследование типа, и 3) объектное поведение.
Комплексные данные могут быть реализованы через постоянно-хранимые объекты ( persistent objects). Создание комплексных данных в большинстве существующих ОРСУБД основано на предварительном определении схемы через определяемый пользователем тип ( UDT — user-defined type). Используются также встроенные конструкторы составных типов, например массив ( ARRAY ).
Иерархия структурных комплексных данных предлагает дополнительное свойство, наследование типа. То есть структурный тип может иметь подтипы, которые используют все его атрибуты и содержат дополнительные атрибуты, специфицированные в подтипе.
Объектное поведение закладывается через описание программных объектов. Такие объекты должны быть сохраняемыми и переносимыми для обработки в базе данных, поэтому они называются обычно как постоянные (или долговременные) объекты. Внутри базы данных все отношения с постоянным программным объектом есть отношения с его объектным идентификатором ( OID ).
Объектно-реляционными СУБД являются, к примеру, широко известные Oracle Database , Microsoft SQL Server 2005, PostgreSQL, а также Sav Zigzag, IBM Cloudscape.
Краткие итоги
Рассмотрены модели организации БД . Различают три основные модели базы данных — это иерархическая, сетевая и реляционная. Эти модели отличаются между собой по способу установления связей между данными.
Достоинства и недостатки ранних СУБД .
Рассмотрены более поздние модели СУБД такие как объектно-ориентированные и объектно-реляционные.
Источник
Сетевые БД
Урок 28. Информатика и ИКТ 11 класс (к учебнику Н. Д. Угриновича)

В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобрев в каталоге.
Получите невероятные возможности



Конспект урока «Сетевые БД»
На прошлом уроке мы с вами рассмотрели иерархические базы данных. В частности, узнали, что иерархическая структура – это многоуровневая форма организации объектов со строгой соотнесённостью объектов нижнего уровня определённому объекту верхнего уровня.
Также познакомились с такими элементами иерархической базы данных, как корень, предок, потомок и близнецы.
На этом уроке мы с вами рассмотрим сетевые базы данных, узнаем, чем сетевая структура отличается от иерархической, а также создадим сетевую базу данных на примере.
Сетевая структура – это логическая модель данных, которая является расширением иерархической структуры.
Давайте рассмотрим, чем отличается иерархическая структура от сетевой. Нам показаны два рисунка, на которых изображены иерархическая и сетевая структуры соответственно.
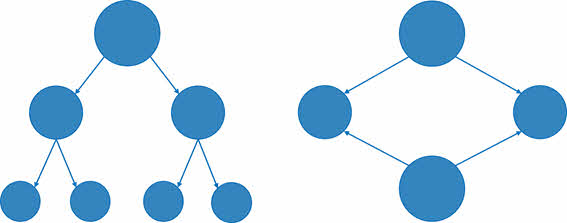
Как мы можем видеть, в иерархической структуре у потомка может быть только один предок. А вот в сетевой структуре у потомка может быть несколько предков.
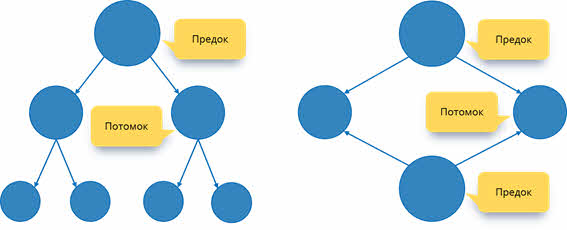
Т. е. в сетевой структуре нет ограничений на связи между объектами. Это говорит о том, что в ней могут находиться объекты, которые имеют более одного предка. Таким образом они организуют структуру, похожую на сеть. Примером сетевой базы данных является организация информации во Всемирной паутине глобальной компьютерной сети Интернет. Гиперссылки связывают между собой сотни миллионов документов в единую распределённую сетевую базу данных.
Также к примерам сетевой базы данных относится генеалогическое древо, т. к. в данной структуре у потомков имеется по 2 предка. То есть потомки (объекты нижележащего уровня) имеют всегда более одно предка (объекта вышестоящего уровня).
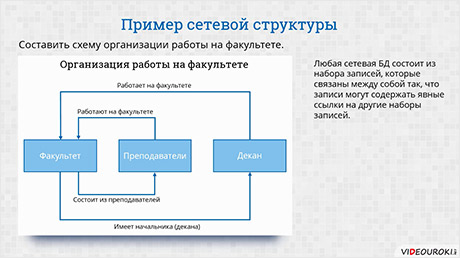
К примерам сетевой базы данных можно отнести и организацию работы на факультете.
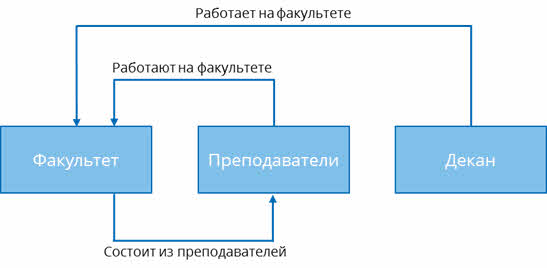
Давайте составим схему. На любом факультете есть преподаватели и декан. Изобразим при помощи прямоугольников сам факультет, преподавателей и декана.

Преподаватели и декан работают на факультете. Давайте изобразим это при помощи стрелок.
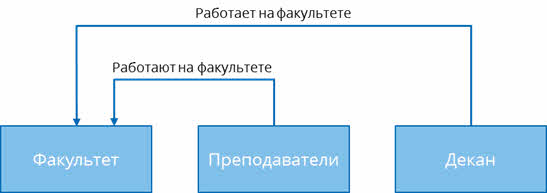
В свою очередь, любой факультет состоит из преподавателей. Также отобразим это отношение на схеме.
Ну и любой факультет имеет начальника, то есть декана. Снова изобразим это отношение.
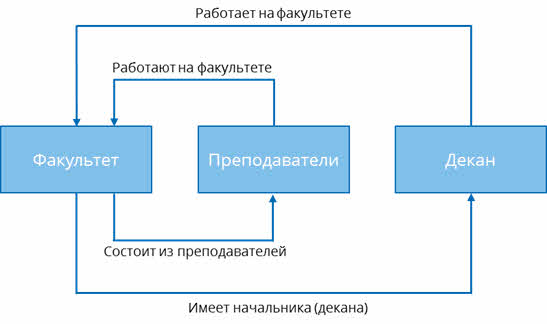
Таким образом мы составили с вами сетевую структуру факультета.
Любая сетевая база данных состоит из наборов записей, которые связаны между собой так, что записи могут содержать явные ссылки на другие наборы записей. То есть все объекты сетевой базы данных так или иначе связаны между собой. Так они образуют сеть. Все же связи между записями хранятся непосредственно в самой базе данных.
А сейчас рассмотрим операции, которые могут выполняться над данными в сетевой базе данных.
· Добавить. Внесение (добавление) записи в базу данных. Например, добавление нового преподавателя на факультет при его приёме на работу.
· Извлечь. Извлечение нужной нам записи из базы данных. Например, сведения о каком-либо преподавателе.
· Обновить. Это действие включает в себя изменение значения элементов записи, которая была предварительно извлечена. То есть, например, внесение дополнительных данных о преподавателе.
· Включить в групповое отношение. При выполнении этого действия мы связываем существующую подчинённую запись с записью-владельцем, то есть создаём своеобразную группу. Например, при приёме на работу нового преподавателя после внесения о нём записи в базу данных, мы будем связывать его с факультетом, на котором он работает.
· Исключить из группового отношения. Это действие разрывает связь между записью-владельцем и записью-членом. Такое действие выполняется, например, при увольнении преподавателя.
· Переключить. При помощи этого действия можно связать существующую подчинённую запись с другой записью-владельцем в том же групповом отношении. Например, при переводе преподавателя с одного факультета на другой в этом же университете.
Первоначально сетевая модель данных создавалась как инструмент для программистов. Базовым же языком программирования был выбран COBOL. Первая сетевая модель была предложена в 1969 году и развивалась до 1980-х годов.
К основному достоинству сетевой модели относятся высокая эффективность затрат памяти и оперативность (быстродействие). К основным недостаткам относятся сложность и жёсткость схемы базы, а также сложное понимание. Помимо этого, из-за возможности установки произвольных связей между записями, в этой модели ослаблен контроль целостности.
Возвращаясь же к сравнению иерархической базы данных и сетевой, можно сказать, что они обе обеспечивают достаточно быстрый доступ к данным. Но, в то же время, если нам необходимо получить какие-либо данные из иерархической базы данных, мы должны начинать запрос с корневой вершины. А вот в сетевой базе данных, так как каждая вершина может иметь связь с любой другой, соответственно данные являются более равноправными, то запрос можно отправлять на любой узел этой структуры.
А сейчас давайте составим генеалогическое древо, исходя из следующих данных:
· Иванов Андрей Геннадьевич, 28.05.1946 г. р.
· Иванова (Кулибина) Виктория Сергеевна, 05.08.1947 г. р.
· Кулаго Сергей Евгеньевич, 01.01.1947 г. р.
· Кулаго (Каменева) Елена Анатольевна, 19.04.1948 г. р.
· Сергеев Константин Алексеевич, 26.06.1955 г. р.
· Сергеева (Мирская) Анна Александровна, 06.09.1956 г. р.
· Иванов Юрий Андреевич, 04.05.1967 г. р.
· Иванова (Кулаго) Татьяна Сергеевна, 17.03.1968 г. р.
· Сергеев Виталий Валерьевич, 13.11.1977 г. р.
· Сергеева (Кулаго) Наталья Сергеевна, 06.12.1977 г. р.
· Иванова Ольга Юрьевна, 03.08.1991 г. р.
· Иванова Мария Юрьевна, 31.09.1998 г. р.
· Сергеева Екатерина Витальевна, 19.04.1995 г. р.
· Сергеева Дарья Витальевна, 17.03.2000 г. р.
Андрей и Виктория являются родителями Юрия. Сергей и Елена являются родителями Татьяны и Натальи. Константин и Анна – родители Виталия.
Юрий и Татьяна являются родителями Ольги и Марии. Наталья и Виталий – родители Екатерины и Дарьи.
Исходя из этих данных, давайте построим генеалогическое древо.
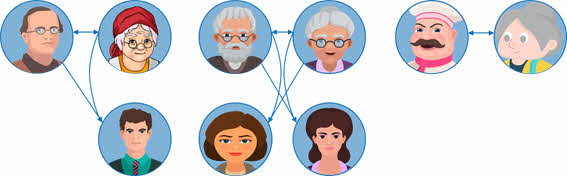
У нас будет шесть вершин: Андрей, Виктория, Сергей, Елена, Константин и Анна. А также изобразим при помощи стрелок, что Андрей и Виктория, Сергей и Елена, Константин и Анна являются семьями.

Далее у нас сказано, что Андрей и Виктория являются родителями Юрия. Изобразим на втором уровне Юрия и проведём к нему стрелки от Андрея и Виктории.

Сергей и Елена являются родителями Татьяны и Натальи. Проведём стрелки от родителей к дочерям.
Также у нас сказано, что Юрий и Татьяна являются родителями Ольги и Марии. Исходя из этого следует, что Юрий и Татьяна являются мужем и женой.
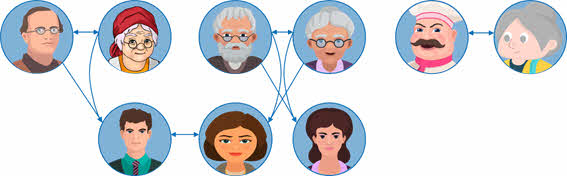
В условии также сказано, что Константин и Анна являются родителя Виталия. Проведём стрелки от родителей к сыну.
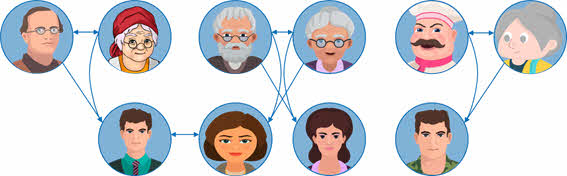
Также у нас сказано, что Наталья и Виталий являются родителями Екатерины и Дарьи, соответственно они являются мужем и женой. Изобразим это отношение на схеме.
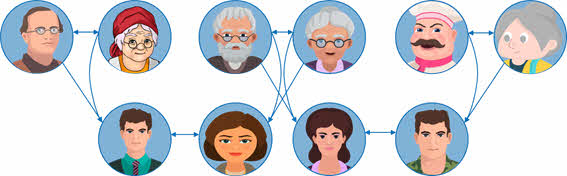
У нас осталось четыре человека: Ольга, Мария, Екатерина и Дарья.

Ольга и Мария являются дочерями Юрия и Татьяны. Изобразим это на схеме при помощи стрелок.

Екатерина и Дарья являются дочерями Натальи и Виталия. Также проведём стрелки от родителей к дочерям.

Подпишем каждого из членов семьи, а также даты их рождения.
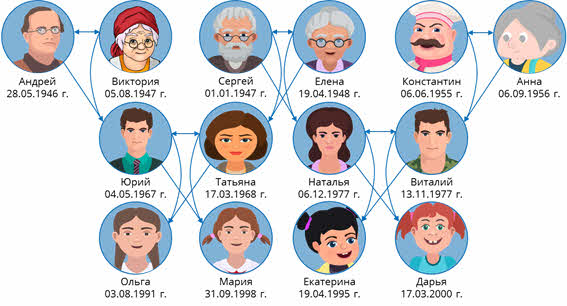
Мы с вами составили генеалогическое древо семьи. Данное древо является примером сетевой структуры, так как у нас потомки имеют по два предка. Например, Юрий является потомком Андрея и Виктории. Или же Екатерина является потомком Натальи и Виталия.
Если же более подробно рассматривать нашу схему, то мы можем видеть, что Андрей, Виктория, Сергей, Елена, Константин и Анна находятся на первом уровне. Юрий, Татьяна, Наталья и Виталий находятся на втором уровне. А Ольга, Мария, Екатерина и Дарья находятся на третьем уровне.

Также, исходя из этой схемы можно сказать, что те, кто находятся на первом уровне, являются дедушками и бабушками по отношению к Ольге, Марии, Екатерине и Дарье. Те, кто находятся на втором уровне, являются родителями.
Если же обратить внимание на данные, которые нам были предоставлены изначально, то мы можем заметить, что у некоторых членов семьи женского рода две фамилии, одна из которых написана в скобках. Обычно так пишется девичья фамилия тех, кто замужем.
Каждый из вас может построить генеалогическое древо своей семьи, причём количество предков и потомков может быть намного больше, чем в представленном примере.
А сейчас пришла пора подвести итоги урока.
На этом уроке мы с вами познакомились с сетевой структурой. Узнали, чем отличается иерархическая структура от сетевой. Помимо этого, мы построили генеалогическое древо семьи.
Источник



