
- ПОСЛЕДОВАТЕЛЬНАЯ ОБРАБОТКА
- Последовательная обработка данных
- Описание презентации по отдельным слайдам:
- последовательная обработка информации
- Полезное
- Смотреть что такое «последовательная обработка информации» в других словарях:
- Обработка данных
- Описание процесса обработки данных. Понятие алгоритма и его свойства. Способы формальной записи алгоритмов
ПОСЛЕДОВАТЕЛЬНАЯ ОБРАБОТКА
Лекция 3. Последовательная обработка данных.
Последовательная обработка данных с указанным количеством элементов, с указанным признаком завершения последовательности, до конца файла. Последовательная обработка числовых последовательностей.
В ряде задач применяется последовательная обработка данных, если:
1. необходимо вводить и обрабатывать последовательность элементов исходных данных в том порядке, в каком она размещена в файле на внешнем носителе;
2. каждый элемент последовательности используется не более одного раза.
Такие задачи называют (однопроходной) последовательной обработкой данных. В этом случае не требуется хранения сразу всех элементов. Достаточно иметь одну переменную, содержащую текущий (очередной) элемент входной последовательности.
В некоторых случаях используются несколько текущих элементов (например, два-три соседних).
Элементами данных последовательности могут быть:
— записи файла и др.
Последовательность исходных данных может задаваться:
1. с указанием количества элементов;
2. с признаком конца последовательности;
3. обрабатываться до конца входного файла.
1. Входная последовательность задается с указанием количества элементов n ≥ 0 в следующем порядке:
Алгоритм 3.1. Последовательная обработка заданного количества элементов.
W -признак конца последовательности (известное заранее значение, отличающееся от элементов последовательности).
Алгоритм 3.2. Последовательная обработка элементов с признаком конца W.
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Источник
Последовательная обработка данных


Описание презентации по отдельным слайдам:
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
1
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
2
Последовательная обработка данных
Задача 4.1. Задана непустая числовая последовательность. Определить, является ли последовательность знакочередующейся.
Тест1. Вход: -5 3.1 -2 1 -7
Выход: Знаки чередуются.
Тест2. Вход: -5 3.1 2 -1 7
Выход: Знаки не чередуются.
Используем алгоритм 3.3. для обработки последовательности.
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
3
Последовательная обработка данных
Одного текущего элемента последовательности недостаточно, будем сохранять два соседних элемента:
xpred – предыдущий элемент последовательности,
x – текущий элемент последовательности.
При обработке последовательности необходимо искать нарушение знакочередования.
Используем дополнительную переменную
flag – признак знакочередования.
flag = 1 — знаки чередуются, 0 – нет,
инициализация: flag =1.
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
4
Последовательная обработка данных
/* Программа 4.1. Знакочередование последовательности чисел */
#include
void main(void)
< float xpred, x; /* предыдущее и текущее числа */
int flag = 1;/* flag = 1 — знаки чередуются, 0 — нет */
scanf(«%f», &xpred) ;
while( scanf(«%f», &x)>0)
< if (xpred * x >= 0) flag = 0;
xpred = x;
>
if (flag) printf («\n Знаки чередуются. «);
else printf («\n Знаки не чередуются. «);
>
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
5
Введение в программирование
ПОСЛЕДОВАТЕЛЬНАЯ
ОБРАБОТКА СИМВОЛОВ
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
6
Последовательная обработка символов
Значением символьного типа является одиночный символ.
В языке C символьные данные рассматриваются как разновидность целых чисел. Числовым значением символа является его код.
В языке C над символами разрешаются не только операции присваивания и сравнения, но и арифметические операции.
В международном стандарте ASCII код символа обычно занимает один байт, но иногда и два байта (в международном коде UNICODE).
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
7
Последовательная обработка символов
Примеры символьных констант:
‘*’ ‘a’‘5’‘n’
Специальные (управляющие) символьные константы:
‘\n’Новая строка (new line),
‘\t’ ‘\v’ Табуляция горизонтальная, вертикальная,
‘\b’Возврат на шаг (backspace),
‘\\’- \ (обратный слэш), ‘\»- ‘ (апостроф), ‘\»‘- » (кавычка),
‘\0’ Нулевой символ (байт с нулевым кодом).
Объявление символьных переменных
char [, ]…; или int [, ]…;
Например:
char s, sim = ‘Z’, c;
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
8
Последовательная обработка символов
Кодировка цифровых символов:
‘0’ = 48
‘1’ = ‘0’ + 1 = 49
‘2’ = ‘0’ + 2 = 50
. . .
‘9’ = ‘0’ + 9 = 57
Отсюда соотношения:
Код цифры = ‘0’ + Значение цифры
Значение цифры = Код цифры — ‘0’
Условие
«значение символьной переменой s является цифрой»
на языке C запишется так:
s >= ‘0’ && s 9 слайд 
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
9
Последовательная обработка символов
Коды заглавных латинских букв возрастают по алфавиту:
‘A’ =’A’ && s =’a’ && s 10 слайд
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
10
Последовательная обработка символов
char s; ( или int s; )
Ввод символа из стандартного входного файла (клавиатуры) в переменную s:
scanf («%с», &s);
можно заменить присваиванием
s = getchar ();
Функция getchar() вводит очередной символ из стандартного входного файла и возвращает в виде значения код этого символа.
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
11
Последовательная обработка символов
Ввод символа часто пишется внутри условия в операторах if, while, do-while и for.
Например, цикл ввода символов до конца файла
Ввод s;
while(s!= конец файла)
< Обработка s;
Ввод s;
>
может иметь вид
while ((s=getchar()) != EOF)
Обработка s;
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
12
Последовательная обработка символов
Символическая константа EOF — код конца файла (после нажатия клавиш Ctrl-Z или Ctrl-z, затем Enter).
Вывод символа s в стандартный выходной файл (на экран)
printf («%c», s);
эквивалентен оператору
putchar (s);
Стандартный входной и выходной файлы, вместо клавиатуры и экрана, можно переадресовать на любой файл магнитного диска.
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
13
Коды символов
Задача 4.2. Вывести коды введенных с клавиатуры символов. Последовательность завершается нажатием клавиши Esc.
Тест. Вход: Kazan 2007
Выход: K=82, a=97, z=122, a=97, n= 110, =32, 2=50, 0=48, 0=48, 7=55, = 27
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
14
Коды символов
/* Программа 4.2. Коды символов*/
#include
#include
main()
< int sim;
printf(«\n Введи текст, завершив клавишей Esc\n»);
do
< sim=getch(); putchar(sim);
printf(«=%d, «,sim);
>
while( sim!=27);
puts(» Нажми любую клавишу»); getch();
return 0;
>
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
15
Последовательная обработка символов
Подсчет строк, слов и символов
Задача 4.3. Составить программу подсчета во входном тексте количества строк, слов и символов.
Словом считается любая последовательность символов, не содержащая пробелов, символов табуляции и новой строки. Строка заканчивается символом новой строки.
Тест.Вход:
Если друг оказался вдруг
И не друг, и не враг, а так.
Выход:
Строк: 2, слов: 12, символов: 53.
Количество символов считаем сразу после ввода, количество строк – по количеству символов ‘\n’, а количество слов – при вводе символа не разделителя, перед которым был разделитель. Используем для этого флаг разделителя.
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
16
Пояснения к программе
switch (переключить) — оператор переключателя для организации многовариантного ветвления.
switch (выражение)
< [ case цел-конст-выраж: [оператор. ]].
[ default: оператор. ]
[ case цел-конст-выраж: [оператор. ]].
>
case (случай) — вариант ветвления, можно пометить целой или символьной константой (или константным выражением).
Вычисляется значение выражения. Переключатель осуществляет переход к одному из вариантов case, константное выражение которого совпадает с вычисленным значением, или к метке default (умолчание), если не совпадает ни с одной из констант вариантов ветвления.
Каждый вариант обычно заканчивается оператором break.
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
17
Последовательная обработка символов
/* Программа 4.3. Подсчет строк, слов и символов*/
/* текст::= символ…*/
/* символ::= разделитель | символ-слова*/
/* разделитель ::= пробел | новая-строка | табуляция*/
/* | конец-файла*/
/* символ-слова — любой символ, кроме разделителей*/
#include
#define DA 1
#define NET 0
void main ()
< int sim; /* Текущий символ (int для EOF) */
int kstr, ksl, ksim; /* Кол-во строк, слов и символов*/
int razdel; /* Флаг символа — разделитель*/
razdel = DA;/* 1-й символ текста — начальный*/
Описание слайда:
КГТУ (КАИ), кафедра АСОИУ
18
Подсчет строк, слов и символов
kstr = ksl = ksim = 0;
while ((sim = getchar()) != EOF)
<
ksim++;
switch (sim)
<
case ‘\n’:
kstr++;
razdel = DA; break; /* Эту строчку можно убрать! */
case ‘ ‘:
case ‘\t’:
razdel = DA; break;
default:/* Символ слова не разделитель */
if (razdel) /* Предыдущий символ — разделитель */
< ksl++; razdel = NET; >
>
>
printf («Строк: %d, слов: %d, символов %d. \n», kstr, ksl, ksim);
>
Если Вы считаете, что материал нарушает авторские права либо по каким-то другим причинам должен быть удален с сайта, Вы можете оставить жалобу на материал.
Источник
последовательная обработка информации
Словарь практического психолога. — М.: АСТ, Харвест . С. Ю. Головин . 1998 .
Психологический словарь . И.М. Кондаков . 2000 .
Большой психологический словарь. — М.: Прайм-ЕВРОЗНАК . Под ред. Б.Г. Мещерякова, акад. В.П. Зинченко . 2003 .
Полезное
Смотреть что такое «последовательная обработка информации» в других словарях:
Последовательная Обработка Информации — модель, используемая в когнитивной психологии, согласно которой информация поочередно проходит ряд преобразований в определенных блоках, так что в каждый отрезок времени ее переработка осуществляется лишь в одном блоке. Альтернативная модель… … Психологический словарь
Обработка информации (information processing) — Исследователи, стоящие на позициях информ. подхода к изучению челов. поведения, разделяют несколько ключевых допущений. Наиболее важное предположение заключается в том, что поведение определяется внутренним потоком информ. в границах действующего … Психологическая энциклопедия
параллельная обработка информации — модель обработки информации в мозге головном, согласно коей информация проходит ряд преобразований в определенных «функциональных блоках» мозга так, что в каждый момент времени ее обработка ведется одновременно (параллельно) в нескольких… … Большая психологическая энциклопедия
ОБРАБОТКА, ПОСЛЕДОВАТЕЛЬНАЯ — Обработка информации, при которой сложные входящие стимулы обрабатываются посредством манипуляции с фрагментами информации последовательно. Большинство контролируемых сознанием процессов обработки информации последовательно по своему характеру.… … Толковый словарь по психологии
информация: обработка последовательная — (последовательная обработка информации) модель обработки информации в мозге головном, согласно коей информация поочередно проходит ряд преобразований в определенных «функциональных блоках» мозга так, что в каждый момент времени ее обработка… … Большая психологическая энциклопедия
информация: обработка параллельная — модель обработки информации в мозге головном, согласно коей информация проходит ряд преобразований в определенных «функциональных блоках» мозга так, что в каждый момент времени ее обработка ведется одновременно (параллельно) в нескольких «блоках» … Большая психологическая энциклопедия
Стереосуггестия — (лат. suggestio – суггестия, внушение; др. греч. στερεός объёмный, пространственный) – внушение, осуществляемое в гипнотическом или трансовом состоянии посредством визуальной и слуховой стимуляции, основным принципом которого является… … Википедия
ПОИСК, ПОСЛЕДОВАТЕЛЬНЫЙ — Поиск информации в памяти, при котором фрагменты информации исследуются по одному, последовательно. См. последовательная обработка информации … Толковый словарь по психологии
Гипноз как инструмент исследования (hypnosis as a research tool) — Традиционно научные исслед. с использованием Г. имели целью изучение природы гипнотических феноменов, измерение индивидуальных различий в восприимчивости к Г. и клиническое применение Г. в таких областях, как психотер., симптоматическое лечение и … Психологическая энциклопедия
Китайская Национальная Нефтегазовая корпорация — (CNPC) Китайская Национальная Нефтегазовая корпорация это одна из крупнейших нефтегазовых компаний мира Китайская Национальная Нефтегазовая корпорация занимается добычей нефти и газа, нефтехимическим производством, продажей нефтепродуктов,… … Энциклопедия инвестора
Источник
Обработка данных
Процессам обработки, в том числе и обработке данных, присуще свойство, заключающееся в том, что обработка состоит из нескольких стадий, этапов, операций, которые могут рассматриваться как более простые процессы (подпроцессы) обработки. Стадии обработки могут быть взаимосвязаны. Выполнение тех или иных этапов обработки зависит от результатов выполнения других этапов.
Описание процессов обработки осуществляется в виде совокупности предписаний или достаточно простых действий, которые должны быть выполнены для придания объекту обработки желаемых свойств. Подобные описания, представленные в формализованном виде, обычно называются алгоритмами.
Для исследования процессов обработки данных используются различные формальные модели : конечные автоматы, сети Петри, взаимодействующие последовательные процессы Хоара, системы и сети массового обслуживания и многие другие. Они описывают различные аспекты процессов обработки. Некоторые из этих моделей рассматриваются далее.
Описание процесса обработки данных. Понятие алгоритма и его свойства. Способы формальной записи алгоритмов
В повседневной жизни часто встречаются различного рода предписания, инструкции и другие подобные документы, определяющие порядок действий, которые необходимо выполнить для достижения определенного результата. Примерами таких документов являются инструкции по использованию различных устройств (бытовых приборов, банкоматов, торговых автоматов и т.п.), правила выполнения работ в промышленности и строительстве, регламенты совершения различных действий (банковских операций, сделок на фондовых валютных и товарных биржах, проверок технического состояния оборудования и объектов и т.п.). Эти предписания могут отличаться различной степенью точности и детальности описания действий. Если предполагается, что исполнителем предпи-саний будет некоторое устройство (агрегат, станок, транспортное средство или ЭВМ), то предписание будет написано на некотором формальном языке. Типичным примером такого предписания является компьютерная программа, написанная на некотором языке программирования. Обобщением различного рода инструкций и предписаний является понятие алгоритма [27], [35].
Алгоритм — это точное, т. е. сформулированное на определенном языке, конечное описание того или иного общего метода, основанного на применении исполнимых элементарных тактов обработки.
Рассмотрим более подробно отдельные аспекты данного определения. Во-первых, в определении говорится, что описание должно быть точным. Точность описания необходима для того, чтобы обеспечить однозначность понимания действий, которые требуется выполнять, и последовательности их выполнения. В зависимости от того, для кого предназначен алгоритм, точность его описания может быть различной. Если алгоритм предназначен для выполнения человеком, то он может быть описан на естественном языке, например, на русском. В этом случае однозначному пониманию алгоритма не мешают некоторые орфографические ошибки или безобидные опечатки. Если алгоритм должен выполняться автоматическим устройством, то описание алгоритма выполняется на некотором формальном языке (см. п. 6.3), например, на языке инструкций вычислительной системы или языке программирования высокого уровня. Важно также, чтобы описание было конечным, чтобы его можно было загрузить (прочитать) за конечное время.
Во-вторых, важную роль в алгоритме играют элементарные шаги или действия, с помощью которых выполняется алгоритм. Эти действия должны быть достаточно конкретно описаны, чтобы однозначно интер-претироваться исполнителем. Алгоритм для исполнителя должен включать только те команды (элементарные действия), которые ему (исполнителю) доступны. Например, если алгоритм предназначен для выполнения на ЭВМ, то элементарные действия должны входить в систему команд ЭВМ.
В-третьих, алгоритмы, как правило, предназначены для решения не только частных задач (выполнения преобразований конкретных исходных данных), но и для решения целых классов задач. Подлежащие решению частные задачи выделяются из рассматриваемого класса выбором параметров алгоритма. Параметры играют роль исходных данных для алгоритма (процедуры преобразования исходных данных в результат). Например, может быть задан алгоритм, который осуществляет сложение любых двух натуральных чисел. Такому алгоритму нужны два натуральных числа в их десятичном представлении в качестве исходных данных, и он вырабатывает одно число в десятичном представлении как выходные данные (результат).
Алгоритмы характеризуются различными свойствами в зависимости от особенностей процесса их исполнения [26], [35]. Алгоритм называется терминистическим или завершающимся, если он всегда (для всех допустимых исходных данных) заканчивается после конечного числа шагов.
Алгоритм называется детерминистическим, если в процессе его выполнения нет никакой свободы в выборе очередного шага обработки.
Алгоритм называется детерминированным или однозначным, если результат алгоритма определен однозначно (даже если некоторые шаги алгоритма не определены однозначно).
Рассмотрим примеры алгоритмов.
Алгоритм вычисления значения дроби 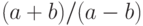 . Сначала вычисляются (используя алгоритмы сложения и вычитания) значения выражений
. Сначала вычисляются (используя алгоритмы сложения и вычитания) значения выражений  и
и  (в любой последовательности), потом находится частное от деления полученных результатов (используя алгоритм деления).
(в любой последовательности), потом находится частное от деления полученных результатов (используя алгоритм деления).
Этот пример демонстрирует иерархическую структуру алгоритмов. Алгоритм вычисления дроби основан на алгоритмах сложения, вычитания и деления чисел. Из того, что операции и могут выполняться в любой последовательности, следует, что этот алго-ритм не детерминистический, но детерминированный. Очевидно, что алгоритм завершающийся (достаточно всего трех элементарных действий: сложения, вычитания и деления).
Алгоритм вставки карточки в упорядоченную картотеку. Постановка задачи. Имеется колода карт. Пусть на каждой карте зафиксировано одно натуральное число. Требуется вставить карточку в картотеку, не нарушив упорядоченности картотеки.
В случае пустой картотеки (в картотеке нет карточек) вставка карточки тривиальна. В противном случае раскроем картотеку в произвольном месте и сравним записанное на открывшейся карточке число с числом на вставляемой карточке. В соответствии с результатом этого сравнения будем действовать тем же самым способом, вставляя карточку соответственно в переднюю или хвостовую часть картотеки. Процесс заканчивается, когда карточку нужно вставлять в пустое множество карт.
Очевидно, что этот алгоритм — завершающийся. Если все числа на карточках различны, то этот алгоритм — детерминированный. Однако из-за произвольности места, в котором раскрывается картотека, алгоритм не является детерминистическим.
Алгоритм для вычисления наибольшего общего делителя (НОД) двух натуральных чисел. Постановка задачи. Пусть даны два натуральных числа  , где
, где 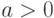 0″ style=»display: inline; «> и
0″ style=»display: inline; «> и 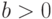 0″ style=»display: inline; «>; надо найти наибольший общий делитель НОД
0″ style=»display: inline; «>; надо найти наибольший общий делитель НОД 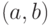 чисел
чисел  и
и  .
.
Еще в III веке до нашей эры математик Евклид, известный автор первого дошедшего до нас теоретического трактата по математике «Начала», в геометрической форме изложил правило получения наибольшего общего делителя двух натуральных чисел. Идея этого правила (обоснование его корректности) заключается в том, что если НОД — наибольший общий делитель двух натуральных чисел и , то в случае равенства этих чисел он совпадает с любым из них, а в случае их неравенства разность между большим и меньшим вместе с меньшим имеет тот же самый наибольший общий делитель. Назовем число, равное тому из двух чисел , которое не меньше другого, их верхней гранью и обозначим 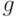 , а второе обозначим
, а второе обозначим  . После вычитания одного числа из другого получим новую пару чисел
. После вычитания одного числа из другого получим новую пару чисел 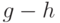 и , верхняя грань
и , верхняя грань 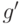 которых строго меньше . Новые числа имеют тот же наибольший общий делитель НОД
которых строго меньше . Новые числа имеют тот же наибольший общий делитель НОД 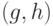 . Значит, мы свели задачу к нахождению наибольшего общего делителя натуральных чисел, верхняя грань которых меньше первоначальной.
. Значит, мы свели задачу к нахождению наибольшего общего делителя натуральных чисел, верхняя грань которых меньше первоначальной.
Повторяя прием, мы должны, в конце концов, прийти к случаю, когда новые полученные натуральные числа между собой равны, так как безграничное число шагов уменьшения верхней грани невозможно (потому что натуральных чисел, не превосходящих числа , всего несколько).
Сам алгоритм нахождения наибольшего общего делителя НОД двух натуральных чисел и (алгоритм Евклида) можно изложить так:
- если
 b» style=»display: inline; «>, то перейти к п. 4, иначе перейти к п. 2;
b» style=»display: inline; «>, то перейти к п. 4, иначе перейти к п. 2; - если a» style=»display: inline; «>, то перейти к п. 5, иначе перейти к п. 3;
- считать, что НОД . Конец;
- от отнять и впредь считать, что эта разность является значением . Возвратиться к п. 1;
- от отнять и впредь считать эту разность значением . Возвра-титься к п. 1.
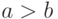 b» style=»display: inline; «>, то перейти к п. 4, иначе перейти к п. 2;
b» style=»display: inline; «>, то перейти к п. 4, иначе перейти к п. 2; a» style=»display: inline; «>, то перейти к п. 5, иначе перейти к п. 3;
a» style=»display: inline; «>, то перейти к п. 5, иначе перейти к п. 3;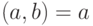 . Конец;
. Конец;Для алгоритма Евклида арифметическая операция «-» и проверка выполнения отношений » и 0″ style=»display: inline; «>, то получается алгоритм, который для неравных отрицательных чисел не прерывается, то есть не является завершающимся. Кроме того, данный алгоритм является детерминистическим, то есть для каждых исходных данных последовательность отдельных шагов точно определена.
Для рассмотренных достаточно простых алгоритмов их свойства (детерминистичность, детерминированность, завершаемость) легко устанавливаются. Однако в общем случае различные свойства алгорит-мов необходимо доказывать. Доказательство свойств алгоритмов относится к проблематике теории алгоритмов. Одним из важнейших вопросов, которым занимается теория алгоритмов, является выяснение того факта, что алгоритм решает сформулированную задачу для заданного множества исходных данных. Представляет интерес также нахождение множества исходных данных, на котором алгоритм решает сформулированную задачу.
В приведенных выше примерах описаний алгоритмов все время встречались некоторые похожие друг на друга фрагменты. Так, некоторые шаги алгоритма могут выполняться лишь при определенном условии, или выполнение некоторых шагов производится неоднократно. Часто также поставленная задача решается с помощью решения той же самой задачи, но с другими исходными данными (более простыми). В этих случаях говорят о разветвлении, повторении и рекурсии.
Классические элементы, которые встречаются в описаниях алгоритмов, — это:
- выполнение элементарных шагов;
- разветвления по условиям;
- повторения;
- рекурсии.
В примере с вычислением дроби мы имеем наиболее простой случай: количество элементарных тактов обработки постоянно и не зависит от чисел a, b. Иначе обстоит дело в других примерах: в случае алгоритма Евклида число шагов обработки зависит от величин чисел a, b, в случае алгоритма карточки число шагов зависит от размера картотеки. Хотя описание алгоритма конечно и постоянно, количество фактически выполняемых тактов — величина переменная; это часто является следствием использованию приема, сводящего общую задачу к более простой задаче того же класса. Этот прием называют рекурсией. В алгоритме Евклида и алгоритме вставки карточки в упорядоченную картотеку наличие рекурсии очевидно из алгоритма. В алгоритмах часто используется специальный случай рекурсии — чисто повторительная рекурсия. При описании алгоритма ее часто записывают в форме итерации: «Пока выполнено определенное условие, повторять. «.
Наряду с рекурсией и повторением в алгоритмах встречается также анализ возможных случаев. Без анализа отдельных случаев и выявления условий завершения было бы невозможно окончание рекурсивных алгоритмов.
Способы описания алгоритмов. Алгоритмы обрабатывают определенные объекты в качестве исходных данных («входные») и выдают другие объекты в качестве результатов. Объекты могут быть конкретными, как, например, десятичное число в случае алгоритма сложения десятичных чисел, или абстрактными, как, скажем, натуральные числа (для которых могут использоваться разнообразные эквивалентные системы предста-вления) в случае нахождения наибольшего общего делителя. Для описанного ранее алгоритма нахождения НОК совершенно не существенно, записываются числа в десятичной или двоичной системе счисления или даже римскими цифрами: свойства делимости от этого не меняются. В теоретических исследованиях предпочитают опираться на алгоритмы, которые работают, например, только с натуральными числами (Гедель) либо только с цепочками знаков (Марков). С практической точки зрения нет никакой пользы или нужды в таких ограничениях, допустимы какие угодно множества объектов, если только можно аккуратно определить их свойства. Разве лишь, поскольку приходится привлекать разбор отдельных случаев, необходимо включить в множество объектов, по крайней мере, значения истинности «истина» и «ложь». В зависимости от того, какие допускаются классы объектов (и соответствующих операций), приходят к различным классам алгоритмов.
Рассмотрим чуть более подробно специальную запись алгоритмов преобразования последовательностей знаков [27], [35]. Такая запись пред-ставляет собой один из способов уточнения понимавшегося до сих пор интуитивно понятия алгоритма.
Без сомнения, элементарной операцией над последовательностями знаков может считаться замена подслова на некоторое слово (текстовая замена). Будем исходить из множеств 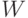 и
и  слов над общим набором знаков (алфавитом)
слов над общим набором знаков (алфавитом)  . Отдельную операцию замены, которую также называют продукцией, будем записывать в виде
. Отдельную операцию замены, которую также называют продукцией, будем записывать в виде  и понимать ее следующим образом.
и понимать ее следующим образом.
Если  является подсловом заданного слова
является подсловом заданного слова 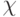 , то заменить это под-слово на
, то заменить это под-слово на 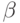 . В случае если подслово встречается в несколько раз, словом заменяется то из них, которое стоит в самой левой позиции.
. В случае если подслово встречается в несколько раз, словом заменяется то из них, которое стоит в самой левой позиции.
Далее, если дано конечное множество таких продукций, перечисленных в определенном порядке, то текстовая замена должна производиться посредством применения самой первой (относительно этого порядка) из применимых продукций. Все это повторяется до тех пор, пока возможно, или же до применения особым образом отмеченной продукции («останавливающей»). Учитывая, что одно из слов в продукции может быть пустым словом (см. 2.1.3), текстовая замена включает в себя вставку и присоединение знаков, а также вычеркивание знаков.
Такого рода алгоритмы называют алгоритмами Маркова по имени советского математика А. А. Маркова, который впервые описал их в 1951 г. Сам Марков называл их » нормальными алгоритмами «. Их можно считать уточнением понятия алгоритма, достигаемым за счет использования специальной формы описания. Существуют и другие подходы к уточнению (формализации) понятия алгоритма, используемые, в основном, для теоретических исследований.
Для практических целей часто используют графические способы описания алгоритмов, которые являются более компактными и наглядными. При графическом описании каждая операция процесса обработки изображается отдельной стандартной геометрической фигурой (блоком).
Некоторые стандартные блоки, их назначение и краткое описание приведены в таблице.
| Наименование | Обозначение | Функция |
|---|---|---|
| Процесс |
| Выполнение операции или группы операций, в результате которых изменяется значение, форма представления или расположение данных |
| Решение |
| Выбор направления выполнения алгоритма в зависимости от некоторых переменных условий |
| Ввод-вывод |
| Преобразование данных в форму, пригодную для обработки (ввод) или отображения результатов обработки (вывод) |
| Предопределённый процесс |
| Использование ранее созданных и отдельно написанных программ (подпрограмм) |
| Пуск-останов |
| Начало, конец, прерывание процесса обработки данных |
| Межстраничный соединитель |
| Указание связи между прерванными линиями, которые соединяют блоки, расположенные на разных листах |

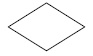
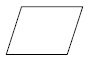



Блоки соединяются линиями переходов, определяющими очередность выполнения действий. Такое графическое представление называется схемой алгоритма или блок-схемой. Набор символов, используемых в блок-схемах, и правила изображения блок-схем в настоящее время определяются ГОСТ 19.701 — 90 (ИСО 5807 — 85) «Единая система программной документации. Схемы алгоритмов, программ, данных и систем. Условные обозначения и правила выполнения».
Источник



