
- Быстро и легко. Разбор (парсинг) XML документов с помощью TXMLDocument
- PHP: Как разобрать сложный XML-файл и не утонуть в собственном коде
- Разбор XML в соответствие или структуру (8.3)
- Скачать файлы
- Специальные предложения
- См. также
- Универсальный редактор данных (УРД) Промо
- Конвертация данных 3 расширение: Редактор кода.
- А1Э — альтернативная стандартная библиотека для 1С
- Должно быть NULL в регистре бухгалтерии Хозрасчетный
- Faster — многофункциональный ускоритель работы программиста 1С и других языков программирования Промо
- CF & SQL : конструктор прямых запросов к БД 1С
- Конвейер проверки качества кода
- Модель объекта
- Установка предопределенных элементов: просмотр, исправление и поиск ошибок (задвоенных и отсутствующих) Промо
- Переводим рутину ручного тестирования 1C на рельсы Jenkins-а и ADD
- Универсальный HTTP-сервис на платформе 1С, аля HTTP-сервер с примером
- Немного о графических файлах. Сжатие. Распознавание текста
- [Расширение] Контроль отрицательных остатков по регистру бухгалтерии при проведении Промо
- Расширение «Быстрая проверка кода» для конфигурации 1С:Автоматизированная проверка конфигураций
- Настройка отладки на сервере 1С
- Методика оптимизации программного кода 1С: проведение документов
- [x1c.ru] 1CDBin: Работа с файлами *.1CD на низком уровне средствами языка 1С с возможностью чтения таблиц (поддерживается формат 8.3.8.0) Промо
- Инструктор. Прототип инструмента создания быстрых пользовательских инструкций
- Конструктор мобильного клиента Simple WMS Client: способ создать полноценный ТСД без мобильной разработки. Теперь новая версия — Simple UI (обновлено 14.11.2019)
Быстро и легко. Разбор (парсинг) XML документов с помощью TXMLDocument
TXMLDocument – стандартный компонент для работы с XML, который входит в состав как VCL, так и FireMonkey. Данный компонент позволяет разбирать уже готовые XML файлы и формировать новые. При этом он выполняет обе задачи достаточно просто и эффективно.
Постановка задачи
Рассмотрим разбор XML на примере документа следующей структуры:
В документе имеется корневой элемент test, два обычных узла node1 (имеет атрибут attr) и node2, а также узел array, представляющий собой, по сути, массив некоторых данных.
Допустим, узел node1 и его атрибут необходимо интерпретировать как текст, node2, как числовое значение, а содержимое узла array, как набор строковых данных.
Реализация
Вначале необходимо загрузить XML документ из файла.
Далее получаем корневой элемент:
После этого можно приступать непосредственно к самому процессу разбора (парсинга).
Для доступа к дочерним узлам используется свойство ChildNodes, которое возвращает массив элементов IXMLNodeList. Для получения конкретного узла (элемента IXMLNode) нужно обратиться к нему по имени или номеру (нумерация начинается с нуля).
Содержимое узла доступно с помощью свойства Text в виде строки.
Доступ к атрибутам конкретного узла осуществляется аналогичным образом при помощи свойства Attributes, которое возвращает массив типа OleVariant содержащий непосредственно сами значения атрибутов.
Извлечём значение первого узла и его атрибута.
Значение второго узла извлекается аналогично, но с учётом того, что его требуется интерпретировать как число.
Для обхода массива потребуется цикл с обращением к каждому элементу по его номеру.
В результате всех вышеописанных действий данные из XML документа будут загружены и отображены в программе.

Несмотря на простоту, подобным образом можно выполнить разбор (парсинг) XML документов практически любой структуры и, соответственно, сложности.
Особенности работы с TXMLDocument в FireMonkey
В отличие от VCL, FireMonkey кроссплатформенная библиотека. Поэтому при работе с TXMLDocument в проектах FireMonkey требуется указывать программу, которая будет заниматься непосредственным разбором XML разметки в свойстве DOMVendor.
Доступны три варианта. MSXML для Windows (используется в этой операционной системе по умолчанию) и два кроссплатформенных Omni XML ADOM XML v4.
Если приложение предназначено для использования не только в Windows или вообще не предназначено для этой операционной системы, нужно обязательно учитывать данное обстоятельство и правильно выбирать программу для разбора XML разметки.
Источник
PHP: Как разобрать сложный XML-файл и не утонуть в собственном коде
Доброе время суток!
Сфера применения XML-формата достаточно обширна. Наряду с CSV, JSON и другими, XML — один из самых распространенных способов представить данные для обмена между различными сервисами, программами и сайтами. В качестве примера можно привести формат CommerceML для обмена товарами и заказами между 1С «Управление торговлей» и интернет-магазином.
Поэтому практически всем, кто занимается созданием веб-сервисов, время от времени приходится сталкиваться с необходимостью разбора XML-документов. В своем посте я предлагаю один из методов, как это сделать по возможности наглядно и прозрачно, используя XMLReader.
PHP предлагает несколько способов работы с форматом XML. Не вдаваясь в подробности, скажу, что принципиально их можно разделить на две группы:
- Загрузка всего XML-документа в память в виде объекта и работа с этим объектом
- Пошаговое чтение XML-строки на уровне тегов, атрибутов и текстового содержимого
Первый способ более понятен на интуитивном уровне, код выглядит прозрачней. Этот способ хорошо подходит для небольших файлов.
Второй способ — это более низкоуровневый подход, что дает нам ряд преимуществ, и вместе с тем несколько омрачает жизнь. Остановимся на нем поподробней. Плюсы:
- Скорость парсинга. Более подробно можете прочитать здесь.
- Потребление меньшего объема оперативной памяти. Мы не храним все данные в виде объекта, весьма затратного по памяти.
Но: мы жертвуем читаемостью кода. Если целью нашего парсинга является, скажем, подсчет суммы значений в определенных местах внутри XML с простой структурой, то проблем никаких.
Однако если структура файла сложна, еще работа с данными зависит от полного пути к этим данным, а результат должен включать в себя множество параметров, то здесь мы придем к довольно сумбурному коду.
Поэтому я написал класс, который впоследствии облегчил мне жизнь. Его использование упрощает написание правил и сильно улучшает читаемость программ, их размер становится в разы меньше, а код — красивее.
Основная идея в следующем: и схему нашего XML, и то, как с ней работать, мы будем хранить в одном-единственном массиве, повторяющем иерархию только необходимых нам тегов. Также для любого из тегов в этом же массиве мы сможем прописать нужные нам функции-обработчики открытия тега, его закрытия, чтения атрибутов или чтения текста, либо все вместе. Таким образом, мы храним структуру нашего XML и обработчики в одном месте. Одного взгляда на нашу структуру обработки будет достаточно для того, чтобы понять, что мы делаем с нашим XML-файлом. Оговорюсь, что на простых задачах (как в примерах ниже) преимущество в читаемости невелико, однако оно будет очевидно при работе с файлами относительно сложной структуры — например, форматом обмена с 1С.
Теперь конкретика. Вот наш класс:
Debug-версия (с параметром $debug):
Как видите, наш класс расширяет возможности стандартного класса XMLReader, к которому мы добавили один метод:
- $xml, $encoding, $options: как в XMLReader::xml()
- $structure: ассоциативный массив, полностью описывающий то, как мы должны работать с нашим файлом. Подразумевается, что его вид заранее известен, и мы точно знаем, с какими тегами и что мы должны делать.
- $debug: (только для Debug-версии) делать ли вывод отладочной информации (по умолчанию — откл.).
Аргумент $structure.
Это ассоциативный массив, структура которого повторяет иерархию тегов XML-файла плюс при необходимости в каждом из элементов структуры могут быть функции-обработчики (определены как поля с соответствующим ключом):
- «__open» — функция при открытии тега — function()
- «__attrs» — функция для обработки атрибутов тега (при наличии) — function($assocArray)
- «__text» — функция при наличии текстового значения тега — function($text)
- «__close» — функция при закрытии тега — function()
Если какой-либо из обработчиков возвратит false, то парсинг прервется, и функция xmlStruct() возвратит false. На приведенных ниже примерах видно, как конструировать аргумент $structure:
Пусть есть XML-файл:
Будут вызваны обработчики (в хронологическом порядке):
атрибуты root->a
текстовое поле root->a
открытие root->b
открытие root->b->x
текст root->b->x
закрытие root->b->x
закрытие root->b
Остальные поля обработаны не будут (в т.ч. root->d->x будет проигнорирован, т.к. он вне структуры)
Пусть есть XML-файл:
Это некий кассовый чек с товарами и услугами.
Каждая запись чека содержит идентификатор записи, тип (товар «product» или услуга «service»), наименование, количество и цена.
Задача: посчитать сумму чека, но раздельно по товарам и услугам.
Источник
Разбор XML в соответствие или структуру (8.3)
После открытия формы, выбираем xml файл и начинаем на него смотреть, с разных сторон.
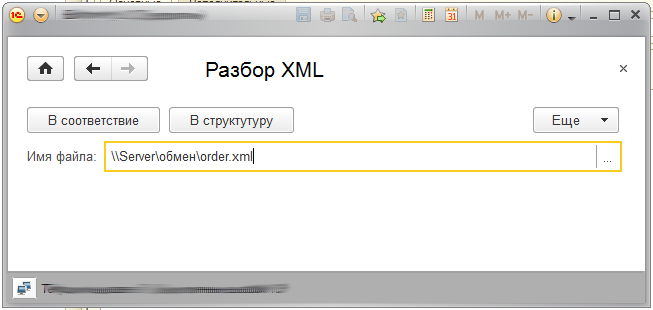
Мой файл выглядит примерно так:
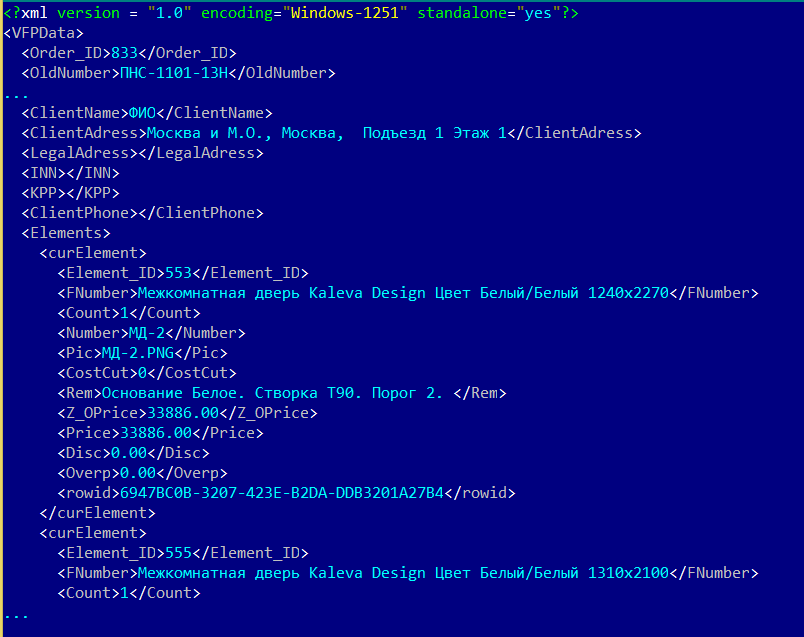
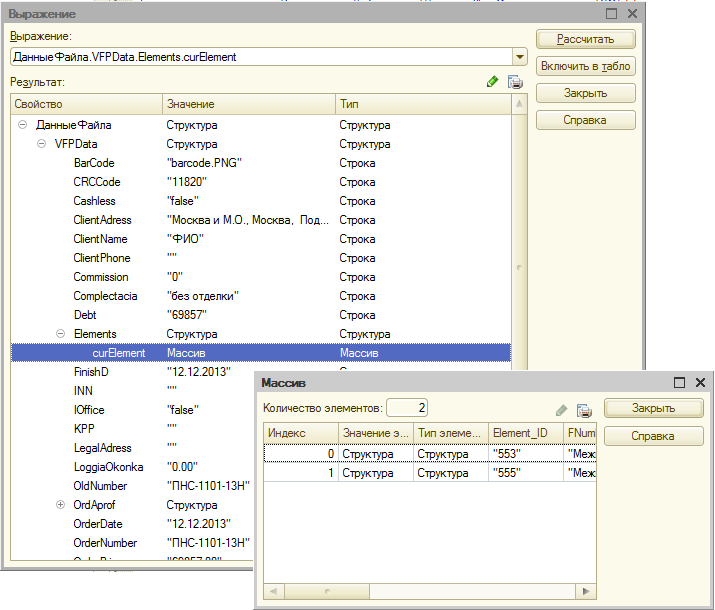
Нагляднее всего будет выглядеть структура:
Но структура имеет массу неприятных ограничений на имена свойств. А вот XML этих неприятностей лищён. Для большей совместимости с исходным форматом данных можно испольщовать соответствие:
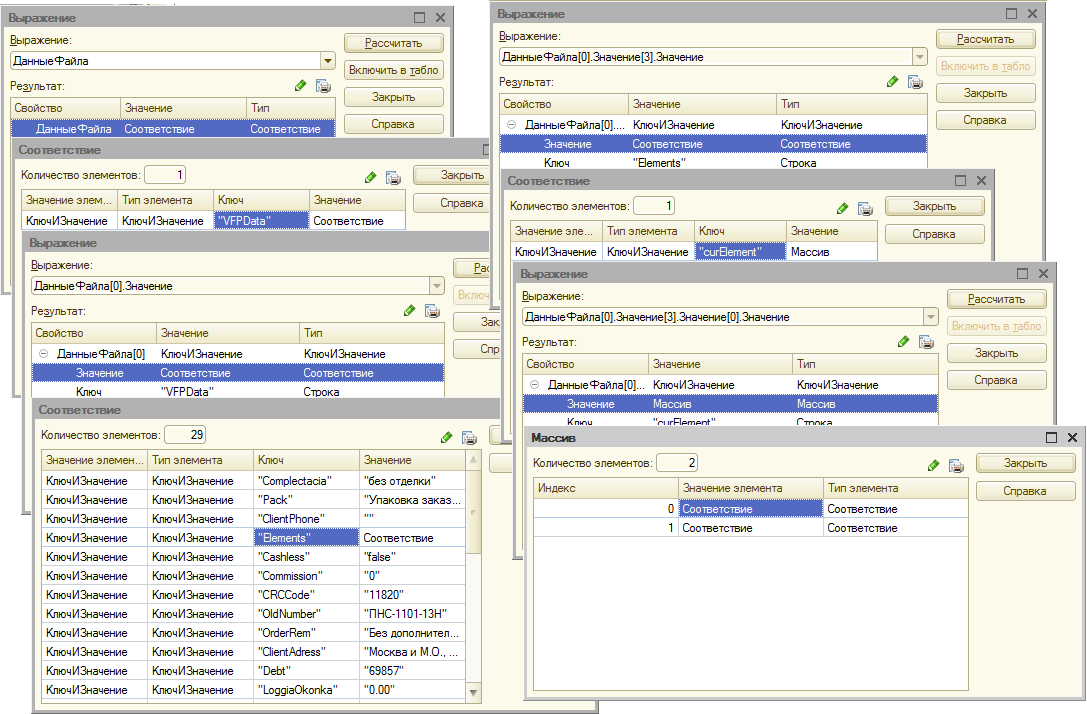
Это конечно более громоздко, по сравнению со структурой, но позволяет работать с «внезапными» XML файлами. Составители которых не знают о наших проблемах, вызываемых именем тега начинающегося с цифры, или содержащего пробел.
Скачать файлы
| Наименование | Файл | Версия | Размер |
|---|---|---|---|











